
- 1Python游戏汇总:三十个pygame游戏代码【附源码免费分享】_游戏代码大全可复制
- 2Excel导入后的后台响应数据前端已经接收但是响应不出来_springblade使用easyexcel导入后往前端发送成功消息但前端不提示
- 3sqlserver 死锁总结_sqlserver 死锁后 超时机制
- 4【例子】webpack 开发一个可以加载 markdown 文件的加载器 loader 案例
- 5Yoshua Bengio、吴恩达等AI巨擘预见2022年人工智能趋势_多模态ai 吴恩达
- 6算法篇——素数筛
- 7从写简历,到面试,到谈薪酬的那些技巧和防坑指南
- 8【物联网】ROM、RAM和FLASH的区别_flash和rom
- 9java 加入音乐_如何实现java插入背景音乐
- 10数据结构与算法6:八大排序算法总结_最好情况交换次数最少的排序
ICLR 2023 神经规范场: 渲染引导空间规范变换
赞
踩
关注公众号,发现CV技术之美
近期,神经场(Neural Fields)领域的巨大进展,已经显著推动了神经场景表示和神经渲染的发展。为了提高3D场景的计算效率和渲染质量,一个常见的范式是将3D坐标系统映射到另一种测量系统,例如2D流形和哈希表,以建模神经场。
本文将这种坐标或者测量系统的转换定义为“规范变换”(gauge transformation)。这种规范变换通常采用预定义的函数,例如EG3D中的垂直投影和Instant-NGP中的空间哈希函数。然而,这种预先定义的函数往往并非最优选择,所以一个很自然的问题浮现出来:是否能以端到端的方式直接学习规范变换,让它与神经场一同进行优化?
本研究将此问题拓展为一个广义的范式,包括连续型和离散型规范变换,并设计了统一的学习框架以共同优化规范变换和神经场。

论文地址:https://arxiv.org/abs/2305.03462
GitHub地址:https://github.com/fnzhan/Neural-Gauge-Fields
项目地址:https://fnzhan.com/Neural-Gauge-Fields/
介绍
规范通常表示一种测量标准或测量系统,比如温度测量中的华氏度和摄氏度。而两种规范之间的转换则被称为规范变换,比如华氏度和摄氏度之间的转换。在物理领域中,各种坐标系统的变换也可以被称之为规范变换,如图一所示的局部和总体的规范变换。
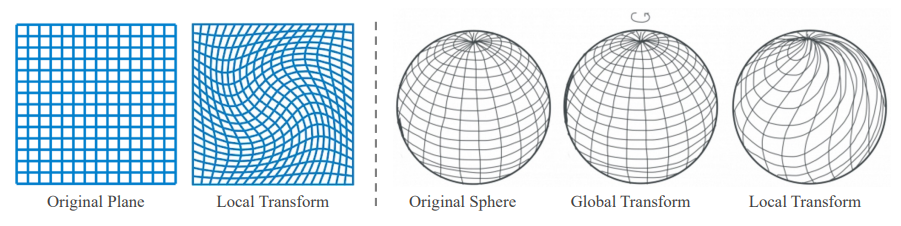
而在神经场领域中,规范变换的定义可以进一步扩展为连续变换和离散变换,如图二。
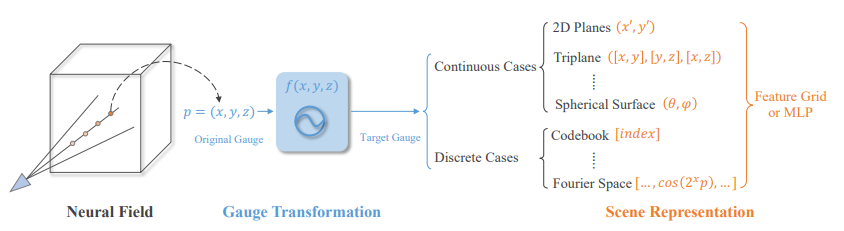
连续规范变换:如果目标规范(测量系统)是连续的,那么这种变换定义为连续规范变换。这种连续规范变换,基本等同于坐标变换。对于一个原始3D空间中的点x,可以通过一个神经网络M对它进行规范变换,从而得到它在目标规范中的新坐标即M(x)或者x+M(x)。这个新坐标可以用来索引神经场,包括隐式神经场(MLP-based)和显式神经场(grid-based)。连续规范变换的典型应用包括UV纹理映射和学习TriPlane映射。
对于UV纹理映射,规范变换具体定义为3D空间到2D UV空间的映射,由于神经场是在2D UV空间进行索引,所以我们通过在UV空间进行均匀点采样可以得到每个点的颜色,从而得到显式的UV,同时可以对2D UV进行编辑(如图)。

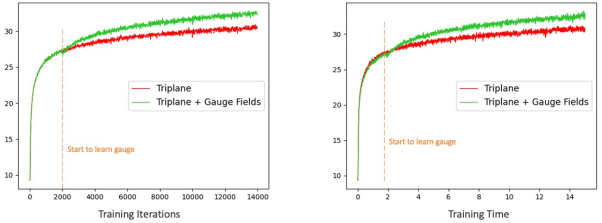
对于TriPlane映射也是类似,我们采用三个单独的网络来分别学习3D空间到2D平面的映射。我们发现这种可学习的变换可以提升TriPlane神经场的渲染效果和模型收敛速度,如图四所示。
以上只是列举出两种应用,实际上这种可学习的连续规范变换可以根据目的灵活地嵌入到各种NeRF模型当中,比如动态场景NeRF,和基于NeRF的本征分解。
离散规范变换:如果目标规范是离散的(比如哈希表空间),那么这种变换定义为离散规范变换。由于离散空间的索引参数是离散的,我们不能像连续规范变换那样直接通过网络预测索引参数值。
所以,对于3D空间中的一个点x,我们用神经网络预测这个点在哈希表上的离散概率分布,然后通过Top-1操作得到最大概率点对应的哈希表索引。由于Top-1操作是不可微分的,所以需要通过重参数技巧来得到近似梯度进行模型优化,算法流程图五所示。

离散规范的主要应用包括Instant-NGP的模型压缩,可泛化NeRF等。对于可泛化NeRF,由于哈希映射变得可学习,所以多个场景都可以学习映射到同一个哈希表中,从而实现场景泛化NeRF。
可视化分析
尽管证明了学习规范变换是可行的,但是学习到的规范变换具体遵循什么样的规律依然不清楚,所以这里对学习到的规范变换进行了可视化。对于3D空间和2D流形(球面或者平面)的规范变换,我们学习一个逆映射将2D流形上均匀采样的点投影到3D空间,如图六所示。
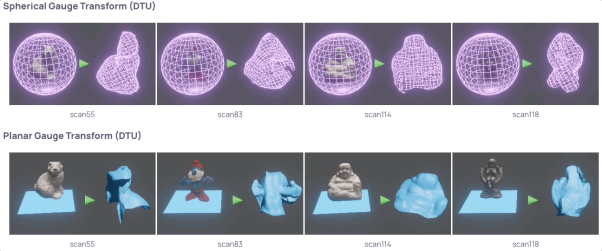
通过观察,我们发现学习到的规范变换和场景的几何(或者说密度)有很明显的关系,物体表面的点(也就是密度比较大的点)会被很好地投影到目标平面即占有率很高,而密度小的点所在空间会被高度压缩并在目标平面只有很低的占有率。
这个结果也符合直觉:物体表面对渲染结果影响最大,所以渲染损失函数倾向于让物体表面更多地占用目标平面的特征,同时压缩对渲染影响很小的低密度空间。
信息不变性规范
理想情况下,我们期望3D空间信息能在规范变换中保证保持不变(Information Invariant, or InfoInv),一般情况下这个很难实现,这里我们通过推导证明了神经场中的位置编码实际上实现了规范变换中的相对信息不变性,从而有助于神经场建模。而本质上,这种不变性规范是对神经场坐标施加了一个相位变换θ :
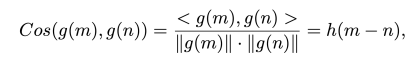
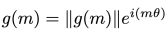
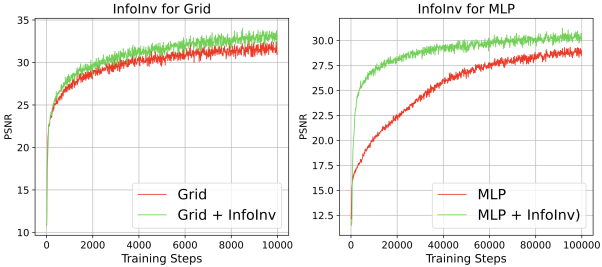
如图七所示,将位置编码简单地和Grid或者MLP-based神经场结合都能显著提高模型效果。近期的PET-NeuS等工作也证明了这种方法的有效性。
总结
这篇文章主要介绍了神经场中的规范变换,尤其是如何通过渲染损失联合优化神经场景表示和规范变换。通过应用和实验,证明了这种可学习规范变换的优点和广泛适用性,包括UV映射,TriPlane神经场等。基于这种可学习的规范变换,还有大量神经渲染任务值得深入探索和应用。

END
欢迎加入「神经场」交流群
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

