
- 1华为OD机试D卷 - 字符串变换最小字符串 - 免费看解析和代码_python 给定一个字符串s,最多只能进行一次变换
- 2政安晨的机器学习笔记——快速理解AI中的ML与DL概念_ai dl
- 3UMG 常用方法_loadclass
(nullptr, - 4机器学习python实践——关于数据集划分和数据标准化的相关问题的思考
- 5时序违例的解决思路_不同时钟 时序违例
- 6构建第一个ArkTS之页面和自定义组件生命周期
- 7windows server 2019-搭建文件共享服务器_windows sever2019服务器创建共享文件夹
- 8【干货】什么是CPU,GPU,ASIC和FPGA?_asic cpu
- 9深入分析 Android Service (六)(完)
- 10Android性能测试 之 APP&FPS的方法_安卓性能分析fpsgo
【AI】金融FinGPT模型_fingpt部署
赞
踩
金融FinGPT模型开源,对标BloombergGPT,训练参数可从61.7亿减少为367万,可预测股价
继Bloomberg提出了500亿参数的BloombergGPT,GPT在金融领域的应用受到了广泛关注,但BloombergGPT是一个非开源的模型,而且用到了Bloomberg自身独有的数据储备,并不利于金融大模型的广泛普及。
FinGPT: Open-Source Financial Large Language Models
Hongyang Yang, Xiao-Yang Liu, Christina Dan Wang

1、完全开源:开源的训练数据、开源的模型。
2、数据中心化:尽管没有Bloomberg用到的独有数据,但FinGPT所用的所有数据都被集中、严格地清洗,保证了数据的质量,并向大众开放。
3、端到端的设计:包括输入层、数据加工层、大语言模型微调层和应用层。
4、BloombergGPT中缺少人类反馈强化学习,但这是GPT模型成功的关键,而FinGPT应用了这项技术。
5、轻量级的部署和微调,为了普及金融大模型,降低应用成本,应用了the Low-Rank Adaptation (LoRA) of LLMs技术,将可训练参数从61.7亿减少为367万。
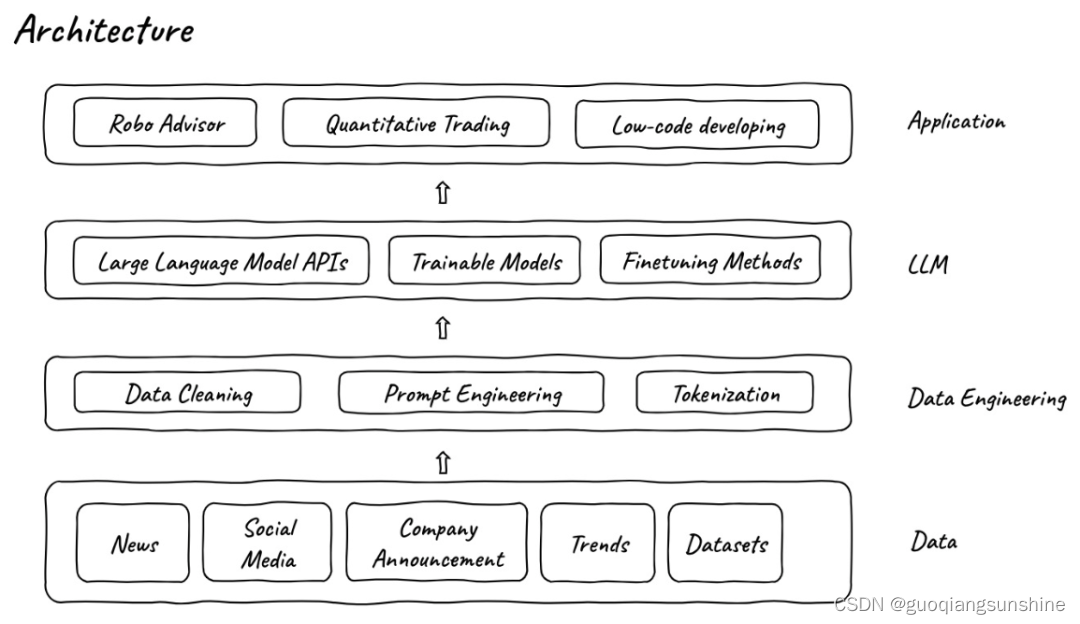
FinGPT运用了各种各样的金融训练数据,包括金融新闻、公司公告、社交媒体、金融专业网站、学术资料等,多种多样的数据保证了FinGPT可以理解金融市场和做出金融决策。
值得注意的是,FInGPT提供了一套完善的机制应对实时数据,做出实时决策;使用者也可以很轻松地对下游任务进行微调。
还可以微调FinGPT来预测股价,由于股价预测任务微调时可以简单利用股价变动作为反馈,因此微调成本相对其它需要人类反馈的任务低得多。

