
- 12024年软件测试最新提高国内访问 GitHub 的速度的 9 种方案_github001,2024年最新软件测试开发面试题及答案_github加速 2024
- 2SpringBootWeb 篇-深入了解 Redis 五种类型命令与如何在 Java 中操作 Redis
- 3解决 Tomcat 跨域问题 - Tomcat 配置静态文件和 Java Web 服务(Spring MVC Springboot)同时允许跨域_tomcat配置跨域
- 4MySQL运维(二)MySQL分库分表概念及实战、读取分离详解_linux mysql 分库
- 5大量机器学习(Machine Learning)&深度学习(Deep Learning)资料_机器学习谁的课讲到最后
- 6记一次在ubuntu安装Mysql8修改lower_case_table_names =1的经历及最终解决方案_ubuntu已安装的mysql怎么重新初始化--lower-case-table-names=1
- 7【单片机笔记】基于XL4015的可调电源_xl4015可调降压电路图
- 8Windows安装PHP及在VScode中配置插件,使用PHP输出HelloWorld_windowsvscode php环境
- 9zookeeper知识点(一)_如何进入zk查看节点
- 10优化 CSS 代码的小技巧_html import的代替方案
流计算迎来代际变革:流式湖仓 Flink + Paimon 加速落地、Flink CDC 重磅升级_flinkcdc 读mysql写入paimon
赞
踩
2023 年 12 月 9 日,Flink Forward Asia 2023 (以下简称 FFA )在北京圆满结束。70+ 演讲议题、30+ 一线大厂技术与实践分享,以及座无虚席的现场,无一不昭示着重回线下的 FFA 的行业号召力。
借用 Apache Flink 中文社区发起人、Apache Paimon PPMC Member、阿里云智能开源大数据平台负责人王峰的话来说:“经过近十年的发展,Flink 已然成为了流式计算的事实标准。”
当然,对于社区开发者而言,这次大会上带来的流计算的新趋势、新实践与新进展或许才是关注的重点。
一、Flink 两大版本更新,深入场景、精益求精
过去十年,随着大数据、物联网和实时分析等需求的日益增长,传统的批量处理和静态分析方法无法满足新型数据处理场景下的高效、实时的要求,流计算的概念由此出现。流计算具有实时性强、处理实时数据流等能力,使得系统能够更加及时地响应和分析从大规模设备、传感器以及其他数据源产生的数据。Apache Flink 开始崭露头角,并且凭借其出色的性能和灵活性在全球范围内赢得了众多企业和开发者的青睐。
发布会上,王峰表示:“Flink 作为开源大数据领域的一棵常青树,一直保持着快速的发展,根本原因是我们在核心技术领域的不断演进。2023 年我们同样取得了一些新的进展,依然保持一年两个大版本的发布,包括 Flink1.17 和 1.18,也产生了很多新的贡献者。”
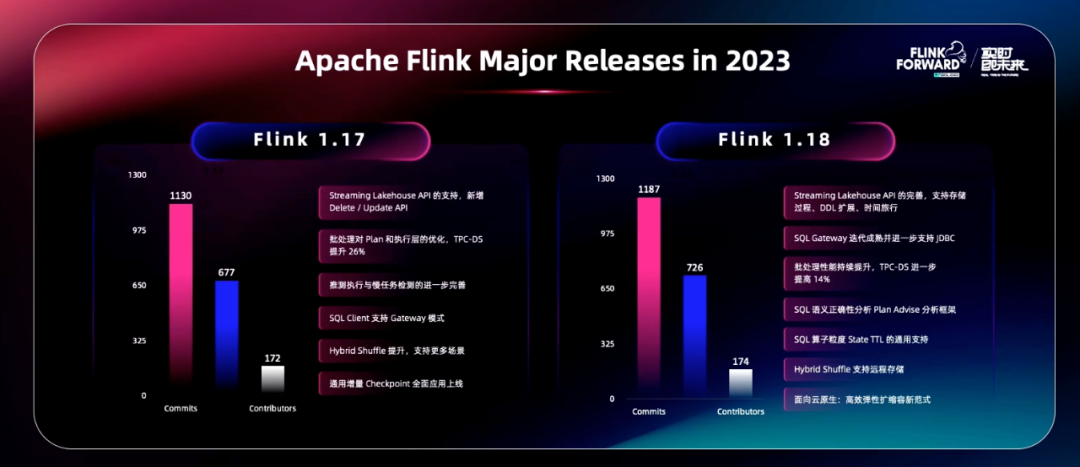
“在核心的流处理领域内,整体总结就是精益求精。”王峰提到。事实上,从技术层面来看,当前 Flink 已经成为了全球流计算领域的标杆,所以 2023 年 Flink 把版本更新的重点放到了深入场景、持续打磨上。比如持续完善 Flink 在批处理模式下的性能问题、功能完善性问题等,让 Flink 成为一款对有限数据集和无限数据集都能统一处理的计算引擎。
具体来说,在用户最关注且使用最多的开发语言—— Flink SQL 方面,Flink 团队进行了数百项调整或优化。比如,今年社区推出了一项新的功能特性—— Plan Advice,它可以帮助用户智能检查流式 SQL。Plan Advice 会在用户编写完流式 SQL 后,自动检查 SQL 可能存在的问题或风险,并第一时间给出提示和可行的建议。目前这项功能受到了用户的热烈欢迎。
在 Streaming Runtime 也就是真正的 Streaming 核心架构上,今年同样做出了较大的升级。“Flink 最大的特点是面向状态计算,自带状态存储和状态访问能力,因此状态管理、State 管理、Checkpoint、快照管理等都是 Flink 非常核心的部分,也是用户有很强诉求的部分。虽然 Flink 定期会做全局一致性快照,但用户希望快照频率越快越好,且代价越小越好,可行的思路是让系统在出现容错的时候,尽量少的数据回放,比如做到秒级的 Checkpoint。”王峰表示。经过一年的努力,通用的增量 Checkpoint 能力在 Flink1.17 和 1.18 成功落地,并且达到了一个完全生产可用的状态。
此外,在 Batch(批处理)引擎层面,Flink 也做了很多性能优化。王峰介绍称:“Flink 作为一款流批一体的引擎,除了强大的流计算能力,我们希望它在批处理方面同样优秀,给用户带来一站式的数据计算、数据开发体验。”
今年,Flink 不仅基于核心的流引擎优势来优化批处理场景下的执行效率,同时也将传统批处理上的优化手段引入到了 Flink 中去。经测试,Flink 1.18 版本的 Batch 执行模式在 TPC-DS 10T 数据集上的性能比 Flink 1.16 提高了 54%,基本达到了业界领先水平。
“这些优化会持续下去,保障 Flink 不仅在流计算领域达到业界的最强水平,在批处理领域依然可以达到一流的引擎执行能力。实际上今年我们已经看到非常多的公司在分享基于 Flink 的流批一体实践了。”王峰介绍道。
在部署架构方面,Flink 社区开发者也做了大量工作,以推动 Flink 在云上更好地运行。毋庸置疑的是,云原生不仅是大数据的新趋势,也为包括 AI 的普惠提供了基础。为了满足越来越多的项目和软件能够更好地在云上运行并提升用户体验,社区开发者做了大量工作。比如支持用户通过 API 在线、实时地进行扩缩容且不必重启整个 Flink 实例。同时为了实现云上全程无人值守的弹性扩缩容, Flink 社区还推出了基于 Kubernetes 的 Autoscaling 技术,通过 Autoscaling 去动态地、实时地监控整个任务的负载和延迟性,来保障用户的弹性扩缩容体验。
在场景方面,王峰表示,为了让更多的数据流动起来,Flink 社区也做了非常多的尝试,比如让 Flink 跟 Lakehouse 的架构协同,希望利用 Flink 强大的实时计算能力,加速 Lakehouse 的数据流动与分析。值得一提的是,今年 Flink 的两个版本加入了许多新的 API 来实现对 Lakehouse 的支持;同时也增加了对 JDBC driver 的支持,用户利用传统的 BI 工具就能实现与 Flink 的无缝对接。
“其实 Flink 的演进一直遵循着一个规律,即大数据行业的发展趋势。当前,大数据的场景正在从离线向实时加速升级转换。在这个大的浪潮下,Flink 的每一项工作都在不停地被验证。”王峰总结道。
发布会现场,曹操出行基础研发部负责人史何富分享了他们基于 Flink 的实时数仓实践。根据介绍,目前曹操出行公司运营中有三类主要的实时数据需求。首先,管理层需要实时的数据来随时了解公司的运营状况;其次,运营团队也需要一个聚焦的工具来可视化掌握运营细节;最后,算法对实时数据的要求越来越高,越实时的数据对于算法的效果越好。
“在过去的一年多里,通过基于 Flink 的流式数仓 ,曹操出行能够生成多样化的指标和实时特征,并输送给算法引擎,最终使得乘客补贴效率提高了 60%,司机效率提高了 20%。更令人振奋的是我们的毛利增长了 10 倍。” 曹操出行基础研发部负责人史何富表示。

对于 Flink 的后续规划,阿里云智能 Flink 分布式执行负责人、Apache Flink PMC 成员、Flink 2.0 Release Manager 宋辛童表示:“我们刚刚在 10 月份推出的 1.18 版本,在明年的 2 月份和 6 月份,我们会分别推出 1.19 跟 1.20 版本,以满足 API 迁移周期的需求。另外,我们将在明年的 10 月份推出全新的 Flink2.0 版本,将围绕流处理的极致优化与技术演进、流批一体架构演进、用户体验提升三个核心方向,大力推动存算分离状态管理、Batch 动态执行优化、流批统一 SQL 语法、流批融合计算模式、API 与配置系统升级等工作,期待更多的社区小伙伴们能够加入共建!”
二、Apache Paimon:引领流式湖仓新变革
除了持续加速 Flink 的演进外,Flink 社区过去一年还孵化出了一个全新的项目,并且成功捐赠给了 Apache 社区,它便是 Apache Paimon。
Apache Paimon 前身为 Flink Table Store,是一项流式数据湖存储技术,可以为用户提供高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。
事实上,随着 Lakehouse 成为了数据分析领域新的架构趋势,越来越多的用户将传统的基于 Hive、Hadoop 的数仓体系,转移到 Lakehouse 架构上。Lakehouse 架构主要有五大优势:计算存储分离、存储冷热分层、操作更灵活、查询可更换以及分钟级时效性。
“时效性是业务迁移的核心动力,而 Flink 是把时效性降低下来的核心计算引擎,有没有可能把 Flink 融入到 Lakehouse 中去,解锁一个全新的 Streaming House 的架构呢?这就是 Paimon 的设计初衷。”阿里云智能开源表存储负责人、Founder of Paimon、Flink PMC 成员李劲松表示。
当然,为了实现这一构想,Flink 团队同样经历了不小的挑战。其中最大的挑战源于“湖格式”,流技术以及流当中产生的大量更新,对湖存储格式带来了非常巨大的挑战。
“首先 Iceberg 是一个架构简单、生态开放的优秀湖存储格式,早在 2020 年,我们就在试图把 Flink 融入 Iceberg 当中,让 Iceberg 具备了流读、流写的能力。但是逐渐我们发现, Iceberg 整体还是面向离线设计的,它必须保持简洁的架构设计来面向各类计算引擎,而这给我们对它做内核改进带来了极大的阻碍。”李劲松解释道。
在 Flink+ Iceberg 的探索碰壁之后,Flink 团队开始思考 Flink+Hudi 的集成。Flink 接入之后,把 Hudi 的时延从 Spark 更新的小时级降低到了十分钟级。但是再往下,又遇到了新的阻碍,因为 Hudi 本身是面向 Spark,面向批计算设计的,它的架构不符合流计算以及更新的需求。
“在总结了 Flink+Iceberg 与 Flink+Hudi 这两套架构的经验之后,我们重新设计了一套全新的流式数据湖架构,也就是 Flink+Paimon。”李劲松表示。
Flink+Paimon 具有湖存储 +LSM 原生的设计,专为流更新而构建。Paimon 与 Flink、 Spark 都有良好的兼容性,并支持强大的流读流写功能,从而能够真正将延迟降低至 1-5 分钟。

“Apache Paimon 是一个流批一体的湖存储格式,它只是一个格式,把数据存储在的 OSS 或者 HDFS 上。然后基于这样的湖格式,通过我们推出的 Flink CDC 就能实现一键入湖,也能通过 Flink、Spark 来流写、批写到 Paimon 中去,后面 Paimon 也将支持各种主流开源引擎的读以及 Flink、Spark 的流读。”李劲松补充道。
“随着 Paimon 的版本迭代,你可以看到非常巨大的进步,目前 Paimon 社区已经有了 120 个来自各行各业的 Contributors,Star 数也达到了 1500+,越来越多的企业开始应用 Paimon 并且分享 Paimon 相关的实践。”
发布会上,同程旅行分享了他们基于 Paimon 的数据湖实践。据介绍,目前同程旅行已将 80% 的 Hudi 湖仓切换至 Paimon,涵盖了 500 多个任务和十多个基于 Paimon 的实时链路场景,处理大约 100TB 的数据量,整体数据条数达到约 1000 亿。
同程旅行大数据专家、Apache Hudi & Paimon Contributor 吴祥平表示,同程旅行基于 Paimon 做了架构升级之后,ODS 层同步效率提高了约 30%,写入速度提升约 3 倍,部分查询速度甚至提升了 7 倍;利用 Tag 的能力,在导出场景节省了约 40% 的存储空间;通过中间数据的可复用性,指标开发人员的工作效率提高了 约 50%。
此外,在汽车服务领域,汽车之家同样成功将 Paimon 应用于运营分析和报表等场景,不仅带来了极大的便利,同时也帮助业务取得了显著的收益。
汽车之家大数据计算平台负责人邸星星表示,通过与 Flink CDC 深度合作,汽车之家实现了流式读取,将数据写入 Paimon,并使用 Flink 再次消费 Paimon 的增量数据,从而将整个 Pipeline 打造成一个实时智能化的系统。
同样,得益于对 Flink+Paimon 的结合使用,在保证数据一致性的基础上,实现了架构简化,主机资源相较于之前减少了约 50%,同时在数据订正、实时批量分析以及中间结果实时查询等方面都获得了很好的支持。
从以上案例中,不难看出 Paimon 在实现流批一体方面发挥了重要作用。它成功地将流计算和批计算这两种不同的计算模式融合到了一起,与 Flink 的流批一体计算和存储能力相结合,打造出一个真正融合流和批的架构。Paimon 最常见的应用场景是数据实时入湖,而在这个过程中,Flink CDC 与 Paimon 的结合能够实现极简的入湖链路,使入湖操作达到全量与增量一体化的状态。这种组合为构建实时数据仓库、实时分析系统等提供了强有力的支持。
三、Flink CDC 3.0 实时数据集成框架发布,并宣布捐赠 Apache 基金会
Flink CDC 是一款基于 Flink 打造的一系列数据库的连接器,主要用于帮助 Flink 去读取隐藏在业务数据库里的增量变更日志。目前 Flink CDC 支持十多种主流的数据源,同时又能跟 Flink SQL 无缝链接,让用户通过 SQL 就能构建丰富的应用形态。
据悉,通过捕获数据变更,Flink CDC 能够实时地将数据变更传输到目标系统,从而实现近实时的数据处理。这种处理方式大大缩短了数据处理的时延,能够将数据处理的时效性从天级别降低到分钟级别,从而显著提升业务价值。
在发布会上,阿里云智能 Flink SQL、Flink CDC 负责人伍翀表示,Flink CDC 在 2023 年发展非常迅速。在生态方面,新增了对 IBM DB2 和 Vitess 这两个新 Connector 的支持,并且将增量快照读取的能力扩充到了更多的数据源;在引擎能力方面,提供了非常多的高级特性,比如动态加表、自动缩容、异步分片、指定位点等,还支持了 At-Least-Once 读取模式,并且还具备了横跨 Flink 1.14 到 1.18 五大版本的兼容能力。
Flink CDC 从诞生至今,已经有三年多的时间。一开始它的定位是做一系列数据库、数据源的连接器,但是随着 Flink CDC 在业界的广泛应用,Flink 团队逐渐发现最初的产品定位无法去 cover 更多的业务场景。
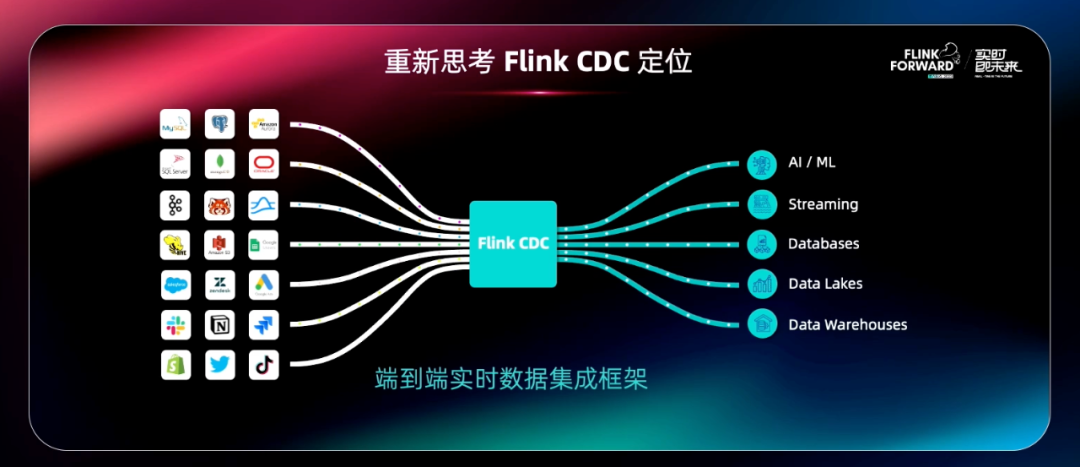
“如果它只是一个数据库的连接器,用户如果要搭建一个数据集成的解决方案,还是需要去做很多的拼装工作,或者遇到一些条件限制。所以我们希望 Flink CDC 它不仅仅是去做数据库的连接器,还能够去连接更多的数据源,包括消息队列数据库、数据湖、文件格式、SaaS 服务等等。更进一步,我们希望把它打造成一个能够打通数据源、数据管道、结果目标的端到端的实时数据集成解决方案和工具。而这也就是我们今天要正式发布的 Flink CDC 3.0 实时数据集成框架。”伍翀表示。

据悉,Flink CDC 3.0 实时数据集成框架是基于 Apache Flink 的内核之上去构建的。在引擎层,Flink CDC 3.0 开放了很多高级特性,包括实时同步、整库同步、分库分表合并等等;在连接层,Flink CDC 3.0 已经支持了 MySQL、StarRocks、Doris 的同步链路,Paimon、kafaka、MongoDB 等同步链路也已经在计划中;在接入层 Flink CDC 3.0 提供了一套 YAML + CLI 的 API 方式,以此来简化用户开发实时数据集成的成本。
“Flink CDC 3.0 实时数据集成框架的发布,是 Flink CDC 在技术上的一次里程碑突破,而在这背后,离不开社区的力量、开源的力量,所以我们希望能够利用技术去回馈开源。”伍翀表示。
随后,在发布会现场,阿里巴巴正式宣布将捐赠 Flink CDC 到 Apache Flink 和 Apache 软件基金会。
四、从引进来到走出去,全球化视野下的开源生态
不止于技术层面的持续创新与硕果累累,近年来 Apache Flink 在国际化生态社区构建方面同样令人瞩目。
在中国,Flink 中文社区成为了最活跃的技术社区之一。在 Flink 中文社区五周年之际,社区开发者们共同见证了 750 篇技术文章的累计发布,吸引了 111 个公司和 351 位开发者的积极参与,这些文章累计获得了高达 235 万的阅读量,凸显了 Flink 全球化社区技术布道的中国力量。
放眼世界,目前 Flink 已经成为 Apache 基金会最活跃的顶级项目之一,Flink 的社区成员覆盖到欧洲、北美、东南亚各地,涵盖了学术界、工业界、开源社区等各个领域。作为其中的主导者,阿里巴巴国际化社区的管理也得到日益增强。根据统计,阿里巴巴培养了 70% 以上的 Flink 项目管理委员会(PMC)成员和提交者(Committor)。

值得一提的是,今年 6 月,Flink 凭借其在实时大数据领域的技术创新和全球影响力,被数据库国际顶级会议 SIGMOD 授予 SIGMOD System Award 2023 大奖。过往获得该奖项的均为全球数据库领域的明星项目,如 Apache Spark、Postgres 和 BerkeleyDB 等。
从国外引入到中国,再到华人贡献推动 Flink 开源技术全球化,华人开发者在这个过程中正在扮演着越来越重要的角色。他们不仅在开源项目的开发中发挥了重要作用,还积极参与到各种开源社区的活动中,共同推动技术的发展和创新。而这些华人开发者的贡献则对 Apache Flink 生态系统的成长和发展起到了关键作用。
Apache Flink 全球化视野的开源生态已经成为其持续繁荣的重要力量。在这个生态中,各种技术、文化和思想得到了充分的交流和融合,为其创新带来了巨大的推动力。我们也有理由相信,未来在这片具备全球视野的开源沃土之上,将会有越来越多的开发者加入,共同为实时计算的未来贡献自己的力量。
Flink Forward Asia 2023
本届 Flink Forward Asia 更多精彩内容,扫描图片二维码在线阅读全部议题 PPT ~



