
GenAI 技术堆栈架构师指南 - 十种工具
赞
踩

这篇文章于 2024 年 6 月 3 日首次出现在 The New Stack 上。
我之前写过关于现代数据湖参考架构的文章,解决了每个企业面临的挑战——更多的数据、老化的Hadoop工具(特别是HDFS)以及对RESTful API(S3)和性能的更大需求——但我想填补一些空白。
现代数据湖(有时称为数据湖仓一体)是基于一半数据湖和一半开放表格式规范 (OTF) 的数据仓库。两者都建立在现代对象存储之上。
同时,我们深入思考了组织如何构建能够支持您所有 AI/ML 需求的 AI 数据基础设施,而不仅仅是训练集、验证集和测试集的原始存储。换句话说,它应该包含训练大型语言模型、MLOps 工具、分布式训练等所需的计算。基于这一思路,我们整理了另一篇关于如何使用现代数据湖参考架构来支持您的 AI/ML 需求的论文。下图展示了现代数据湖参考架构,并突出显示了生成式 AI 所需的功能。
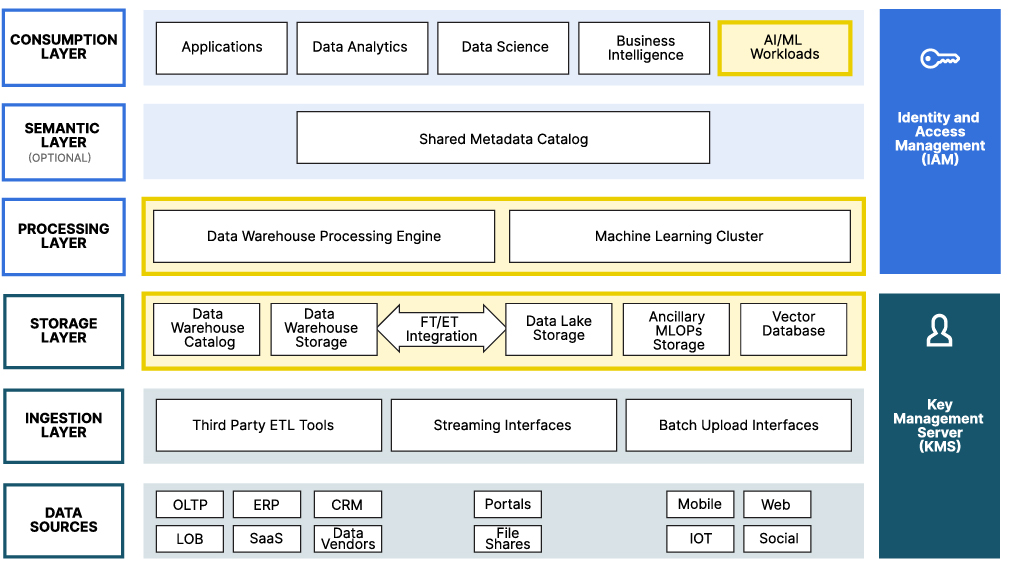
来源:现代数据湖中的 AI/ML
1. 数据湖
企业数据湖建立在对象存储之上。不是老式的、基于设备的对象存储,它服务于廉价和深入的存档用例,而是现代的、高性能的、软件定义的和 Kubernetes 原生对象存储,它们是现代 GenAI 堆栈的基石,它们可以作为服务(AWS、GCP、Azure)或本地或混合/两者提供,例如 MinIO。这些数据湖必须支持流式工作负载,必须具有高效的加密和纠删码,需要以原子方式存储对象的元数据,并支持 Lambda 计算等技术。鉴于这些现代替代方案是云原生的,它们将与其他云原生技术的整个堆栈集成 - 从防火墙到可观测性再到用户和访问管理 - 开箱即用。
2. 基于OTF的数据仓库
对象存储也是基于 OTP 的数据仓库的底层存储解决方案。将对象存储用于数据仓库可能听起来很奇怪,但以这种方式构建的数据仓库代表了下一代数据仓库。这是由 Netflix、Uber 和 Databricks 编写的 OTF 规范实现的,这些规范使得在数据仓库中无缝使用对象存储成为可能。
OTF——Apache Iceberg、Apache Hudi 和 Delta Lake——之所以被编写,是因为市场上没有可以处理创作者数据需求的产品。 从本质上讲,它们(以不同的方式)所做的是定义一个可以构建在对象存储之上的数据仓库。对象存储提供了可扩展容量和高性能的组合,这是其他存储解决方案无法做到的。由于这些是现代规范,因此它们具有老式数据仓库所不具备的高级功能,例如分区演变、模式演变和零拷贝分支。
两个可以在 MinIO 之上运行基于 OTF 的数据仓库的 MinIO 合作伙伴是 Dremio 和 Starburst。
Dremio Sonar(数据仓库处理引擎)
Dremio Arctic(数据仓库目录)
开放数据湖仓一体 |Starburst(目录和处理引擎)
3. 机器学习操作 (MLOps)
MLOps 之于机器学习,就像 DevOps 之于传统软件开发一样。两者都是一组旨在改善工程团队(开发或 ML)和 IT 运营 (Ops) 团队之间协作的实践和原则。目标是使用自动化来简化开发生命周期,从规划和开发到部署和运营。这些方法的主要好处之一是持续改进。
MLOps 技术和功能在不断发展。您需要一个由主要参与者支持的工具,确保该工具不断开发和改进,并将提供长期支持。这些工具中的每一个都在后台使用 MinIO 来存储模型生命周期中使用的工件。
MLRun(Iguazio,被麦肯锡公司收购)
MLflow (Databricks)
Kubeflow (谷歌)
4. 机器学习框架
机器学习框架是用于创建模型并编写训练模型的代码的库(通常用于 Python)。这些库具有丰富的功能,因为它们为神经网络提供了不同的损失函数、优化器、数据转换工具和预构建层的集合。这两个库提供的最重要的功能是张量。张量是可以移动到 GPU 上的多维数组。它们还具有自动微分功能,可在模型训练期间使用。
当今最流行的两个机器学习框架是 PyTorch(来自 Facebook)和 Tensorflow(来自 Google)。
5. 分布式训练
分布式模型训练是跨多个计算设备或节点同时训练机器学习模型的过程。这种方法加快了训练过程,特别是当需要大型数据集来训练复杂模型时。
在分布式模型训练中,数据集被划分为更小的子集,每个子集由不同的节点并行处理。这些节点可以是集群中的单个计算机、单个进程或 Kubernetes 集群中的单个 Pod。他们可能有权访问 GPU。每个节点独立处理其数据子集,并相应地更新模型参数。下面的五个库使开发人员免受分布式训练的大部分复杂性的影响。如果您没有集群,您可以在本地运行它们,但您需要一个集群才能看到训练时间的显着减少。
6. 模型中心
模型中心并不是现代数据湖参考架构的真正组成部分,但我还是将其包括在内,因为它对于快速开始使用生成式 AI 非常重要。Hugging Face 已成为大型语言模型的去处。Hugging Face 拥有一个模型中心,工程师可以在其中下载预先训练的模型并共享他们自己创建的模型。Hugging Face 还是 Transformers 和 Datasets 库的作者,这些库使用大型语言模型 (LLMs) 以及用于训练和微调它们的数据。
还有其他模型中心。所有主要的云供应商都有某种方式上传和共享模型,但 Hugging Face 凭借其模型和库集合,已成为该领域的领导者。
7. 应用框架
应用程序框架有助于将 合并LLM到应用程序中。使用 an LLM 与使用标准 API 不同。必须做很多工作才能将用户请求转化为LLM可以理解和处理的内容。例如,如果您构建了一个聊天应用程序,并且想要使用 Retrieval Augmented Generation (RAG),则需要对请求进行标记化,将标记转换为向量,与向量数据库集成(如下所述),创建提示,然后调用 LLM.生成式 AI 的应用程序框架将允许您将这些操作链接在一起。当今使用最广泛的应用程序框架是LangChain。它与其他技术集成,例如,Hugging Face Transformer 库和用于文档处理的 Unstructured 库。它功能丰富,使用起来可能有点复杂,所以下面列出了一些替代方案,适合那些没有复杂要求并想要比LangChain更简单的东西的人。
8. 文件处理
大多数组织没有一个包含干净和准确文档的存储库。相反,文档以多种格式分布在组织中的各种团队门户中。为生成式 AI 做好准备的第一步是构建一个管道,该管道仅获取已批准用于生成式 AI 的文档,并将它们放置在矢量数据库中。对于大型全球组织来说,这可能是生成式人工智能解决方案中最艰巨的任务。

文档管道应将文档转换为文本,对文档进行分块,并通过嵌入模型运行分块文本,以便将其向量表示形式保存到向量数据库中。幸运的是,一些开源库可以对许多常见的文档格式做到这一点。下面列出了一些库。这些库可以与LangChain一起使用,以构建完整的文档处理管道。
9. 向量数据库
向量数据库有助于语义搜索。了解这是如何完成的需要大量的数学背景,而且很复杂。但是,语义搜索在概念上很容易理解。假设您想找到所有讨论与“人工智能”相关的任何内容的文档。要在传统数据库上执行此操作,您需要搜索“人工智能”的所有可能的缩写、同义词和相关术语。
看起来像这样:
SELECT snippet
FROM MyCorpusTable
WHERE (text like '%artificial intelligence%' OR
text like '%ai%' OR
text like '%machine learning%' OR
text like '%ml%' OR
... and on and on ...
- 1
这种手动相似性搜索不仅费力且容易出错,而且搜索本身也非常缓慢。向量数据库可以接受如下所示的请求,并更快、更准确地运行查询。如果您希望使用 Retrieval Augmented Generation,那么快速准确地运行语义查询的能力非常重要。
{
Get {
MyCorpusTable(nearText: {concepts: ["artificial intelligence"]})
{snippet}
}
}
- 1
下面列出了四种流行的向量数据库。Milvus
Pgvector
Pinecone
Weaviate
10. 数据探索和可视化
拥有允许您整理数据并以不同的方式可视化数据的工具始终是一个好主意。下面列出的 Python 库提供数据操作和可视化功能。这些似乎是传统 AI 才需要的工具,但它们在生成式 AI 中也派上用场。例如,如果你正在做情绪分析或情绪检测,那么你应该检查你的训练、验证和测试集,以确保你在所有类中都有适当的分布。
结论
这就是:可以在现代数据湖参考架构中找到的 10 项功能,以及每种功能的具体供应商产品和库。下表总结了这些工具。
1 . Data Lake - MinIO, AWS, GCP, Azure
2 . OTF-based data warehouse - Dremio, Dremio Sonar, Dremio Arctic, Starburst, Open Data Lakehouse | Starburst
3 . Machine learning framework - PyTorch, TensorFlow
4 . Machine learning operations - MLRun (McKinsey & Company), MLflow (Databricks), Kubeflow (Google)
5 . Distributed training - DeepSpeed (from Microsoft), Horovod (from Uber), Ray (from Anyscale), Spark PyTorch Distributor (from Databricks), Spark Tensoflow Distributor (from Databricks)
6 . Model hub - Hugging Face
7 . Application framework - LangChain, AgentGPT, Auto-GPT, BabyAGI, Flowise, GradientJ, LlamaIndex, Langdock, TensorFlow (Keras API)
8 . Document processing - Unstructured, Open-Parse
9 . Vector database - Milvus, Pgvector, Pinecone, Weaviate
10 . Data exploration and visualization - Pandas, Matplotlib, Seaborn, Streamlit

