
- 1uniapp开发微信小程序-5.用户授权登录和用户信息获取_uniapp获取微信用户信息
- 2动手学深度学习(Pytorch版)代码实践 -深度学习基础-09过拟合与欠拟合
- 3初阶数据结构1_public int rank;
- 4为了追到小姐姐,我用 Python 制作了一个机器人
- 52023年湖北高考作文AI写_湖北拥有农产品资源ai续写
- 6Python 用 py7zr压缩文件_pyhton py7zr archive.write 把路径也压缩进去了
- 7【脚本工具】Python暴力破解ZIP文件_脚本破译工具
- 8MATLAB算法实战应用案例精讲-【深度学习】预训练模型-Transformer_matlab 使用transformer进行深度学习
- 9【AI速递】OPENAI的GPT-4 升级为GPT-4 Turbo了!_是gpt4-turbo能创建gpts还是gpt4能创建
- 10解决 Docker pull 速度慢,出现的 error pulling image configuration 后面为i/o timeout_docker pull io timeout
数据库操作指南:轻松掌握CRUD和高级查询技巧,轻松实现数据操作_sql增删改查基本命令
赞
踩
SQL增删改查详解
一、CRUD
注意,操作数据库的时候为避免名称可能存在关键字的影响,最好使用反引号包含起来;这样MySQL在做词法语法分析的时候,就不会把其作为关键字进行分析。
1.1、创建数据库
语法:
CREATE DATABASE `数据库名` DEFAULT CHARACTER SET utf8;
- 1
示例:
create DATABASE `fly_test` DEFAULT CHARACTER set utf8;
- 1
执行信息:
create DATABASE `fly_test` DEFAULT CHARACTER set utf8
> OK
> 时间: 0 秒
- 1
- 2
- 3
1.2、选择数据库
语法:
USE `数据库名`;
- 1
示例:
use fly_test;
- 1
执行信息:
use fly_test
> OK
> 时间: 0 秒
- 1
- 2
- 3
1.3、删除数据库
语法:
DROP DATABASE `数据库名`;
- 1
示例:
DROP DATABASE `fly_test2`;
- 1
执行信息:
DROP DATABASE `fly_test2`
> OK
> 时间: 0 秒
- 1
- 2
- 3
1.4、CRUD的五大约束
- not null,即非空约束。
- Autoincrement,即自增约束。可以指定初始值,没有指定默认是0;插入节点的时候会自增。这对事务的一致性非常重要。
- unique,即唯一约束。
- primary,即主键约束。设计表的时候,每张表都需要一个主键约束;就算没有设置,MySQL也会自动帮生成一个主键。
- foreign,即外键约束。用于表与表之间的联动关系。
1.5、创建表
语法:
CREATE TABLE `table_name` (column_name column_type);
- 1
创建表的时候,要有列名称、列类型、约束。
示例:
CREATE TABLE IF NOT EXISTS `fly_table1` (
`id` INT UNSIGNED AUTO_INCREMENT COMMENT '编号',
`course` VARCHAR(100) NOT NULL COMMENT '课程',
`teacher` VARCHAR(40) NOT NULL COMMENT '讲师',
`price` DECIMAL(8,2) NOT NULL COMMENT '价格',
PRIMARY KEY ( `id` )
)ENGINE=innoDB DEFAULT CHARSET=utf8 COMMENT = '课程表';
- 1
- 2
- 3
- 4
- 5
- 6
- 7
ENGINE指定引擎,charset指定编码方式,COMMENT是注释。
执行信息:
CREATE TABLE IF NOT EXISTS `fly_table1` (
`id` INT UNSIGNED AUTO_INCREMENT COMMENT '编号',
`course` VARCHAR(100) NOT NULL COMMENT '课程',
`teacher` VARCHAR(40) NOT NULL COMMENT '讲师',
`price` DECIMAL(8,2) NOT NULL COMMENT '价格',
PRIMARY KEY ( `id` )
)ENGINE=innoDB DEFAULT CHARSET=utf8 COMMENT = '课程表'
> OK
> 时间: 0.006 秒
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
1.6、删除数据表
1.6.1、删除表
语法:
DROP TABLE `table_name`;
- 1
删除表结构及其表数据。
1.6.2、清空数据表
语法:
TRUNCATE TABLE `table_name`; -- 截断表 以页为单位(至少有两行数据),有自增索引的话,从初始值开始累加
DELETE TABLE `table_name`; -- 逐行删除,有自增索引的话,从之前值继续累加
- 1
- 2
TRUNCATE TABLE:截断表 以页为单位(至少有两行数据),有自增索引的话,从初始值开始累加。
DELETE TABLE : 逐行删除,有自增索引的话,从之前值继续累加
1.6.3、区别
| 命令 | 速度 | 内容 | 事务回滚 |
|---|---|---|---|
| drop | 速度最快 | 删除整张表的表结构和表数据,包括索引,约束‘触发器等等。 | 不能回滚 |
| truncate | 速度较快 | 删除表数据,其他保留。 | 不能回滚 |
| delete | 速度较慢 | 删除部分或全部数据,其他保留。这是条件删除 | 能回滚 |
drop和truncate会阻塞其他操作。只有停机维护状态才使用这两个命令。
| 命令 | 删除原理 | 使用建议 |
|---|---|---|
| drop | 删除整张表 | 业务上最好不使用。一般在停机维护状态时,修改或设计表结构出现错误时使用。 |
| truncate | 以页为单位进行删除。 | 业务上最好不使用。一般在停机维护状态时,修改或设计表结构出现错误时使用。 |
| delete | 逐行删除。 | 推荐使用 |
因为delete是以行为单位,逐行删除的;而drop是以页(8K)为单位进行删除的;所以delete比drop慢。
1.7、增
语法:
INSERT INTO `table_name`(`field1`, `field2`, ...,`fieldn`) VALUES (value1, value2, ..., valuen);
- 1
如果列设置了自增组件,那么操作时可以不列出来,系统会将其自增的。
示例:
INSERT INTO fly_table1 (`course`,`teacher`,`price`) VALUES ('linux C/C++','fly',0.0);
- 1
执行信息:
INSERT INTO fly_table1 (`course`,`teacher`,`price`) VALUES ('linux C/C++','fly',0.0)
> Affected rows: 1
> 时间: 0.046 秒
- 1
- 2
- 3
1.8、删
语法:
DELETE FROM `table_name` [WHERE Clause];
- 1
示例:
DELETE FROM `fly_table1` where id = 2;
- 1
执行信息:
DELETE FROM `fly_table1` where id = 2
> Affected rows: 1
> 时间: 0.001 秒
- 1
- 2
- 3
1.9、改
语法:
UPDATE table_name SET field1=new_value1,field2=new_value2 [, fieldn=new_valuen]
- 1
示例:
UPDATE `fly_table1` SET price=price+100,course='linux MySQL' WHERE id =3;
- 1
执行信息:
UPDATE `fly_table1` SET price=price+100,course='linux MySQL' WHERE id =3
> Affected rows: 1
> 时间: 0.003 秒
- 1
- 2
- 3
1.10、查
语法:
SELECT field1, field2,...fieldN FROM table_name [WHERE Clause]
- 1
实际使用中最好不要使用select *的方式。
示例:
SELECT price FROM fly_table1 WHERE course='linux C/C++';
- 1
执行信息:
SELECT price FROM fly_table1 WHERE course='linux C/C++'
> OK
> 时间: 0.001 秒
- 1
- 2
- 3
1.11、去重的方式
(1)group by column。
(2)select distinct column。
1.12、条件判断类型
(1)… where condition。
(2)group by column having condition。
(3)… join … on condition。
其中,condition是条件,column是列名。
二、高级查询
做一下准备,为下面的查询操作建立数据库。
DROP TABLE IF EXISTS `class`; CREATE TABLE `class` ( `cid` int(11) NOT NULL AUTO_INCREMENT, `caption` varchar(32) NOT NULL, PRIMARY KEY (`cid`) ) ENGINE=innoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `student`; CREATE TABLE `student` ( `sid` int(11) NOT NULL AUTO_INCREMENT, `gender` char(1) NOT NULL, `class_id` int(11) NOT NULL, `sname` varchar(32) NOT NULL, PRIMARY KEY (`sid`), KEY `fk_class` (`class_id`), CONSTRAINT `fk_class` FOREIGN KEY (`class_id`) REFERENCES `class` (`cid`) ) ENGINE=innoDB AUTO_INCREMENT=17 DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `teacher`; CREATE TABLE `teacher` ( `tid` int(11) NOT NULL AUTO_INCREMENT, `tname` varchar(32) NOT NULL, PRIMARY KEY (`tid`) ) ENGINE=innoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `course`; CREATE TABLE `course` ( `cid` int(11) NOT NULL AUTO_INCREMENT, `cname` varchar(32) NOT NULL, `teacher_id` int(11) NOT NULL, PRIMARY KEY (`cid`), KEY `fk_course_teacher` (`teacher_id`), CONSTRAINT `fk_course_teacher` FOREIGN KEY (`teacher_id`) REFERENCES `teacher` (`tid`) ) ENGINE=innoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8; DROP TABLE IF EXISTS `score`; CREATE TABLE `score` ( `sid` int(11) NOT NULL AUTO_INCREMENT, `student_id` int(11) NOT NULL, `course_id` int(11) NOT NULL, `num` int(11) NOT NULL, PRIMARY KEY (`sid`), KEY `fk_score_student` (`student_id`), KEY `fk_score_course` (`course_id`), CONSTRAINT `fk_score_course` FOREIGN KEY (`course_id`) REFERENCES `course` (`cid`), CONSTRAINT `fk_score_student` FOREIGN KEY (`student_id`) REFERENCES `student` (`sid`) ) ENGINE=innoDB AUTO_INCREMENT=53 DEFAULT CHARSET=utf8;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
innoDB 有外键约束,myisam 注释的作用。
2.1、基础查询
-- 全部查询
SELECT * FROM student;
-- 只查询部分字段
SELECT `sname`, `class_id` FROM student;
-- 别名 列明 不要用关键字
SELECT `sname` AS '姓名' , `class_id` AS '班级ID'
FROM student;
-- 把查询出来的结果的重复记录去掉
SELECT distinct `class_id` FROM student;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.2、 条件查询
-- 查询姓名为 fly1 的学生信息
SELECT * FROM `student` WHERE `sname` = 'fly1';
-- 查询性别为 男,并且班级为 2 的学生信息
SELECT * FROM `student` WHERE `gender`="男" AND `class_id`=5;
- 1
- 2
- 3
- 4
2.3、范围查询
-- 查询班级id 1 到 3 的学生的信息
SELECT * FROM `student` WHERE `class_id` BETWEEN 1 AND 3;
- 1
- 2
2.4、判空查询
is null 判断造成索引失效。
# 索引 B+ 树
SELECT * FROM `student` WHERE `class_id` IS NOT NULL; #判断不为空
SELECT * FROM `student` WHERE `class_id` IS NULL;#判断为空
SELECT * FROM `student` WHERE `gender` <> '';
#判断不为空字符串
SELECT * FROM `student` WHERE `gender` = '';
#判断为空字符串
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.5、模糊查询
使用 like关键字,"%"代表任意数量的字符,”_”代表占位符。
-- 查询名字为 m 开头的学生的信息
SELECT * FROM `teacher` WHERE `tname` LIKE '谢%';
-- 查询姓名里第二个字为 小 的学生的信息
SELECT * FROM `teacher` WHERE `tname` LIKE '_小%';
- 1
- 2
- 3
- 4
2.6、分页查询
分页查询主要用于查看第N条 到 第M条的信息,通常和排序查询一起使用。
使用limit关键字,第一个参数表示从条记录开始显示,第二个参数表示要显示的数目。表中默认第一条记录的参数为0。
-- 查询第二条到第三条内容
SELECT * FROM `student` LIMIT 1,2;
- 1
- 2
2.7、查询后排序
关键字:order by field。
asc:升序。
desc:降序
SELECT * FROM `score` ORDER BY `num` ASC;
-- 按照多个字段排序
SELECT * FROM `score` ORDER BY `course_id` DESC,`num` DESC;
- 1
- 2
- 3
2.8、聚合查询
| 聚合函数 | 描述 |
|---|---|
| sum() | 计算某列的总和 |
| avg() | 计算某列的平均值 |
| max() | 计算某列的最大值 |
| min() | 计算某列的最小值 |
| count() | 计算某列的行数 |
SELECT sum(`num`) FROM `score`;
SELECT avg(`num`) FROM `score`;
SELECT max(`num`) FROM `score`;
SELECT min(`num`) FROM `score`;
SELECT count(`num`) FROM `score`;
- 1
- 2
- 3
- 4
- 5
2.9、分组查询
分组加group_concat。
-- 分组加group_concat
SELECT `gender`, group_concat(`age`) as ages FROM `student` GROUP BY `gender`;
-- 可以把查询出来的结果根据某个条件来分组显示
SELECT `gender` FROM `student` GROUP BY `gender`;
-- 分组加聚合
SELECT `gender`, count(*) as num FROM `student` GROUP BY `gender`;
-- 分组加条件
SELECT `gender`, count(*) as num FROM `student` GROUP BY `gender` HAVING num > 6;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
三、联表查询
可以把表想象成集合。
联表查询分为内联(inner join)和外联(left join,right join,full join)。内联类似交集,full join类似并集。
如果只写了join,那么默认是内联。
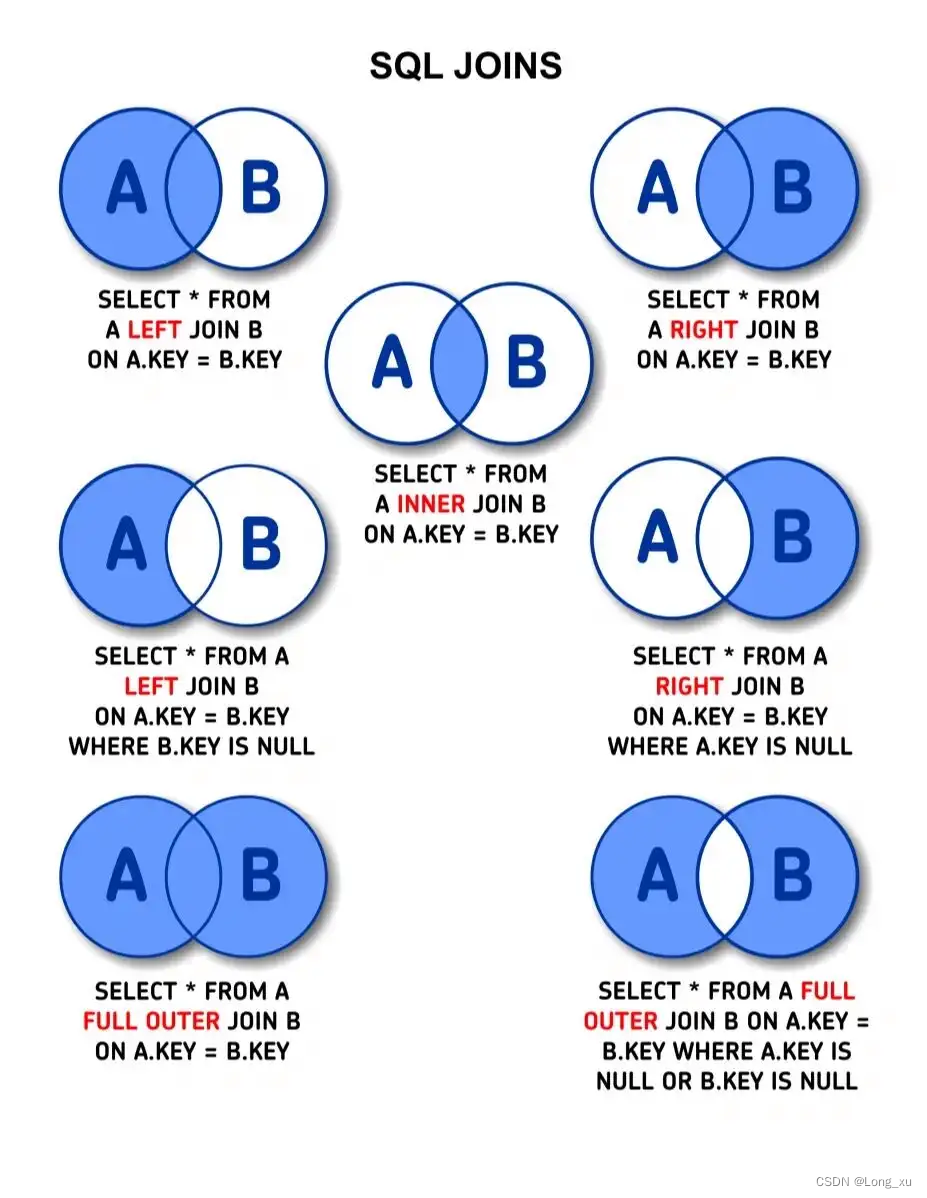
3.1、INNER JOIN
只取两张表有对应关系的记录。
SELECT cid FROM `course` INNER JOIN `teacher` ON course.teacher_id = teacher.tid;
- 1
3.2、LEFT JOIN
在内连接的基础上保留左表没有对应关系的记录。
select course.cid from `course` left join `teacher` on course.teacher_id = teacher.tid;
- 1
3.3、RIGHT JOIN
在内连接的基础上保留右表没有对应关系的记录。
select course.cid from `course` right join `teacher` on course.teacher_id = teacher.tid;
- 1
四、子查询/合并查询
4.1、单行子查询
select * from course where teacher_id = (select tid from teacher where tname = 'lucien')
- 1
4.2、多行子查询
多行子查询即返回多行记录的子查询。
IN 关键字:运算符可以检测结果集中是否存在某个特定的值,如果检测成功就执行外部的查询。
EXISTS 关键字:内层查询语句不返回查询的记录。而是返回一个真假值。如果内层查询语句查询到满足条件的记录,就返回一个真值( true ),否则,将返回一个假值( false )。当返回的值为 true 时,外层查询语句将进行查询;当返回的为false 时,外层查询语句不进行查询或者查询不出任何记录。
ALL 关键字:表示满足所有条件。使用 ALL 关键字时,只有满足内层查询语句返回的所有结果,才可以执行外层查询语句。
ANY 关键字:允许创建一个表达式,对子查询的返回值列表,进行比较,只要满足内层子查询中的,任意一个比较条件,就返回一个结果作为外层查询条件。
在 FROM 子句中使用子查询:子查询出现在 from 子句中,这种情况下将子查询当做一个临时表使用。
示例:
select * from student where class_id in (select cid from course where teacher_id = 6);
select * from student where exists(select cid from course where cid = 5);
select student_id,sname FROM (SELECT * FROM score WHERE course_id = 5 OR course_id = 2) AS A LEFT JOIN student ON A.student_id = student.sid;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
4.3 正则表达式
使用关键字:REGEXP。
| 选项 | 说明(自动加匹配二字) | 例子 | 匹配值示例 |
|---|---|---|---|
| ^ | 文本开始字符 | '^b’匹配以字母b开头的字符串 | book, big,banana,bike |
| . | 任何单个字符 | 'b.t’匹配任何b和t之间有一个字符 | bit, bat,but, bite |
| * | 0个或多个在它前面的字符 | 'f*n’匹配字符n前面有任意多个字符f | fn, fan,faan, abcn |
| + | 前面的字符一次或多次 | 'ba+'匹配以b开头后面紧跟至少一个a | ba, bay,bare, battle |
| <字符串> | 包含指定字符串的文本 | ‘fa’ | fan, afa,faad |
| [字符集合] | 字符集合中的任一个字符 | '[xz]'匹配x或者z | dizzy,zebra, xray,extra |
| [^] | 不在括号中的任何字符 | '[^abc]'匹配任何不包含a、b或c的字符串 | desk, fox,f8ke |
| 字符串{n} | 前面的字符串至少n次 | b{2}匹配2个或更多的b | bbb, bbbb,bbbbbb |
| 字符串{n,m} | 前面的字符串至少n次,至多m次 | b{2,4}匹配最少2个,最多4个b | bb, bbb,bbbb |
SELECT * FROM `teacher` WHERE `tname` REGEXP '^long';
- 1
总结
- 在实际使用中最好不要使用select *的方式查询数据,这种查询方式既不好分析数据,也会使查询效率降低。
- SQL查询中,如果不清楚名称是不是关键字,最好使用反引号括起来,避免在词法语法分析时被当成关键字处理。
- group by会去重,group_concat会分组。


