- 1重温CLR(十二) 委托
- 2LLM大模型实战项目--基于Stable Diffusion的电商平台虚拟试衣
- 3GPT-4o mini 比gpt-3.5更便宜(2024年7月18日推出)
- 4Git实战攻略:分支、合并与提交技巧_git合并分支提交分支
- 5银河麒麟V10桌面操作系统安装教程_银河麒麟操作系统v10
- 6tensorflow 车牌识别项目(一)_车牌定位的标签文件时json吗
- 7单链表(二)_建立一个非递减有序单链表(不少于5个元素结点),输出该链表中重复的元素以及重复次
- 8在安卓手机上用termux安装完整kali linux的办法_安卓完整linux
- 9 [推荐]dotNET中进程间同步/通信的经典框架_christoph ruegg
- 10平衡二叉树与java实现_java实现平衡二叉树
HADOOP安装详细步骤_hadoop安装配置步骤
赞
踩
SSH无密码登录
关闭防火墙,安全上下文,改虚拟机名
改虚拟机名
虚拟机master:
[root@localhost ~]# hostnamectl set-hostname master
[root@localhost ~]# bash
[root@master ~]# hostname
master
虚拟机slava1:
[root@localhost ~]# hostnamectl set-hostname slava1
[root@localhost ~]# bash
[root@ slava1 ~]# hostname
slava1
虚拟机slava2:
[root@localhost ~]# hostnamectl set-hostname slava2
[root@localhost ~]# bash
[root@ slava2 ~]# hostname
Slava2
防火墙关闭:
[root@master ~]# systemctl stop firewalld
[root@master ~]# systemctl disable firewalld

安全上下文关闭:
vim /etc/sysconfig/selinux
修改
Selinux=disabled
查看 SSH 服务状态及创建hadoop用户
[root@master ~]# systemctl status sshd
创建用户:
[root@master ~]# useradd hadoop
[root@master ~]# echo "1" |passwd --stdin hadoop

卸载自带 OpenJDK及安装并设置JDK
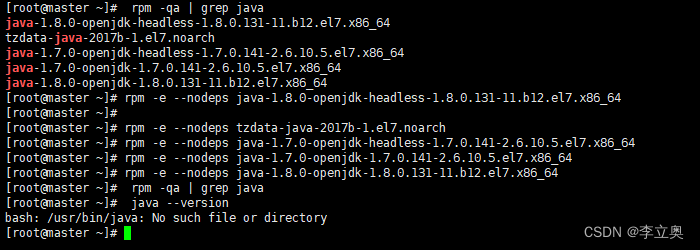
[root@master ~]# rpm -qa | grep java
然后删除查询出来的软件包
导入jdk安装包到/opt/software下
解压安装包
[root@master~]#tar -zxvf /opt/software/jdk-8u152-linux-x64.tar.gz –C /usr/local/src/
[root@master ~]# ls /usr/local/src/
jdk1.8.0_152
修改jdk配置文件:
[root@master ~]# vi /etc/profile
在文件的最后增加如下两行:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152export
PATH=$PATH:$JAVA_HOME/bin
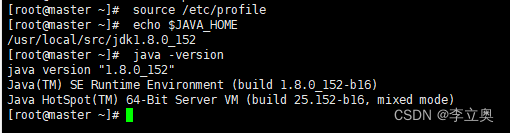
执行source /etc/profile使其生效
检查 JAVA 是否可用。
[root@master ~]# echo $JAVA_HOME/usr/local/src/jdk1.8.0_152
[root@master ~]# java -version
java version "1.8.0_152"
安装hadoop软件包并修改配置文件
将hadoop-2.7.1.tar.gz压缩包导入到/opt/software内
解压安装包:
[root@master ~]# tar -zxvf /opt/software/hadoop-2.7.1.tar.gz –C /usr/local/src/
[root@master ~]# ll /usr/local/src/
配置 Hadoop 环境变量
[root@master ~]# vi /etc/profile
在文件的最后增加如下两行:
exportHADOOP_HOME=/usr/local/src/hadoop-2.7.1export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
执行source /etc/profile使其生效
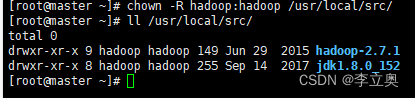
Hadoop 软件的所有者改为 hadoop 用户。
[root@master ~]# chown -R hadoop:hadoop /usr/local/src/
[root@master ~]# ll /usr/local/src/
总用量 0
drwxr-xr-x. 9 hadoop hadoop 149 6月 29 2015 hadoop-2.7.1
drwxr-xr-x. 8 hadoop hadoop 255 9月 14 2017 jdk1.8.0_152
配置 Hadoop 配置文件
[root@master ~]# cd /usr/local/src/hadoop-2.7.1/
[root@master hadoop-2.7.1]# ls
bin etc include lib libexec LICENSE.txt NOTICE.txt README.txt sbin share
[root@master hadoop-2.7.1]# vi etc/hadoop/hadoop-env.sh
在文件中查找 export JAVA_HOME 这行,将其改为如下所示内容:
export JAVA_HOME=/usr/local/src/jdk1.8.0_152

切换到hadoop用户下,在~/目录下创建input目录,再其中在创建数据文件data.txt,输入如下内容:
Hello World
Hello Hadoop
Hello Husan
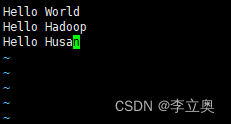
测试 MapReduce 运行:
[hadoop@master~]$hadoop jar /usr/local/src/hadoop2.7.1/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jarwordcount ~/input/data.txt ~/output
Hadoop平台环境配置
[root@master ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2

[root@slave1 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2
[root@slave2 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain428
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.47.140 master
192.168.47.141 slave1
192.168.47.142 slave2
SSH 无密码验证配置:
[root@master ~]# rpm -qa | grep openssh
openssh-server-7.4p1-11.el7.x86_64
openssh-7.4p1-11.el7.x86_64
openssh-clients-7.4p1-11.el7.x86_64
[root@master ~]# rpm -qa | grep rsync
rsync-3.1.2-11.el7_9.x86_64
查看有没有如上几个包,如果没有就下载
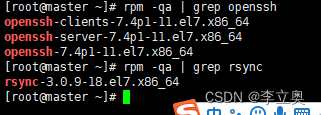
将master,slave1,slave2都转到用户hadoop下
在master,slave1,slave2上都执行如下命令:
ssh-keygen –t rsa
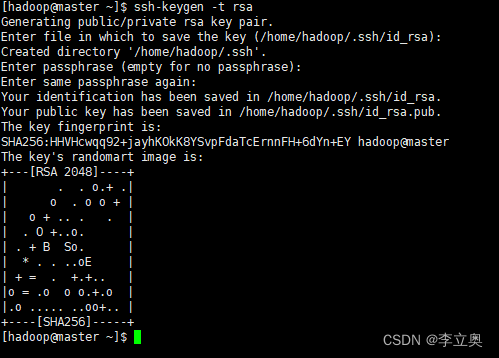
查看~/下有没有".ssh"文件夹
[hadoop@master ~]$ ls ~/.ssh/
id_rsa id_rsa.pub
在master,slave1,slave2上将 id_rsa.pub 追加到授权 key 文件中
[hadoop@master ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@master ~]$ ls ~/.ssh/
authorized_keys id_rsa id_rsa.pub

在master,slave1,slave2上修改文件权限
chmod 600 ~/.ssh/authorized_keys
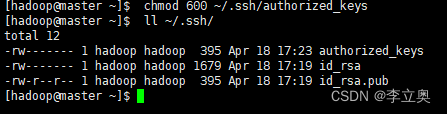
在master,slave1,slave2上管理员root下:
[root@master ~]# vi /etc/ssh/sshd_config
PubkeyAuthentication yes 找到此行,并把#号注释删除。

重启 SSH 服务,并切换到hadoop用户下验证能否嵌套登录本机,若可以不输入密码登录,则本机通过密钥登录认证成功。
交换 SSH 密钥
[hadoop@master ~]$ scp ~/.ssh/id_rsa.pub hadoop@slave1:~/
[hadoop@master ~]$ scp ~/.ssh/id_rsa.pub hadoop@slave2:~/
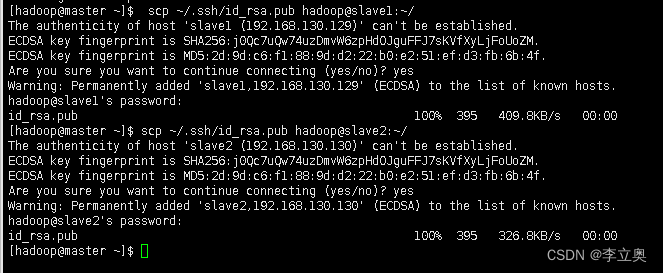
[hadoop@slave1 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@slave1 ~]$ rm -rf ~/id_rsa.pub

[hadoop@slave2 ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@slave2 ~]$ rm -rf ~/id_rsa.pub

将每个 Slave 节点的公钥保存到 Master
[hadoop@slave1 ~]$ scp ~/.ssh/id_rsa.pub hadoop@master:~/
[hadoop@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@master ~]$ rm -rf ~/id_rsa.pub
想做以上几步,在做以下几步
[hadoop@slave2 ~]$ scp ~/.ssh/id_rsa.pub hadoop@master:~/
[hadoop@master ~]$ cat ~/id_rsa.pub >>~/.ssh/authorized_keys
[hadoop@master ~]$ rm -rf ~/id_rsa.pub
验证 SSH 无密码登录
[hadoop@master ~]$ cat ~/.ssh/authorized_keys
查看返回值中有没有master,slave1,slave2
[hadoop@slave1 ~]$ cat ~/.ssh/authorized_keys
查看返回值中有没有master,slave1
[hadoop@slave2 ~]$ cat ~/.ssh/authorized_keys
查看返回值中有没有master,slave2

验证 Master 到每个 Slave 节点无密码登录
[hadoop@master ~]$ ssh slave1
Last login: Mon Nov 14 16:34:56 2022
[hadoop@slave1 ~]$
[hadoop@master ~]$ ssh slave2
Last login: Mon Nov 14 16:49:34 2022 from 192.168.47.140
[hadoop@slave2 ~]$
验证两个 Slave 节点到 Master 节点无密码登录
[hadoop@slave1 ~]$ ssh master
Last login: Mon Nov 14 16:30:45 2022 from ::1
[hadoop@master ~]$
[hadoop@slave2 ~]$ ssh master
Last login: Mon Nov 14 16:50:49 2022 from 192.168.47.141
[hadoop@master ~]$

配置两个子节点slave1、slave2的JDK环境。
[root@master ~]# cd /usr/local/src/
[root@master src]# ls
hadoop-2.7.1 jdk1.8.0_152
[root@master src]# scp -r jdk1.8.0_152 root@slave1:/usr/local/src/
[root@master src]# scp -r jdk1.8.0_152 root@slave2:/usr/local/src/

[root@slave1 ~]# ls /usr/local/src/
jdk1.8.0_152
[root@slave1 ~]# vi /etc/profile
#此文件最后添加下面两行
export JAVA_HOME=/usr/local/src/jdk1.8.0_15237
export PATH=$PATH:$JAVA_HOME/bin
[root@slave1 ~]# source /etc/profile
root@slave1 ~]# java –version
java version "1.8.0_152"

[root@slave2 ~]# ls /usr/local/src/
jdk1.8.0_152
[root@slave2 ~]# vi /etc/profile
#此文件最后添加下面两行
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
[root@slave2 ~]# source /etc/profile
[root@slave2 ~]# java –version
java version "1.8.0_152"
Hadoop集群运行
在 Master 节点上安装 Hadoop
将 hadoop-2.7.1 文件夹重命名为 Hadoop
[root@master ~]# cd /usr/local/src/
[root@master src]# mv hadoop-2.7.1 hadoop
[root@master src]# ls hadoop
jdk1.8.0_152
配置 Hadoop 环境变量
[root@master src]# vim /etc/profile
在最后添加以下四行
export JAVA_HOME=/usr/local/src/jdk1.8.0_152export
PATH=$PATH:$JAVA_HOME/binexport
HADOOP_HOME=/usr/local/src/hadoopexport PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
切换到hadoop用户下使环境变量生效
[root@master src]# cd /usr/local/src/hadoop/etc/hadoop/
[root@master hadoop]# vim hadoop-env.sh
#修改以下配置
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
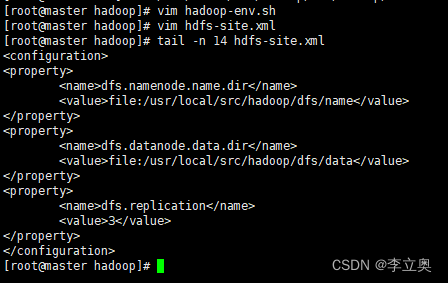
配置 hdfs-site.xml 文件参数
[root@master hadoop]# vim hdfs-site.xml
#编辑以下内容
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
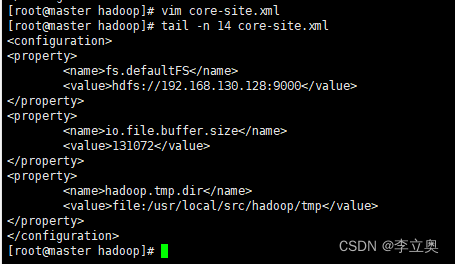
配置 core-site.xml 文件参数
[root@master hadoop]# vim core-site.xml
#编辑以下内容
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.130.128:9000</value> 注意其中的ip地址
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop/tmp</value>
</property>
</configuration>
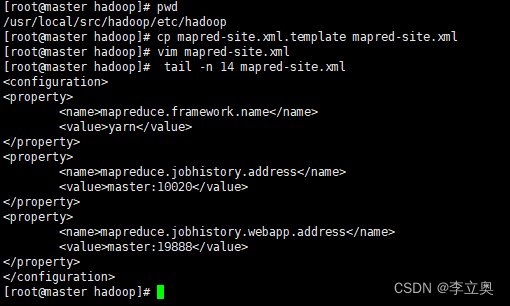
配置 mapred-site.xml
[root@master hadoop]# pwd
/usr/local/src/hadoop/etc/hadoop
[root@master hadoop]# cp mapred-site.xml.template mapred-site.xml
[root@master hadoop]# vim mapred-site.xml
#添加以下配置
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置 yarn-site.xml
[root@master hadoop]# vim yarn-site.xml
#添加以下配置
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name
><value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
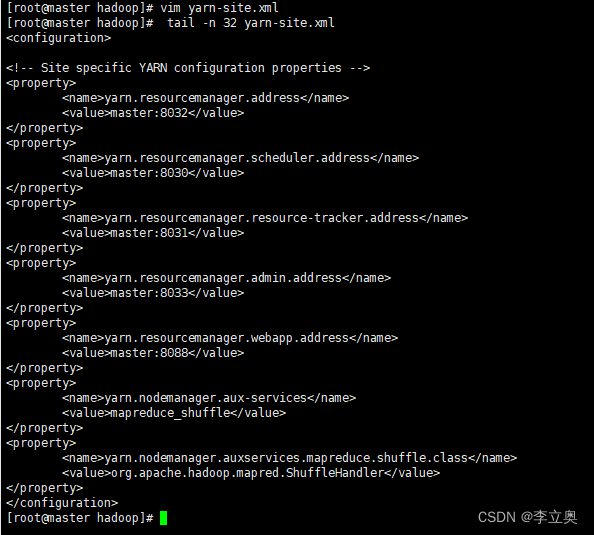
Hadoop 其他相关配置
配置 masters 文件,添加master的ip地址
[root@master hadoop]# vim masters
[root@master hadoop]# cat masters
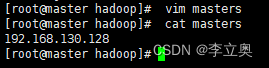
配置 slaves 文件,添加slave1,slave2的ip地址
[root@master hadoop]# vim slaves
[root@master hadoop]# cat slaves
新建以下几个目录
[root@master hadoop]# mkdir /usr/local/src/hadoop/tmp
[root@master hadoop]# mkdir /usr/local/src/hadoop/dfs/name -p
[root@master hadoop]# mkdir /usr/local/src/hadoop/dfs/data -p

修改目录权限
[root@master hadoop]# chown -R hadoop:hadoop /usr/local/src/hadoop/

同步配置文件到 Slave 节点
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave1:/usr/local/src/
[root@master ~]# scp -r /usr/local/src/hadoop/ root@slave2:/usr/local/src/
slave1 配置
[root@slave1 ~]# yum install -y vim
[root@slave1 ~]# vim /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@slave1 ~]# chown -R hadoop:hadoop /usr/local/src/hadoop/
[hadoop@slave1 ~]$ source /etc/profile
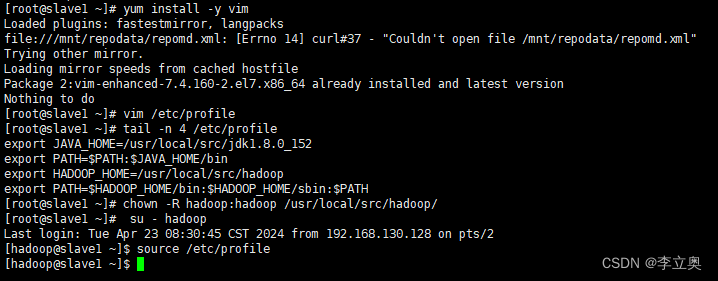
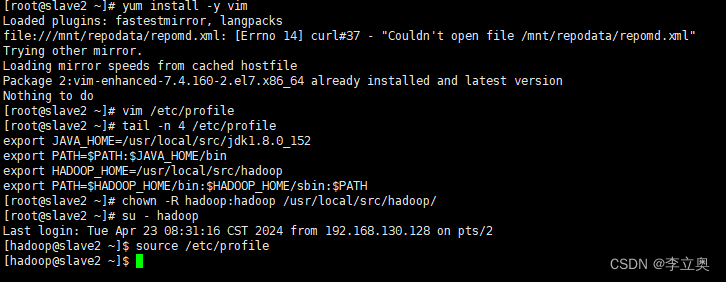
slave2 配置
[root@slave2 ~]# yum install -y vim
[root@slave2 ~]# vim /etc/profile
[root@slave2 ~]# tail -n 4 /etc/profile
export JAVA_HOME=/usr/local/src/jdk1.8.0_152
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/usr/local/src/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
[root@slave2 ~]# chown -R hadoop:hadoop /usr/local/src/hadoop/
[root@slave2 ~]# su - hadoop
[hadoop@slave2 ~]$ source /etc/profile
hadoop 集群运行
配置 Hadoop 格式化
NameNode 格式化
执行如下命令,格式化 NameNode
[root@master ~]# su - hadoop
[hadoop@master ~]# cd /usr/local/src/hadoop/
[hadoop@master hadoop]$ bin/hdfs namenode –format
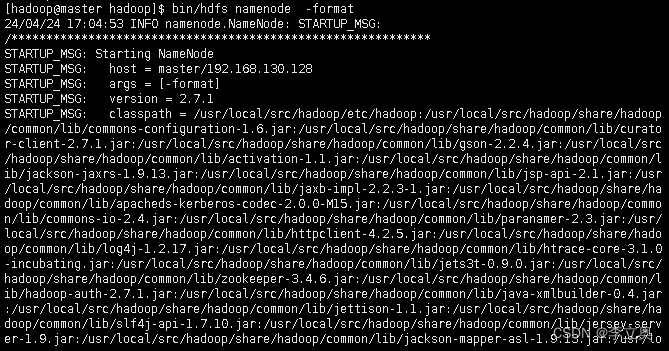
启动 NameNode
执行如下命令,启动 NameNode:
[hadoop@master hadoop]$ hadoop-daemon.sh start namenode

查看 Java 进程
[hadoop@master hadoop]$ jps
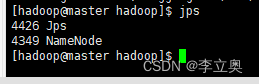
slave节点 启动 DataNode
[hadoop@slave1 hadoop]$ hadoop-daemon.sh start datanode
[hadoop@slave1 hadoop]$ jps

[hadoop@slave2 hadoop]$ hadoop-daemon.sh start datanode
[hadoop@slave2 hadoop]$ jps

启动 SecondaryNameNode
[hadoop@master hadoop]$ hadoop-daemon.sh start secondarynamenode
[hadoop@master hadoop]$ jps

查看 HDFS 数据存放位置
[hadoop@master hadoop]$ ll dfs/
[hadoop@master hadoop]$ ll ./tmp/dfs
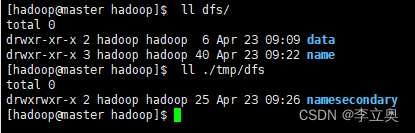
查看报告
[hadoop@master sbin]$ hdfs dfsadmin -report
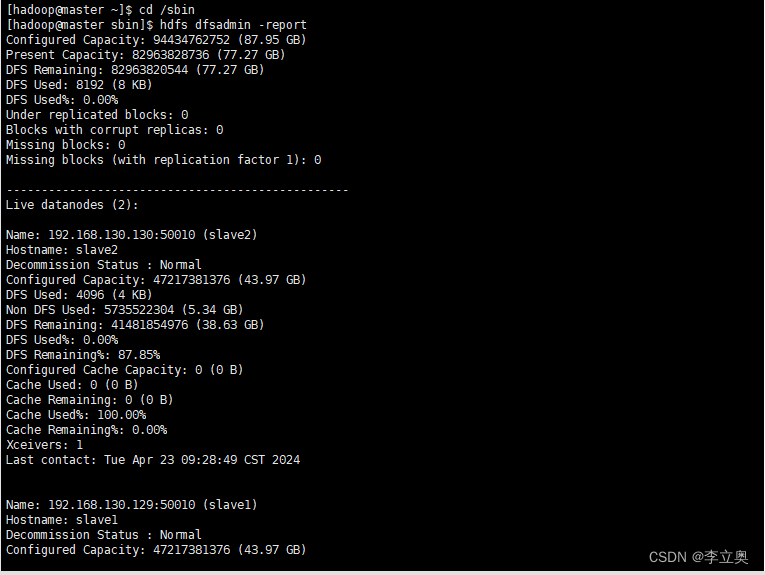
使用浏览器查看节点状态
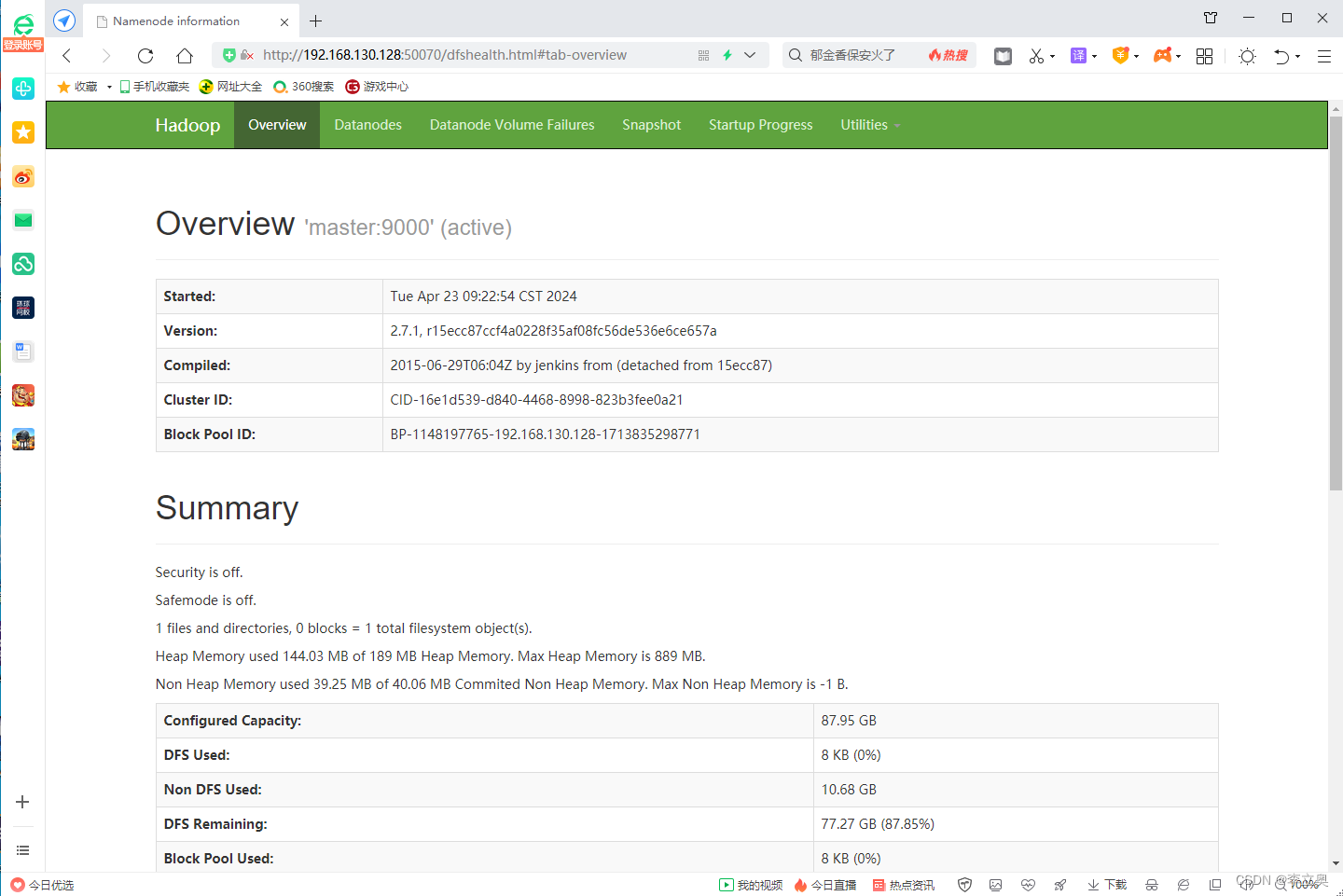
在浏览器的地址栏输入http://master:50070,进入页面可以查看NameNode和DataNode 信息
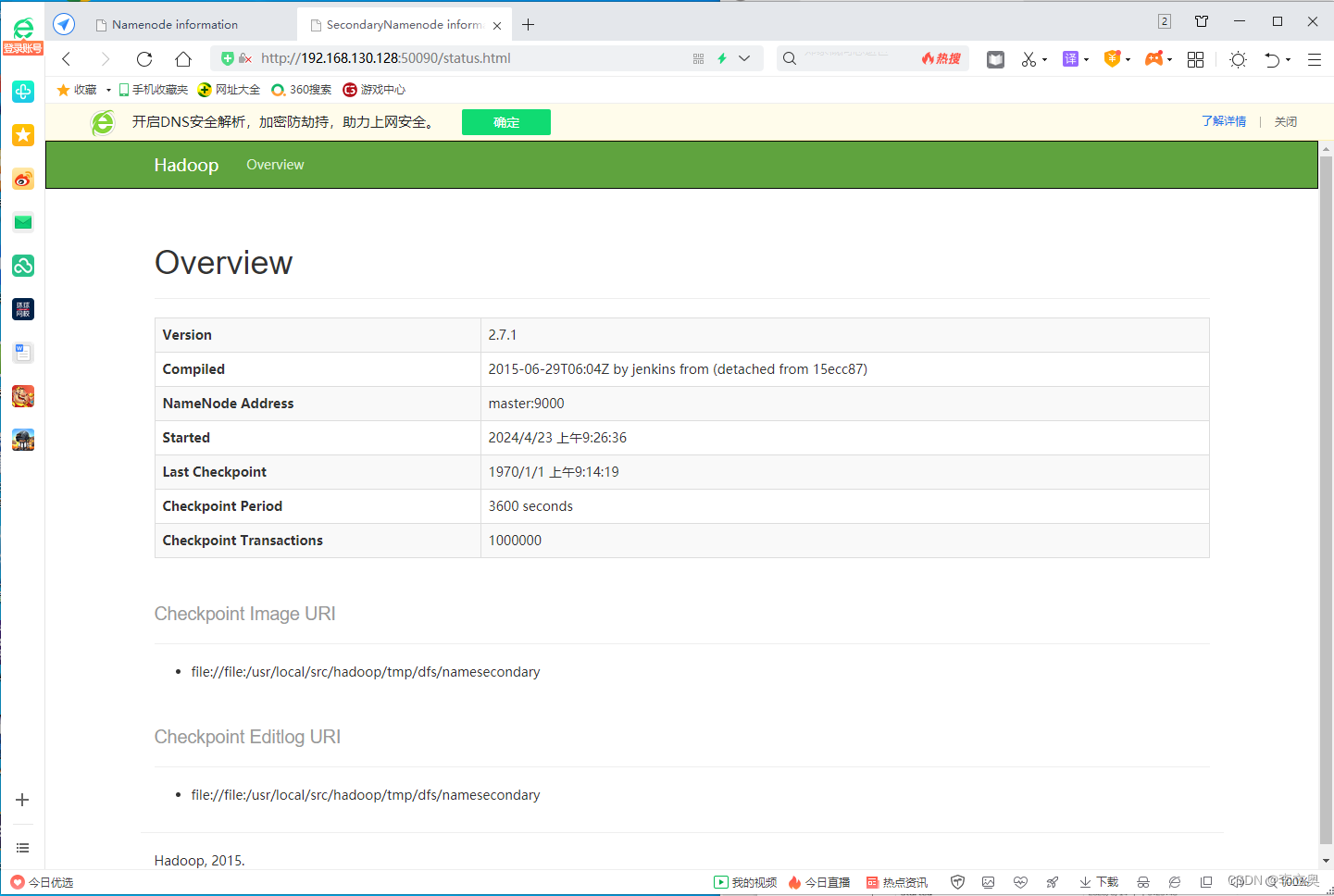
在浏览器的地址栏输入 http://master:50090,进入页面可以查看 SecondaryNameNode信息
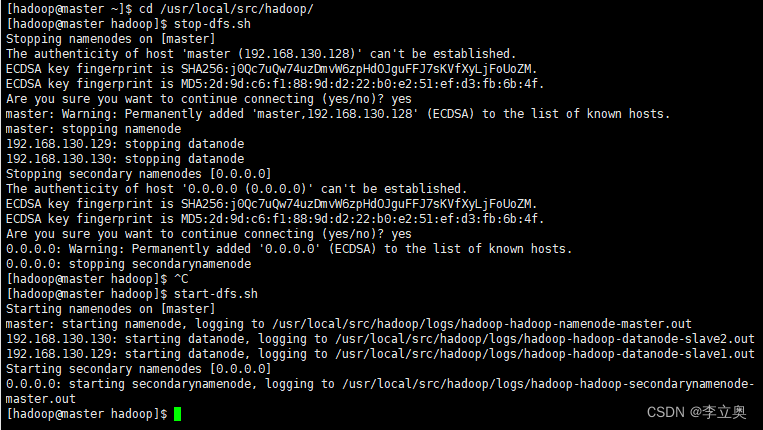
可以使用 start-dfs.sh 命令启动 HDFS。。
[hadoop@master hadoop]$ stop-dfs.sh
[hadoop@master hadoop]$ start-dfs.sh
在 HDFS 文件系统中创建数据输入目录
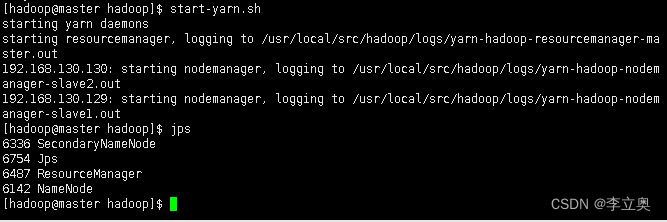
[hadoop@master hadoop]$ start-yarn.sh
[hadoop@master hadoop]$ jps
[hadoop@master hadoop]$ hdfs dfs -mkdir /input
[hadoop@master hadoop]$ hdfs dfs -ls /

将输入数据文件复制到 HDFS 的/input 目录中
[hadoop@master hadoop]$ cat ~/input/data.txt
Hello World
Hello Hadoop
Hello Huasan
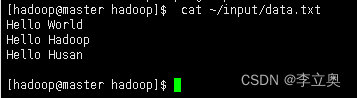
将输入数据文件复制到 HDFS 的/input 目录中:
[hadoop@master hadoop]$ hdfs dfs -put ~/input/data.txt /input
[hadoop@master hadoop]$ hdfs dfs -ls /input

[hadoop@master hadoop]$ hdfs dfs -mkdir /output
查看 HDFS 中的文件:
[hadoop@master hadoop]$ hdfs dfs -ls /
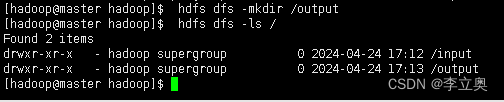
上述目录中/input 目录是输入数据存放的目录,/output 目录是输出数据存放的目录。执 行如下命令,删除/output 目录。
[hadoop@master hadoop]$ hdfs dfs -rm -r -f /output

[hadoop@master hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.1.jar wordcount /input/data.txt /output
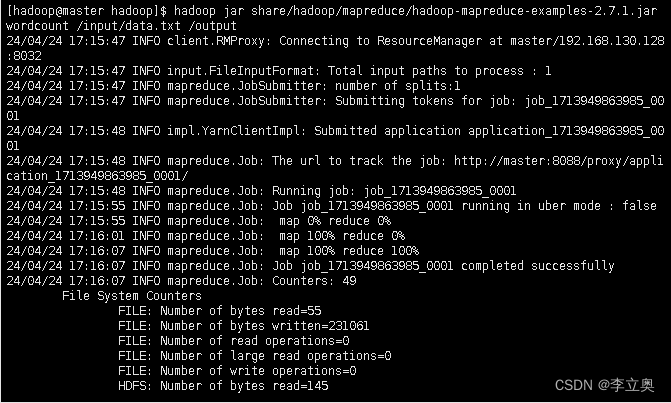
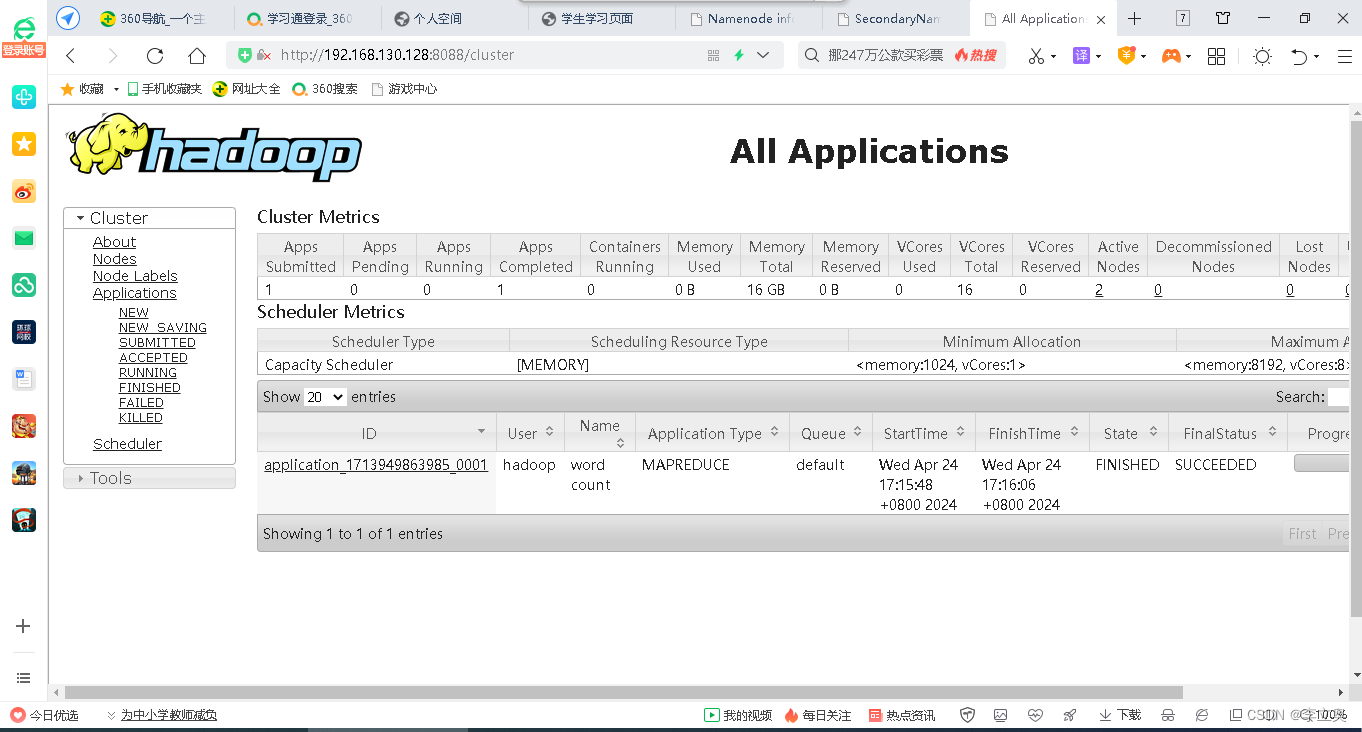
在浏 览器的地址栏输入:http://192.168.130.128:8088 颜色标为master的ip地址