- 1史上最快的推理终端来啦!Groq API 新手入门指南
- 2软件测试面试题之自动化测试题合集(金九银十必备)_自动化测试笔试题
- 3Mybatis (plus 也适用)原生直接执行某句SQL_mybatis plus 直接执行sql
- 4重磅!2024智源大会完整日程公布——全球大模型先锋集结
- 5实验07 因子分析_因子分析实验
- 6鸿蒙一次开发,多端部署(七)响应式布局_鸿蒙breakpointsystem
- 7chatgpt赋能python:Python编译成C代码的完整指南_将python代码转换成c代码
- 8PHP设计网站登录功能_php用户名密码登录界面
- 9【Asp.Net Core】C#解析Markdown文档_c# markdown
- 10大数据 深度学习毕业论文(毕设)课题汇总_深度学习的毕设论文怎么写
【YOLOv10: 利用最先进的多尺度前馈网络革新目标检测技术】_ultralytics
赞
踩
本文改进:多尺度前馈网络(MSFN),通过提取不同尺度的特征来增强特征提取能力
1.YOLOv10介绍

论文:[https://arxiv.org/pdf/2405.14458]
代码: https://gitcode.com/THU-MIG/yolov10?utm_source=csdn_github_accelerator&isLogin=1
摘要:在过去的几年里,由于其在计算成本和检测性能之间的有效平衡,YOLOS已经成为实时目标检测领域的主导范例。研究人员已经探索了YOLOS的架构设计、优化目标、数据增强策略等,并取得了显著进展。然而,对用于后处理的非最大抑制(NMS〉的依赖妨碍了YOLOS的端到端部署,并且影响了推理延迟。此外, YOLOS中各部件的设计缺乏全面和彻底的检查,导致明显的计算冗余,限制了模型的性能。这导致次优的效率,以及相当大的性能改进潜力。
在这项工作中,我们的目标是从后处理和模型架构两个方面进一步推进YOLOS的性能-效率边界。为此,我们首先提出了用于YOLOs无NMS训练的持续双重分配,该方法带来了有竞争力的性能和低推理延迟。此外,我们还介绍了YOLOS的整体效率-精度驱动模型设计策略。我们从效率和精度两个角度对YOLOS的各个组件进行了全面优化,大大降低了计算开销,增强了性能。
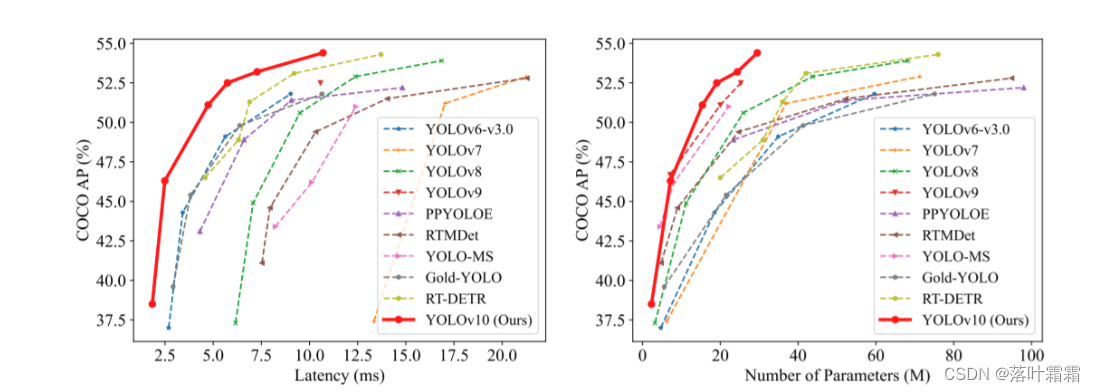
我们努力的成果是用于实时端到端对象检测的新一代YOLO系列,称为YOLOV10。广泛的实验表明,YOLOV10在各种模型规模上实现了最先进的性能和效率。例如,在COCO上的类似AP下,我们的YOLOV10-8比RT-DETR-R18快1.8倍,同时具有2.8倍更少的参数和FLOPS。与YOLOV9-c相比,YOLOV10-B在性能相同的情况下,延迟减少了46%,参数减少了25%。
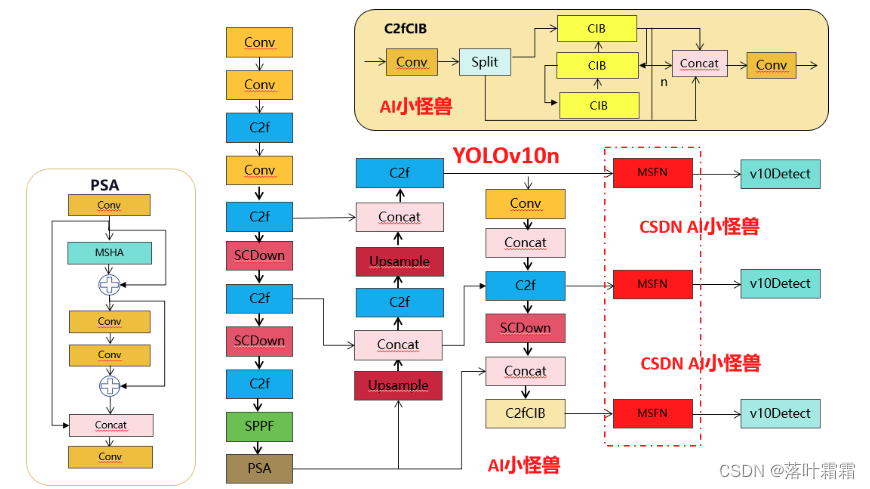
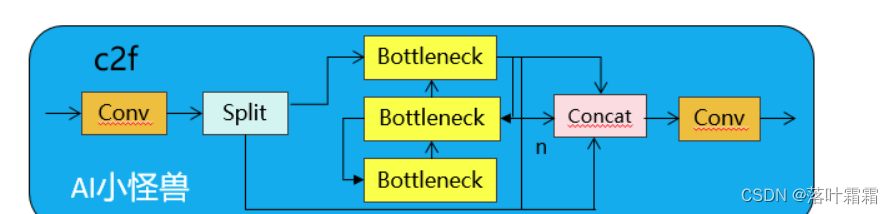
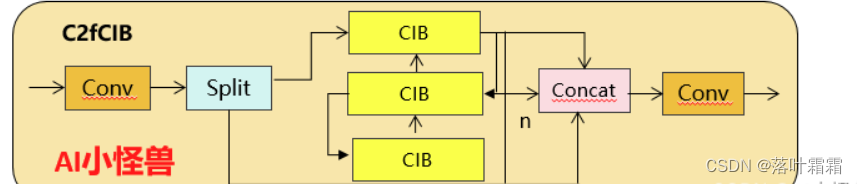
1.1C2fUIB介绍
为了解决这个问题,我们提出了一种基于秩的块设计方案,旨在通过紧凑的架构设计降低被证明是冗余的阶段复杂度我们首先提出了一个紧凑的倒置块(CIB)结构,它采用廉价的深度可分离卷积进行空间混合,以及成本效益高的点对点卷积进行通道混合C2fUIB只是用CIB结构替换了YOLOv8中C2f的Bottleneck结构
实现代码ultralytics/nn/modules/block.py
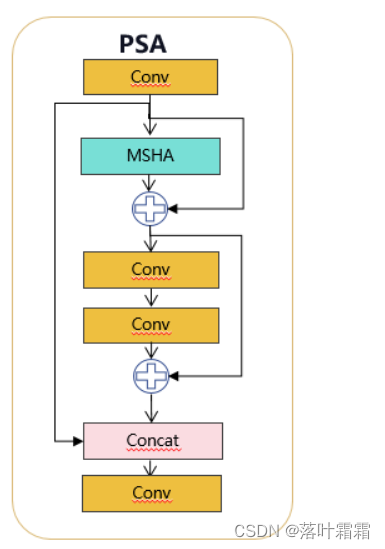
1.2 PSA介绍
具体来说,我们在1×1卷积后将特征均匀地分为两部分。我们只将一部分输入到由多头自注意力模块(MHSA)和前馈网络(FFN)组成的NPSA块中。然后,两部分通过1×1卷积连接并融合。此外,遵循将查询和键的维度分配为值的一半,并用BatchNorm替换LayerNorm以实现快速推理。
实现代码ultralytics/nn/modules/block.py
1.3 SCDown
OLOs通常利用常规的3×3标准卷积,步长为2,同时实现空间下采样(从H×W到H/2×W/2)和通道变换(从C到2C)。这引入了不可忽视的计算成本O(9HWC·2)和参数数量0(18C’2)。相反,我们提议将空间缩减和通道增加操作解耦,以实现更高效的下采样。
具体来说,我们首先利用点对点卷积来调整通道维度,然后利用深度可分离卷积进行空间下采样。这将计算成本降低到O(2HWC^2 +9HWC),并将参数数量减少到O(2C^2 + 18C)。同时,它最大限度地保留了下采样过程中的信息,从而在减少延迟的同时保持了有竞争力的性能。
实现代码ultralytics/nn/modules/block.py
2.原理介绍
论文:
https:llarxiv.org/pdf/2403.10067.pdf
摘要:
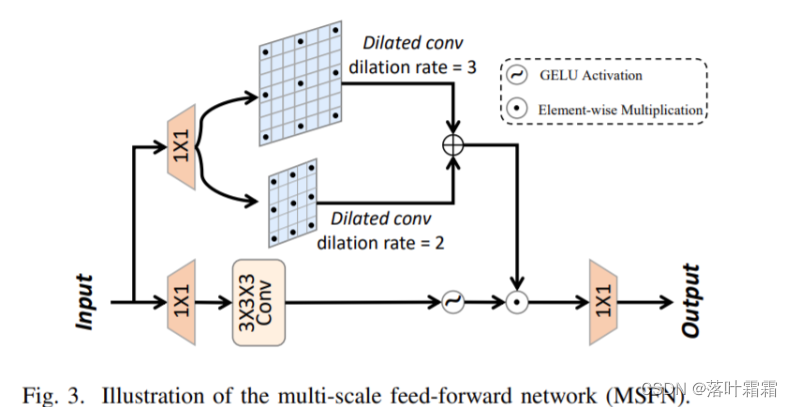
高光谱图像去噪对于高光谱数据的有效分析和解释至关重要。然而,同时建模全局和局部特征以增强HSI去噪的研究很少。在这封信中,我们提出了一个混合卷积和注意力网络(HCANet),它利用了卷积神经网络(cnn)和变压器的优势。为了增强对全局和局部特征的建模,我们设计了一个卷积和注意力融合模块,旨在捕获远程依赖关系和邻域光谱相关性。此外,为了改善多尺度Q信息聚合,我们设计了一个多尺度前馈网络,通过提取不同尺度的特征来增强去噪性能。在主流HSI数据集上的实验结果验证了该算法的合理性和有效性。该模型能够有效地去除各种类型的复杂噪声。
为了解决上述两个挑战,我们提出了一种用于HSI去噪的混合卷积和注意网络(HCANet),它同时利用了全局上下文信息和局部特征,如图1所示。具体来说,为了增强全局和局部特征的建模,我们设计了一个卷积和注意力融合模块(CAFM),旨在捕获远程依赖关系和邻域光谱相关性。此外,为了改善FFN的多尺度信息聚合,我们设计了一个多尺度前馈网络(MSFN),通过提取不同尺度的特征来增强去噪性能。在MSFN中使用了三个不同步长的平行扩展卷积。通过在两个真实数据集Q上进行实验,我们验证了我们提出的HCANet优于其他最先进的竞争对手。
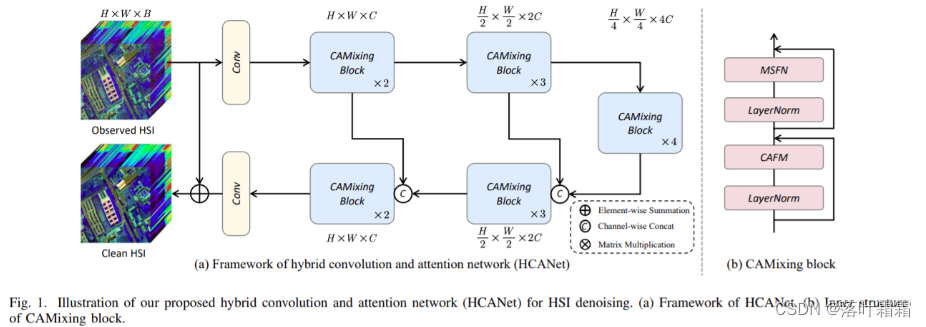
图1所示。我们提出的用于HSI去噪的混合卷积和注意网络(HCANet)的说明。(a)HCANet框架。(b)CAMixing内部结构图。
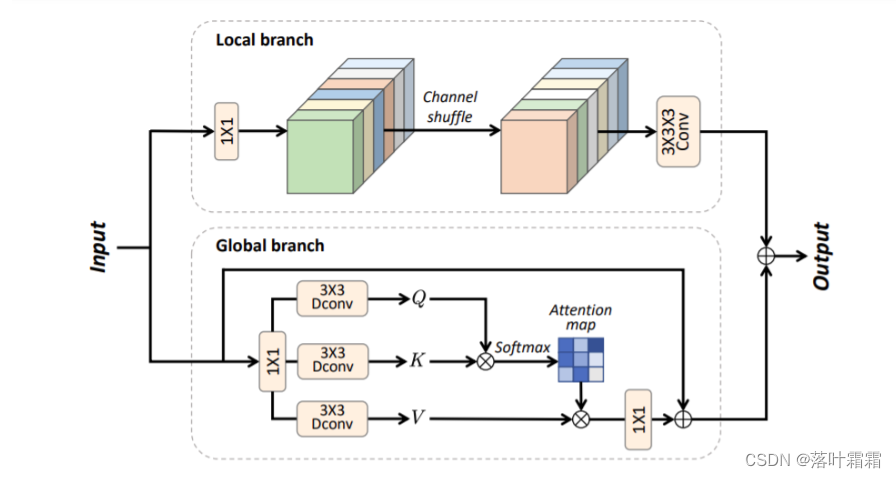

图2所示。所提出的卷积和注意融合模块(CAFM)的示意图。它由全局和局部分支机构组成。在局部分支中,采用卷积和信道变换进行局部特征提取口。在全局分支中,注意机制被用于建模远程特征依赖。
我们提出了用于高光谱图像去噪的混合卷积和注意网络(HCANet)。如图1所示,模型的主要结构是一个Ushaped网络,其中包含多个Convolution !Attention Mixing (CAMixing)块。每个混合块包括两个部分:卷积-注意融合模块(CAFM)和多尺度前馈网络(MSFN)。对于HS,3D卷积全面捕获空间和光谱特征,但增加了参数。为了管理复杂性,我们使用2D卷积进行通道调整,有效地利用了HSI特征
3.MSFN将入到YOLOv10
3.1加入ultralytics/nn/backbone/HCANet.py
import sys import torch import torch.nn as nn import torch.nn.functional as F from pdb import set_trace as stx import numbers from einops import rearrange import os sys.path.append(os.getcwd()) # m_seed = 1 # # 设置seed # torch.manual_seed(m_seed) # torch.cuda.manual_seed_all(m_seed) def to_3d(x): return rearrange(x, 'b c h w -> b (h w) c') def to_4d(x, h, w): return rearrange(x, 'b (h w) c -> b c h w', h=h, w=w) class BiasFree_LayerNorm(nn.Module): def __init__(self, normalized_shape): super(BiasFree_LayerNorm, self).__init__() if isinstance(normalized_shape, numbers.Integral): normalized_shape = (normalized_shape,) normalized_shape = torch.Size(normalized_shape) assert len(normalized_shape) == 1 self.weight = nn.Parameter(torch.ones(normalized_shape)) self.normalized_shape = normalized_shape def forward(self, x): sigma = x.var(-1, keepdim=True, unbiased=False) return x / torch.sqrt(sigma + 1e-5) * self.weight class WithBias_LayerNorm(nn.Module): def __init__(self, normalized_shape): super(WithBias_LayerNorm, self).__init__() if isinstance(normalized_shape, numbers.Integral): normalized_shape = (normalized_shape,) normalized_shape = torch.Size(normalized_shape) assert len(normalized_shape) == 1 self.weight = nn.Parameter(torch.ones(normalized_shape)) self.bias = nn.Parameter(torch.zeros(normalized_shape)) self.normalized_shape = normalized_shape def forward(self, x): mu = x.mean(-1, keepdim=True) sigma = x.var(-1, keepdim=True, unbiased=False) return (x - mu) / torch.sqrt(sigma + 1e-5) * self.weight + self.bias class LayerNorm(nn.Module): def __init__(self, dim, LayerNorm_type): super(LayerNorm, self).__init__() if LayerNorm_type == 'BiasFree': self.body = BiasFree_LayerNorm(dim) else: self.body = WithBias_LayerNorm(dim) def forward(self, x): h, w = x.shape[-2:] return to_4d(self.body(to_3d(x)), h, w) ########################################################################## ## Multi-Scale Feed-Forward Network (MSFN) class MSFN(nn.Module): def __init__(self, dim, ffn_expansion_factor=2.66, bias=False): super(MSFN, self).__init__() hidden_features = int(dim * ffn_expansion_factor) self.project_in = nn.Conv3d(dim, hidden_features * 3, kernel_size=(1, 1, 1), bias=bias) self.dwconv1 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3, 3, 3), stride=1, dilation=1, padding=1, groups=hidden_features, bias=bias) # self.dwconv2 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3,3,3), stride=1, dilation=2, padding=2, groups=hidden_features, bias=bias) # self.dwconv3 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3,3,3), stride=1, dilation=3, padding=3, groups=hidden_features, bias=bias) self.dwconv2 = nn.Conv2d(hidden_features, hidden_features, kernel_size=(3, 3), stride=1, dilation=2, padding=2, groups=hidden_features, bias=bias) self.dwconv3 = nn.Conv2d(hidden_features, hidden_features, kernel_size=(3, 3), stride=1, dilation=3, padding=3, groups=hidden_features, bias=bias) self.project_out = nn.Conv3d(hidden_features, dim, kernel_size=(1, 1, 1), bias=bias) def forward(self, x): x = x.unsqueeze(2) x = self.project_in(x) x1, x2, x3 = x.chunk(3, dim=1) x1 = self.dwconv1(x1).squeeze(2) x2 = self.dwconv2(x2.squeeze(2)) x3 = self.dwconv3(x3.squeeze(2)) # x1 = self.dwconv1(x1) # x2 = self.dwconv2(x2) # x3 = self.dwconv3(x3) x = F.gelu(x1) * x2 * x3 x = x.unsqueeze(2) x = self.project_out(x) x = x.squeeze(2) return x ########################################################################## ## Convolution and Attention Fusion Module (CAFM) class CAFMAttention(nn.Module): def __init__(self, dim, num_heads, bias=False): super(CAFMAttention, self).__init__() self.num_heads = num_heads self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1)) self.qkv = nn.Conv3d(dim, dim * 3, kernel_size=(1, 1, 1), bias=bias) self.qkv_dwconv = nn.Conv3d(dim * 3, dim * 3, kernel_size=(3, 3, 3), stride=1, padding=1, groups=dim * 3, bias=bias) self.project_out = nn.Conv3d(dim, dim, kernel_size=(1, 1, 1), bias=bias) self.fc = nn.Conv3d(3 * self.num_heads, 9, kernel_size=(1, 1, 1), bias=True) self.dep_conv = nn.Conv3d(9 * dim // self.num_heads, dim, kernel_size=(3, 3, 3), bias=True, groups=dim // self.num_heads, padding=1) def forward(self, x): b, c, h, w = x.shape x = x.unsqueeze(2) qkv = self.qkv_dwconv(self.qkv(x)) qkv = qkv.squeeze(2) f_conv = qkv.permute(0, 2, 3, 1) f_all = qkv.reshape(f_conv.shape[0], h * w, 3 * self.num_heads, -1).permute(0, 2, 1, 3) f_all = self.fc(f_all.unsqueeze(2)) f_all = f_all.squeeze(2) # local conv f_conv = f_all.permute(0, 3, 1, 2).reshape(x.shape[0], 9 * x.shape[1] // self.num_heads, h, w) f_conv = f_conv.unsqueeze(2) out_conv = self.dep_conv(f_conv) # B, C, H, W out_conv = out_conv.squeeze(2) # global SA q, k, v = qkv.chunk(3, dim=1) q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads) k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads) v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads) q = torch.nn.functional.normalize(q, dim=-1) k = torch.nn.functional.normalize(k, dim=-1) attn = (q @ k.transpose(-2, -1)) * self.temperature attn = attn.softmax(dim=-1) out = (attn @ v) out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w) out = out.unsqueeze(2) out = self.project_out(out) out = out.squeeze(2) output = out + out_conv return output ########################################################################## ## CAMixing Block class CAMixingTransformerBlock(nn.Module): def __init__(self, dim, num_heads, ffn_expansion_factor=2.66, bias=False, LayerNorm_type='WithBias'): super(CAMixingTransformerBlock, self).__init__() self.norm1 = LayerNorm(dim, LayerNorm_type) self.attn = CAFMAttention(dim, num_heads, bias) self.norm2 = LayerNorm(dim, LayerNorm_type) self.ffn = MSFN(dim, ffn_expansion_factor, bias) def forward(self, x): x = x + self.attn(self.norm1(x)) x = x + self.ffn(self.norm2(x)) return x

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
3.2修改task.py
1)首先进行引用定义
from ultralytics.nn.backbone.HCANet import MSFN
- 1
2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain if m in { Classify, Conv, ConvTranspose, GhostConv, Bottleneck, GhostBottleneck, SPP, SPPF, DWConv, Focus, BottleneckCSP, C1, C2, C2f, RepNCSPELAN4, ADown, SPPELAN, C2fAttn, C3, C3TR, C3Ghost, nn.ConvTranspose2d, DWConvTranspose2d, C3x, RepC3, PSA, SCDown, C2fCIB, MSFN }: c1, c2 = ch[f], args[0] if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output) c2 = make_divisible(min(c2, max_channels) * width, 8) if m is C2fAttn: args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channels args[2] = int( max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2] ) # num heads args = [c1, c2, *args[1:]] if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3, C2fCIB): args.insert(2, n) # number of repeats n = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
3.3 yolov10n-MSFN.yaml
# Parameters nc: 80 # number of classes scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n' # [depth, width, max_channels] n: [0.33, 0.25, 1024] # YOLOv8.0n backbone backbone: # [from, repeats, module, args] - [-1, 1, Conv, [64, 3, 2]] # 0-P1/2 - [-1, 1, Conv, [128, 3, 2]] # 1-P2/4 - [-1, 3, C2f, [128, True]] - [-1, 1, Conv, [256, 3, 2]] # 3-P3/8 - [-1, 6, C2f, [256, True]] - [-1, 1, SCDown, [512, 3, 2]] # 5-P4/16 - [-1, 6, C2f, [512, True]] - [-1, 1, SCDown, [1024, 3, 2]] # 7-P5/32 - [-1, 3, C2f, [1024, True]] - [-1, 1, SPPF, [1024, 5]] # 9 - [-1, 1, PSA, [1024]] # 10 # YOLOv8.0n head head: - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 6], 1, Concat, [1]] # cat backbone P4 - [-1, 3, C2f, [512]] # 13 - [-1, 1, nn.Upsample, [None, 2, "nearest"]] - [[-1, 4], 1, Concat, [1]] # cat backbone P3 - [-1, 3, C2f, [256]] # 16 (P3/8-small) - [-1, 1, Conv, [256, 3, 2]] - [[-1, 13], 1, Concat, [1]] # cat head P4 - [-1, 3, C2f, [512]] # 19 (P4/16-medium) - [-1, 1, SCDown, [512, 3, 2]] - [[-1, 10], 1, Concat, [1]] # cat head P5 - [-1, 3, C2fCIB, [1024, True, True]] # 22 (P5/32-large) - [16, 1, MSFN, [256]] - [19, 1, MSFN, [512]] - [22, 1, MSFN, [1024]] - [[23, 24, 25], 1, v10Detect, [nc]] # Detect(P3, P4, P5)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44