
- 1【计算机视觉】人脸算法之图像处理基础知识(六)
- 2vue-cli3.0配置不同的网址(根据不同的环境进行网址切换)_vue3怎么切换接口地址用的是env还是env.dev
- 3Android Studio--NDK编译C代码为.so文件,JNI调用_android 代码全编译为so
- 43.4神经网络学习规则
- 52024新版Git教程 从入门到实战(四)Git远程仓库Gitee的使用_vs git远程(1)
- 6IDEA 打包 Spark 项目 POM 文件依赖_怎么打包spark程序
- 7【Docker】Docker安装入门教程及基本使用_熟悉docker的安装和使用,掌握使用docker容器化技术来包装和运行程序的原理和方法
- 8在visecode中使用最基本的拉取和推送gitee_vscode拉取gitee代码
- 9分布式版本控制系统——Git学习(1)初识Git与Git的安装卸载_git卸载了
- 10datastage--自己定义函数_datastage 8.5 transformer 自定义match函数
Linux信号机制及其原理分析_linux sigpromask
赞
踩
前言
在最近在工作中,使用到了信号的相关知识,之前我们在分析Android系统init进程的时候也提到了信号,但并没有对信号这个机制做出深入的理解,借此机会,我们深入分析一下Linux信号机制是怎样实现的
简介
信号(signal),是Unix系统中的一种古老的进程间通信机制,而Linux作为类Unix系统,早期也是模仿了Unix系统,自然也保留下了这个机制。信号是一种异步通信机制,它是在软件层面上对中断机制的一种模拟
注:本篇文章基于glibc版本2.35,Linux内核版本5.17,x86_64架构
信号的产生
信号可以由内核产生,也可以由用户产生,这边举几个例子:
-
用户在终端输入
ctrl + c时,会产生一个SIGINT信号 -
在程序中对一个数除0,会产生一个异常,最终由内核产生一个
SIGFPE信号 -
在程序中非法访问一段内存,会由内核产生一个
SIGBUS信号 -
在终端或程序中手动发送一个信号
-
终端:比如说
kill -9 [pid] -
程序:调用
kill函数,raise函数等
-
信号种类
在Linux中,信号被分为不可靠信号和可靠信号,一共64种,可以通过kill -l命令来查看
-
不可靠信号:也称为非实时信号,不支持排队,信号可能会丢失,比如发送多次相同的信号,进程只能收到一次,信号值取值区间为1~31
-
可靠信号:也称为实时信号,支持排队,信号不会丢失,发多少次,就可以收到多少次,信号值取值区间为32~64
在早期的Linux中,只定义了前面的不可靠信号,随着时间的发展,发现有必要对信号机制加以改进和扩充,又由于原先定义的信号已有应用,出于兼容性考虑,不能再做改动,于是又新增了一部分信号,这些信号被定义为可靠信号。
在arch/x86/include/uapi/asm/signal.h中,我们可以发现这些信号的定义,在文末的附录中,我们也详细介绍了每个信号的含义和默认动作
如何使用
我一向认为,如果想要理解一个技术原理,首先我们必须要会使用这个技术
发送信号
之前提过,用户是可以手动向一个进程发送信号的,我们可以使用以下一些函数:
kill
原型:
#include <signal.h>
int kill(pid_t pid, int sig);
- 1
- 2
- 3
文档:https://man7.org/linux/man-pages/man2/kill.2.html
这个函数的作用是向指定进程(或进程组)发送一个信号,成功返回0,失败返回-1
其中的pid参数:
-
当
pid > 0时,发送信号给pid对应的进程 -
当
pid = 0时,发送信号给本进程组中的所有进程 -
当
pid = -1时,发送信号给所有调用进程有权给其发送信号的进程,除了init进程 -
当
pid < -1时,发送信号给进程组id为-pid的所有进程
当sig参数为0时,不会发送任何信号,但仍然会进行参数检测,我们可以用这种方法检查pid对应进程是否存在或允许发送信号
raise
原型:
#include <signal.h>
int raise(int sig);
- 1
- 2
- 3
文档:https://man7.org/linux/man-pages/man3/raise.3.html
这个函数的作用是向本进程或线程发送信号,成功返回0,失败返回-1
这个函数对于主线程来说,相当于kill(getpid(), sig),对于子线程来说,相当于pthread_kill(pthread_self(), sig)
sigqueue
原型:
#include <signal.h>
int sigqueue(pid_t pid, int sig, const union sigval value);
- 1
- 2
- 3
文档:https://man7.org/linux/man-pages/man3/sigqueue.3.html
这个函数的作用是向一个进程发送信号,同时可以传递一些额外数据,成功返回0,失败返回-1
这个函数和kill不同的地方是,它只能向一个进程发送信号,不能发送给信号组,当sig为0时,行为和kill一致
abort
原型:
#include <stdlib.h>
noreturn void abort(void);
- 1
- 2
- 3
文档:https://man7.org/linux/man-pages/man3/abort.3.html
这个函数的作用是向本进程发送SIGABRT信号
需要注意的有两点:
-
abort函数会首先解除进程对SIGABRT信号的阻塞 -
无论
SIGABRT信号是否注册了自定义处理器,最后都会终止进程,因为abort函数会在SIGABRT信号处理完后恢复默认信号处理方式,然后重发这个信号
alarm
原型:
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
- 1
- 2
- 3
文档:https://man7.org/linux/man-pages/man2/alarm.2.html
这个函数的作用是在seconds秒后向本进程发送SIGALRM信号
参数seconds为时间,单位为秒
返回值,如果以前没有设置过alarm或超时,则返回0,如果以前没有设置过alarm,则返回剩余的时间
处理信号
我们是可以自定义一些信号的处理方式,需要注意的是,SIGKILL和SIGSTOP是两个特殊的信号,它们不允许被忽略、处理和阻塞
sigaction
原型:
#include <signal.h>
int sigaction(int signum, const struct sigaction *restrict act,
struct sigaction *restrict oldact);
- 1
- 2
- 3
- 4
文档:https://man7.org/linux/man-pages/man2/sigaction.2.html
这是较新的一个信号处理函数,它的作用是,对一个信号注册一个新的信号处理方式,并获取以前的信号处理方式,成功返回0,失败返回-1
第一个参数signum,用来指定信号的编号(需要设置哪个信号)
第二个参数act用来指定注册的新的信号处理方式
第三个参数oldact不为null时,可以用来获取该信号原来的处理方式
当参数act为null,oldact不为null时,这个函数可以用来只获取信号当前的处理方式
sigaction结构体
struct sigaction {
union {
__sighandler_t _sa_handler;
void (*_sa_sigaction)(int, struct siginfo *, void *);
} _u;
sigset_t sa_mask;
unsigned long sa_flags;
void (*sa_restorer)(void);
};
typedef void __signalfn_t(int);
typedef __signalfn_t __user *__sighandler_t;
#define sa_handler _u._sa_handler
#define sa_sigaction _u._sa_sigaction
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
可以看到,其中有一个联合,它是用来兼容旧版本函数的,当参数sa_mask中含有SA_SIGINFO的时候,回调的是_sa_sigaction函数,当没有这个参数时,回调的是_sa_handler这个旧版本函数
_sa_sigaction函数相对于_sa_handler函数而言,多携带了一些信号信息,譬如说发送信号的进程pid
_sa_handler可以被赋值成SIG_DFL或SIG_IGN,它们分别对应着默认处理和忽略信号,需要注意的时,它们只是一个int值,是不能被直接调用的
#define SIG_DFL ((__force __sighandler_t)0) /* default signal handling */
#define SIG_IGN ((__force __sighandler_t)1) /* ignore signal */
- 1
- 2
这个结构体中的sa_mask域为一个信号集,表示当正在执行信号处理函数的时候,阻塞一些信号,只有这个信号处理完了,这些信号才会被处理
这个结构体中的sa_flags域,有如下一些标志:
-
SA_NOCLDSTOP:当signum为SIGCHLD的时候才生效,当子进程暂停或恢复时,父进程不会收到SIGCHLD信号 -
SA_NOCLDWAIT:当signum为SIGCHLD的时候才生效,当子进程退出时,父进程不会收到SIGCHLD信号,子进程也不会成为僵尸进程 -
SA_NODEFER:一般情况下,当信号处理函数运行时,内核将阻塞对应的信号。但是如果设置了SA_NODEFER标记,那么在该信号处理函数运行时,内核将不会阻塞该信号 -
SA_ONSTACK:表示使用一个备用栈,当发生栈溢出时,内核会发出SIGILL信号,如果此时在原来的栈上调用信号处理函数,也会发生栈溢出,导致死循环,此时就需要准备一个备用栈,在备用栈上处理信号 -
SA_RESETHAND:表示设置的信号处理行为只生效一次,当触发我们设置的信号处理函数后,内核会将信号处理行为重置(SA_ONESHOT作用相同,但它是一个过时的,非标准的flag) -
SA_RESTART:当执行系统调用时,如果收到一个信号,系统默认将中断这个系统调用,转而执行信号处理函数,结束后让这个被中断的系统调用失败,设置了SA_RESTART标志后,当信号处理函数执行完后,会自动恢复执行这个被中断的系统调用 -
SA_SIGINFO:设置这个标志后,会回调_sa_sigaction作为信号处理函数,会携带更多的信号信息
signal
原型:
#include <signal.h>
sighandler_t signal(int signum, sighandler_t handler);
- 1
- 2
- 3
文档:https://man7.org/linux/man-pages/man2/signal.2.html
这个函数的作用是,设置下一次的信号处理函数(只生效一次),成功返回上一次设置的信号处理函数,失败返回SIG_ERR
这个函数在新版本中实际上是通过sigaction函数实现的,推荐使用更加强大的sigaction函数
阻塞信号
信号有几种状态,首先是信号的产生 (Genertion),而实际执行信号处理动作时,状态为递达 (Delivery),信号在产生到递达中的状态被称为未决 (Pending)
进程可以选择阻塞 (Blocking)某些信号,被阻塞的信号在产生后将保持在未决状态,直到进程解除对该信号的阻塞,才执行递达的动作
信号集函数
我们可以用信号集函数改变当前进程的信号屏蔽字(Signal Mask),控制信号的阻塞与否
信号集设置函数
#include <signal.h> //信号集数据类型 typedef unsigned long sigset_t; //清空一个信号集(将这个sigset_t置0) //文档:https://man7.org/linux/man-pages/man3/sigemptyset.3p.html void sigemptyset(sigset_t *set); //填充满一个信号集(将这个sigset_t的每一位都置1) //文档:https://man7.org/linux/man-pages/man3/sigfillset.3p.html void sigfillset(sigset_t *set); //将指定的信号添加到信号集中(将这个sigset_t的对应信号位置1) //文档:https://man7.org/linux/man-pages/man3/sigaddset.3p.html int sigaddset(sigset_t *set, int signo); //将指定的信号从信号集中移除(将这个sigset_t的对应信号位置0) //文档:https://man7.org/linux/man-pages/man3/sigdelset.3p.html int sigdelset(sigset_t *set, int signo); //判断一个信号是否在这个信号集中(判断这个sigset_t的对应信号位是否为1) //文档:https://man7.org/linux/man-pages/man3/sigismember.3p.html int sigismember(const sigset_t *set, int signo);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
sigpromask
原型:
#include <signal.h>
int sigpromask(int how, const sigset_t *set, sigset_t *oldset);
- 1
- 2
- 3
文档:https://man7.org/linux/man-pages/man2/sigprocmask.2.html
这个函数通过指定的方法和信号集修改进程的信号屏蔽字,成功返回0,失败返回-1
第一个参数how有3种取值:
SIG_BLOCK:将set中的信号添加到信号屏蔽字中(不改变原有已存在信号屏蔽字,相当于用set中的信号与原有信号取并集设置)SIG_UNBLOCK:将set中的信号移除信号屏蔽字(相当于用set中的信号的补集与原有信号取交集设置)SIG_SETMASK:使用set中的信号直接代替原有信号屏蔽字中的信号
第二个参数set是一个信号集,怎么使用和参数how相关
第三个参数oldset,如果不为null,会将原有信号屏蔽字的信号集保存进去
sigpending
原型:
#include <signal.h>
int sigpending(sigset_t *set);
- 1
- 2
- 3
这个函数的作用是获得当前进程的信号屏蔽字,将结果保存到传入的set中,成功返回0,失败返回-1
信号原理
我们已经了解了信号的产生和处理,现在我们可以具体的看看一个信号从产生到响应处理,它经历了什么,它的原理是什么
我们在简介中说过:信号是一种异步通信机制,它是在软件层面上对中断机制的一种模拟,该怎么理解这句话呢?
当我们对一个进程发送信号后,会将这个信号暂时存放到这个进程所对应的task_struct的pending队列中,此时,进程并不知道有新的信号过来了,这也就是异步的意思。那么进程什么时候才能得知并处理这个信号呢?有两个时机,一个是进程从内核态返回到用户态时,一个是进程从睡眠状态被唤醒。让信号看起来是一个异步中断的关键就是,正常的用户进程是会频繁的在用户态和内核态之间切换的,所以信号能很快的得到执行
下图为信号相关的一些结构
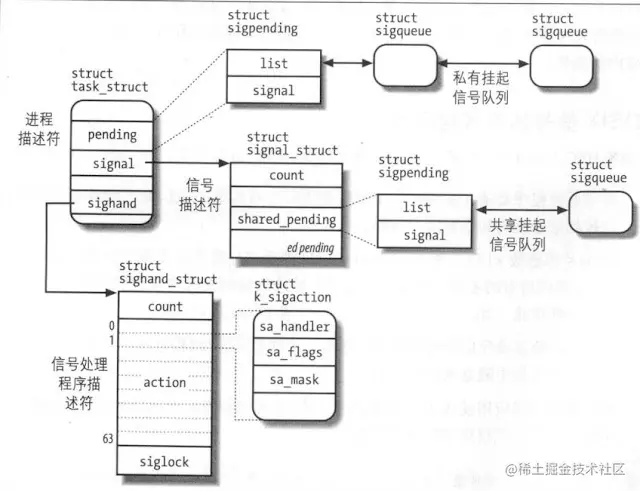
信号的发送
我们以kill函数为例,看看信号是如何发送的,它被定义在tools/include/nolibc/nolibc.h中
static __attribute__((unused)) int kill(pid_t pid, int signal) { int ret = sys_kill(pid, signal); if (ret < 0) { SET_ERRNO(-ret); ret = -1; } return ret; } static __attribute__((unused)) int sys_kill(pid_t pid, int signal) { return my_syscall2(__NR_kill, pid, signal); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
可以看到,这里使用了系统调用,在Linux内核中,每个syscall都对应着唯一的系统调用号,kill函数的系统调用号为__NR_kill,它被定义在tools/include/uapi/asm-generic/unistd.h中
/* kernel/signal.c */
#define __NR_kill 129
__SYSCALL(__NR_kill, sys_kill)
- 1
- 2
- 3
在x86_64架构的机器上,my_syscall2是这样被定义的
#define my_syscall2(num, arg1, arg2) \ ({ \ long _ret; \ register long _num asm("rax") = (num); \ register long _arg1 asm("rdi") = (long)(arg1); \ register long _arg2 asm("rsi") = (long)(arg2); \ \ asm volatile ( \ "syscall\n" \ : "=a"(_ret) \ : "r"(_arg1), "r"(_arg2), \ "0"(_num) \ : "rcx", "r11", "memory", "cc" \ ); \ _ret; \ })
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这里涉及到了扩展内联汇编,syscall指令需要一个系统调用号和一些参数,在x86_64架构中,系统调用号需要存放在rax寄存器中,参数依次存放在rdi, rsi, rdx, r10, r8, r9寄存器中,执行syscall指令后,内核会通过系统调用号去从系统调用表找到对应函数的入口
我们之前在找系统调用号__NR_kill的时候可以发现,上面标了注释,表明这个函数的实现在kernel/signal.c中,但我们在这个文件中并没有找到sys_kill这个函数,实际上这里隐藏了一个宏定义
在include/linux/syscalls.h中,我们可以找到这样一些宏定义
#ifndef SYSCALL_DEFINE0 #define SYSCALL_DEFINE0(sname) \ SYSCALL_METADATA(_##sname, 0); \ asmlinkage long sys_##sname(void); \ ALLOW_ERROR_INJECTION(sys_##sname, ERRNO); \ asmlinkage long sys_##sname(void) #endif /* SYSCALL_DEFINE0 */ #define SYSCALL_DEFINE1(name, ...) SYSCALL_DEFINEx(1, _##name, __VA_ARGS__) #define SYSCALL_DEFINE2(name, ...) SYSCALL_DEFINEx(2, _##name, __VA_ARGS__) #define SYSCALL_DEFINE3(name, ...) SYSCALL_DEFINEx(3, _##name, __VA_ARGS__) #define SYSCALL_DEFINE4(name, ...) SYSCALL_DEFINEx(4, _##name, __VA_ARGS__) #define SYSCALL_DEFINE5(name, ...) SYSCALL_DEFINEx(5, _##name, __VA_ARGS__) #define SYSCALL_DEFINE6(name, ...) SYSCALL_DEFINEx(6, _##name, __VA_ARGS__) #define SYSCALL_DEFINE_MAXARGS 6 #define SYSCALL_DEFINEx(x, sname, ...) \ SYSCALL_METADATA(sname, x, __VA_ARGS__) \ __SYSCALL_DEFINEx(x, sname, __VA_ARGS__) #define __PROTECT(...) asmlinkage_protect(__VA_ARGS__) /* * The asmlinkage stub is aliased to a function named __se_sys_*() which * sign-extends 32-bit ints to longs whenever needed. The actual work is * done within __do_sys_*(). */ #ifndef __SYSCALL_DEFINEx #define __SYSCALL_DEFINEx(x, name, ...) \ __diag_push(); \ __diag_ignore(GCC, 8, "-Wattribute-alias", \ "Type aliasing is used to sanitize syscall arguments");\ asmlinkage long sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) \ __attribute__((alias(__stringify(__se_sys##name)))); \ ALLOW_ERROR_INJECTION(sys##name, ERRNO); \ static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__));\ asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)); \ asmlinkage long __se_sys##name(__MAP(x,__SC_LONG,__VA_ARGS__)) \ { \ long ret = __do_sys##name(__MAP(x,__SC_CAST,__VA_ARGS__));\ __MAP(x,__SC_TEST,__VA_ARGS__); \ __PROTECT(x, ret,__MAP(x,__SC_ARGS,__VA_ARGS__)); \ return ret; \ } \ __diag_pop(); \ static inline long __do_sys##name(__MAP(x,__SC_DECL,__VA_ARGS__)) #endif /* __SYSCALL_DEFINEx */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
SYSCALL_DEFINEx中的x表示接受x个参数,这个宏定义根据传入的name参数,以sys_name为名定义了一个函数,也就是说SYSCALL_DEFINE2(kill, ...)这个宏展开后基本相当于sys_kill函数,在kernel/signal.c中我们可以找到这段代码
/**
* sys_kill - send a signal to a process
* @pid: the PID of the process
* @sig: signal to be sent
*/
SYSCALL_DEFINE2(kill, pid_t, pid, int, sig)
{
struct kernel_siginfo info;
prepare_kill_siginfo(sig, &info);
return kill_something_info(sig, &info, pid);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里就是kill函数的真正实现,我们这里主要关注信号的发送,就屏蔽一些细节,只看发送部分
static int kill_something_info(int sig, struct kernel_siginfo *info, pid_t pid) { int ret; //这里我们就只看对一个进程发送信号 if (pid > 0) return kill_proc_info(sig, info, pid); ... } static int kill_proc_info(int sig, struct kernel_siginfo *info, pid_t pid) { ... kill_pid_info(sig, info, find_vpid(pid)); ... } int kill_pid_info(int sig, struct kernel_siginfo *info, struct pid *pid) { struct task_struct *p; for (;;) { ... //获取pid对应进程的task_struct p = pid_task(pid, PIDTYPE_PID); if (p) //PIDTYPE_TGID表示类型是线程组id,对于同一进程中的所有线程,tgid都是一致的,为该进程的进程id group_send_sig_info(sig, info, p, PIDTYPE_TGID); ... } } int group_send_sig_info(int sig, struct kernel_siginfo *info, struct task_struct *p, enum pid_type type) { int ret; ... if (!ret && sig) ret = do_send_sig_info(sig, info, p, type); return ret; } int do_send_sig_info(int sig, struct kernel_siginfo *info, struct task_struct *p, enum pid_type type) { ... send_signal(sig, info, p, type); ... } static int send_signal(int sig, struct kernel_siginfo *info, struct task_struct *t, enum pid_type type) { /* Should SIGKILL or SIGSTOP be received by a pid namespace init? */ ... return __send_signal(sig, info, t, type, force); } static int __send_signal(int sig, struct kernel_siginfo *info, struct task_struct *t, enum pid_type type, bool force) { struct sigpending *pending; struct sigqueue *q; int override_rlimit; int ret = 0, result; result = TRACE_SIGNAL_IGNORED; //判断是否可以忽略信号 if (!prepare_signal(sig, t, force)) goto ret; //选择信号pending队列 //线程组共享队列(t->signal->shared_pending) 或 进程私有队列(t->pending) pending = (type != PIDTYPE_PID) ? &t->signal->shared_pending : &t->pending; result = TRACE_SIGNAL_ALREADY_PENDING; //如果该信号是不可靠信号,且已经在padding队列中,则忽略这个信号 if (legacy_queue(pending, sig)) goto ret; result = TRACE_SIGNAL_DELIVERED; //对SIGKILL信号和内核进程跳过信号的pending if ((sig == SIGKILL) || (t->flags & PF_KTHREAD)) goto out_set; //实时信号可以突破队列大小限制,否则丢弃信号 if (sig < SIGRTMIN) override_rlimit = (is_si_special(info) || info->si_code >= 0); else override_rlimit = 0; //新分配一个sigqueue,并将其加入pending队尾 q = __sigqueue_alloc(sig, t, GFP_ATOMIC, override_rlimit, 0); if (q) { list_add_tail(&q->list, &pending->list); switch ((unsigned long) info) { case (unsigned long) SEND_SIG_NOINFO: clear_siginfo(&q->info); q->info.si_signo = sig; q->info.si_errno = 0; q->info.si_code = SI_USER; q->info.si_pid = task_tgid_nr_ns(current, task_active_pid_ns(t)); rcu_read_lock(); q->info.si_uid = from_kuid_munged(task_cred_xxx(t, user_ns), current_uid()); rcu_read_unlock(); break; case (unsigned long) SEND_SIG_PRIV: clear_siginfo(&q->info); q->info.si_signo = sig; q->info.si_errno = 0; q->info.si_code = SI_KERNEL; q->info.si_pid = 0; q->info.si_uid = 0; break; default: copy_siginfo(&q->info, info); break; } } else if (!is_si_special(info) && sig >= SIGRTMIN && info->si_code != SI_USER) { ... } else { ... } out_set: signalfd_notify(t, sig); sigaddset(&pending->signal, sig); ... //唤醒进程 complete_signal(sig, t, type); ret: return ret; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
从代码里我们可以看出来,和我们之前说的原理是一样的,新分配了一个sigqueue,并将其加入到对应进程task_struct的pending队列队尾
设置信号处理
之前我们介绍了怎么自定义信号处理行为,如何设置信号屏蔽字,实际上都能在进程的task_struct中体现出来,信号处理行为保存在其中的sighand域中,而信号屏蔽字保存在其中的blocked域中
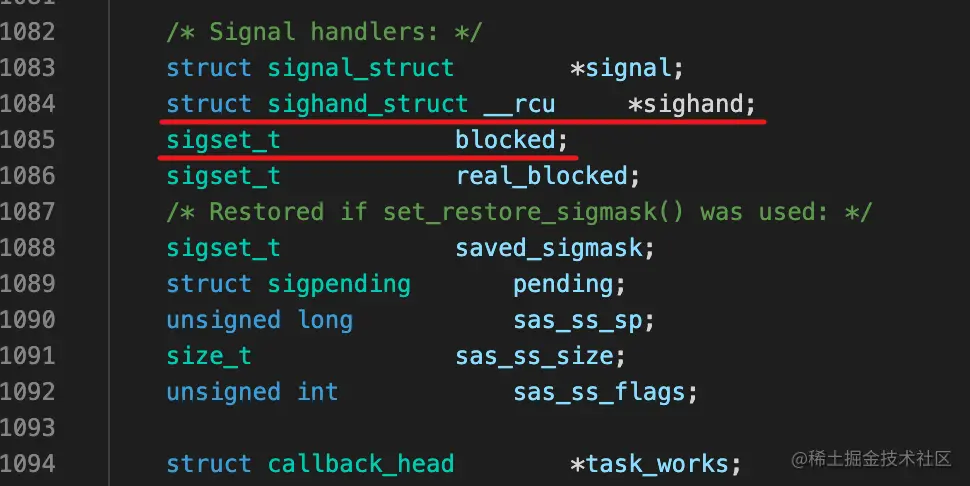
信号的响应
x86_64架构系统调用会经历do_syscall_64这么一个函数,它被实现在arch/x86/entry/common.c中
__visible noinstr void do_syscall_64(struct pt_regs *regs, int nr)
{
add_random_kstack_offset();
nr = syscall_enter_from_user_mode(regs, nr);
instrumentation_begin();
if (!do_syscall_x64(regs, nr) && !do_syscall_x32(regs, nr) && nr != -1) {
/* Invalid system call, but still a system call. */
regs->ax = __x64_sys_ni_syscall(regs);
}
instrumentation_end();
syscall_exit_to_user_mode(regs);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
从代码我们可以看出来,当进程从内核空间返回用户空间时,会调用syscall_exit_to_user_mode函数
最终经历一系列调用,会走到exit_to_user_mode_loop函数中,它们被定义在kernel/entry/common.c中
static unsigned long exit_to_user_mode_loop(struct pt_regs *regs,
unsigned long ti_work)
{
while (ti_work & EXIT_TO_USER_MODE_WORK) {
...
if (ti_work & (_TIF_SIGPENDING | _TIF_NOTIFY_SIGNAL))
handle_signal_work(regs, ti_work);
...
}
return ti_work;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以看到,如果当前线程包含_TIF_SIGPENDING或_TIF_NOTIFY_SIGNAL,表明该线程可能有信号需要处理,会调用到handle_signal_work函数处理,接着调用到arch_do_signal_or_restart函数中,它被实现在arch/x86/kernel/signal.c中
//has_signal的值为 (ti_work & _TIF_SIGPENDING) void arch_do_signal_or_restart(struct pt_regs *regs, bool has_signal) { struct ksignal ksig; if (has_signal && get_signal(&ksig)) { handle_signal(&ksig, regs); return; } //如果该进程没有对这个信号设置处理程序,这里会自动重启这个系统调用 /* Did we come from a system call? */ if (syscall_get_nr(current, regs) != -1) { /* Restart the system call - no handlers present */ switch (syscall_get_error(current, regs)) { case -ERESTARTNOHAND: case -ERESTARTSYS: case -ERESTARTNOINTR: regs->ax = regs->orig_ax; regs->ip -= 2; break; case -ERESTART_RESTARTBLOCK: regs->ax = get_nr_restart_syscall(regs); regs->ip -= 2; break; } } restore_saved_sigmask(); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
这个函数中的if语句体,看上去是如果有信号,则处理这个信号,其实不完全是这样的。如果该进程没有对这个信号设置处理程序,则会执行默认的信号处理,这里的处理过程是在get_signal中完成的,我当时在看这块源码的时候还在疑惑为什么找不到信号默认处理的地方,结果是这个函数的名字误导了我。如果该进程没有对这个信号设置处理程序,则会自动重启这个系统调用,这里就不展开说了,我们首先看一下get_signal函数是怎么实现的,它被实现在kernel/signal.c中
bool get_signal(struct ksignal *ksig) { struct sighand_struct *sighand = current->sighand; struct signal_struct *signal = current->signal; int signr; ... relock: spin_lock_irq(&sighand->siglock); //如果子进程的状态发生变化,发送SIGCHLD信号给父进程 if (unlikely(signal->flags & SIGNAL_CLD_MASK)) { int why; if (signal->flags & SIGNAL_CLD_CONTINUED) why = CLD_CONTINUED; else why = CLD_STOPPED; signal->flags &= ~SIGNAL_CLD_MASK; spin_unlock_irq(&sighand->siglock); read_lock(&tasklist_lock); do_notify_parent_cldstop(current, false, why); if (ptrace_reparented(current->group_leader)) do_notify_parent_cldstop(current->group_leader, true, why); read_unlock(&tasklist_lock); goto relock; } for (;;) { struct k_sigaction *ka; enum pid_type type; ... //从进程task_struct的pending队列中取出一个信号 type = PIDTYPE_PID; signr = dequeue_synchronous_signal(&ksig->info); if (!signr) signr = dequeue_signal(current, ¤t->blocked, &ksig->info, &type); if (!signr) break; /* will return 0 */ ... //从信号处理数组中,取出对应信号的处理动作 ka = &sighand->action[signr-1]; if (ka->sa.sa_handler == SIG_IGN) /* Do nothing. */ continue; if (ka->sa.sa_handler != SIG_DFL) { /* Run the handler. */ ksig->ka = *ka; //如果设置了SA_RESETHAND或者SA_ONESHOT标志(这俩标志的值是一样的),将其信号处理函数重设为默认 if (ka->sa.sa_flags & SA_ONESHOT) ka->sa.sa_handler = SIG_DFL; break; /* will return non-zero "signr" value */ } //下面为默认信号处理 //部分信号的默认动作为忽略(具体可以查看SIG_KERNEL_IGNORE_MASK这个宏定义) if (sig_kernel_ignore(signr)) /* Default is nothing. */ continue; ... //部分信号的默认动作为停止进程(具体可以查看SIG_KERNEL_STOP_MASK这个宏定义) if (sig_kernel_stop(signr)) { if (signr != SIGSTOP) { spin_unlock_irq(&sighand->siglock); //当前为孤儿进程组 if (is_current_pgrp_orphaned()) goto relock; spin_lock_irq(&sighand->siglock); } //默认动作为停止当前线程组里的所有线程 if (likely(do_signal_stop(ksig->info.si_signo))) { goto relock; } continue; } fatal: spin_unlock_irq(&sighand->siglock); ... current->flags |= PF_SIGNALED; //部分信号的默认动作为dump core,然后终止进程(具体可以查看SIG_KERNEL_COREDUMP_MASK这个宏定义) if (sig_kernel_coredump(signr)) { if (print_fatal_signals) print_fatal_signal(ksig->info.si_signo); proc_coredump_connector(current); do_coredump(&ksig->info); } if (current->flags & PF_IO_WORKER) goto out; //剩下来的信号的默认操作为终止进程 do_group_exit(ksig->info.si_signo); } spin_unlock_irq(&sighand->siglock); out: ksig->sig = signr; if (!(ksig->ka.sa.sa_flags & SA_EXPOSE_TAGBITS)) hide_si_addr_tag_bits(ksig); //当当前进程对此信号设置了自定义信号处理动作后,返回true return ksig->sig > 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
likely & unlikely
这里的likely和unlikely为两个宏,指向__builtin_expect函数,是gcc编译器提供给程序员优化的一种方式,likely表示表达式为真的可能性更大,unlikely表示表达式为假的可能性更大,这样gcc编译器可以在编译过程中,将可能性更大的代码紧跟前面的代码,减少指令跳转带来的性能开销
我们接着看,当用户自定义了信号处理函数后,内核是怎么处理的。从上面的代码看来,当用户自定义了信号处理函数,get_signal函数会返回true,紧接着就会进入到handle_signal函数中,这里的处理比较特殊,我们要先了解信号处理的一些过程
用户自定义信号处理函数实际上是在用户空间执行的,目的是为了防止用户利用内核空间的ring 0特权等级做一些意想不到的事,处理过程如下两图所示:
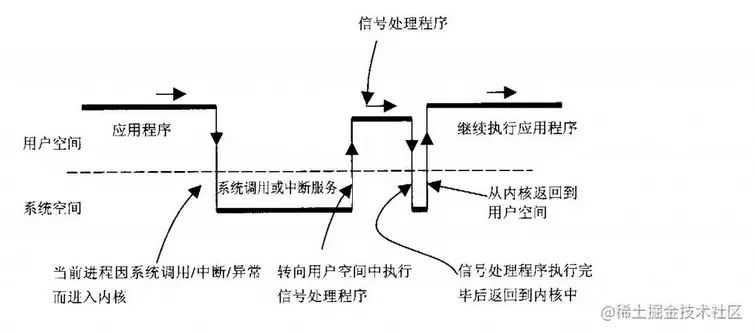

整个过程如图中所见,进程由于系统调用或中断进入内核空间,在内核空间完成工作后返回用户空间的前夕,检查信号队列,如果检查有信号并且有自定义的信号处理函数,返回到用户空间执行信号处理函数,处理完后再返回内核空间,最后再回到用户空间之前代码执行到的地方继续运行
可以看到,这一套流程经历了4次用户态与内核态的切换,比较复杂,那么内核是如何做到的呢?为什么信号处理函数执行完后还要返回内核空间呢?
用户态与内核态的切换
在Linux中,在用户态和内核态运行的进程使用的是不同的栈,分别为用户栈和内核栈,当一个进程陷入内核态时,需要将用户栈的信息保存到内核栈中,具体的,会将ss, sp, flags, cs, ip等值依次压入栈中,保存为pt_regs结构,然后设置CPU堆栈寄存器的地址为内核栈顶,这样,后续使用的栈便变成了内核栈,当系统调用结束,需要从内核态切换到用户态时,再将之前压入栈中的寄存器值弹出,将pt_regs中保存的值恢复到相应的寄存器中,这里改变了sp寄存器的值,即完成了换栈,cs:ip这两个寄存器分别指向用户态代码段以及用户态指令指针,后续CPU便会执行之前用户态的代码了
pt_regs结构体
pt_regs结构体位于arch/x86/include/asm/ptrace.h中
struct pt_regs { /* * C ABI says these regs are callee-preserved. They aren't saved on kernel entry * unless syscall needs a complete, fully filled "struct pt_regs". */ unsigned long r15; unsigned long r14; unsigned long r13; unsigned long r12; unsigned long bp; unsigned long bx; /* These regs are callee-clobbered. Always saved on kernel entry. */ unsigned long r11; unsigned long r10; unsigned long r9; unsigned long r8; unsigned long ax; unsigned long cx; unsigned long dx; unsigned long si; unsigned long di; /* * On syscall entry, this is syscall#. On CPU exception, this is error code. * On hw interrupt, it's IRQ number: */ unsigned long orig_ax; /* Return frame for iretq */ unsigned long ip; unsigned long cs; unsigned long flags; unsigned long sp; unsigned long ss; /* top of stack page */ };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
我们从理论角度上大概理解了内核是怎么在用户态与内核态之间切换的,接下来我们去源码里验证一下是不是我们所想的这样,syscall的入口函数为entry_SYSCALL_64,位于arch/x86/entry/entry_64.S中
SYM_CODE_START(entry_SYSCALL_64) UNWIND_HINT_EMPTY /* 切换gs寄存器至内核态 */ swapgs /* tss.sp2为用户栈 */ movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* 切换页表 */ SWITCH_TO_KERNEL_CR3 scratch_reg=%rsp /* 切换至内核栈 */ movq PER_CPU_VAR(cpu_current_top_of_stack), %rsp SYM_INNER_LABEL(entry_SYSCALL_64_safe_stack, SYM_L_GLOBAL) /* 保存用户栈寄存器值至pt_regs结构中 */ pushq $__USER_DS /* pt_regs->ss */ pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* pt_regs->sp */ /* 当执行syscall指令时,cpu会将rflags的值保存在r11寄存器中 */ pushq %r11 /* pt_regs->flags */ pushq $__USER_CS /* pt_regs->cs */ /* 当执行syscall指令时,cpu会将syscall指令的下一条指令的地址传给rcx寄存器 */ pushq %rcx /* pt_regs->ip */ SYM_INNER_LABEL(entry_SYSCALL_64_after_hwframe, SYM_L_GLOBAL) pushq %rax /* pt_regs->orig_ax */ /* 保存并清除寄存器 */ PUSH_AND_CLEAR_REGS rax=$-ENOSYS /* 此时,rsp指向的栈顶地址即为pt_regs的地址 */ movq %rsp, %rdi /* 设置系统调用号 */ movslq %eax, %rsi /* 以rdi, rsi作为参数,调用do_syscall_64函数 */ call do_syscall_64 /* returns with IRQs disabled */ ... cmpq %rcx, %r11 jne swapgs_restore_regs_and_return_to_usermode cmpq $__USER_CS, CS(%rsp) /* CS must match SYSRET */ jne swapgs_restore_regs_and_return_to_usermode movq R11(%rsp), %r11 cmpq %r11, EFLAGS(%rsp) /* R11 == RFLAGS */ jne swapgs_restore_regs_and_return_to_usermode testq $(X86_EFLAGS_RF|X86_EFLAGS_TF), %r11 jnz swapgs_restore_regs_and_return_to_usermode cmpq $__USER_DS, SS(%rsp) /* SS must match SYSRET */ jne swapgs_restore_regs_and_return_to_usermode /* * 这个标签实际上只是为了便于理解,并没有地方跳转它 * 实际工作是在swapgs_restore_regs_and_return_to_usermode中完成的 */ syscall_return_via_sysret: /* 恢复寄存器 */ POP_REGS pop_rdi=0 skip_r11rcx=1 movq %rsp, %rdi /* 保存内核栈 */ movq PER_CPU_VAR(cpu_tss_rw + TSS_sp0), %rsp UNWIND_HINT_EMPTY pushq RSP-RDI(%rdi) /* RSP */ pushq (%rdi) /* RDI */ STACKLEAK_ERASE_NOCLOBBER /* 切换页表 */ SWITCH_TO_USER_CR3_STACK scratch_reg=%rdi popq %rdi popq %rsp /* 切换gs寄存器至用户态 */ swapgs /* 恢复rip, rflags等寄存器,使cpu接下来要执行指令指向syscall的下一条指令 */ sysretq SYM_CODE_END(entry_SYSCALL_64)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
信号处理函数的跳转方式
但是在系统调用完后,回到的将是syscall后的下一条指令,那么如何才能让程序去执行信号处理函数呢?信号处理函数执行完后,又如何回到之前所执行到的代码呢?我们很容易就能想到,先将pt_regs中的值备份一下,然后改变pt_regs中一些寄存器值,比如说将cs:ip修改成信号处理函数对应地址,这样从内核态返回后,就会自动跳转到信号处理函数了,等到信号处理函数执行完,再进入内核态,恢复pt_regs中的值后回到用户态,这样cpu又会从用户调用syscall后的指令开始正常执行了
我们具体的看一下内核代码是怎么做的,这里的逻辑在arch/x86/kernel/signal.c中的handle_signal函数里
static void handle_signal(struct ksignal *ksig, struct pt_regs *regs) { ... failed = (setup_rt_frame(ksig, regs) < 0); ... signal_setup_done(failed, ksig, stepping); } static int setup_rt_frame(struct ksignal *ksig, struct pt_regs *regs) { int usig = ksig->sig; sigset_t *set = sigmask_to_save(); compat_sigset_t *cset = (compat_sigset_t *) set; /* Perform fixup for the pre-signal frame. */ rseq_signal_deliver(ksig, regs); //设置栈帧 if (is_ia32_frame(ksig)) { if (ksig->ka.sa.sa_flags & SA_SIGINFO) return ia32_setup_rt_frame(usig, ksig, cset, regs); else return ia32_setup_frame(usig, ksig, cset, regs); } else if (is_x32_frame(ksig)) { return x32_setup_rt_frame(ksig, cset, regs); } else { return __setup_rt_frame(ksig->sig, ksig, set, regs); } } //x86_64执行的应该是这个函数 static int __setup_rt_frame(int sig, struct ksignal *ksig, sigset_t *set, struct pt_regs *regs) { struct rt_sigframe __user *frame; void __user *fp = NULL; unsigned long uc_flags; /* x86-64 should always use SA_RESTORER. */ if (!(ksig->ka.sa.sa_flags & SA_RESTORER)) return -EFAULT; //获取一个栈帧 frame = get_sigframe(&ksig->ka, regs, sizeof(struct rt_sigframe), &fp); uc_flags = frame_uc_flags(regs); if (!user_access_begin(frame, sizeof(*frame))) return -EFAULT; /* Create the ucontext. */ unsafe_put_user(uc_flags, &frame->uc.uc_flags, Efault); unsafe_put_user(0, &frame->uc.uc_link, Efault); unsafe_save_altstack(&frame->uc.uc_stack, regs->sp, Efault); /* Set up to return from userspace. If provided, use a stub already in userspace. */ //设置执行完信号处理函数后,要跳回的地址,即sa_restorer unsafe_put_user(ksig->ka.sa.sa_restorer, &frame->pretcode, Efault); //将原本的pt_regs备份保存至frame.uc.uc_mcontext中 unsafe_put_sigcontext(&frame->uc.uc_mcontext, fp, regs, set, Efault); unsafe_put_sigmask(set, frame, Efault); user_access_end(); if (ksig->ka.sa.sa_flags & SA_SIGINFO) { if (copy_siginfo_to_user(&frame->info, &ksig->info)) return -EFAULT; } //信号处理函数的第1个参数 regs->di = sig; /* In case the signal handler was declared without prototypes */ regs->ax = 0; /* 设置了SA_SIGINFO标志位,需要带一些额外的信号信息 */ //信号处理函数的第2个参数 regs->si = (unsigned long)&frame->info; //信号处理函数的第3个参数 regs->dx = (unsigned long)&frame->uc; //设置指令指针指向信号处理函数 //sigaction结构体中的第一个域是一个联合,所以这里 //sa_handler和sa_sigaction的地址是相同的 regs->ip = (unsigned long) ksig->ka.sa.sa_handler; //设置栈顶地址 regs->sp = (unsigned long)frame; //设置用户代码段 regs->cs = __USER_CS; if (unlikely(regs->ss != __USER_DS)) force_valid_ss(regs); return 0; Efault: user_access_end(); return -EFAULT; } #define unsafe_put_sigcontext(sc, fp, regs, set, label) \ do { \ if (__unsafe_setup_sigcontext(sc, fp, regs, set->sig[0])) \ goto label; \ } while(0); static __always_inline int __unsafe_setup_sigcontext(struct sigcontext __user *sc, void __user *fpstate, struct pt_regs *regs, unsigned long mask) { unsafe_put_user(regs->di, &sc->di, Efault); unsafe_put_user(regs->si, &sc->si, Efault); unsafe_put_user(regs->bp, &sc->bp, Efault); unsafe_put_user(regs->sp, &sc->sp, Efault); unsafe_put_user(regs->bx, &sc->bx, Efault); unsafe_put_user(regs->dx, &sc->dx, Efault); unsafe_put_user(regs->cx, &sc->cx, Efault); unsafe_put_user(regs->ax, &sc->ax, Efault); unsafe_put_user(regs->r8, &sc->r8, Efault); unsafe_put_user(regs->r9, &sc->r9, Efault); unsafe_put_user(regs->r10, &sc->r10, Efault); unsafe_put_user(regs->r11, &sc->r11, Efault); unsafe_put_user(regs->r12, &sc->r12, Efault); unsafe_put_user(regs->r13, &sc->r13, Efault); unsafe_put_user(regs->r14, &sc->r14, Efault); unsafe_put_user(regs->r15, &sc->r15, Efault); unsafe_put_user(current->thread.trap_nr, &sc->trapno, Efault); unsafe_put_user(current->thread.error_code, &sc->err, Efault); unsafe_put_user(regs->ip, &sc->ip, Efault); unsafe_put_user(regs->flags, &sc->flags, Efault); unsafe_put_user(regs->cs, &sc->cs, Efault); unsafe_put_user(0, &sc->gs, Efault); unsafe_put_user(0, &sc->fs, Efault); unsafe_put_user(regs->ss, &sc->ss, Efault); unsafe_put_user(fpstate, (unsigned long __user *)&sc->fpstate, Efault); /* non-iBCS2 extensions.. */ unsafe_put_user(mask, &sc->oldmask, Efault); unsafe_put_user(current->thread.cr2, &sc->cr2, Efault); return 0; Efault: return -EFAULT; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
这里实际上是这么做的,首先,内核默认在用户栈上分配了一个栈帧(如果设置了备用栈的话,则会在备用栈上分配),将pt_regs备份到这个栈帧上,用于后续恢复,然后设置pt_regs,改变其sp, cs, ip等值,使程序从内核态返回时,可以跳转到信号处理函数对应的栈和代码指令地址,当信号处理函数返回时会执行sigreturn系统调用再进入内核态,将之前备份到栈帧中的寄存器值重新恢复到pt_regs中,然后再从内核态回到用户态就可以正常继续执行syscall后面的代码了
其中sa_restorer是在glibc里的__libc_sigaction函数中被设置的
int __libc_sigaction (int sig, const struct sigaction *act, struct sigaction *oact) { int result; struct kernel_sigaction kact, koact; if (act) { kact.k_sa_handler = act->sa_handler; memcpy (&kact.sa_mask, &act->sa_mask, sizeof (sigset_t)); kact.sa_flags = act->sa_flags; //设置sa_restorer SET_SA_RESTORER (&kact, act); } ... return result; } extern void restore_rt (void) asm ("__restore_rt") attribute_hidden; #define SET_SA_RESTORER(kact, act) \ (kact)->sa_flags = (act)->sa_flags | SA_RESTORER; \ (kact)->sa_restorer = &restore_rt RESTORE (restore_rt, __NR_rt_sigreturn) #define RESTORE(name, syscall) RESTORE2 (name, syscall) #define RESTORE2(name, syscall) \ asm \ ( \ /* `nop' for debuggers assuming `call' should not disalign the code. */ \ " nop\n" \ ".align 16\n" \ ".LSTART_" #name ":\n" \ " .type __" #name ",@function\n" \ "__" #name ":\n" \ " movq $" #syscall ", %rax\n" \ " syscall\n" \ ... );
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
可以看到,这里也是一个系统调用,和上面所说的规则一样,它最终会调用sys_rt_sigreturn函数,具体实现如下:
SYSCALL_DEFINE0(rt_sigreturn) { struct pt_regs *regs = current_pt_regs(); struct rt_sigframe __user *frame; sigset_t set; unsigned long uc_flags; frame = (struct rt_sigframe __user *)(regs->sp - sizeof(long)); if (!access_ok(frame, sizeof(*frame))) goto badframe; if (__get_user(*(__u64 *)&set, (__u64 __user *)&frame->uc.uc_sigmask)) goto badframe; if (__get_user(uc_flags, &frame->uc.uc_flags)) goto badframe; set_current_blocked(&set); //frame.uc.uc_mcontext中恢复pt_regs if (!restore_sigcontext(regs, &frame->uc.uc_mcontext, uc_flags)) goto badframe; if (restore_altstack(&frame->uc.uc_stack)) goto badframe; return regs->ax; badframe: signal_fault(regs, frame, "rt_sigreturn"); return 0; } static bool restore_sigcontext(struct pt_regs *regs, struct sigcontext __user *usc, unsigned long uc_flags) { struct sigcontext sc; /* Always make any pending restarted system calls return -EINTR */ current->restart_block.fn = do_no_restart_syscall; if (copy_from_user(&sc, usc, CONTEXT_COPY_SIZE)) return false; regs->bx = sc.bx; regs->cx = sc.cx; regs->dx = sc.dx; regs->si = sc.si; regs->di = sc.di; regs->bp = sc.bp; regs->ax = sc.ax; regs->sp = sc.sp; regs->ip = sc.ip; regs->r8 = sc.r8; regs->r9 = sc.r9; regs->r10 = sc.r10; regs->r11 = sc.r11; regs->r12 = sc.r12; regs->r13 = sc.r13; regs->r14 = sc.r14; regs->r15 = sc.r15; /* Get CS/SS and force CPL3 */ regs->cs = sc.cs | 0x03; regs->ss = sc.ss | 0x03; regs->flags = (regs->flags & ~FIX_EFLAGS) | (sc.flags & FIX_EFLAGS); /* disable syscall checks */ regs->orig_ax = -1; ... return fpu__restore_sig((void __user *)sc.fpstate, IS_ENABLED(CONFIG_X86_32)); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
从上面代码还是可以比较清楚的看出来,和我们之前描述的原理基本一致,到这一步时,恢复pt_regs中的值,这样后续返回用户态后便可以正常继续运行后面的用户代码了
总结
Linux信号的原理分析到这基本上也就结束了,其实整个信号原理分析对现阶段的我来说,还是一件相当具有挑战性的事情,不过在此过程中,还是收获了很多知识,也发现了一些之前文章里错漏的地方,由于我对Linux内核以及汇编并不熟悉,所以难免会有一些分析错误或者不到位的地方,欢迎大家指正
附录
信号表
| 取值 | 名称 | 解释 | 默认动作 |
|---|---|---|---|
| 1 | SIGHUP | 挂起 | 终止进程 |
| 2 | SIGINT | 中断 | 终止进程 |
| 4 | SIGILL | 非法指令 | coredump后终止进程 |
| 5 | SIGTRAP | 断点或陷阱指令 | coredump后终止进程 |
| 6 | SIGABRT/SIGIOT | abort发出的信号 | coredump后终止进程 |
| 7 | SIGBUS | 非法内存访问 | coredump后终止进程 |
| 8 | SIGFPE | 浮点异常 | coredump后终止进程 |
| 9 | SIGKILL | kill信号 | 不能被忽略、处理和阻塞 |
| 10 | SIGUSR1 | 用户自定义信号1 | 终止进程 |
| 11 | SIGSEGV | 无效内存访问 | coredump后终止进程 |
| 12 | SIGUSR2 | 用户自定义信号2 | 终止进程 |
| 13 | SIGPIPE | 管道破损,没有读端的管道写数据 | 终止进程 |
| 14 | SIGALRM | alarm发出的信号 | 终止进程 |
| 15 | SIGTERM | 终止信号 | 终止进程 |
| 16 | SIGSTKFLT | 栈溢出 | 终止进程 |
| 17 | SIGCHLD | 子进程退出 | 忽略信号 |
| 18 | SIGCONT | 进程继续 | 忽略信号 |
| 19 | SIGSTOP | 进程停止 | 不能被忽略、处理和阻塞 |
| 20 | SIGTSTP | 进程停止 | 停止进程 |
| 21 | SIGTTIN | 进程停止,后台进程从终端读数据时 | 停止进程 |
| 22 | SIGTTOU | 进程停止,后台进程想终端写数据时 | 停止进程 |
| 23 | SIGURG | I/O有紧急数据到达当前进程 | 忽略信号 |
| 24 | SIGXCPU | 进程的CPU时间片到期 | coredump后终止进程 |
| 25 | SIGXFSZ | 文件大小的超出上限 | coredump后终止进程 |
| 26 | SIGVTALRM | 虚拟时钟超时 | 终止进程 |
| 27 | SIGPROF | profile时钟超时 | 终止进程 |
| 28 | SIGWINCH | 窗口大小改变 | 忽略信号 |
| 29 | SIGPOLL/SIGIO | I/O相关 | 终止进程 |
| 30 | SIGPWR | 关机 | 默认忽略 |
| 31 | SIGSYS/SIGUNUSED | 系统调用异常 | coredump后终止进程 |


