
- 1初识人脸识别---人脸识别研究报告(概述篇)_机器视觉的人脸识别报告
- 2专科程序员VS本科程序员,如何摆脱学历「魔咒」?_大专选择程序员摆脱了蓝领
- 3基于Java的连连看游戏设计与实现_java数字连连看程序设计项目背景
- 4交换二叉树的左右子树——非递归方式_非递归实现二叉树左右子树交换
- 5Hbase伪分布式搭建时HQuorumeer启动不成功_hquorumpeer进程没起来是什么原因
- 6git命令删除缓存区(git add)的内容_git删除缓冲区文件
- 7使用MacOS M1(ARM)芯片系统搭建CentOS虚拟机,并基于kubeadm部署搭建k8s集群_m1 vmware centos
- 8[python] 使用scikit-learn工具计算文本TF-IDF值(转载学习)_tf-idf算法调用
- 9android radiobutton 设置选中问题_android recyclerview把第一个item的radiobutton设置成选中状态
- 10Java技能点--switch支持的数据类型解释_java 类常量和接口常量 switch
MapReduce详解(MR运行全流程,shuffle,分区,分片)_mr任务怎么在运行的map和reduce个数
赞
踩
本文行文逻辑
分别从MR过程的前,中,后三个阶段对MR进行详细介绍
- 1
MapReduce程序详解(即map中,reduce中)
一种分布式运算程序,分为map阶段和reduce阶段
Map阶段会有一个实体程序,不需要我们自己开发,用户只需要维护map方法就可以
默认情况下map程序读取一行数据(映射成key-value对是一行行的)就会调用一次map方法,而且会将这一行数据的偏移量作为key(即key一定是IntWritable),这一行数据的内容作为value返回给框架,然后由框架写出context.write(key,value)
Reduce 阶段会有一个实体程序,不要我们自己开发我们需要维护reduce方法
Reduce程序会接受map端输出的中间结果数据,而且相同的key的数据会到达同一个reduce实例中去,每个reduce实例会处理多个key的数据。Reduce程序会将自己收集的数据按照key相同进行分组,对一组数据调用一次reduce方法(按组调用reduce方法),并且将参数传给reduce(key,迭代器values,context),然后写出
map前,reduce后详解
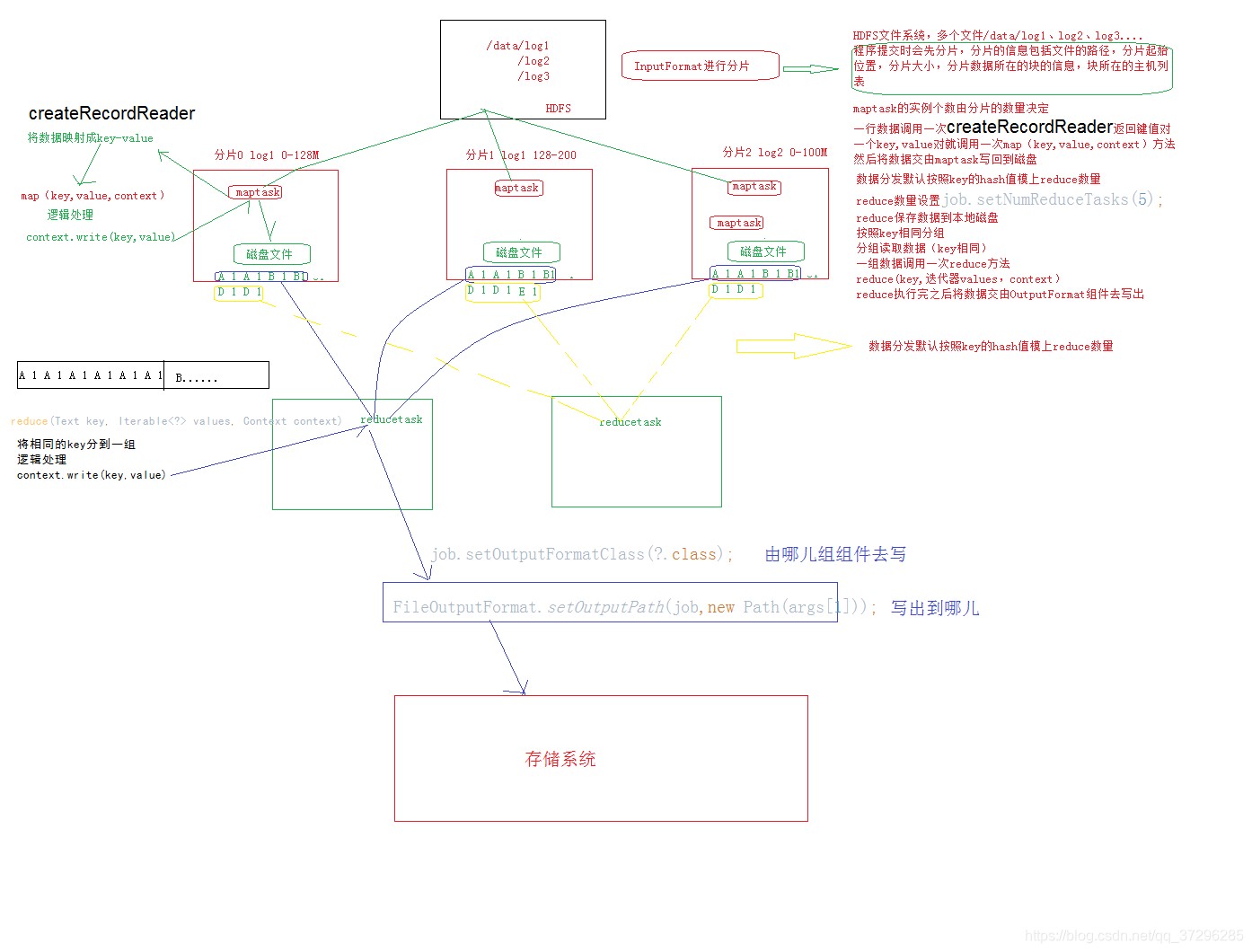
分片详解
什么是分片?
在进行map计算之前,map会根据输入文件计算输入分片(input split);每个输入分片(input split)针对一个map任务,输入分片存储的并非是数据本身,而是一个分片长度和一个记录数据的位置的数组。
逻辑概念,分片信息包括起始偏移量,分片大小,分片数据所在的块的信息,块所在的主机列表。
注意:分片是根据输入文件计算的,这些输入文件即是存储在hdfs上的那些个文件。
为何要分片?
答:方便多个Map任务并行处理,提高运作效率。
每一个分片对应着一个maptask,通过调整分片的大小可以调整maptask的数量,也就是调整map阶段的并行度。
分片大小计算?
下面是源程序中对分片大小的计算:
long minSize = Math.max(getFormatMinSplitSize(), getMinSplitSize(job));//返回1
long maxSize = getMaxSplitSize(job);//返回long的最大值
long splitSize = computeSplitSize(blockSize, minSize, maxSize)
return Math.max(minSize, Math.min(maxSize, blockSize));
总计:先比较块大小和最大分片,选出其中较小的,然后将结果和最小分片比较,选出较大的。
//计算分片大小,实际的分片大小。
while (((double) bytesRemaining)/splitSize > SPLIT_SLOP) {} //分片有一个1.1倍的冗余
通过这个可以对实际分片大小进行设置,主要从最大分片大小和最小分片大小入手。
(1)FileInputFormat.setMinInputSplitSize(job,1000);
(2)FileInputFormat.setMaxInputSplitSize(job,1000000);
分片的读取规则
- 第一个分片从第一行开始读取,读到分片末尾,再读取下一个分片的第一行
- 既不是第一个分片也不是最后一个分片,第一行数据舍去,读到分片末尾,再继续读 取下一个分片的第一行数据
- 最后一个分片舍去第一行,读到分片末尾
控制maptask和reducetask数量
控制maptask数量:
1)maptask数量由分片数量决定,可设置maxsize,minsize,blocksize来控制分片的大小,进而控制分片数量
2)改变数据总量也可影响maptask数量
控制reducetask数量:
1)job.setNumReduceTasks(5); 直接设置reducetask数量
2)分区数和reducetask数量是一致的,可以调整分区数。
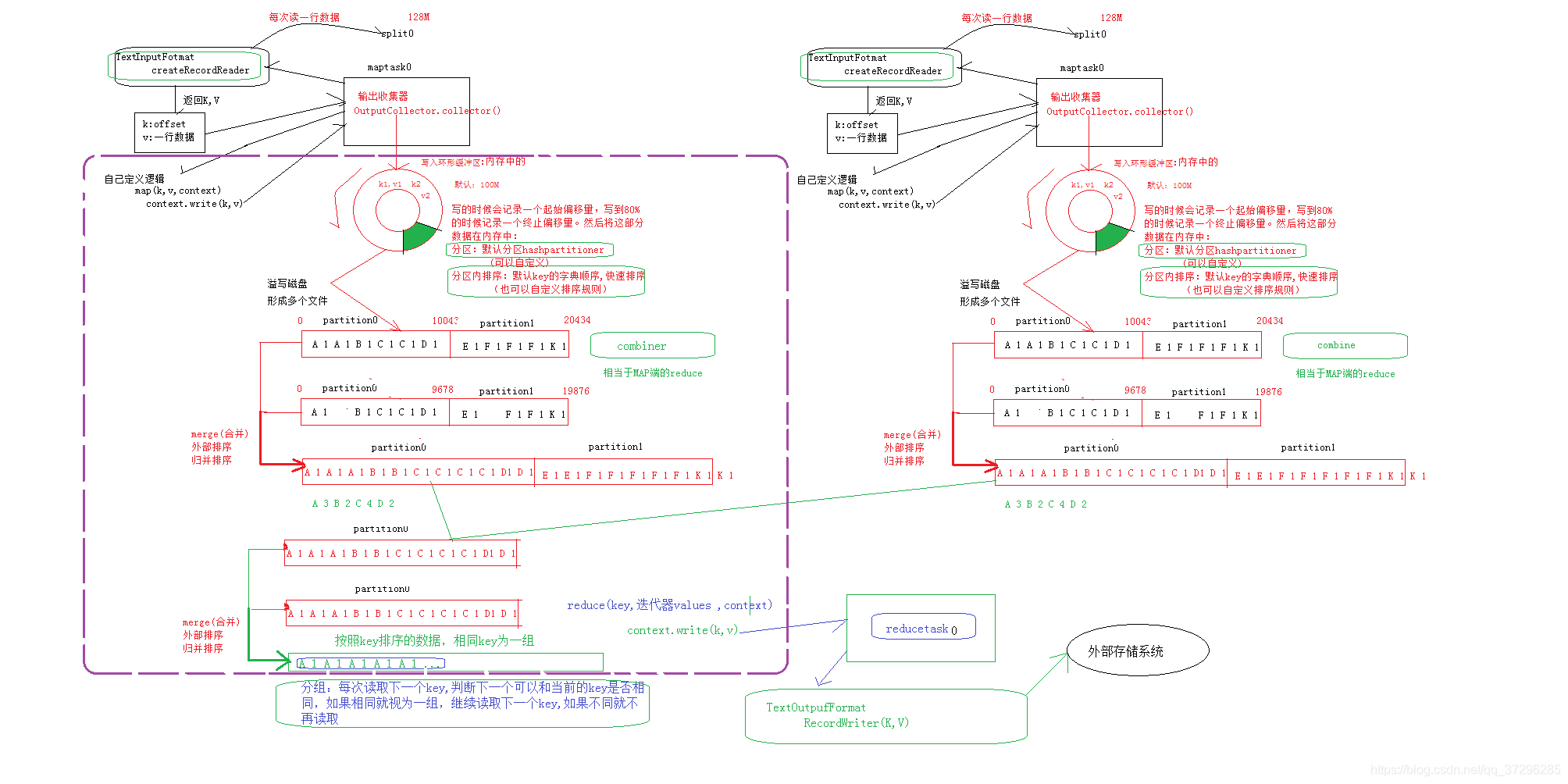
MapReduce运行全流程(主要介绍map到reduce的其中过程,即shuffle流程)
-
org.apache.hadoop.mapred.OutputCollector(即文中的输出收集器),OutputCollector由Hadoop框架提供,负责收集Mapper和Reducer的输出数据,实现map函数和reduce函数时,只需要简单的将其输出的<key,value>对往OutputCollector中一丢即可,剩余的事情框架自会帮你处理好。
可以理解为map()和reduce()不会每执行一次便写出,是需要积累的,具体流程可以查看底层原理进行了解。 -
为什么要写入环形缓冲区?
答: hadoop在执行MapReduce任务的时候,在map阶段,map()函数产生输出以后,并不是直接写入到磁盘中,而是先写入到了环形缓冲区,这样做的原因是无论缓冲区写入还是读出,速度都更快,效率更高 -
写入磁盘缓冲区的时候,为什么只写入百分之80,那百分之20干啥的?
答:这个内存缓冲区是有大小限制的,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。这个从内存往磁盘写数据的过程被称为Spill,中文可译为溢写,字面意思很直观。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。溢写线程启动时不应该阻止map的结果输出,所以整个缓冲区有个溢写的比例spill.percent。这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。 -
分片数据和溢写磁盘文件的对应关系?
通过上一条问题可知,环形缓冲区会重复利用。
一个分片数据有可能会产生多个溢写磁盘文件。 -
内/外部排序针对的是内存,在内存中的排序称之为内部排序,反之,在磁盘等位置的排序称为外部排序。
MR运行全流程中自定义部分
在MR运行全流程中,存在若干过程是设计人员可以进行自定义设计,即人为干预的。
包括:
- TextInputFormat
- map()函数
- 自定义分区(注意:先分区后排序,且是在溢写之前进行分区)
- 分区内自定义排序(注意:要在分区内进行排序)
- combine()
- 传入reduce()函数的key,我们可以自定义key类型,并定义什么样的key算是一样的
- reduce( )
- TextOutputFormat
自定义数据类型
1.要实现writable接口
2.读写顺序要一致
3.构造方法如果进行了重写,要显示定义无参的构造方法
4.重写toString方法
自定义分区
数据分发的策略
如何实现自定义分区?
前提要保证相同key的数据会发送到同一个reduce中,或者说是分到同一个分区中
Partitioner<key,value> ,这里的key和value的数据类型和map输出的数据类型保持一致
继承Patitioner这个类,重写分区方法getPartition(map输出key,map输出value,分区数量)
然后在job中设置使用我们自定义的分区方法进行数据分发
/** 场景:将不同手机号前缀归向不同省份地区 */ public class ProvincePartitioner extends Partitioner<Text,FlowBean>{ private static HashMap<String,Integer>pmap = new HashMap<>(); static{ pmap.put("136",0); pmap.put("137",1); pmap.put("138",2); pmap.put("139",3); } @Override public int getPartition(Text key,FlowBean flowBean,int numPartitions){ String prefix = key.toStrirg().substring(0,3); #截取手机号前三位 Integer partNum = pmap.get(prefix); return(partNum==null?4:partNUm); } } job.setPartitioner(ProvincePartitioner.class);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
Combine
combine出现的原因,作用?
减少数据量,提高传输效率。将形如A 1 A 1 A1 转换成A 3,类似于map端的reduce。
注意:combine需要注意场合,不是什么MR都适用。
分区详解
分区的数量和reduce(或者叫reducetask)数量是一致的。

