
热门标签
热门文章
- 1Python酷库之旅-第三方库Pandas(060)
- 2软考高级架构师下篇-17安全架构设计理论与实践_软考架构师(17)——应用数学
- 3探讨如何面试外包人员?
- 4STM32-GPRS模块连接系统主站_stm32gprs
- 5软件工程-系统架构师(四十一)
- 6基本SQL语句(一篇就够了)
- 7如何用conda安装PyTorch(windows、GPU)最全安装教程(cudatoolkit、python、PyTorch、Anaconda版本对应问题)(完美解决安装CPU而不是GPU的问题)_conda安装torch
- 82024最新基于Java+SpringBoot+Vue2+Uniapp微信小程序商城系统设计和实现
- 9手把手带你从0开始搭建个人网站,小白可懂的保姆级教程_怎么创建网站免费建立个人网站
- 10python计算机毕设(附源码)养老服务系统的设计与实现(django+mysql5.7+文档)_利用python实现社会养老保险程序
当前位置: article > 正文
如何搭建一个属于自己的简易LLM——基于阿里云服务器_阿里云在线部署自定义llm
作者:码创造者 | 2024-08-08 06:01:44
赞
踩
阿里云在线部署自定义llm
本篇为一个基于调用商用大模型API的自用GPT部署教程
环境配置
阿里云服务器
这里选择阿里云ECS,后续购买,配置等步骤,请自行baidu
进入控制台页面,找到自己的ECS服务器,进入安全组,放行防火墙端口,streamlit默认端口为8501

按顺序依次填写,最后保存即可

Anaconda
安装
如有需要可自行选择安装包下载地址
# 获取Anaconda安装包
wget https://repo.anaconda.com/archive/Anaconda3-2024.02-1-Linux-x86_64.sh
# 解压安装
bash Anaconda3-2024.02-1-Linux-x86_64.sh
# 后面按照安装步骤一步一步安装即可
# 安装成功后,刷新环境配置
source ~/.bashrc
- 1
- 2
- 3
- 4
- 5
- 6
- 7
创建 虚拟环境
# llm为指定虚拟环境名字,3.10为指定python版本
conda create -n llm python=3.10
# 进入刚刚创建的环境
conda activate llm
- 1
- 2
- 3
- 4
Python
pip install streamlit
pip install dotenv
pip install zhipuai
- 1
- 2
- 3
部署
API调用
这里以智谱AI为例
注册账号
点击开始使用,即可跳转到登陆or注册页面
获取API密匙
选择调用方式
这里选择基于SDK的调用,如有其他调用需求可自行查看文档
在当前页面往下翻,找到SSE调用
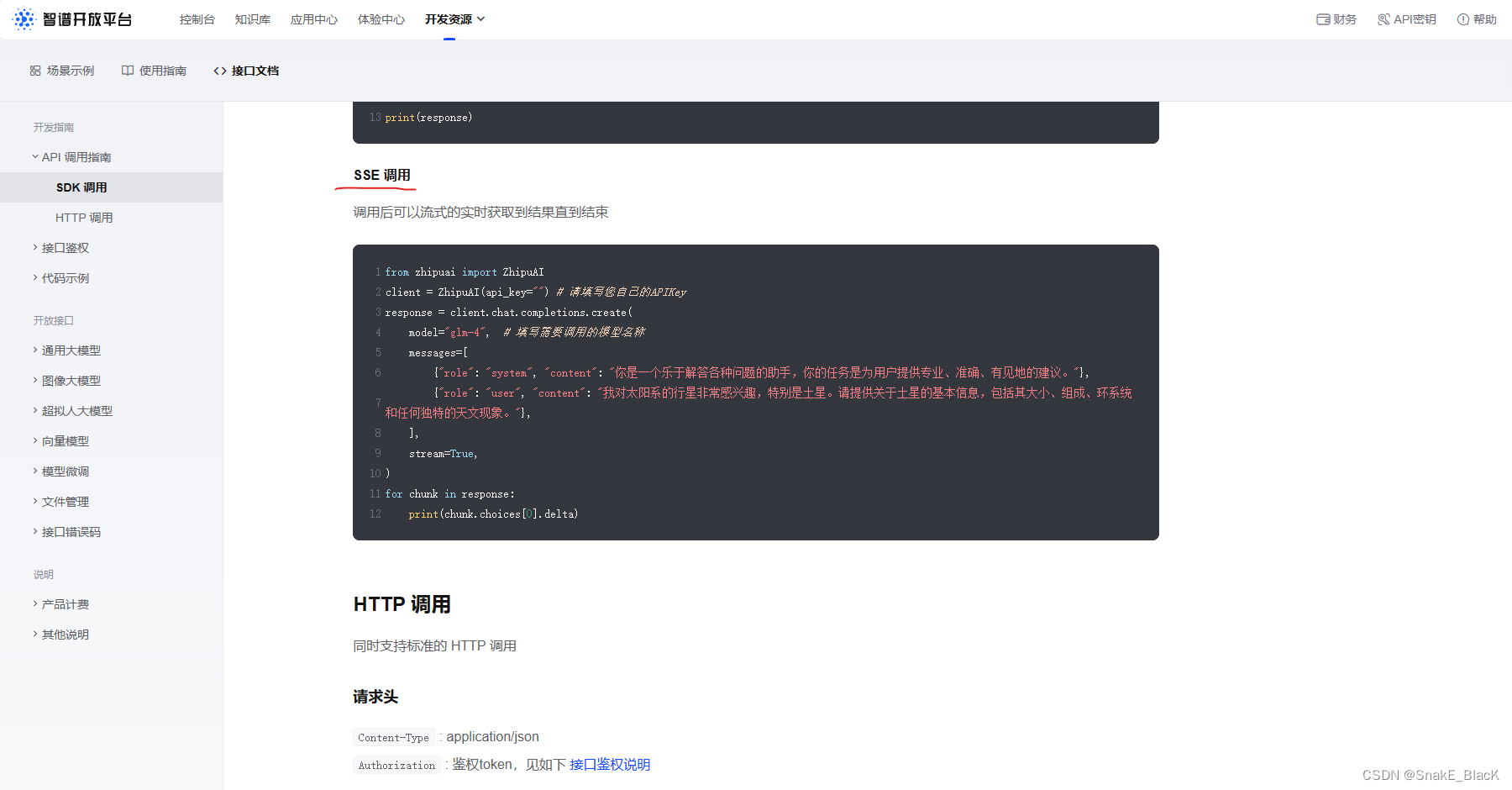
from zhipuai import ZhipuAI
client = ZhipuAI(api_key="") # 请填写您自己的APIKey
response = client.chat.completions.create(
model="glm-4", # 填写需要调用的模型名称
messages=[
{"role": "system", "content": "你是一个乐于解答各种问题的助手,你的任务是为用户提供专业、准确、有见地的建议。"},
{"role": "user", "content": "我对太阳系的行星非常感兴趣,特别是土星。请提供关于土星的基本信息,包括其大小、组成、环系统和任何独特的天文现象。"},
],
stream=True,
)
# 这是查看调用返回结果示例,后面会用到
for chunk in response:
print(chunk.choices[0].delta)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
编写脚本
先创建一个名为.env的文件,然后在文件中写入下述内容
vim .env
- 1
# 智谱 API 访问密钥配置
ZHIPUAI_API_KEY = "请填写您自己的APIKey"
- 1
- 2
model
这里只对模型调用部分作简要说明,关于前端页面的搭建,可自行查看文档streamlit——Build a simple chatbot GUI with streaming
import os import streamlit as st # 导入前端框架streamlit from dotenv import load_dotenv, find_dotenv # 导入环境配置包 from zhipuai import ZhipuAI # 导入智谱AI包 _ = load_dotenv(find_dotenv()) # 加载环境变量 api_key = os.environ["ZHIPUAI_API_KEY"] # 读取调用API密匙 client = ZhipuAI(api_key=api_key) # 加载智谱AI模型 st.title("A Simple ChatGPT") def stream_data(stream_in): # 将列表转为流式数据 for word in stream_in: yield word.choices[0].delta.content + " " # 调用返回结果 if "messages" not in st.session_state: st.session_state.messages = [] for message in st.session_state.messages: with st.chat_message(message["role"]): st.markdown(message["content"]) if prompt := st.chat_input("What is up?"): st.session_state.messages.append({"role": "user", "content": prompt}) with st.chat_message("user"): st.markdown(prompt) with st.chat_message("assistant"): stream = client.chat.completions.create( # SSE调用 model="glm-4", messages=[ {"role": m["role"], "content": m["content"]} for m in st.session_state.messages ], stream=True, ) response = st.write_stream(stream_data(stream)) # 以流式写入数据 st.session_state.messages.append({"role": "assistant", "content": response})

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
运行
# nohup为当关闭终端时,仍保持进程运行
nohup streamlit run model.py
- 1
- 2
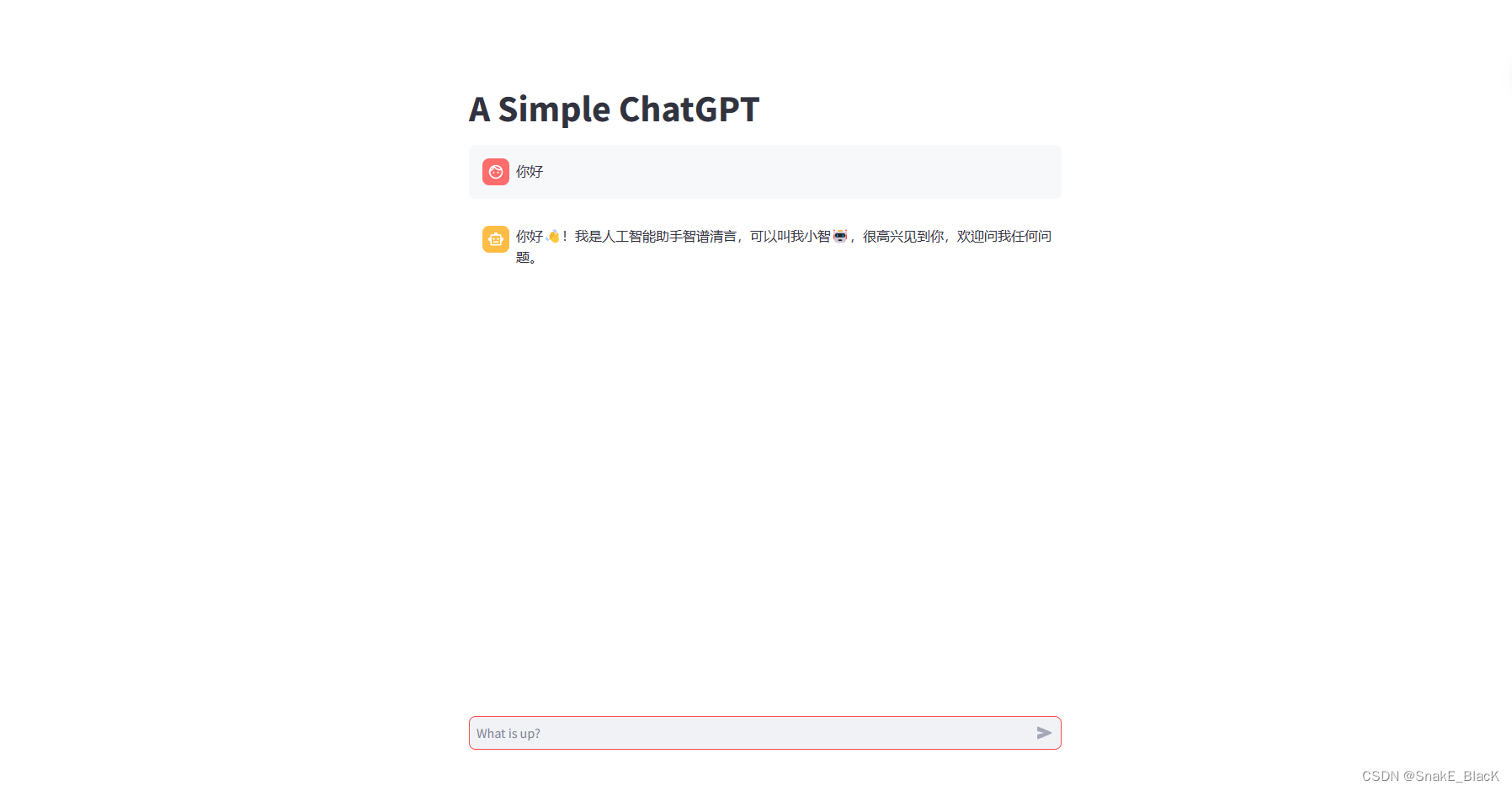
在浏览器输入 服务器的公网IP:8501 ,运行结果如图所示
参考文献
1.动手学大模型开发应用——https://github.com/datawhalechina/llm-universe
2.智谱接口文档——https://open.bigmodel.cn/dev/api
3.dotenv文档——https://www.dotenv.org/docs/
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/码创造者/article/detail/946449
推荐阅读
相关标签

