
- 1Mongodb中Security介绍
- 2SQL Server定期收缩日志文件详细步骤——基于SQL Server 2012_sql自动收缩日志文件
- 3Parallels Desktop Business Edition 19.4.0.54962中文破解版
- 4庆祝法国队夺冠:用Python放一场烟花秀
- 5【性能】什么是CPU密集型计算、IO密集型计算与多进程、多线程、多协程_cpu密集计算
- 6Linux工具入门:make工具与Makefile文件
- 7MySql数据操作总结_mysql表数据操作实验总结心得
- 8HashMap详解(含动画演示)
- 9使用Oracle创建数据库_oracle数据库创建代码
- 10Spring tool suite4 安装及配置_springtoolsuite4
AIGC发展方向和前景_aigc 发展相关背景及有利条件
赞
踩
引言
背景介绍
AIGC的定义及其发展历程
AIGC,即人工智能生成内容,是近年来在人工智能领域兴起的一项重要技术。它通过使用机器学习和深度学习等技术,使得计算机能够自动生成各种形式的数字内容,如文本、图像、音频和视频等。
AIGC的发展可以追溯到上世纪80年代,但真正取得突破性进展是在过去的十年里。随着深度学习技术的发展和大数据的积累,AIGC技术在自然语言处理、计算机视觉和语音识别等领域取得了进步。随着互联网和移动互联网的普及,用户对多样化、个性化内容的需求日益增长,这为AIGC技术的应用提供了强大的驱动力。AIGC技术在内容创作、个性化推荐、智能客服等领域的应用,能够有效提高生产效率、降低成本,并提升用户体验。
在国内,百度、腾讯、阿里、科大讯飞、字节跳动等科技巨头在AIGC技术的研究和应用方面取得了许多重要成果,推动了国内AIGC技术的发展。AIGC技术在2023-2024年飞速发展,对多个行业产生了颠覆性的影响。其中AIGC已经在广告、游戏、自媒体等内容创作领域实现了广泛应用,教育、电商、软件开发、金融等领域也尝试扩大AIGC的应用范围。从商业视角来看,AIGC技术可以提高生产效率,降低成本。例如,在内容创作领域,AIGC技术可以帮助创作者更快地生成高质量的内容;AIGC技术可以提供个性化的服务,提高用户体验;AIGC技术可以帮助企业进行创新,帮助领导者开拓新的商业模式。
AIGC是内容生产方式的进阶,实现内容和资产的再创造。AIGC(AI-Generated Content)本质上是一种内容生产方式,即人工智能自动生产内容,是基于深度学习技术,输入数据后由人工智能通过寻找规律并适当泛化从而生成内容的一种方式。过往的内容创作生态主要经历了PGC、UGC到AIUGC的几个阶段,但始终难以平衡创作效率、创作成本及内容质量三者之间的关系,而AIGC可以实现专业创作者和个体自由地发挥创意,降低内容生产的门槛,带来大量内容供给。此外,对于仍处于摸索阶段的元宇宙世界,AIGC技术的发展也带来了解决元宇宙内容创造问题的解决可能,可实现为元宇宙世界构建基石的关键作用。

AIGC技术的前景非常广阔。随着技术的不断进步,AIGC技术有望在更多的领域得到应用,并进一步提高生产效率和用户体验。同时,AIGC技术的发展也面临一些挑战,如数据隐私、算法偏见等问题,需要进一步的研究和解决。总体而言,AIGC技术的发展将对社会产生革命性影响,并成为未来科技发展的重要方向之一。
AIGC在现代社会中的应用场景
本文从各个不同的来源获取AI的应用场景,可以更好的帮助大家选择自己擅长的赛道。
B站上2019年中国AI产业生态图谱:
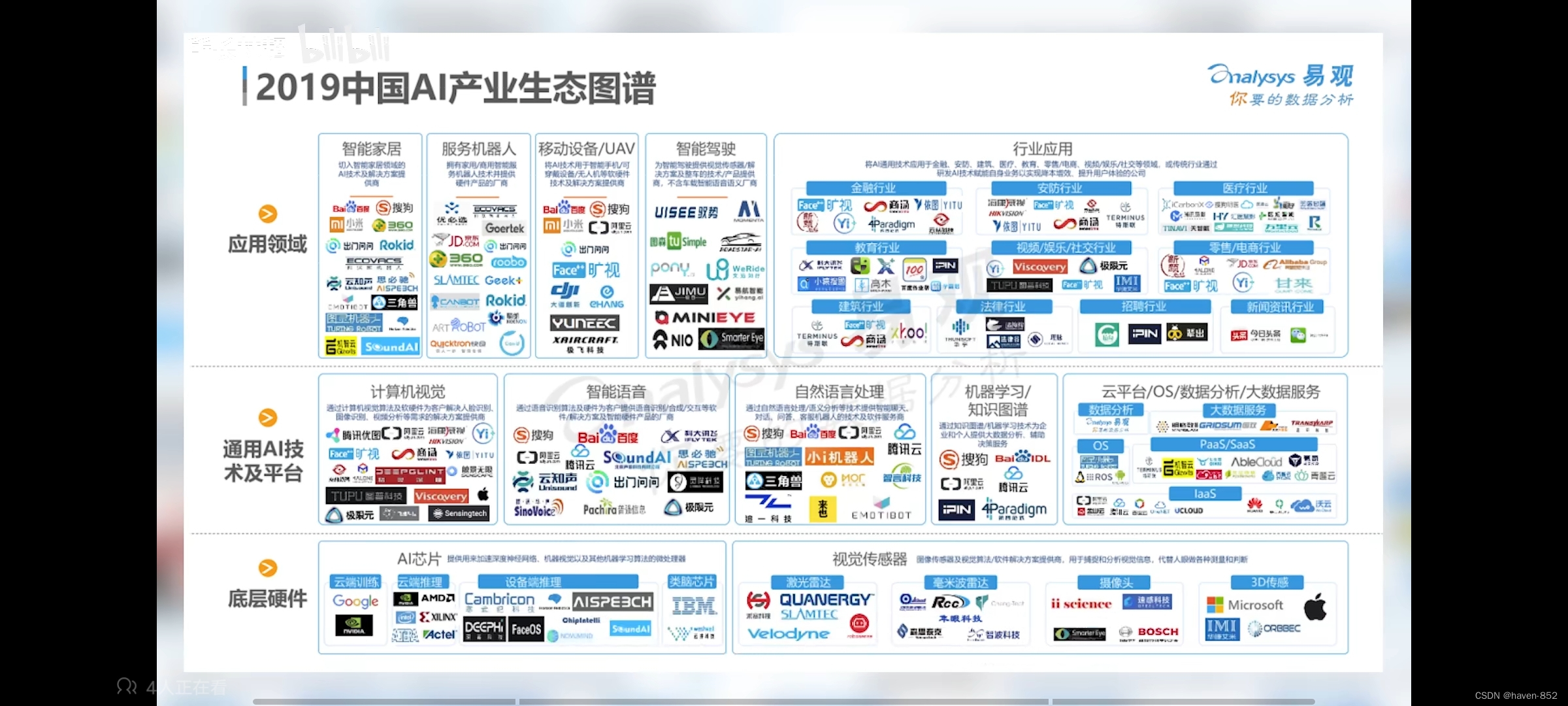
十大人工智能应用场景:
- 智能助手:智能助手是人工智能技术在个人生活中的一种应用,它们可以回答问题,提供日程安排,发送消息等。
- 语音识别:语音识别是人工智能在语言处理领域的一项重要的应用。它可以将人类的语音转化为文本,进而实现语音控制、语音搜索等功能。
- 自然语言处理:自然语言处理是人工智能在理解和处理人类语言方面的应用。他可以用于机器翻译、文本摘要、情感分析等任务。
- 机器学习:机器学习是一种让机器 通过数据自动学习和改进的技术。它在各个领域有广泛应用,包括推荐系统、垃圾邮件过滤、图像识别等。
- 人脸识别:人脸识别是一种利用AI技术对人脸进行识别和验证的应用。它被广泛应用于安全领域、人脸解锁、人脸支付等。
- 自动驾驶:自动驾驶是AI在汽车领域的一项重要应用,通过激光雷达、摄像头和传感器等设备,自动驾驶车辆可以感知周围环境并作出驾驶决策。
- 医疗诊断:AI在医疗领域的应用也越来越多,它可以辅助医生进行疾病诊断,提供精准的治疗方案等。
- 虚拟现实和增强现实(VR & AR):AI在VR和AR的应用正在迅速发展 ,它可以同i共更沉浸式的虚拟体验,并将虚拟和现实世界融合在一起。
- 金融风险管理:金融领域利用AI技术进行风险管理和预测分析,机器学习(Machine Learning,ML)可以分析大量的金融数据,提供风险评估、欺诈检测等服务。
- 智能制造:AI在制造业中的应用被称为智能制造(Smart Manufacturing),它可以用过数据分析和自动化控制,提高生产效率,优化供应链 管理等,例如工业机器人的应用。
AIGC产业
我国AIGC产业发展目前已经发展出了两类主要业态,其一是主要面向 C端用户,提供的产品主要包括文本生成、图片
生成、音频生成、视频生成、虚拟人生成等多样内容形态;其二是主要面向B端企业客户,提供的产品更多是基于特
定领域的专业服务。未来,C端和B端可能会出现“双向奔赴”的趋势,在行业层面汇合。
新一代人工智能示范应用场景

这里先展示一张产业发展路线图,产业发展的起点是能源结构和基础原材料,这些是工业生产和经济活动的基础。能源的多样化和原材料的丰富性直接影响一个国家的工业能力和竞争力。能源和原材料经过初步加工转化为工业品、中间品和化工产品。这些产品是进一步制造和生产的基础,通常涉及较低的附加值。中间品和化工产品经过加工后,转变为消费品和工业品,进入市场供消费者和其他工业部门使用。这一步骤提高了产品的附加值,体现了工业链的延伸。工业发展到一定阶段后,重点转向高附加值产品和工业品的生产。这些产品通常具有高技术含量、创新性和市场竞争力,能够显著提高国家经济的整体效益和产业水平。产业链的最终阶段是高附加值服务的提供。这包括技术服务、研发、设计、咨询等。高附加值服务不仅能增加经济收益,还能促进产业升级和结构优化,提升国家在全球产业链中的地位。国家为了从基础资源走向高附加值产品和服务的产业,必须通过不断向高附加值产业链攀升,国家能够实现产业结构优化,推动经济高质量发展,增强在全球市场的竞争力。由此,国家推出了:科技部关于支持建设新一代人工智能示范应用场景的通知:国家首次明确指出的AI智能赛道,根据以往的经验来看,这十个领域不仅会获得国家的大力 补贴,而且会有广阔的市场,以及庞大的盈利空间。
(一)智慧农场。
针对水稻、玉米、小麦、棉花等农作物生产过程,聚焦“耕、种、管、收”等关键作业环节,运用面向群体智能自主无人作业的农业智能化装备等关键技术,构建农田土壤变化自适应感知、农机行为控制、群体实时协作、智慧农场大脑等规模化作业典型场景,实现农业种植和管理集约化、少人化、精准化。
(二)智能港口。
针对港口大型码头泊位、岸桥管理以及堆场、配载调度等关键业务环节,运用智能化码头机械、数字孪生集成生产时空管控系统等关键技术,开展船舶自动配载、自动作业路径及泊位计划优化、水平运输车辆及新型轨道交通设备的协同调度、智能堆场选位等场景应用,形成覆盖码头运作、运行监测与设备健康管理的智能化解决方案,打造世界一流水平的超大型智能港口。
(三)智能矿山。
针对我国矿山高质量安全发展需求,聚焦井工矿和露天矿,运用人工智能、5G通信、基础软件等新一代自主可控信息技术,建成井工矿“数字网联、无人操作、智能巡视、远程干预”的常态化运行示范采掘工作面,开展露天矿矿车无人驾驶、铲运装协同自主作业示范应用,通过智能化技术减人换人,全面提升我国矿山行业本质安全水平。
(四)智能工厂。
针对流程制造业、离散制造业工厂中生产调度、参数控制、设备健康管理等关键业务环节,综合运用工厂数字孪生、智能控制、优化决策等技术,在生产过程智能决策、柔性化制造、大型设备能耗优化、设备智能诊断与维护等方面形成具有行业特色、可复制推广的智能工厂解决方案,在化工、钢铁、电力、装备制造等重点行业进行示范应用。
(五)智慧家居。
针对未来家庭生活中家电、饮食、陪护、健康管理等个性化、智能化需求,运用云侧智能决策和主动服务、场景引擎和自适应感知等关键技术,加强主动提醒、智能推荐、健康管理、智慧零操作等综合示范应用,推动实现从单品智能到全屋智能、从被动控制到主动学习、各类智慧产品兼容发展的全屋一体化智控覆盖。
(六)智能教育。
针对青少年教育中“备、教、练、测、管”等关键环节,运用学习认知状态感知、无感知异地授课的智慧学习和智慧教室等关键技术,构建虚实融合与跨平台支撑的智能教育基础环境,重点面向欠发达地区中小学,支持开展智能教育示范应用,提升优质教育资源覆盖面,助力乡村振兴和国家教育数字化战略实施。
(七)自动驾驶。
针对自动驾驶从特定道路向常规道路进一步拓展需求,运用车端与路端传感器融合的高准确环境感知与超视距信息共享、车路云一体化的协同决策与控制等关键技术,开展交叉路口、环岛、匝道等复杂行车条件下自动驾驶场景示范应用,推动高速公路无人物流、高级别自动驾驶汽车、智能网联公交车、自主代客泊车等场景发展。
(八)智能诊疗。
针对常见病、慢性病、多发病等诊疗需求,基于医疗领域数据库知识库的规模化构建、大规模医疗人工智能模型训练等智能医疗基础设施,运用人工智能可循证诊疗决策医疗关键技术,建立人工智能赋能医疗服务新模式。重点面向县级医院,提升基层医疗服务水平。
(九)智慧法院。
针对诉讼服务、审判执行、司法管理等法院业务领域,运用非结构化文本语义理解、裁判说理分析推理、风险智能识别等关键技术,加强庭审笔录自动生成、类案智能推送、全案由智能量裁辅助、裁判文书全自动生成、案件卷宗自适应巡查、自动化审判质效评价与监督等智能化场景的应用示范,有效化解案多人少矛盾,促进审判体系和审判能力现代化。
(十)智能供应链。
针对智能仓储、智能配送、冷链运输等关键环节,运用人机交互、物流机械臂控制、反向定制、需求预测与售后追踪等关键技术,优化场景驱动的智能供应链算法,构建智能、高效、协同的供应链体系,推进智能物流与供应链技术规模化落地应用,提升产品库存周转效率,降低物流成本。
研究动机
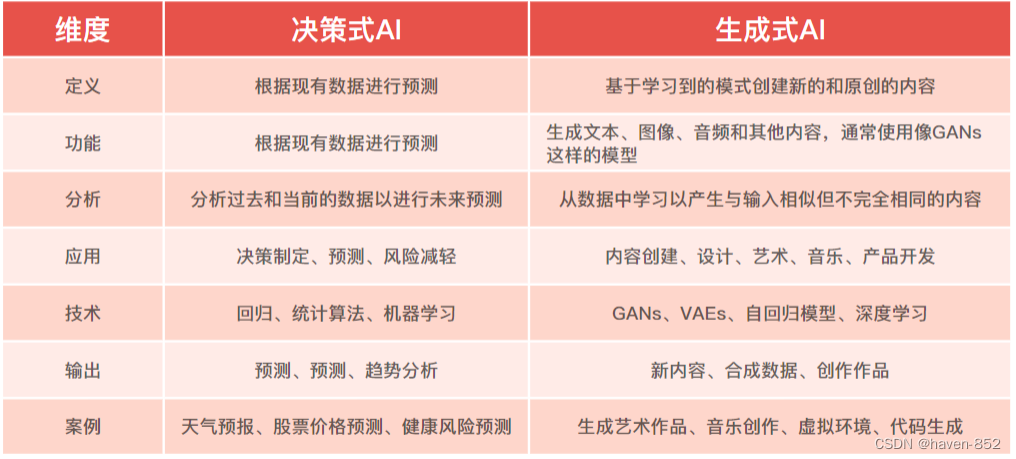
AI的发展经历了从决策式AI到生成式AI的过程。在2010年之前,AI以决策式AI为主导,决策式AI学习数据中的条件概率分布,底层逻辑是AI提取样本特征信息,与数据库中的特征数据进行匹配,最后对样本进行归类,主要针对对样本的识别和分析。2011年之后随着深度机器学习算法以及大规模预训练模型的出现,AI开始迈入生成式AI时代,生成式AI的特征是可以根据已有的数据进行总结归纳,自动生成新的内容,在决策式AI决策、感知能力的基础上开始具备学习、执行、社会协作等方面的能力。当下人工智能在生成(Generation)和通用(General)两条主线上不断发展

AI的发展经历了从决策式AI到生成式AI的过程。在2010年之前,AI以决策式AI为主导(Predictive AI),专注于使用历史数据来预测未来事件。随着深度机器学习算法以及大规模预训练模型的出现,AI开始迈入生成式AI时代(Generative AI),生成式AI的特征是创建之前不存在的全新原创内容,它从训练数据中学习到的模式进行创作。
AIGC迎来了广袤的商业前景和未来主要的科技发展方向。从全球的视域来看,全球AI产业在22年经历了微小的回落之后,23年迎来强劲反弹,仅上半年生成式AI在资本市场便募集约141亿美元的资金,产业在资本市场异常火爆,同时大部分的企业仍处在早期融资轮次,后期仍存在大量的资金需求。由此可见,AIGC将会变成未来10年主要的商机。
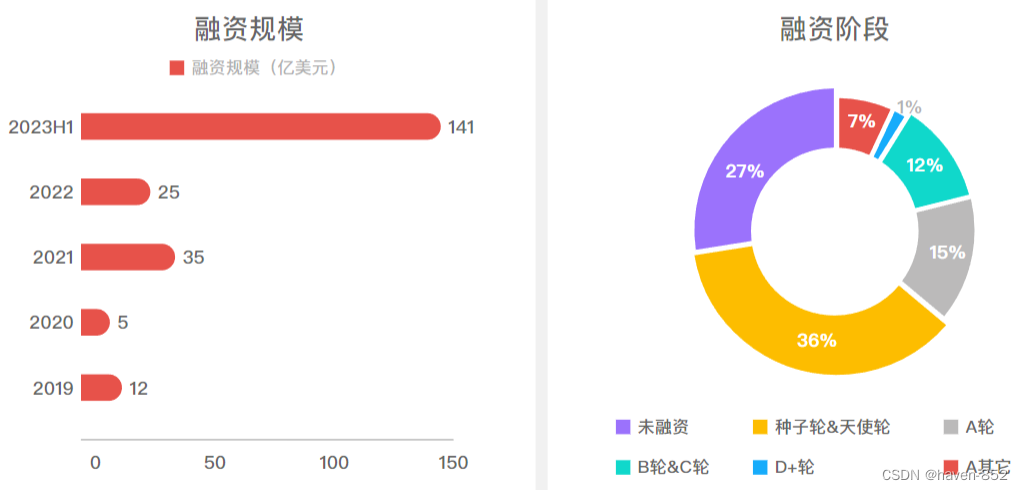
不同数据来源对AIGC未来10年(2022年到2032年)的市场规模预测存在差异,但复合年增⻓率(CAGR值)都表明
该行业有着强劲的增⻓轨迹。彭博财经预测未来10年的CAGR将达到令人印象深刻的42%,而其他来源则提出从2023
年至2032年的CAGR为27.02%。

第一部分:AIGC的技术基础
这里展示AIGC的一些核心论文,这里由于上传图片大小的限制,这里只展示一部分,需要的可以在这个链接进行提取。后面将介绍各个技术的概念、常用算法和应用。
数据增强和预处理
数据增强和预处理是数据科学和机器学习中的两个重要概念,旨在提高模型的性能和鲁棒性。以下是这两个概念的详细介绍、常用算法和应用。
数据增强(Data Augmentation)
概念
数据增强是一种通过对训练数据进行各种变换来生成更多训练样本的方法。这种技术特别常用于图像、文本和音频数据,以增加数据的多样性,防止模型过拟合。
常用算法
- 图像数据增强
- 旋转:随机旋转图像一定角度。
- 平移:随机平移图像在水平或垂直方向上的位置。
- 缩放:随机放大或缩小图像。
- 剪切:随机剪切图像的某个部分。
- 翻转:水平或垂直翻转图像。
- 颜色扰动:调整图像的亮度、对比度、饱和度和色调。
- 随机裁剪:从图像中随机裁剪出一定大小的区域。
- 噪声添加:在图像中添加随机噪声。
- 文本数据增强
- 同义词替换:将句子中的某些词替换为同义词。
- 随机插入:随机向句子中插入一些词。
- 随机删除:随机删除句子中的一些词。
- 随机交换:随机交换句子中两个词的位置。
- 音频数据增强
- 时间偏移:随机将音频片段在时间轴上移动。
- 速度变化:改变音频的播放速度。
- 音量变化:调整音频的音量。
- 添加噪声:在音频中添加背景噪声。
应用
数据增强在图像分类、目标检测、自然语言处理和语音识别等任务中广泛应用。例如,在图像分类中,通过数据增强可以生成更多变种图像,增强模型的泛化能力。
数据预处理(Data Preprocessing)
概念
数据预处理是对原始数据进行清洗、转换和整理的过程,以便于后续的分析和建模。预处理的目标是提高数据质量,消除噪声,处理缺失值,使数据适应模型的要求。
常用算法
- 缺失值处理
- 删除缺失值:直接删除包含缺失值的样本或特征。
- 填充缺失值:使用均值、中位数、众数或其他统计值填充缺失值,或使用插值和预测模型进行填充。
- 数据标准化
- 归一化(Normalization):将数据缩放到一个固定范围(通常是0到1)。
- 标准化(Standardization):将数据转换为均值为0、标准差为1的分布。
- 特征工程
- 特征选择:选择对模型有重要影响的特征,去除无关或冗余特征。
- 特征提取:从原始数据中提取新的、更有信息量的特征。
- 数据清洗
- 去除噪声:过滤掉数据中的异常值和噪声。
- 数据格式转换:将数据转换为适合模型输入的格式,如将分类变量转换为数值变量(独热编码)。
应用
数据预处理在任何数据驱动的任务中都是必不可少的步骤,包括数据分析、机器学习、深度学习等。例如,在金融预测中,通过数据预处理可以清洗和标准化历史数据,以便模型更好地理解和预测未来趋势。
生成对抗网络(GANs)
概念
生成对抗网络(Generative Adversarial Networks, GANs)由Ian Goodfellow等人在2014年提出。GANs由两个神经网络组成:生成器(Generator)和判别器(Discriminator)。这两个网络通过对抗训练(Adversarial Training)相互竞争,从而共同提升性能。
- 生成器(G):生成器接受随机噪声作为输入,并生成逼真的数据样本。其目标是欺骗判别器,使其无法区分生成样本和真实样本。
- 判别器(D):判别器接受数据样本(包括真实样本和生成样本),并输出一个概率值,表示输入样本是真实数据的概率。其目标是尽可能准确地区分真实样本和生成样本。
在训练过程中,生成器和判别器不断地进行博弈:生成器试图生成更加逼真的样本来欺骗判别器,而判别器则不断提高自己的辨别能力,以识别生成样本和真实样本。最终,当生成器生成的样本无法被判别器有效区分时,训练达到平衡。
常用算法
-
基本GAN(Vanilla GAN):这是最基础的GAN结构,生成器和判别器分别由全连接神经网络构成。训练目标是通过最小化交叉熵损失来优化生成器和判别器。
-
DCGAN(Deep Convolutional GAN):使用卷积神经网络(CNN)构建生成器和判别器,特别适用于图像生成任务。DCGAN通过使用卷积层和反卷积层来生成高质量的图像。
-
CGAN(Conditional GAN):在生成过程中引入条件信息,如类别标签或其他辅助信息,从而生成具有特定属性的样本。CGAN通过将条件信息与随机噪声一起输入到生成器和判别器中,来实现条件生成。
-
WGAN(Wasserstein GAN):改进了基本GAN的训练稳定性问题,使用Wasserstein距离(地球移动距离)作为损失函数,能够更好地度量生成样本与真实样本之间的差异。WGAN通过剪裁判别器权重或使用梯度惩罚来确保训练的稳定性。
-
CycleGAN:用于无监督的图像到图像翻译任务,如将马的图像转换为斑马图像,或将夏天的景象转换为冬天的景象。CycleGAN通过引入循环一致性损失(Cycle Consistency Loss),确保生成图像能转换回原始图像。
应用
-
图像生成:GANs可以生成高质量的图像,如人脸生成、风景生成等。这在游戏设计、电影制作等领域具有广泛应用。
-
图像到图像翻译:如风格迁移(Style Transfer)、超分辨率重建(Super-Resolution Reconstruction)、图像修复(Image Inpainting)等。GANs可以将一张图像转换为另一种风格或增强图像的分辨率。
-
数据增强:在医疗影像、自动驾驶等领域,GANs可以生成更多的训练样本,以提高模型的泛化能力和性能。
-
文本生成:GANs不仅能生成图像,还能用于生成文本内容,如诗歌创作、新闻生成等。
-
视频生成:GANs可以用于生成连续的视频帧,应用于动画制作、视频增强等领域。
-
音乐生成:GANs在音乐生成和风格转换中也有应用,可以创作新曲子或将音乐片段转换为不同的风格。
机器学习与深度学习
机器学习(Machine Learning)
概念
机器学习是一种通过从数据中自动学习模型,并使用这些模型进行预测或决策的技术。机器学习主要依赖于统计学和计算理论,通过识别数据中的模式和规律,使计算机能够在没有明确编程指令的情况下进行任务处理。
常用算法
- 监督学习(Supervised Learning)
- 线性回归(Linear Regression):用于预测连续值,如房价预测。
- 逻辑回归(Logistic Regression):用于二分类问题,如垃圾邮件分类。
- 支持向量机(SVM, Support Vector Machine):用于分类和回归任务,能处理高维数据。
- k近邻(k-NN, k-Nearest Neighbors):基于相似性进行分类和回归。
- 决策树(Decision Tree):通过构建树状模型进行分类和回归。
- 随机森林(Random Forest):多个决策树的集成方法,增强模型的稳定性和准确性。
- 神经网络(Neural Networks):模仿生物神经网络的结构和功能,用于复杂的模式识别任务。
- 无监督学习(Unsupervised Learning)
- k均值聚类(k-Means Clustering):将数据点分成k个簇。
- 层次聚类(Hierarchical Clustering):构建层次树状结构的聚类方法。
- 主成分分析(PCA, Principal Component Analysis):用于降维和数据压缩。
- 孤立森林(Isolation Forest):用于异常检测。
- 强化学习(Reinforcement Learning)
- Q学习(Q-Learning):通过动作和奖励的反馈学习最优策略。
- 深度Q网络(DQN, Deep Q-Network):结合深度学习和Q学习,用于复杂环境中的决策问题。
应用
- 推荐系统:如电影推荐、商品推荐。
- 金融预测:如股票价格预测、信用评分。
- 自然语言处理(NLP):如文本分类、情感分析。
- 图像处理:如图像分类、目标检测。
- 医疗诊断:如疾病预测、医学影像分析。
深度学习(Deep Learning)
概念
深度学习是机器学习的一个子领域,主要关注通过深层神经网络(Deep Neural Networks)进行学习和表示复杂数据模式。深度学习通过多层非线性变换和表示,能够自动提取数据中的高级特征。
常用算法
- 卷积神经网络(CNN, Convolutional Neural Networks)用于图像和视频处理,特别擅长于捕捉空间层次的特征。
- 循环神经网络(RNN, Recurrent Neural Networks)用于处理序列数据,如时间序列分析和自然语言处理。
- 长短期记忆网络(LSTM, Long Short-Term Memory)一种改进的RNN,能够捕捉长期依赖关系。
- 生成对抗网络(GANs, Generative Adversarial Networks)用于生成数据,如图像生成、文本生成。
- 自编码器(Autoencoders)用于无监督学习的降维和特征提取。
- Transformer用于自然语言处理中的模型架构,如BERT和GPT系列,擅长处理长文本和并行计算。
应用
- 计算机视觉:如图像分类、对象检测、图像生成。
- 自然语言处理:如机器翻译、文本生成、语音识别。
- 自动驾驶:如车辆检测、路径规划。
- 游戏AI:如AlphaGo,通过深度学习和强化学习结合进行复杂决策。
- 语音处理:如语音识别、语音合成。
- 医疗影像分析:如肿瘤检测、X光图像分析。
自然语言处理(NLP)
自然语言处理(NLP)是人工智能和计算机科学的一个分支,主要研究如何实现计算机与人类语言的交互。NLP包括从文本分析到语音识别的广泛任务,目标是让计算机能够理解、生成和处理自然语言。
概念
NLP的目标是让计算机能够理解和生成人类语言,从而实现人机互动、信息提取、翻译等功能。它涉及语言学、计算机科学、人工智能等多个学科,利用各种算法和模型来处理和分析自然语言数据。
常用算法
- 文本预处理
- 分词(Tokenization):将文本划分为独立的词或子词。
- 词干提取(Stemming)和词形还原(Lemmatization):将词归一化为其基本形式。
- 去停用词(Stop Words Removal):去除无意义的常用词,如"the"、"and"等。
- 文本标准化:将文本中的字符转换为统一格式,如小写转换、去除标点符号。
- 特征提取
- 词袋模型(Bag of Words, BoW):将文本表示为词频向量。
- TF-IDF(Term Frequency-Inverse Document Frequency):评估词的重要性,结合词频和逆文档频率。
- 词向量(Word Embeddings):如Word2Vec、GloVe,将词表示为连续向量,捕捉词之间的语义关系。
- 语言模型
- N-gram模型:基于n个连续词的概率模型,用于文本生成和预测。
- 神经网络语言模型:如RNN、LSTM、GRU,用于捕捉序列数据的依赖关系。
- Transformer模型:如BERT、GPT,基于自注意力机制,能够并行处理文本,并捕捉长距离依赖关系。
- 文本分类
- 朴素贝叶斯(Naive Bayes):基于贝叶斯定理的概率分类算法。
- 支持向量机(SVM, Support Vector Machine):用于分类任务的监督学习模型。
- 深度学习模型:如卷积神经网络(CNN)、循环神经网络(RNN)和Transformer,用于文本分类任务。
- 序列标注
- 隐马尔可夫模型(HMM, Hidden Markov Model):用于标注序列数据,如词性标注。
- 条件随机场(CRF, Conditional Random Fields):用于序列标注任务,如命名实体识别(NER)。
- BiLSTM-CRF:结合双向LSTM和CRF,用于高效的序列标注。
- 生成模型
- 神经机器翻译(NMT, Neural Machine Translation):如基于注意力机制的Seq2Seq模型和Transformer,用于机器翻译任务。
- 生成对抗网络(GANs, Generative Adversarial Networks):用于文本生成和风格转换。
- GPT(Generative Pre-trained Transformer):用于文本生成、对话系统和问答系统。
应用
- 机器翻译:自动将一种语言翻译成另一种语言,如Google翻译、微软翻译。
- 文本分类:如垃圾邮件过滤、情感分析、话题分类。
- 信息检索和问答系统:如搜索引擎、智能问答系统。
- 文本摘要:自动生成文章的简短摘要。
- 命名实体识别(NER):识别文本中的人名、地名、组织名等实体。
- 语音识别:将语音转换为文本,如苹果的Siri、Google Assistant。
- 对话系统:如聊天机器人、客服机器人,用于自动回答用户问题和提供服务。
- 情感分析:分析文本中的情感倾向,如社交媒体评论分析。
- 文本生成:如自动写作、诗歌生成。
计算机视觉
概念
计算机视觉(Computer Vision)是研究如何使计算机从数字图像或视频中获取有用信息的科学和技术。其目标是模拟人类视觉系统的功能,使计算机能够识别、跟踪和理解视觉数据中的对象和场景。
常用算法
- 图像处理和预处理
- 灰度化(Grayscale Conversion):将彩色图像转换为灰度图像。
- 图像滤波(Image Filtering):如高斯滤波、均值滤波、边缘检测等,用于去噪和特征提取。
- 直方图均衡化(Histogram Equalization):增强图像对比度。
- 特征提取
- SIFT(Scale-Invariant Feature Transform):提取图像中的关键点和描述子,具有尺度和旋转不变性。
- SURF(Speeded-Up Robust Features):一种加速的SIFT算法,提取图像特征。
- ORB(Oriented FAST and Rotated BRIEF):一种快速的特征提取和匹配算法。
- HOG(Histogram of Oriented Gradients):用于捕捉图像的梯度方向信息,常用于行人检测。
- 图像分类
- 支持向量机(SVM, Support Vector Machine):用于分类图像特征向量。
- 卷积神经网络(CNN, Convolutional Neural Networks):一种深度学习模型,专门用于处理图像数据,能自动提取和学习图像特征。
- 目标检测
- R-CNN(Regions with Convolutional Neural Networks):通过候选区域提取并使用CNN进行分类。
- Fast R-CNN和Faster R-CNN:改进的R-CNN模型,具有更快的检测速度。
- YOLO(You Only Look Once):一种实时目标检测算法,直接在完整图像上进行目标定位和分类。
- SSD(Single Shot MultiBox Detector):另一种实时目标检测算法,能在不同尺度上进行检测。
- 图像分割
- FCN(Fully Convolutional Networks):一种全卷积网络,用于语义分割,将每个像素分类。
- U-Net:一种常用于医学图像分割的网络,具有编码器-解码器结构。
- Mask R-CNN:在Faster R-CNN的基础上增加了分割分支,实现实例分割。
- 姿态估计
- OpenPose:一种多人体姿态估计算法,能够检测和识别人体关键点。
- PoseNet:一种基于深度学习的姿态估计算法,用于实时人体姿态识别。
- 三维重建
- 立体视觉(Stereo Vision):通过两幅图像的视差计算物体的深度信息。
- 结构光(Structured Light):通过投射光线模式并分析变形来获取三维形状。
应用
- 自动驾驶:通过计算机视觉技术,车辆能够识别道路、交通标志、行人和其他车辆,实现自动驾驶功能。
- 人脸识别:用于身份验证、安防监控、社交媒体标签推荐等。
- 医疗影像分析:辅助医生进行医学诊断,如X光、CT和MRI图像的分析和检测。
- 智能安防:通过监控摄像头进行实时异常行为检测和人脸识别,提升安全性。
- 增强现实(AR)和虚拟现实(VR):通过实时识别和跟踪场景中的物体,实现增强和虚拟环境的互动。
- 工业检测:在制造业中,通过视觉检测系统对产品进行质量控制和缺陷检测。
- 农业:如作物监测、病虫害检测和农产品分类。
- 零售:通过视觉技术实现智能货架管理、顾客行为分析和自动结算系统。
语音生成和识别
语音识别(Automatic Speech Recognition, ASR)
概念
语音识别是将人类语音转换为文本的过程。它涉及语音信号的处理、特征提取以及将这些特征映射为相应的文本序列。目标是使计算机能够理解和处理人类的口语指令和交流。
常用算法
- 特征提取
- MFCC(Mel-Frequency Cepstral Coefficients):将语音信号转换为一组特征向量,用于语音识别的输入。
- PLP(Perceptual Linear Prediction):另一种常用的语音特征提取方法。
- 隐马尔可夫模型(HMM, Hidden Markov Model)传统的语音识别模型,通过状态转移和观测概率来建模语音信号。
- 高斯混合模型(GMM, Gaussian Mixture Model)与HMM结合使用,建模语音信号的概率分布。
- 深度神经网络(DNN, Deep Neural Networks)用于语音特征和文本之间的映射,能够捕捉复杂的语音特征。
- 长短期记忆网络(LSTM, Long Short-Term Memory)处理序列数据,捕捉语音信号中的长期依赖关系。
- 卷积神经网络(CNN, Convolutional Neural Networks)提取语音信号的局部特征,常用于端到端语音识别系统。
- 端到端模型
- CTC(Connectionist Temporal Classification):处理序列对齐问题,实现端到端语音识别。
- Transformer和Attention机制:用于捕捉语音信号中的全局依赖关系,如深度学习模型中的Attention机制。
应用
- 语音助手:如苹果的Siri、谷歌助手、亚马逊的Alexa。
- 自动字幕生成:为视频和音频内容自动生成字幕。
- 语音输入法:将语音转换为文字输入。
- 智能家居:通过语音控制家电和设备。
- 语音翻译:实时语音翻译系统,如Google翻译。
语音生成(Text-to-Speech, TTS)
概念
语音生成是将文本转换为自然语音的过程。目标是使计算机能够以自然和流畅的方式朗读文本,使其能够应用于各种语音输出场景。
常用算法
- 参数合成方法
- LPC(Linear Predictive Coding):基于线性预测编码的语音合成方法。
- Formant Synthesis:基于声道模型合成语音,通过调整共振峰频率和带宽生成语音信号。
- 拼接合成方法
- Unit Selection Synthesis:从大规模录音数据库中选择合适的语音单元拼接成语音。
- 统计参数合成方法
- HMM-based Synthesis:基于HMM的语音合成方法,通过统计模型生成语音参数。
- 深度学习方法
- WaveNet:谷歌提出的一种基于深度神经网络的生成模型,能够生成高质量的语音波形。
- Tacotron:端到端语音生成模型,通过序列到序列的转换直接将文本映射为语音波形。
- Tacotron 2:结合Tacotron和WaveNet,通过生成语音特征和波形,实现高质量的语音合成。
- FastSpeech:通过改进生成过程,提高语音合成速度和质量。
应用
- 语音助手:如智能手机和智能音箱中的语音反馈。
- 导航系统:GPS导航中的语音提示。
- 电子书朗读:将电子书内容转换为语音,方便用户收听。
- 客户服务:自动化客服系统中的语音应答。
- 语言学习:为语言学习者提供标准的语音朗读。
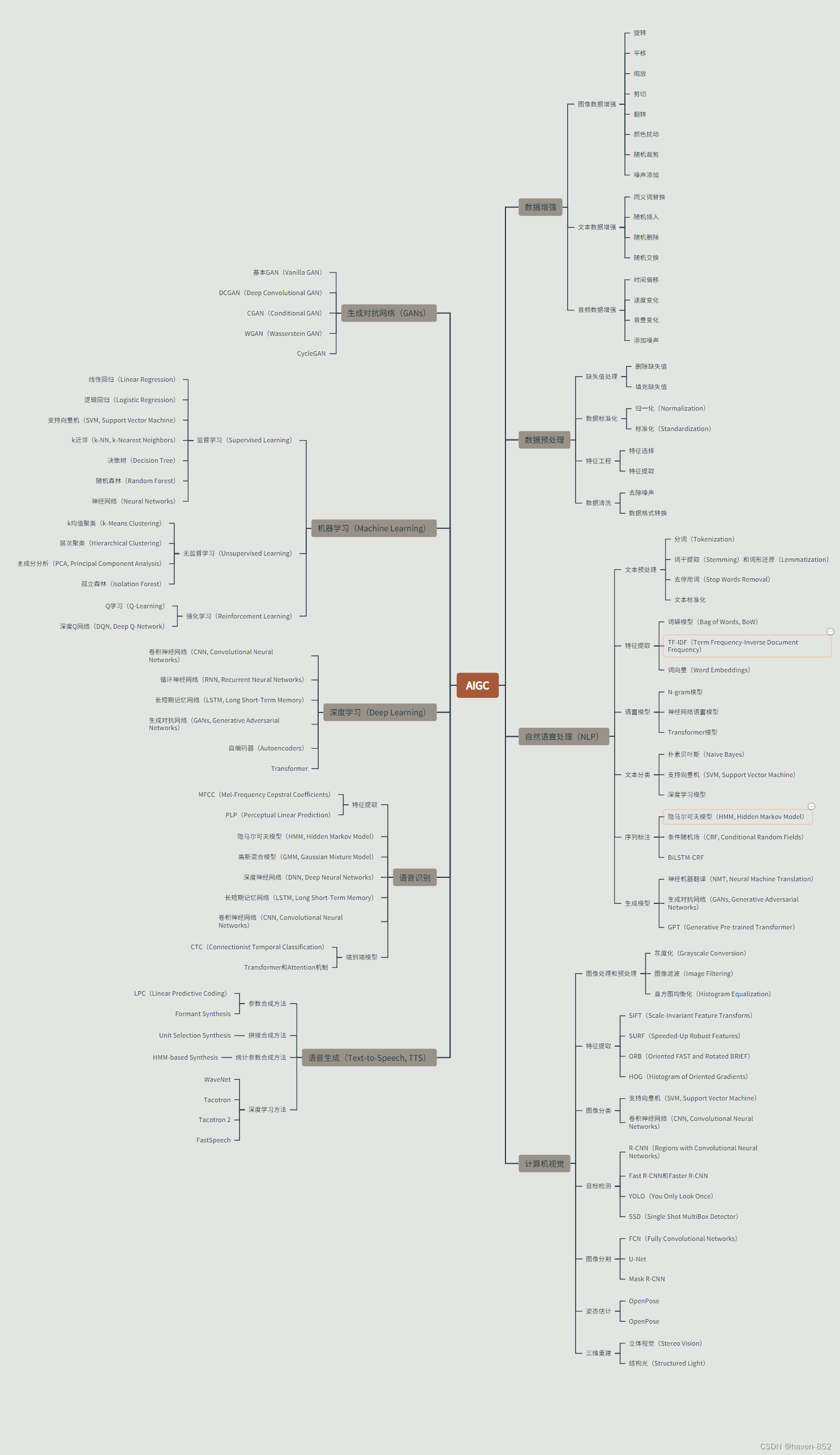
各项技术的思维导图
如果有遗漏的,希望各位读者能不吝赐教,
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

