
- 1MacBook 整个配置过程,供新入手MacBook的同学_macbook 你是配置清单
- 2想面试Java后端,至少这些你都要会吧_java后端要熟悉es吗
- 3掌握Hive:从入门到精通的知识总结_hive从入门到精通
- 447天录用!3天见刊!IEEE-Trans系列SCI,进展超顺!稳定检索49年!_ieee trans期刊
- 5【人工智能 AI】Transformer 神经网络模型的实现原理_人工智能transformer
- 62024西南交通大学计算机考研信息汇总_西南交通大学计算机考研群2024
- 7Odoo 14 免费下载_odoo14原码zip百度网盘下载
- 8芬兰木棋 (25 分)
- 9基于RAG和大模型构建股价预测系统(实践篇)_用大模型做股票分析、预测
- 10迁移学习(Transfer learning)_迁移学习是transform 吗
常用MQ消息中间件Kafka、ZeroMQ和RabbitMQ对比及RabbitMQ详解_zeromq和rabbimq的区别
赞
踩
1、概述
在现代的分布式系统和实时数据处理领域,消息中间件扮演着关键的角色,用于解决应用程序之间的通信和数据传递的挑战。在众多的消息中间件解决方案中,Kafka、ZeroMQ和RabbitMQ 是备受关注和广泛应用的代表性系统。它们各自具有独特的特点和优势,适用于不同的应用场景和需求。
Kafka 是一个高性能、可扩展的分布式消息队列系统,被设计用于处理大规模的数据流和实时数据传输。它以其出色的吞吐量、持久性和可靠性而闻名,广泛应用于各种数据处理和事件驱动的架构中。Kafka 的设计思想注重于可扩展性和高性能,使其成为大规模数据处理和实时数据流的首选。
ZeroMQ 是一个高性能的消息传递库,旨在提供低延迟和轻量级的消息通信。ZeroMQ 的设计目标是简化并发编程和分布式系统的开发,通过提供灵活的消息传递模式和异步通信机制,使开发人员能够轻松构建高效的通信系统。它的特点包括高性能、低延迟和可靠性,适用于需要高并发和低延迟通信的场景。
RabbitMQ 是一个灵活的消息中间件,提供了丰富的消息路由和队列模式,以及多种协议的支持。它的设计目标是提供可靠性、灵活性和高度可定制化的消息传递解决方案。RabbitMQ 提供了多种消息传递模式,包括发布-订阅模式、消息队列模式和广播模式,可以根据需求选择适当的模式。它支持多种协议,如 AMQP、STOMP 和 MQTT,使其能够与不同的应用程序和系统进行集成。
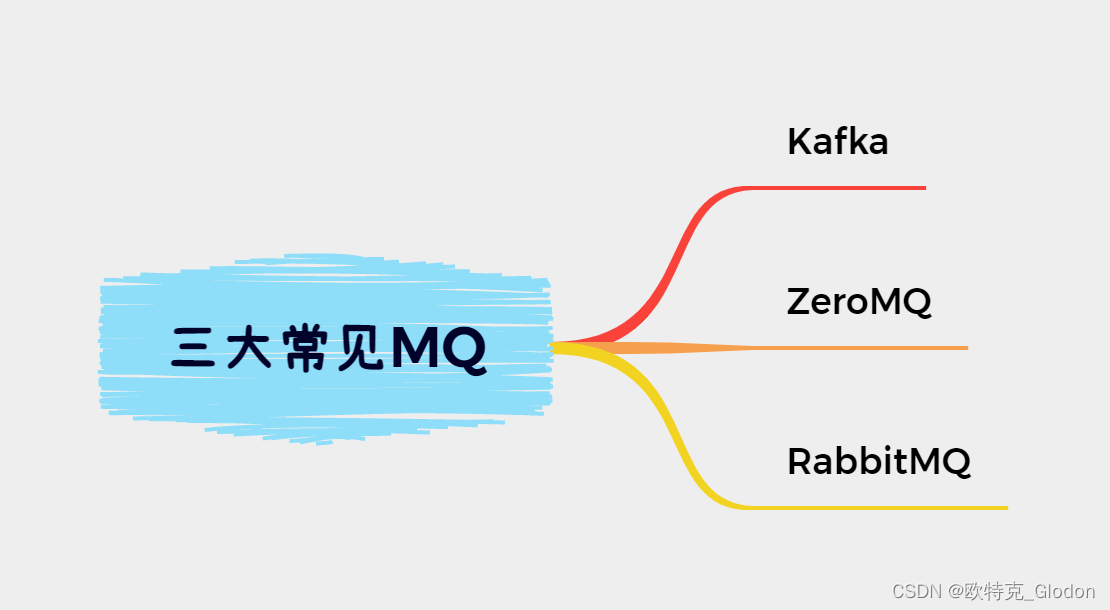
2、Kafka、ZeroMQ、RabbitMQ比较
2.1 ZeroMQ
ZeroMQ——【Zero】MQ:其实不是传统意义上的MQ。它只是一个用于网络编程的SDK,目标是给常见的网络通讯方式提供一个更好用的接口,在没有“broker”的情况下实现网络通讯。比如,想实现一个req/resp的机制。用常规的socket是个相当麻烦的事。从客户端要connect,按照报格式序列化数据,发数据,接收数据,关闭连接;而服务端要listen,accept,读取数据,发送数据……这还不算每个步骤的错误处理,缓冲区的管理,多路复用……。(所以普通人估计直接就上http了)。再比如fanout,fanin,master-worker……这些模式也都相当麻烦。而ZeroMQ提供了SDK可以帮助开发者快速实现这些功能。
ZeroMQ (also spelled ØMQ, 0MQ or ZMQ) is a high-performance asynchronous messaging library, aimed at use in distributed or
concurrent applications. It provides a message queue, but unlike message-oriented middleware, a ZeroMQ system can run without a
dedicated message broker.……The philosophy of ZeroMQ starts with the zero. The zero is for zero broker (ZeroMQ is brokerless), zero
latency, zero cost (it’s free), and zero administration.
- 1
- 2
- 3
- 4
个人认为ZeroMQ适合用来搭建一个框架,而并非被直接被业务使用。比如:ZeroMQ完全不解决消息高可用的的问题;消息落盘这种事并不在ZeroMQ的scope里。因为它和常规MQ的差异过于巨大(除了名字里带mq,和mq没有关系),从应用角度,除非是做网络编程的,不太建议进一步深入了解它。
2.2 RabbitMQ
RabbitMQ代表了传统的broker为中心的MQ,其设计和信箱很像。被发送的消息经过1个或者多个broker的处理,最终进入一个消费者的信箱(queue)。消费者正确处理后,这个message就被删除了。如果存在多个不同的,彼此独立的consumer,可以设置各自独立的queue,各不影响。这里说”以broker为中心“就是着重强调”转发能力”。一个broker可以根据路由规则进行投递,可以fanout,可以根据tag做部分message的过滤。多个broker之间还可以“接力”。message还能有TTL生命周期。在复杂的企业级信息系统里实现message通讯和协作。RabbitMQ也满足多个标准,如AMQP,MQTT,STOMP等。遵守这些协议可以帮助上游在多个MQ上做迁移。
这类MQ从使用者角度,用起来非常方便。producer只管发,consumer只管收。业务逻辑都是broker上面配置。但这种设计也带来一些根本性的问题,让他非常不适合在一些场景中使用。
- 首先是保序性。RabbitMQ(或者这类MQ)都只能保证在单broker+单consumer+不自动进入死信队列的情况下实现保证严格的顺序。但是单broker+单consumer是不可扩展的,无法实现更高的吞吐。类似于数据库Syncer之类需要严格顺序的服务就无法实现了。
- 因为存在多个queue,因此一个message可能被写入多次,存在写放大的问题。但既然支持了多个queue,就不可能不复制message。那么吞吐就会受到极大的影响。类似于日志流式处理的场景就无法支持了。
- 一个message被消费了,就会被清理。那么如果一个流处理存在bug,产生了错误的结果,就意味着无论如何都无法重新修正了。除非数据源可以把messge重新发一遍。如果MQ拓扑很复杂,这几乎就不可能。类似的,也没法做到“半夜把白天的数据用批处理重新跑一遍”之类的事情。
2.3 Kafka
Kafka从一开始就实现了一个和传统的MQ完全不同的”MQ“。它的出现一开始就是面向大数据,高吞吐的场景。尽管Kafka里也有个“broker”。但这个broker干的事情和RabbitMQ的“根据业务逻辑转发和处理”完全不同。Kafka的broker仅仅是以理论上最快的速度来将消息写入,供consuemr读取。在磁盘上,最快的写入就是顺序写(当时HDD还大量存在,HDD的顺序写和随机写的性能差异比SSD大得多)。因此Kafka的broker就是将数据的以“Append only”的形式写入文件。(对比传统MQ一般会用某种数据库)。这个Append only file模型上实际就是个log(留意这里的log的意思并不是业务日志,是指总是追加写的数据模型)。
kafka就实现了一个可以极大吞吐的,有顺序保证的,可以被反复消费log文件队列。而log这种数据模型,其实是很多数据系统的内部核心数据结构。比如在mysql中有binlog负责主从同步,redo log负责数据恢复;在raft中每个节点都会维护一个log做total order broadcast等等。在2010~2015年,因为大数据流式处理的兴起,Kafka成为数据分析领域无可替代的中间件(后来才有了RocketMQ和pulsar)。而对于大多数线上处理,只需要消息1跳的场景,不需要灵活配置转发规则的场景,Kafka也可以用。且吞吐高,相对的省资源,还可以省一套运维,顶多就是费点磁盘(便宜得很)。因此很多公司会选择运维几套不同的Kafka集群同时支持线上和离线业务。
2.4 优缺点对比

3、RabbitMQ详解
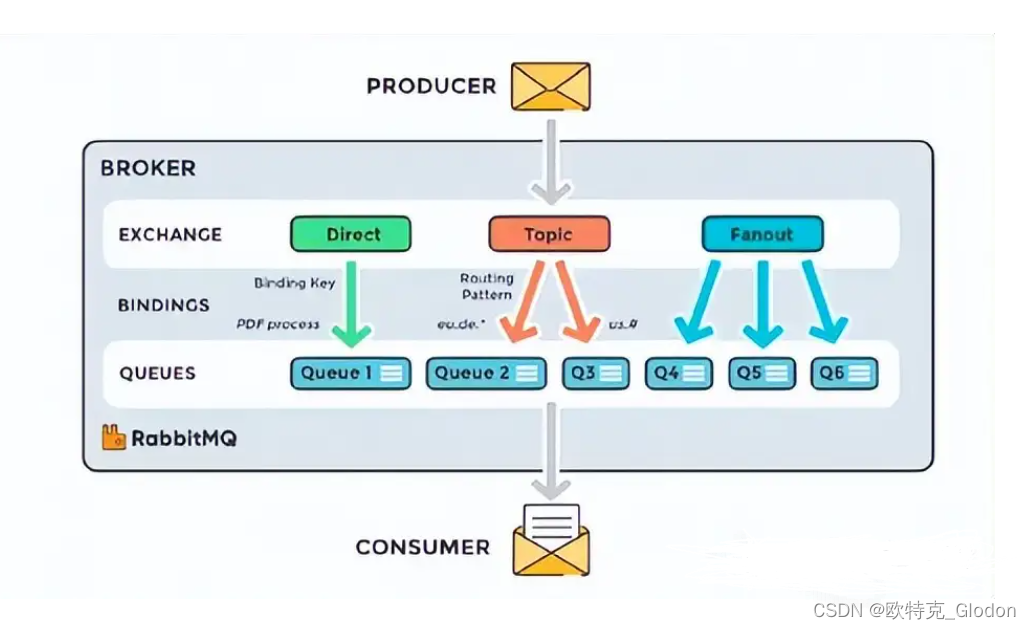
3.1 RabbitMQ的起源
RabbitMQ的诞生可以追溯到电信行业。它最初是为了满足电信业务中对可靠通信的需求而开发的。作为少有的几款支持AMQP(Advanced Message Queuing Protocol,高级消息队列协议)的产品之一,RabbitMQ自推出以来就受到广泛关注和应用。AMQP协议的设计初衷是为了在不同系统之间实现可靠、高效的消息传递,而RabbitMQ作为其实现者,自然具备了这些优秀特性。
3.2 RabbitMQ的优点
- 轻量级,快速,部署使用方便
RabbitMQ的设计非常轻量级,启动速度快,占用资源少,这使得它在各种环境下都能快速部署和运行。无论是开发环境还是生产环境,RabbitMQ的安装和配置都非常简单友好。你只需几条命令或几个点击就能启动一个RabbitMQ实例,轻松开始你的消息队列之旅。
- 支持灵活的路由配置
在RabbitMQ中,消息的生产者和消费者之间有一个非常重要的角色——交换器(Exchange)。交换器根据预先配置的路由规则,将生产者发送的消息路由到不同的队列中。这种设计使得RabbitMQ的路由规则非常灵活,你可以根据业务需求,配置多种不同类型的交换器(如直接交换器、主题交换器、扇出交换器等),甚至可以实现自定义的路由逻辑。这种灵活性使得RabbitMQ在各种复杂的消息传递场景中都能应对自如。
- 多语言客户端支持
RabbitMQ的另一个优点是其广泛的客户端支持。无论你是使用Java、Python、Ruby、JavaScript,还是其他编程语言,RabbitMQ都能提供相应的客户端库,使得你可以方便地将RabbitMQ集成到你的应用中。同时,由于RabbitMQ遵循AMQP协议,这也意味着你可以使用任何符合AMQP标准的客户端与之通信,这大大增加了系统集成的灵活性。
3.3 RabbitMQ的缺点
- 大量消息堆积时性能下降
虽然RabbitMQ在大多数情况下表现优异,但当队列中堆积了大量消息时,其性能会明显下降。这是因为RabbitMQ需要在内存中维护这些消息,同时还要处理消息的持久化和消费请求。当消息量达到一定程度后,RabbitMQ的处理能力会受到影响,导致消息处理速度变慢。因此,在设计系统时,需要考虑消息的处理和清理机制,避免大量消息长期堆积在队列中。
- 每秒处理消息量有限
如果你的应用需要每秒处理几十万甚至上百万条消息,那么RabbitMQ可能不是最优选择。虽然RabbitMQ在很多中小型场景中表现出色,但在极高性能要求的场景下,其处理能力还是有限的。在这种情况下,你可能需要考虑一些专为高吞吐量设计的消息队列产品,如Apache Kafka。
- 功能扩展和二次开发代价高
RabbitMQ是用Erlang语言开发的,这种语言虽然在并发处理和分布式系统方面有独特的优势,但其学习曲线相对较陡。对于大多数开发者来说,使用和扩展RabbitMQ的功能可能需要一定的学习成本。此外,由于Erlang社区相对较小,相关资源和支持也比较有限,这在一定程度上增加了功能扩展和二次开发的难度。
3.4 RabbitMQ的使用场景
RabbitMQ作为一个成熟、稳定的消息队列产品,在很多场景下都能发挥重要作用。它轻量级、快速、易于部署,支持灵活的路由配置和多种编程语言客户端,使得它在各种复杂的消息传递场景中都能应对自如。当然,在使用RabbitMQ时,我们也需要注意其在高性能和大消息量场景下的局限,合理设计系统架构,避免性能瓶颈。以下是一些RabbitMQ常见的使用场景:
- 异步处理
在很多Web应用中,为了提升响应速度,常常需要将一些耗时操作异步处理,比如发送邮件、生成报表等。RabbitMQ可以帮助我们将这些任务放入队列,后台处理,从而提升系统的响应速度和用户体验。 - 负载均衡
在分布式系统中,通过将任务分发到多个工作节点,可以实现负载均衡,提升系统的处理能力和可靠性。RabbitMQ通过其灵活的路由和队列机制,可以很好地实现任务的分发和负载均衡。
- 日志收集和分析
在大数据时代,日志的收集和分析变得非常重要。通过RabbitMQ,可以将各个系统模块的日志统一收集起来,发送到日志处理和分析系统中,帮助我们实时监控和分析系统运行情况。
- 微服务通信
在微服务架构中,各个服务之间常常需要进行大量的通信。通过RabbitMQ,可以实现可靠、灵活的服务间消息传递,提升系统的可扩展性和可靠性。

