
热门标签
热门文章
- 1python从入门到精通第三版,python3.8从入门到精通pdf_python3.8从入门到精通pdf百度云下载
- 2maven:下载和安装_aide maven仓库
- 3oracle 把某用户下的表权限授权给另一用户_jbqd
- 4【C++】string类的基础操作_c++ string
- 5展锐NewGallery2移植AndroidStudio指南(2024)_展锐android移植
- 6Mysql常用SQL:日期转换成周_DAYOFWEEK(date)_mysql dayofweek
- 7绕过 Android SSL Pinning
- 8MySQL:查询(万字超详细版)_mysql查询据命令
- 9二叉树OJ题
- 10【数据结构初阶】新学期带你领跑二叉树,二叉树的迭代遍历,递归遍历详解,建议收藏
当前位置: article > 正文
Python爬虫——爬取某网站的视频_python爬取bilibili视频
作者:神奇cpp | 2024-08-21 14:53:51
赞
踩
python爬取bilibili视频
爬取视频

-
本次爬取,还是运用的是requests方法
-
首先进入此网站中,选取你想要爬取的视频,进入视频播放页面,按F12,将网络中的名称栏向上拉找到第一个并点击,可以在标头中,找到后续我们想要的一些信息。

-
爬取视频的步骤大致分为
- 1、UA伪装
- 2、获取url
- 3、发送请求
- 4、获取响应的数据
- 5、数据解析
- 获取存放视频和音频数据的"window.playinfo"文本内容
- 分别获取视频和音频的url
- 将获取到的视频和音频数据存放在两个不同的文件中
-
UA伪装
- 找到Cookie并复制—>用户登陆此网站的个人Cookie信息,每个人的都不同
- 找到Referer并复制—>每个网站的防盗链
- 找到User-Agent并复制—>标头的最下面


# UA伪装 head = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0" # 防盗链子 , "Referer":"https://www.bilibili.com/" , "Cookie":"CURRENT_FNVAL=4048; buvid3=BE2D386A-BBCB-E06E-8C2B-F5223B4C8BC517591infoc; b_nut=1721567317; _uuid=67165DF10-7B77-BDE8-3C63-732C2FCAF4D520375infoc; enable_web_push=DISABLE; buvid4=0245F01B-6C4B-CD5A-2EC5-BC060EC0777D18433-024072113-zRTpkL0r94scQqxGfSYKhQ%3D%3D; home_feed_column=5; header_theme_version=CLOSE; rpdid=|(Y|RJRR)Y~0J'u~kulY~Rkk; DedeUserID=1611307689; DedeUserID__ckMd5=b0865dba0b3ced5b; buvid_fp_plain=undefined; is-2022-channel=1; b_lsid=D8542F24_191412D93C0; bsource=search_bing; bmg_af_switch=1; bmg_src_def_domain=i1.hdslb.com; browser_resolution=1659-943; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MjM2MzQ1OTMsImlhdCI6MTcyMzM3NTMzMywicGx0IjotMX0.Ox8rnEpQH5i1H_wQfH2z5CzZC0y8PlqQCy1KVa8XEfQ; bili_ticket_expires=1723634533; SESSDATA=f567fef6%2C1738927393%2C5d207%2A82CjAh2pSUKwDLr1XiI6ncU5B6NXEfWKS7ES6mDC8yGxM6aT3-BTdvK0KAlYpMhCXtEXgSVkl2aTlQWUNacTZOZ0ZNXzJwZ21QT2ozMXFXcWtFc1FpNnBIWlNWbml2Y3BxNV80bUNMZTBVN1dyb3h0STU1ZklDM0MwckJvanRmTmNkeTBFcW5qYl9RIIEC; bili_jct=8d788bcb503d69ba2ded7dfbb53f6e58; sid=71po5kkf; fingerprint=0c7279b7c69b9542a76b8d9df9b7872a; buvid_fp=BE2D386A-BBCB-E06E-8C2B-F5223B4C8BC517591infoc; bp_t_offset_1611307689=964382000909647872" }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
获取url
-
可以在标头中看到请求URL

# 指定url 自定义一个变量接收 url = "https://www.bilibili.com/video/BV17w4m1e7PT/?spm_id_from=333.1007.tianma.1-1-1.click&vd_source=2a6e427465a2f829272f5863986dfa80"- 1
- 2
-
-
发送请求
- 可以在标头中看到请求方式,这里的请求方式是GET方法
# 发送请求,这里的请求方式是get方法 response = requests.get(url, headers = head)- 1
- 2
- 可以在标头中看到请求方式,这里的请求方式是GET方法
-
获取响应的数据
- 这里使用requests中的response.text方法
# 获取响应的数据 res_text = response.text- 1
- 2
- 这里使用requests中的response.text方法
-
数据解析
-
使用 lxml 库中的 etree 方法
-
并将获取到的数据写入到一个html的文件中,进入这个文件可以通过浏览器打开,查看是否是我们将要获取视频的页面
tree = etree.HTML(res_text) with open("bili2.html", "w", encoding="utf-8") as f: f.write(res_text)- 1
- 2
- 3
- 4
-
获取存放视频和音频数据的"window.–playinfo–"文本内容
-
因为视频和音频的数据都存在window.–playinfo–中,因此我们需要在元素栏下通过标签定位到它,但是我们只需要其内容
-
因为window.–playinfo–的内容是一个大json字符串,所以我们可以通过json.loads的方法将它变成一个字典,方便后面通过键来取视频和音频的数据

base_info = "".join(tree.xpath("/html/head/script[4]/text()"))[20:] info_dict = json.loads(base_info)- 1
- 2
-
-
分别获取视频和音频的url
-
在元素栏中可以看出window.–playinfo–的内容太多了,不利于我们寻找视频和音频的数据,我们可以在网络栏下,名称中第一个数据的响应中也可以找到,耐心一点向下慢慢通过标签找到window.–playinfo–,再在其中找到视频和音频的baseUrl
-
获取后,再次通过get请求方式,发送请求
-
注意:图片,视频和音频都是二进制内容,所以用content属性获取



video_url = info_dict["data"]["dash"]['video'][0]["baseUrl"] audio_url = info_dict["data"]["dash"]['audio'][0]["baseUrl"] video_content = requests.get(video_url, headers=head).content audio_content = requests.get(audio_url, headers=head).content- 1
- 2
- 3
- 4
- 5
-
-
-
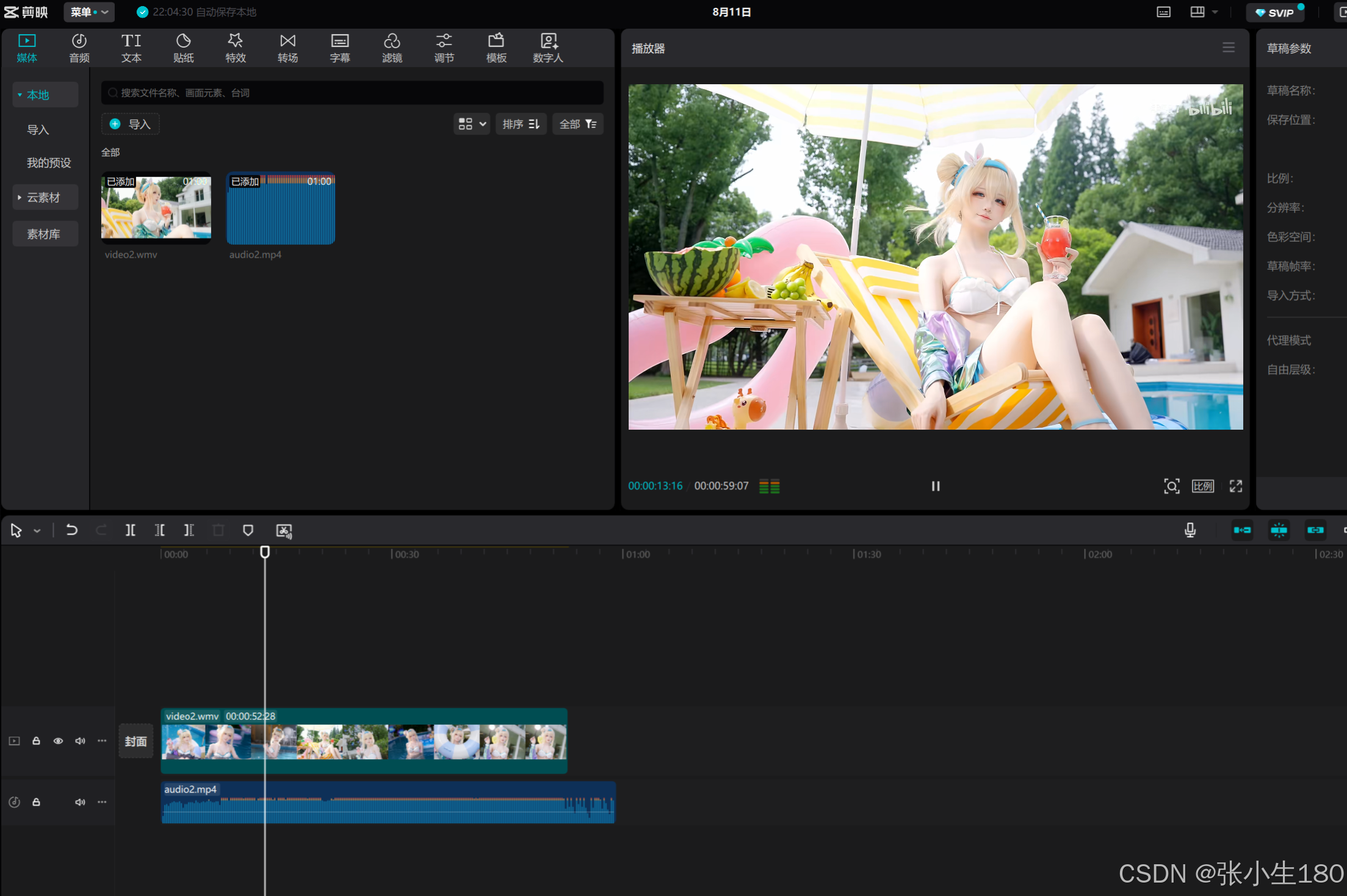
最后将获取到的视频和音频的数据分别存放在两个不同的文件中,视频可以是MP4或者是wmv格式,音频是MP4格式
with open("video2.wmv", "wb") as f:
f.write(video_content)
with open("audio2.mp4", "wb") as fp:
fp.write(audio_content)
- 1
- 2
- 3
- 4
- 完整代码
import requests from lxml import etree import json if __name__ == '__main__': # UA伪装 head = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36 Edg/127.0.0.0" # 防盗链子 , "Referer":"https://www.bilibili.com/" , "Cookie":"CURRENT_FNVAL=4048; buvid3=BE2D386A-BBCB-E06E-8C2B-F5223B4C8BC517591infoc; b_nut=1721567317; _uuid=67165DF10-7B77-BDE8-3C63-732C2FCAF4D520375infoc; enable_web_push=DISABLE; buvid4=0245F01B-6C4B-CD5A-2EC5-BC060EC0777D18433-024072113-zRTpkL0r94scQqxGfSYKhQ%3D%3D; home_feed_column=5; header_theme_version=CLOSE; rpdid=|(Y|RJRR)Y~0J'u~kulY~Rkk; DedeUserID=1611307689; DedeUserID__ckMd5=b0865dba0b3ced5b; buvid_fp_plain=undefined; is-2022-channel=1; b_lsid=D8542F24_191412D93C0; bsource=search_bing; bmg_af_switch=1; bmg_src_def_domain=i1.hdslb.com; browser_resolution=1659-943; bili_ticket=eyJhbGciOiJIUzI1NiIsImtpZCI6InMwMyIsInR5cCI6IkpXVCJ9.eyJleHAiOjE3MjM2MzQ1OTMsImlhdCI6MTcyMzM3NTMzMywicGx0IjotMX0.Ox8rnEpQH5i1H_wQfH2z5CzZC0y8PlqQCy1KVa8XEfQ; bili_ticket_expires=1723634533; SESSDATA=f567fef6%2C1738927393%2C5d207%2A82CjAh2pSUKwDLr1XiI6ncU5B6NXEfWKS7ES6mDC8yGxM6aT3-BTdvK0KAlYpMhCXtEXgSVkl2aTlQWUNacTZOZ0ZNXzJwZ21QT2ozMXFXcWtFc1FpNnBIWlNWbml2Y3BxNV80bUNMZTBVN1dyb3h0STU1ZklDM0MwckJvanRmTmNkeTBFcW5qYl9RIIEC; bili_jct=8d788bcb503d69ba2ded7dfbb53f6e58; sid=71po5kkf; fingerprint=0c7279b7c69b9542a76b8d9df9b7872a; buvid_fp=BE2D386A-BBCB-E06E-8C2B-F5223B4C8BC517591infoc; bp_t_offset_1611307689=964382000909647872" } # 1、指定url url = "https://www.bilibili.com/video/BV17w4m1e7PT/?spm_id_from=333.1007.tianma.1-1-1.click&vd_source=2a6e427465a2f829272f5863986dfa80" # 2、发送请求 response = requests.get(url, headers = head) # 3、获取响应的数据 res_text = response.text # 4、数据解析 tree = etree.HTML(res_text) with open("bili2.html", "w", encoding="utf-8") as f: f.write(res_text) base_info = "".join(tree.xpath("/html/head/script[4]/text()"))[20:] info_dict = json.loads(base_info) video_url = info_dict["data"]["dash"]['video'][0]["baseUrl"] audio_url = info_dict["data"]["dash"]['audio'][0]["baseUrl"] video_content = requests.get(video_url, headers=head).content audio_content = requests.get(audio_url, headers=head).content with open("video2.wmv", "wb") as f: f.write(video_content) with open("audio2.mp4", "wb") as fp: fp.write(audio_content)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 注意!!!注意!!!注意!!!
- 获取到的是视频和音频两个文件,所以播放时也只能分开播放,也有方法可以将其合并,但是比较繁琐,可以先通过这种方法获取视频练一练,后期再学习合并的方法。
- 其实有一种很简单的方法就是将这两个文件,放到剪映中合并,效果也是一样的
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/1012262
推荐阅读

相关标签

