
- 1谷歌前CEO Eric Schmidt:这就是人工智能未来改变科学研究的方式
- 2Docker Compose 通信超时问题及其解决方案_docker compose 超时
- 3OpenCV——彩色空间互转(python实现和c++实现)_实验一色彩空间转换与直方图处理e3、配置python+opencv的开发环境。“ 二、编写一
- 4Redis面试总结_mysql里有2000w数据,redis中只存20w的数据
- 5adb---调试连接设备_adb连接设备
- 6【数据结构】第十五弹---C语言实现直接插入排序
- 7重新定义大模型的学习方式:为什么算力和数据胜过代码?_学普通算法好 还是大模型算法好
- 8shiro反序列化漏洞原理分析及漏洞复现(Shiro-550/Shiro-721反序列化)_shiro550和shiro721的区别
- 92024年免费无限制使用的多功能ChatGPT中文平台_免费gpt
- 10华为OD机考题HJ1 字符串最后一个单词的长度
2022版shardingsphere4.1.1结合mybatis-plus进行简单依赖YML文件进行分片、自定义生成主键、自定义水平分片的相关策略_sharding5.2.1和4.1.1
赞
踩
shardingsphere4.1.1水平分片相关知识
一、概述
shardingsphere是一个很好的分库分表的技术,博主最近要处理大批量数据,所以也用到了这项技术,主要关于水平分表的,至于其它的以后再慢慢补充。一开始我用的是shardingsphere5.1.1,也就是shardingsphere最新版,但实践中总会出现这样或那样的问题,而且网上也只有最简单的操作,显然满足不了我的要求,同时我尝试使用shardingsphere4.1.1里的自动生成主键的相关库,也不行,我又想找有没有类似的,也没找到。没办法我又用了shardingsphere4.1.1,至于5.1.1版的以后再摸索补充。
二、相关代码
我就不废话了,直接上我的代码,希望能帮助大家。
1、pom.xml
主要是mybatis-plus 3. 5. 2 ,druid 1. 2. 8,shardingsphere 4. 1. 1,hutool 5. 8. 9
<!-- https://mvnrepository.com/artifact/com.baomidou/mybatis-plus-boot-starter -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.2</version>
</dependency>
<!--引入druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.8</version>
</dependency>
<!--shardingjdbc分片策略-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.1.1</version>
</dependency>
<!-- <dependency>-->
<!-- <groupId>org.apache.shardingsphere</groupId>-->
<!-- <artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>-->
<!-- <version>5.1.1</version>-->
<!-- </dependency>-->
<!--HUTool工具-->
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.9</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
2、application.yml(两种shardingsphere的编写)
因为我用了shardingsphere5.1.1和shardingsphere4.1.1,而且这是我写的第一篇关于shardingsphere的文章,想到读者也会陷入选择中,我就直接将我写的关于application.yml两个shardingsphere的代码都贴出来。上面的pom.xml也可自行取用。但shardingsphere5.1.1和shardingsphere4.1.1的application.yml不能混用。
(1)shardingsphere5.1.1(按照奇偶来分片存储,分片不均匀)仅作参考
这是广大其他博主写的关于奇偶来分片,简单的一批啊,作为入门也行。
server:
port: 8082
spring:
shardingsphere:
mode:
type: memory
datasource:
names: m1
m1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 123456
rules:
sharding:
tables:
test:
actual-data-nodes: m1.test_$->{0..2}
table-strategy:
standard:
sharding-column: id
sharding-algorithm-name: test-inline
key-generate-strategy:
column: id
key-generator-name: snowflake
key-generators:
snowflake:
type: SNOWFLAKE
sharding-algorithms:
test-inline:
type: inline
props:
# 分表策略
algorithm-expression: test_$->{id % 2 + 1}
props:
sql-show: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
(2)shardingsphere5.1.1(按照哈希取模分片算法,分片均匀 )仅作参考
这是按照哈希取模来分片的,也很简单,当做入门即可
server:
port: 8082
spring:
shardingsphere:
mode:
type: memory
datasource:
names: m1
m1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/test?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 123456
rules:
sharding:
tables:
test:
actual-data-nodes: m1.test_$->{0..2}
table-strategy:
standard:
sharding-column: id
sharding-algorithm-name: test-inline
key-generate-strategy:
column: id
key-generator-name: snowflake-name
key-generators:
snowflake-name:
type: SNOWFLAKE
sharding-algorithms:
test-inline:
type: HASH_MOD
props:
sharding-count: 3
props:
sql-show: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
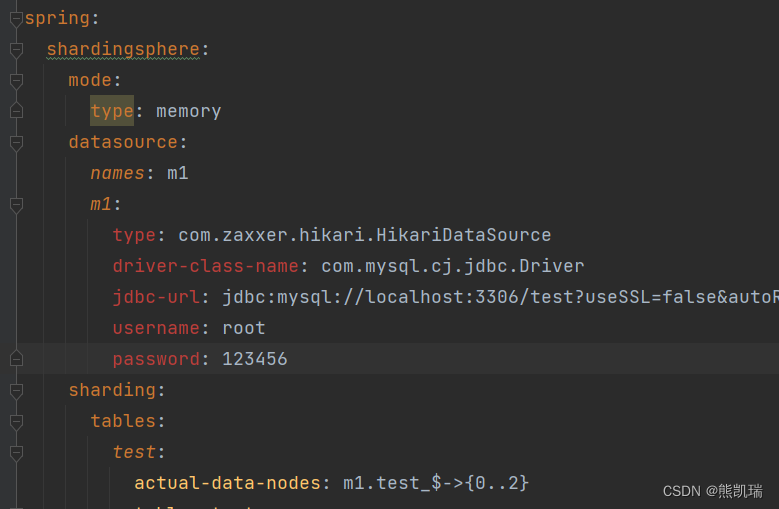
(3)shardingsphere4.1.1(按照奇偶来分片存储,分片不均匀)仅作参考
这的功能和shardingsphere5.1.1实现思路差不多,当做入门即可
server:
port: 8082
spring:
shardingsphere:
mode:
type: memory
datasource:
names: m1
m1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/test?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 123456
sharding:
tables:
test:
actual-data-nodes: m1.test_$->{0..2}
table-strategy:
inline:
sharding-column: id
algorithm-expression: test_$->{id % 3}
key-generator:
column: id
type: SNOWFLAKE
props:
sql-show: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
(4)shardingsphere4.1.1(自定义分片以及自定义主键自增)本文实际用到
作为博主的我自然不满足只实现那些简单方法,还是自定义的舒服,对于小白来说难度开始升级了啊。
server:
port: 8082
spring:
shardingsphere:
mode:
type: memory
datasource:
names: m1
m1:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/test?useSSL=false&autoReconnect=true&characterEncoding=UTF-8&serverTimezone=UTC
username: root
password: 123456
sharding:
tables:
test:
actual-data-nodes: m1.test_$->{0..2}
table-strategy:
standard:
sharding-column: id
precise-algorithm-class-name: com.example.demo01.sharding.CreateTableShardingAlgorithm
key-generator:
column: id
type: MIKEY
props:
sql-show: true
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
3、自定义主键生成策略(从1开始自增,按雪花算法增加)
(1)相关代码
package com.example.demo01.id;
import lombok.Getter;
import lombok.Setter;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.util.IdUtil;
import org.apache.shardingsphere.core.strategy.keygen.SnowflakeShardingKeyGenerator;
import org.apache.shardingsphere.spi.keygen.ShardingKeyGenerator;
import java.util.Properties;
import java.util.concurrent.atomic.AtomicLong;
public class keyGenerator implements ShardingKeyGenerator {
private AtomicLong atomic = new AtomicLong(0);
@Getter
@Setter
private Properties properties = new Properties();
/**
* 方案一 id从 1 开始增加(1,2,3.....)
* @return
*/
@Override
public Comparable<?> generateKey() {
System.out.println("------执行了自定义主键生成器 简单自增+1-------");
Long id = atomic.incrementAndGet();
System.out.println("自定义的id" + id);
return id;
}
// /**
// * 方案二 id遵从雪花算法
// * @return
// */
// @Override
// public Comparable<?> generateKey() {
// System.out.println("------执行了自定义主键生成器 雪花算法-------");
// Snowflake snowflake = IdUtil.getSnowflake(1, 1);
// Long id = snowflake.nextId();
// System.out.println("我自定义的id" + id);
// return id;
// }
/**
* 自定义主键生成的名字
* @return
*/
@Override
public String getType() {
return "MIKEY";
}
@Override
public Properties getProperties() {
return null;
}
@Override
public void setProperties(Properties properties) {
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
(2)创建文件
这个地方是写死的,想要主键递增成功,必须这样写,这样配。

(3)文件内容
也就是你写的自定义主键自增策略的类的路径
// 文件内容
com.example.demo01.id.keyGenerator
- 1
- 2

4、自定义水平分片策略(表有三个,所以%3,普通入门即可)
package com.example.demo01.sharding;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingAlgorithm;
import org.apache.shardingsphere.api.sharding.standard.PreciseShardingValue;
import org.springframework.stereotype.Component;
import java.util.Collection;
@Component
public class CreateTableShardingAlgorithm implements PreciseShardingAlgorithm<Long> {
/**
* 自定义水平分片的策略
* @param collection
* @param preciseShardingValue
* @return
*/
@Override
public String doSharding(Collection<String> collection, PreciseShardingValue<Long> preciseShardingValue) {
//preciseShardingValue就是当前插入的字段值
//collection 内就是所有的逻辑表
//获取字段值
Long id = preciseShardingValue.getValue();
System.out.println("水平分表获得的id: " + id);
if(id == null){
throw new UnsupportedOperationException("id is null");
}
//循环表名已确定使用哪张表
for (String tableName : collection) {
// 去掉字符串最后一位
tableName = tableName.substring(0,tableName.length() -1);
// 字符串添加余数
tableName= tableName + (int) (id % 3);
//返回要插入的逻辑表
return tableName;
}
return null;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
5、实体类
这个id必须加 @TableId(type = IdType.AUTO),不然会出错
package com.example.demo01.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
import java.io.Serializable;
@Data
@TableName("test")
public class Tests implements Serializable {
// 当配置了shardingsphere-jdbc的分布式序列时,自动使用shardingsphere-jdbc的分布式序列
// 当没有配置shardingsphere-jdbc的分布式序列时,自动依赖数据库的主键自增策略
// 代码中主键用Long,数据库中主键用bigint
@TableId(type = IdType.AUTO)
private Long id;
private String price;
private Integer money;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
6、Mapper类
继承mybatis-plus的mapper
package com.example.demo01.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.example.demo01.entity.Tests;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface TestMapper extends BaseMapper<Tests> {
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
7、测试类
@Test
void contextLoads() {
for (int i = 1 ; i < 16; i++) {
Tests test = new Tests();
test.setPrice("price:" + i);
test.setMoney(100);
System.out.println(test);
testMapper.insert(test);
}
}
@Test
void test2(){
List<Tests> list = testMapper.selectList(null);
System.out.println(list);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
三、注意
有些小伙伴可能有些倒霉,yml文件中粘贴上去,还是爆红。但不要慌,像博主我还不是爆红了,照样能用,所以临危不乱,当时我想了好久,没想出来为什么爆红,之后自暴自弃直接运行,居然成功了,开心,当然如果有小伙伴告诉博主解决方案,博主也会更开心啦。
- xml层: -->
赞
踩

