
- 1使用OpenAI的Whisper 模型进行语音识别
- 2python 模拟键盘鼠标操作_python 模拟操作qq
- 3远程控制技术:应用与趋势
- 4Java学习笔记(视频:韩顺平老师)2.0_韩顺平java
- 5【Kafka专题】Kafka快速实战以及基本原理详解_kafka专栏
- 6解决Django报错 raise ImproperlyConfigured(‘SQLite 3.8.3 or later is required (found %s).‘ % Database.s_watching for file changes with statreloader except
- 7OpenCV + Python 实现视频通道分离与合并_opencv通道分离合成python
- 8MySQL【部署 03】8.0.25离线部署(下载+安装+配置)Failed dependencies 问题处理及8.0配置参数说明_numactl离线安装
- 9探索边缘计算与云计算之间的区别
- 10Gartner发布零信任网络访问ZTNA市场指南_中国零信任网络访问市场指南
Mamba一作再祭神作,H100利用率飙至75%!FlashAttention三代性能翻倍,比标准注意力快16倍_flashattention3
赞
踩
来源 | 新智元 ID | AI-era
FlashAttention又有后续了!
去年7月,FlashAttention-2发布,相比第一代实现了2倍的速度提升,比PyTorch上的标准注意力操作快5~9倍,达到A100上理论最大FLOPS的50~73%,实际训练速度可达225 TFLOPS(模型FLOPs利用率为72%)。
然而,去年发布FlashAttenion-2尚未运用到硬件中的最新功能,在H100上仅实现了理论最大FLOPS 35%的利用率。
时隔一年,FlashAttention-3归来,将H100的FLOP利用率再次拉到75%,相比第二代又实现了1.5~2倍的速度提升,在H100上的速度达到740 TFLOPS。

论文地址:https://tridao.me/publications/flash3/flash3.pdf
值得一提的是,FlashAttention v1和v2的第一作者也是Mamba的共同一作,普林斯顿大学助理教授Tri Dao,他的名字也在这次FlashAttention-3的作者列表中。
Tri Dao师从于Christopher Ré和Stefano Ermon,去年6月在斯坦福大学获得计算机博士学位,毕业后担任Together AI的首席科学家,并从今年6月开始入职普林斯顿大学。

用最新最强的GPU,达到超高的算力利用率,这下LLM的性能和上下文长度又要迎来一波暴涨了。
PyTorch官方也在推特上转发了这个消息,想必我们能在不久后看到FlashAttention被集成到PyTorch中。

目前论文还未上传到arxiv平台,只发表在Tri Dao本人的博客中,但GitHub上已经发布了用于Beta测试的源代码。
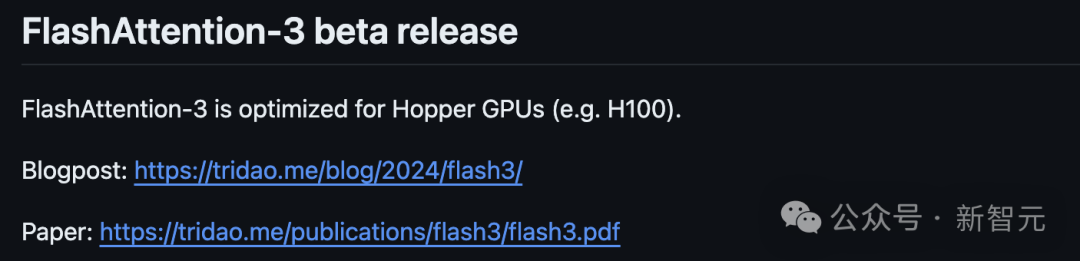
项目地址:https://github.com/Dao-AILab/flash-attention
网友在其中发现了重要的华点——这一版的FlashAttention专攻H100 GPU,只能在H100或H800上运行,不支持其他GPU型号。
所以即使有了源代码,大多数只有4090的开发者也应该运行不起来,还得先攒钱买H100。

面对这篇论文,财大气粗的科技巨头可以说,「太棒了,现在我们99999个H100的算力集群还能更快。」
普通研发人员只能说,「啊,得买几个H100来试试,但不幸的是,我只有2个肾。」
H100利用率飙至75%,LLM速度再翻倍
对Transformer架构来说,注意力机制既是核心优势,也是重要瓶颈。其理论计算量是序列长度的二次方,因此拖慢了计算速度,阻碍了在LLM中的长上下文应用。
FlashAttention(以及FlashAttention-2)通过减少内存读写次数,开创了一种在GPU上加速注意力机制的方法,现在大多数库都使用它来加速Transformer的训练和推理。
这使得大语言模型的上下文长度在过去两年中大幅增加,从2-4K(如GPT-3、OPT)扩展到128K(如GPT-4),甚至达到1M(如Llama 3、Gemini 1.5 Pro)。
然而,尽管取得了显著进展,FlashAttention还没有充分利用现代硬件的新功能,FlashAttention-2在H100 GPU上仅实现了理论最大FLOPs的35%利用率。
针对最新的Hopper GPU进行改进,FlashAttention-3主要使用了如下3种技术加速注意力机制:利用Tensor Cores和TMA的异步性——
1)通过warp-specialization技术重叠整体计算和数据移动;
2)其次,交替进行块状矩阵乘法和softmax操作;
3)利用硬件支持进行FP8低精度的非相干处理。
在FP16模式下,FlashAttention-3比FlashAttention-2快1.5~2倍,达到740 TFLOPS,即H100理论最大FLOPs的75%。
在FP8模式下,FlashAttention-3接近1.2 PFLOPS,误差比基线FP8注意力小2.6倍。
FlashAttention-3的改进将带来以下变化:
1. 更高效的GPU利用率:新技术使H100 GPU的利用率从之前的35%提升到75%。这使得LLM的训练和运行速度显著提高,达到了之前版本的1.5~2倍。
2. 更好的低精度性能:FlashAttention-3在保持准确性的同时,可以使用FP8这样的较低精度。这不仅加快了处理速度,还能减少内存使用,从而为运行大规模AI操作的客户节省成本并提高效率。
3. 在LLMs中使用更长上下文的能力:通过加速注意力机制,FlashAttention-3使AI模型能够更高效地处理更长的文本。这意味着应用程序可以理解和生成更长、更复杂的内容,而不会影响速度。
FlashAttention回顾
FlashAttention是一种对注意力计算进行重新排序的算法,利用分块和重计算技术,大大加快了计算速度,并将内存使用量从序列长度的二次方减少到线性。
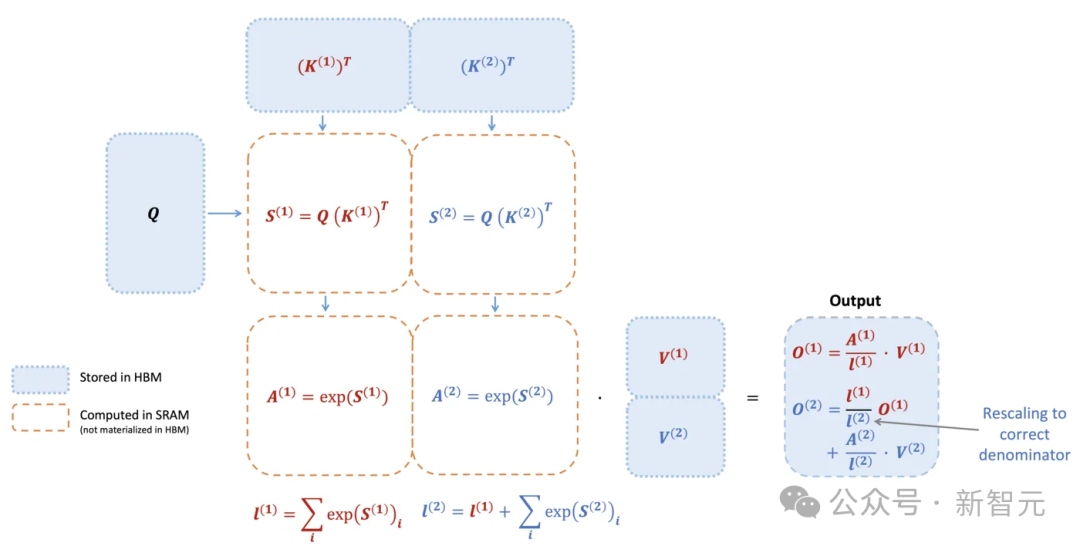
利用分块技术,将输入数据块从GPU内存中的HBM(高速带宽缓存)加载到SRAM中,对其进行注意力计算,然后在HBM中更新输出。
这种方法不将计算过程中的大型注意力矩阵写入HBM,减少了内存的读写总量,从而实现了2~4倍的速度提升。
下面是FlashAttention前向传递的示意图:通过分块和softmax重新缩放,以块为单位进行操作,避免了从HBM中频繁读写,同时能够准确地获得结果而无需近似计算。
Hopper GPU上的新硬件功能:WGMMA、TMA、FP8
Hopper GPU上的新硬件功能:WGMMA、TMA、FP8
虽然FlashAttention-2在Ampere系列(如A100)GPU上,可以达到理论最大FLOPS的72%,但尚未充分利用Hopper GPU的新功能来最大化性能。
Hopper特有的一些新功能包括:
1. WGMMA(Warpgroup Matrix Multiply-Accumulate)
这个新功能利用了Hopper上的新Tensor Cores,相较于Ampere中原来的mma.sync指令,吞吐量得到大大提高。
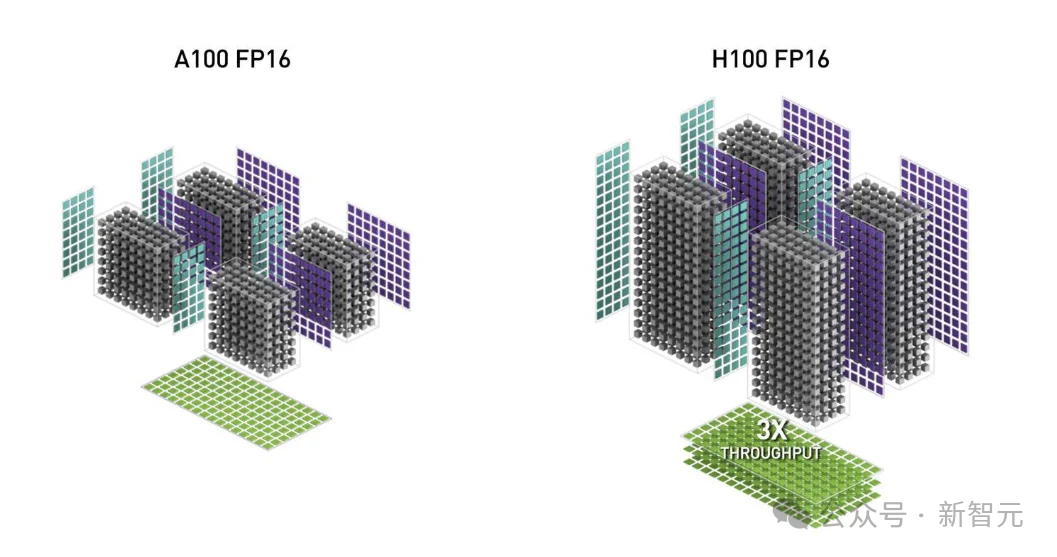
2. TMA(Tensor Memory Accelerator)
这是一种特殊的硬件单元,可以加速全局内存和共享内存之间的数据传输,并负责所有的索引计算和越界预测。这代替了寄存器的部分工作,从而能够释放寄存器资源,用于增加块大小、提高效率。
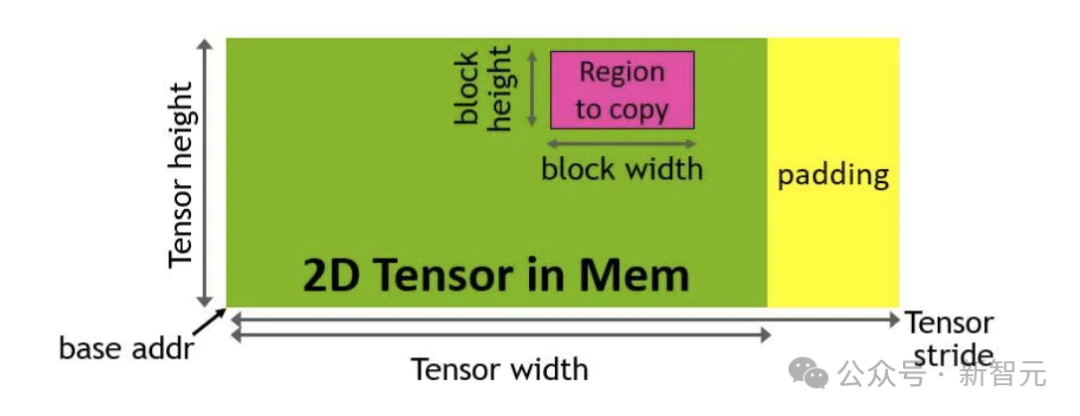
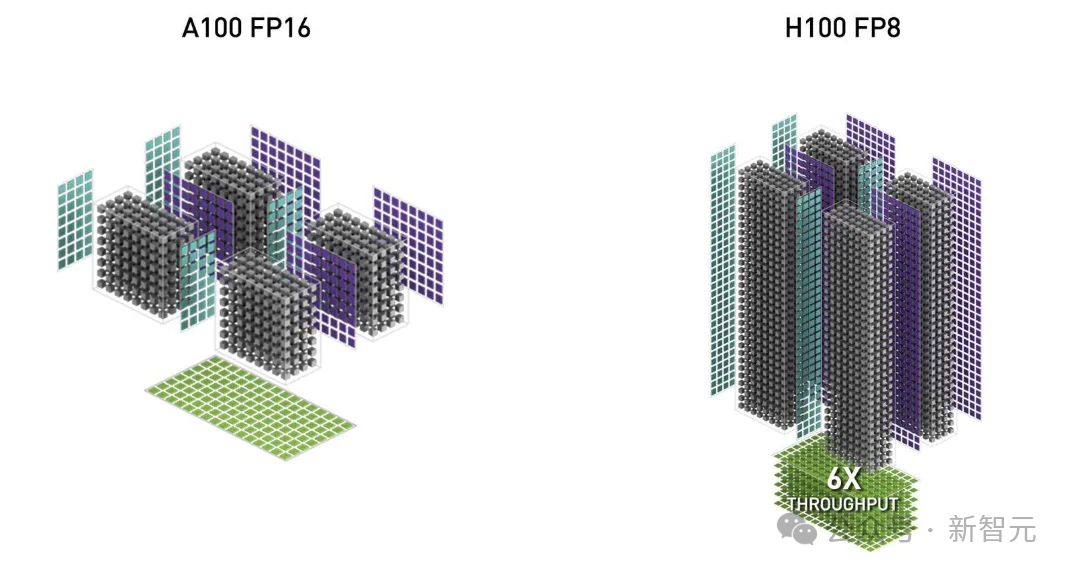
3. 低精度的FP8
FP8能够使Tensor Core的吞吐量翻倍,例如,用FP16实现989 TFLOPS计算量的同时,FP8能达到1978 TFLOPS。但由于使用更少的位来表示浮点数,牺牲了一些计算准确性。
进化后的FlashAttention-3,充分利用了Hopper GPU的以上所有新功能,并使用了NVIDIA CUTLASS库的强大抽象。
仅仅是用这些功能重写FlashAttention,就显著加快了速度,从FlashAttention-2 FP16前向计算的350 TFLOPS提升到大约540-570 TFLOPS。
不过,Hopper上新指令(WGMMA和TMA)的异步性,提供了另一种方式——通过重叠操作来提取更高的性能。
具体来说,研究人员开发了新技术来重叠矩阵函数和softmax的新技术。
异步处理:重叠GEMM和Softmax
为什么要重叠?
在注意力机制中,主要涉及两种操作:GEMM(即Q和K之间的矩阵乘法,以及注意力概率P和V之间的矩阵乘法)和softmax。
为什么需要将它们重叠呢?
大部分的浮点运算不都是在GEMM中进行的吗?
只要GEMM足够快(例如使用WGMMA指令进行计算),GPU不就应该一直高速运转吗?
事实上,并不是GEMM的问题,而是softmax会占用令人惊讶的大量时间。
问题在于,在现代加速器上,非矩阵乘法操作的速度远不及矩阵乘法操作。
像指数函数(用于softmax)这样的特殊函数,其吞吐量甚至比浮点乘法加法还低。
它们是由多功能单元(multi-function unit)计算的,与负责浮点乘加或矩阵乘加运算的单元分开计算。
例如,H100 GPU SXM5的FP16矩阵乘法性能可以达到989 TFLOPS,但特殊函数的性能只有3.9 TFLOPS(吞吐量低了256倍)!
head维度为128时,矩阵乘法的FLOPS运算是指数函数的512倍,这意味着指数函数的计算时间可以占到矩阵乘法的一半。
对于FP8,情况更糟,因为矩阵乘法的运算速度是指数函数的两倍,但指数函数的速度却没有变化。
因此,理想情况下,应该让矩阵乘法和softmax并行操作。
当Tensor Cores忙于矩阵乘法时,多功能单元应该在计算指数函数!
通过乒乓调度实现跨warp组重叠
第一种,也是最简单的重叠GEMM和softmax的方法,那就是什么都不做!
warp调度器已经在尝试调度warp,当某些warp被阻塞(例如,等待GEMM结果)时,其他warp可以继续运行。
也就是说,warp调度器已经在帮研究者做一些重叠工作了,而且不引入额外成本。
然而,我们依旧可以通过手动调度来进一步优化。
例如,如果有两个warp组(标记为1和2,每个warp组包含4个warp),可以使用同步屏障(bar.sync),使得warp组1先执行其GEMM指令(例如,GEMM1的一次迭代和GEMM0的下一次迭代),然后warp组2执行其GEMM,同时warp组1执行其softmax,依次循环。
下图展示了这种「乒乓」调度,其中相同颜色表示相同的迭代。
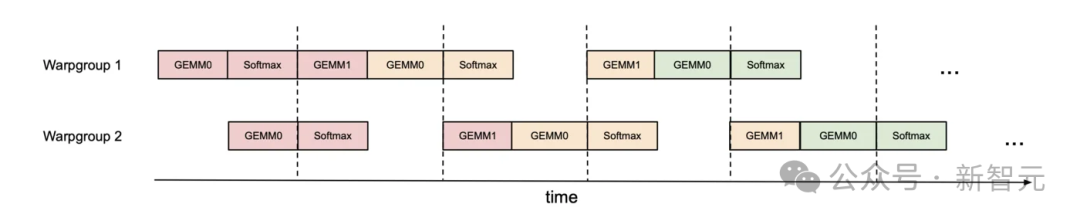
这将使我们能够在另一个warp组进行GEMM计算的同时,执行softmax操作。
当然,这个图只是一个简化示意图;实际调度并没有这么整齐。
然而,乒乓调度可以将FP16注意力在前向计算中的性能从大约570 TFLOPS提高到620 TFLOPS(head维度128,序列长度8K)。
在单个warp组内重叠GEMM和Softmax
即使在一个warp组内,也可以在warp组进行GEMM计算时,同时运行softmax的一部分。
下图展示了这种情况,其中相同颜色表示相同的迭代。
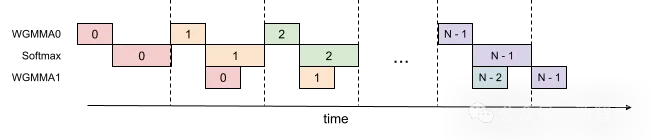
使用这种流水线,FP16注意力前向计算的吞吐量从大约620 TFLOPS,提高到大约640-660 TFLOPS,但代价是增加了寄存器压力。
这种情况下,就需要更多的寄存器,来同时保存GEMM的累加器,和softmax的输入/输出。
总之,这种技术可以提供一种有利的折衷方案。
低精度:通过非相干处理减少量化误差
在LLM的激活函数中,可能会出现一些比其他特征大得多的异常值,这会增加量化的难度,并产生更大的量化误差。
为此,论文采用了一种常用的量化技术——非相干处理(incoherent processing),例如QuIP论文中描述的,通过将查询和键乘以一个随机正交矩阵来「分散」这些异常值,从而减少量化误差。
特别的,论文使用Hadamard变换(带有随机正负号)产生随机矩阵,可以在O(d log d)而不是O(d^2)时间内完成每个注意力头的计算,其中d是head维度。
由于Hadamard变换受限于内存带宽,它可以与之前的操作,如旋转嵌入,进行无成本融合,后者同样受内存带宽的限制。
在实验中,Q、K、V是从标准正态分布生成的,但其中的0.1%有更大的数量级(以模拟异常值)。
结果发现,非相干处理可以将量化误差减少2.6倍。下表展示了数值误差对比。

注意力基准测试
接下来,论文展示了一些FlashAttention-3的测试结果,并将其与FlashAttention-2以及PyTorch中Triton和cuDNN的注意力实现进行了比较(注意,后两者都已经利用了Hopper GPU的新硬件特性)。
对于FP16精度,他们发现FlashAttention-3相对于FlashAttention-2,有大约1.6倍到2.0倍的加速效果。
序列长度在在1k或以下时,FA3相比Triton和cuDNN的优势并不明显,有时甚至会落后。
但随着序列长度和head维度逐渐增大,FA3与其他实现方案的差距也越来越显著,可见这种算法非常适用于大规模运算场景。
相较于标准注意力,FlashAttention-3的速度快了3-16倍。
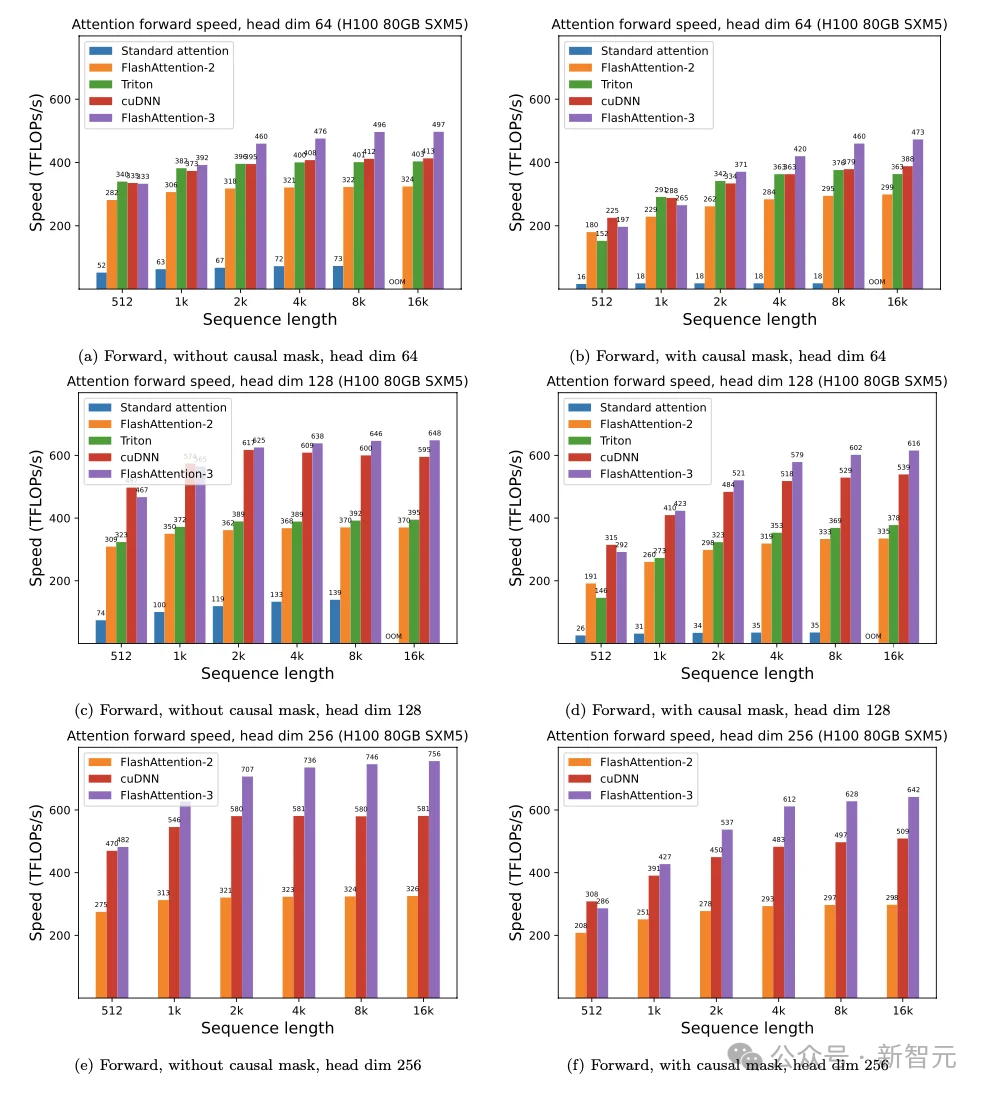
对于FP8精度,FlashAttention-3的性能可以接近1.2 PFLOPS,但会在某些情况下落后于Triton和cuDNN的性能。
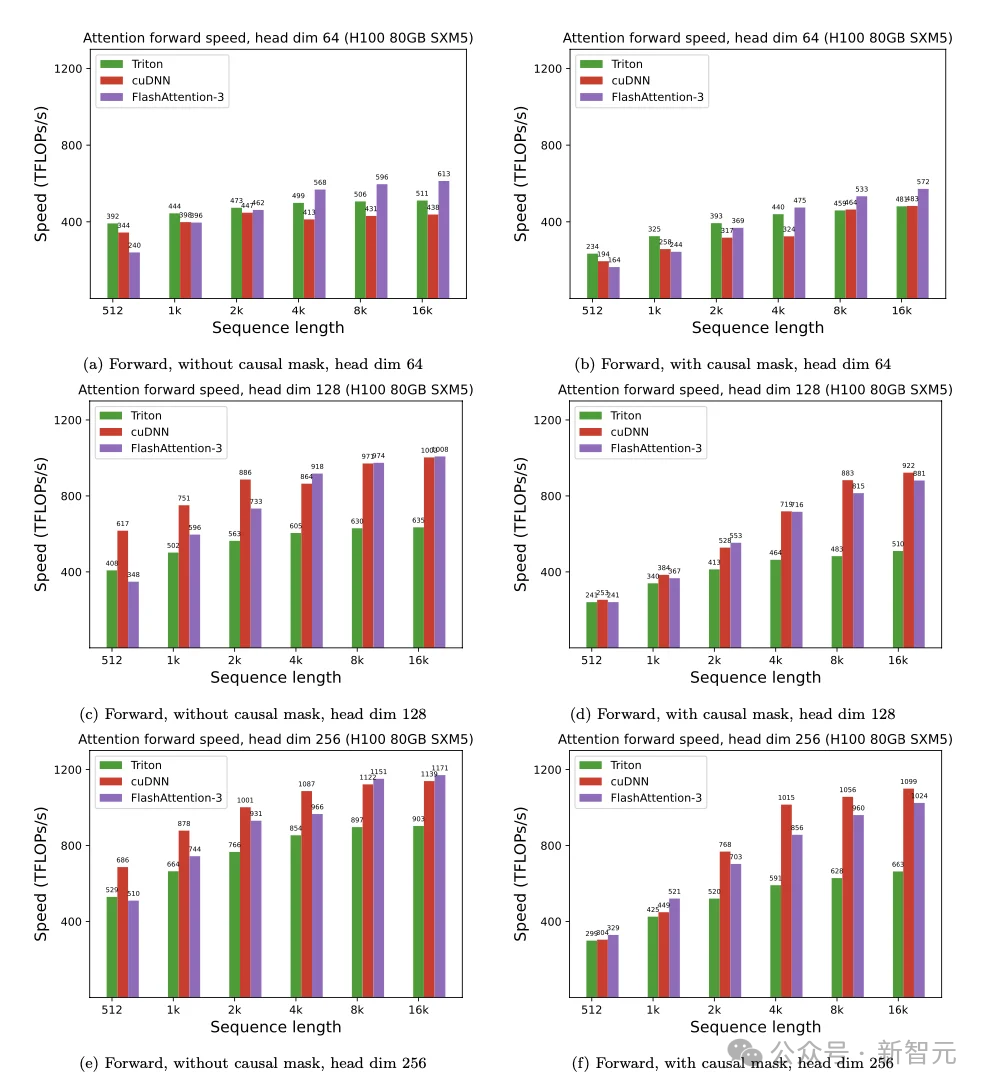
除了前向计算,FA3后向传播的运算速度也同样领先其他方案。

以上重点介绍了FlashAttention针对Hopper GPU新特性实现的优化,此外,论文中也详述了其他方面的优化,包括可变长度序列、持久内核和FP8内核转置等。
可以看到,能够充分利用硬件性能的算法可以显著提升效率,还能解锁新的模型能力,比如处理更长的上下文。
目前,FlashAttetion-3着重训练过程的优化,未来的工作可以继续提升推理性能,并推广到Hopper GPU以外的其他硬件架构。
参考资料:
https://tridao.me/publications/flash3/flash3.pdf
https://tridao.me/blog/2024/flash3/

