
热门标签
热门文章
- 1数据结构——二叉树_采用二叉链表存储结构,visit是对数据元素操作的应用函数。 中序遍历二叉树t的递归
- 2postgresql触发器_postgre 触发器能同时写之前和之后吗?
- 3浅谈机器学习(第一章基本概念)_特征空间
- 4uni-app(微信小程序) 特定页面生成小程序码或小程序二维码(带参数)_uniapp 生成小程序二维码
- 5云计算学习之路—云计算基础—Linux文件管理命令_云计算cp -p命令怎么用
- 6git commit --amend 与git commit -m 的区别以及用法_git commit --amend -m
- 7【InternVL 1.5】最强开源多模态大模型(性能比肩GPT-4V)_intervl多模态模型
- 8基于web场馆预约管理系统(JSP+java+springmvc+mysql+MyBatis)_基于web的预约排队系统
- 9字节跳动后端实习面试经验_字节跳动 算法题 大富翁游戏 房子租金最小花费
- 10苹果电脑畅玩《魔兽世界巫妖王之怒》怀旧服国服 苹果电脑怎么玩魔兽世界手游?PD虚拟机能玩魔兽世界吗 Mac运行Windows游戏_苹果可以玩《魔兽世界》“巫妖王之怒”
当前位置: article > 正文
Python-drop_duplicates_dropduplicates 方法的作用
作者:码创造者 | 2024-06-26 16:07:01
赞
踩
dropduplicates 方法的作用
drop_duplicate方法是对DataFrame格式的数据,去除特定列下面的重复行。返回DataFrame格式的数据
df.drop_duplicates(keep= , subset=[], inplace= )
- 1
keep: {‘first’, ‘last’, False},默认为’first’
保留项。保留第一个(first)/最后一个(last)/不保留(False)重复的项
subset:默认所有列
指定的列。即需要删除哪些列中重复的项,列用’'说明,用,隔开
inplace : {‘True’,‘False’},默认为False
是否在原数据上修改。False表示另存一个副本
下面以例子来说明:
新建一个表格示例数据如下
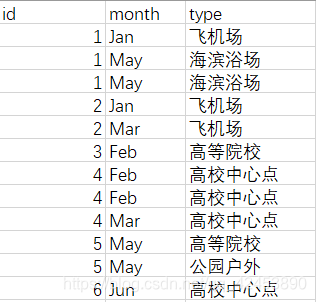
1.删除重复行
删除type中重复的项,并保留第一次出现的数据
df.drop_duplicates(keep='first', subset=['type'])
- 1

删除month和type中同时重复的项,并保留最后一次出现的数据
df.drop_duplicates(keep='last', subset=['type', 'month'])
- 1

2.保留不重复行
保留id只出现过一次的数据
df.drop_duplicates(keep=False, subset=['id'])
- 1

3.保留重复行
保留id重复的数据
首先将2中不重复的数据保存,再从原始数据中删除2的数据
# 只出现一次的元素
output1 = df.drop_duplicates(keep=False, subset=['id'])
output1.to_csv('E:\\output1.csv', encoding='utf-8-sig', index=True)
output2 = df
# 删除output1中的元素
for i in range(0, len(output1)):
output2.drop([output1.index[i]], inplace=True)
output2.to_csv('E:\\output2.csv', encoding='utf-8-sig', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

完整代码
import pandas as pd
beer = pd.read_csv("E:\\test.csv", encoding='utf-8-sig', low_memory=False)
df = pd.DataFrame(beer)
output1 = df.drop_duplicates(...)
output1.to_csv('E:\\output1.csv', encoding='utf-8-sig', index=True)
output2 = df
for i in range(0, len(output1)):
output2.drop([output1.index[i]], inplace=True)
output2.to_csv('E:\\output2.csv', encoding='utf-8-sig', index=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/759826
推荐阅读

相关标签

