
- 1windows下搭建Redis群集,实现主从复制 和 故障转移_redis在windows上故障转移
- 21.1 微信Native支付 - 接入指引与支付安全
- 3考研系列-数据结构第七章:查找(下)_b树和b+树
- 4朝阳医院2018年销售数据 数据分析与可视化
- 5微信部署ChatGPT机器人/bot_chatgpt for wechat
- 6粤嵌gec6818开发板-播放视频、音频文件(管道文件控制)_6818开发版视频播放
- 7算法导论笔记:13-04红黑树以及其他平衡树_加权平衡树
- 82023年2月可用的免费图床_图床链接生成器
- 9热门开源项目推荐
- 10FPGA之JESD204B接口——总体概要 尾片_204b映射关系
Spark的10个常见面试题_spark面试题
赞
踩
关于 Apache Spark 的重要面试问题
微信搜索关注《Java学研大本营》,加入读者群,分享更多精彩
Apache Spark 是一个用于大规模数据处理的开源统一分析引擎。Spark 的内存数据处理能力使其比 Hadoop 快 100 倍。它具有在如此短的时间内处理大量数据的能力。Spark 最重要的特性是内存数据处理。

Spark 是面试官在大数据面试中最喜欢的话题之一,因此在这篇博客中,我们将回顾有关 Apache Spark 的最重要和最常见的面试问题。
1.Spark是什么?
Spark 是一个通用的内存计算引擎。您可以将它与任何存储系统连接,如本地存储系统、HDFS、Amazon S3 等。它还让您可以自由使用您选择的资源管理器,无论是 Yarn、Mesos、Kubernetes 还是独立的。它旨在管理批处理应用程序工作负载、迭代算法、交互式查询和流式传输。Spark 支持高级 API,例如Java、Scala、Python和R。它是用 Scala 语言构建的。
2. Apache Spark 中的 RDD 是什么?
RDD 代表弹性分布式数据集。它是任何 Spark 应用程序最重要的构建块 。它是不可变的。RDD 属性是:-
-
弹性:- 它具有容错特性,可以快速恢复丢失的数据。
-
分布式:- 数据分布在多个节点上以加快处理速度。
-
数据集:- 我们执行操作的数据点的集合。RDD 通过沿袭图提供容错能力。沿袭图跟踪调用动作后要执行的转换。沿袭图有助于重新计算由于节点故障而丢失或损坏的任何 RDD。RDD 用于低级转换和操作。
3. SparkContext 与 SparkContext 之间的区别是什么?火花会议?
在 Spark 1.x 版本中,我们必须为每个 API 创建不同的上下文。例如:-
-
Spark上下文
-
SQL上下文
-
Hive上下文 而在 spark 2.x 版本中,引入了一个名为 SparkSession 的新入口点,单独覆盖了所有功能。无需为入口点创建不同的上下文。
SparkContext是访问 spark 功能的主要入口点。它表示 spark 集群的连接,这对于在集群上构建 RDD、累加器和广播变量很有用。我们可以在 spark-shell 中访问 SparkContext 的默认对象,它存在于变量名“sc”中。
SparkSession:-在 spark 2.0 版本之前,我们需要不同的上下文来访问 spark 中的不同功能。而在 spark 2.0 中,我们有一个名为 SparkSession 的统一入口点。它包含 SQLContext、HiveContext 和 StreamingContext。无需创建单独的。在这些上下文中可访问的 API 同样在SparkSession中可用,并且 SparkSession 包含用于实际计算的SparkContext。
4.什么是广播变量?
Spark 中的广播变量是一种在执行程序之间共享只读数据的机制。如果没有广播变量,我们必须在执行任何类型的转换和操作时将数据发送给每个执行器,这可能会导致网络开销。而在广播变量的情况下,它们会一次性发送给所有执行程序并缓存在那里以供将来参考。
广播变量用例
假设我们正在进行转换,需要查找一个更大的邮政编码/密码表。在需要的时候把数据发给每个executor是不可行的,我们也不可能每次都去数据库查询。因此,在这种情况下,我们可以将此查找表转换为广播变量,Spark 会将其缓存在每个执行程序中。
5.解释Pair RDD?
Spark Paired RDD 是键值对的集合。键值对(KVP)中有两个数据项。键是标识符,值是键值对应的数据。在键值对的 RDD 上可以进行一些特殊操作,例如分布式“洗牌”操作、分组或按键聚合元素。
- val spark = SparkSession.builder()
-
- .appName("PairedRDDCreation")
-
- .master("local")
-
- .getOrCreate()
-
- val rdd = spark.sparkContext.parallelize(
- List("Germany India USA","USA India Russia","India Brazil Canada China"))
- val wordsRdd = rdd.flatMap(_.split(" "))
- val pairRDD = wordsRdd.map(f=>(f,1))
- pairRDD.foreach(println)
输出:
- (Germany,1)
- (India,1)
- (USA,1)
- (USA,1)
- (India,1)
- (Russia,1)
- (India,1)
- (Brazil,1)
- (Canada,1)
- (China,1)
6. RDD persist() 和 cache() 方法有什么区别?
持久性和缓存机制是优化技术。它可用于交互式和迭代计算。迭代意味着在多次计算中重用结果。交互意味着允许信息的双向流动。这些机制帮助我们保存结果,以便接下来的阶段可以使用它们。我们可以将 RDD 保存在内存(首选)或磁盘((不太首选,因为它的访问速度慢)。
**Persist()**:-我们知道,由于 RDD 的默认行为,每个操作都可以重新计算 RDD。为了避免重新计算,我们可以坚持使用 RDD。现在,无论何时我们调用 RDD 上的操作,都不会发生重新计算。
在 persist() 方法中,计算结果存储在它的分区中。使用 Java 和 Scala 时,持久化方法会将数据存储在 JVM 中。而在 python 中,当我们调用 persist 方法时,就会发生数据的序列化。我们可以将数据存储在内存中或磁盘上。两者的组合也是可能的。
持久化 RDD 的存储级别:-
-
MEMORY_ONLY(DEFAULT LEVEL)
-
MEMORY_AND_DISK
-
MEMORY_ONLY_SER
-
MEMORY_ONLY_DISK_SER
-
DISC_ONLY
Cache():-与persist方法相同;唯一的区别是缓存将计算结果存储在默认存储级别,即内存。当存储级别设置为 MEMORY_ONLY 时,Persist 将像缓存一样工作。
取消保留 RDD 的语法:-
RDD.unpersist()
7. 什么是Spark Core?
Spark Core 是所有 Spark 应用程序的基础单元。它执行以下功能:内存管理、故障恢复、调度、分发和监控作业以及与存储系统的交互。可以通过用 Java、Scala、Python 和 R 构建的应用程序编程接口 (API) 访问 Spark Core。它包含有助于定义和操作 RDD 的 API。这些 API 有助于将分布式处理的复杂性隐藏在简单的高级运算符背后。它提供与不同数据源的基本连接,如 AWS S3、HDFS、HBase 等。
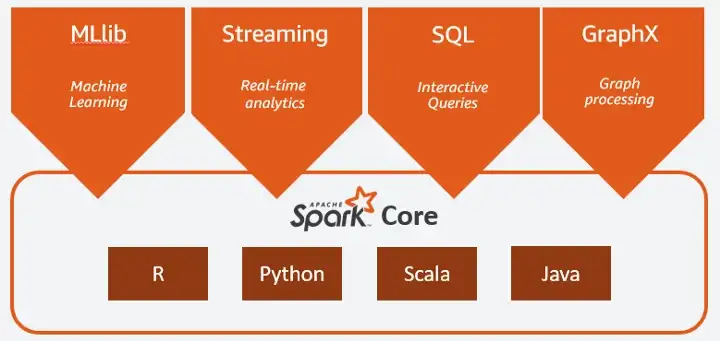
资料来源:Spark 文档
8. 什么是 RDD 沿袭?
RDD Lineage(RDD operator graph或RDD dependency graph)是包含一个 RDD 的所有父 RDD 的图。
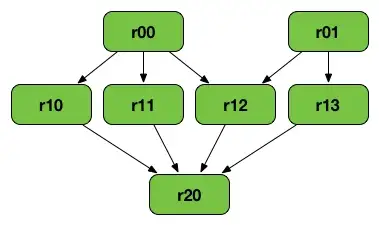
以下转换可以生成上图:-
- val r00 = sc.parallelize(0 to 9)
- val r01 = sc.parallelize(0 to 90 by 10)
- val r10 = r00.cartesian(r01)
- val r11 = r00.map(n => (n, n))
- val r12 = r00.zip(r01)
- val r13 = r01.keyBy(_ / 20)
- val r20 = Seq(r11, r12, r13).foldLeft(r10)(_ union _)
-
当我们对一个 RDD 应用不同类型的转换时,RDD 沿袭被创建,创建一个所谓的逻辑执行计划。
-
谱系图包含有关调用操作时需要应用的所有转换的信息。
-
逻辑执行计划从最早的RDD开始,到RDD结束,产生调用action的最终结果。
9.RDD和DataFrame有什么区别?
数据框:-
数据框以表格格式存储数据。它是行和列中的分布式数据集合。这些列可以存储数据类型,例如数字、逻辑、因子或字符。它使处理更大的数据集更加容易。开发人员可以在数据框架的帮助下将结构强加到分布式数据集合上。它还提供了对分布式数据的高级抽象。
RDD:-
RDD(Resilient Distributed Dataset)是分布在多个集群节点上的元素集合。RDD 是不可变的和容错的。RDDs,一旦创建,就不能改变,但是我们可以执行一些转换来从中生成新的 RDDs。
10. 解释 Spark 中的 Accumulator 共享变量?
累加器是只读的共享变量。它们仅通过关联和交换操作“添加”。它们可用于实现计数器(如在 MapReduce 中)或求和。Spark 原生支持数字类型的累加器,您还可以添加对新类型的支持。
累加器是增量变量。在节点上运行的任务可以添加到它,而驱动程序可以读取该值。在不同机器上运行的任务可以递增它们的值,并且此聚合信息可返回给驱动程序。
在本文中,我们讨论了关于 Apache Spark 的最重要和最常见的面试问题。我们从一些基本问题开始讨论,例如什么是 spark、RDD、Dataset 和 DataFrame。然后,我们转向中级和高级主题,如广播变量、缓存和 spark 中的持久方法、累加器和 pair RDD。

推荐书单
《项目驱动零起点学Java》
《项目驱动零起点学Java》共分 13 章,围绕 6 个项目和 258 个代码示例,分别介绍了走进Java 的世界、变量与数据类型、运算符、流程控制、方法、数组、面向对象、异常、常用类、集合、I/O流、多线程、网络编程相关内容。《项目驱动零起点学Java》总结了马士兵老师从事Java培训十余年来经受了市场检验的教研成果,通过6 个项目以及每章的示例和习题,可以帮助读者快速掌握Java 编程的语法以及算法实现。扫描每章提供的二维码可观看相应章节内容的视频讲解。
《项目驱动零起点学Java》贯穿6个完整项目,经过作者多年教学经验提炼而得,项目从小到大、从短到长,可以让读者在练习项目的过程中,快速掌握一系列知识点。
马士兵,马士兵教育创始人,毕业于清华大学,著名IT讲师,所讲课程广受欢迎,学生遍布全球大厂,擅长用简单的语言讲授复杂的问题,擅长项目驱动知识的综合学习。马士兵教育获得在线教育“名课堂”奖、“最受欢迎机构”奖。
赵珊珊,从事多年一线开发,曾为国税、地税税务系统工作。拥有7年一线教学经验,多年线上、线下教育的积累沉淀,培养学员数万名,讲解细致,脉络清晰。

精彩回顾
微信搜索关注《Java学研大本营》
访问【IT今日热榜】,发现每日技术热点

