
- 1autojs粘贴文本_autojs基础教程 入门篇
- 2220:vue+openlayers 加载动画,采用css的@keyframes方式_layer加载动画
- 3浅聊最近几次的面试经历_玄武云前端面试
- 4Udacity简明自动驾驶原理:它凭什么改变未来?
- 5【机器学习】【深度学习】【人工智能】【算法工程师】面试问题汇总(持续更新)_人工智能工程师面试试题
- 6自然语言处理-信息提取_自然语言处理 信息提取
- 7计算机网络综合实训——某分公司网络搭建_企业网络搭建综合实训
- 8hive concat_ws列转行排序问题_hive列转行时保证顺序
- 9Java计算机毕业设计和Vue的安全教育科普平台设计与实现(开题报告+源码+论文)
- 10(十六)ArcGIS JS 如何获取服务中图层geometry的属性symbol_arcgis api js 获取点击要素的属性
总结当前开源可用的Instruct/Prompt Tuning数据
赞
踩

©作者 | 李雨承
单位 | 英国萨里大学
研究方向 | Conceptual Reasoning
最近在做大模型的尝试和评测,之前写了一篇总结可用大模型的文章,反响很好,有很多有价值的反馈:
https://zhuanlan.zhihu.com/p/611403556
本文总结开源可用的 Instruct Prompt 数据(截止19.03.2023)。
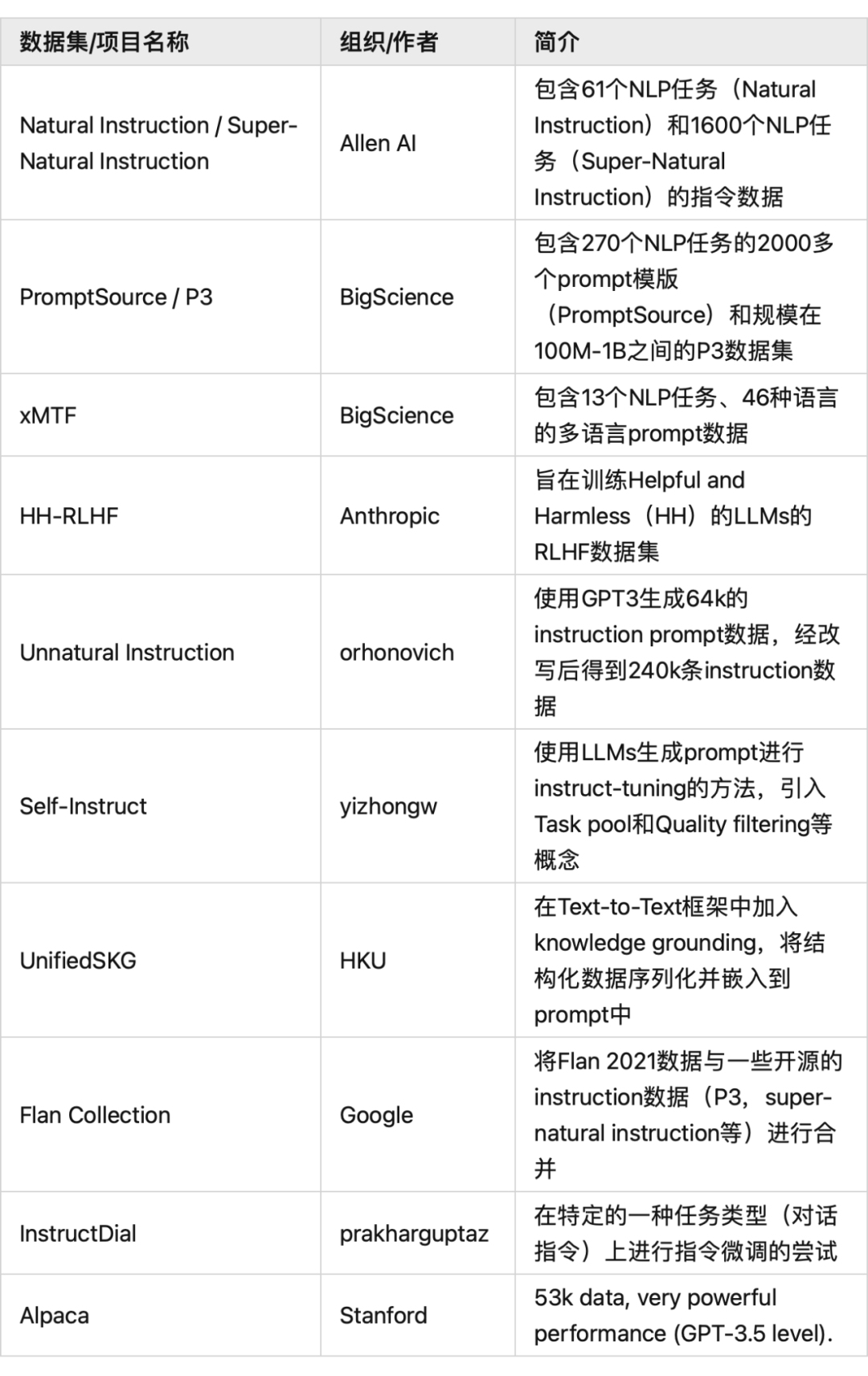

Natural Instruction/Super-Natural Instruction-Allen AI
Allen AI. 是第一批尝试 Instruction 做 prompt 并微调 LLMs 的机构。
在 Natural Instruction 论文里可以基本了解 instruction 的标注思路:
https://aclanthology.org/2022.acl-long.244.pdf
在其提出的数据集中,包含了 61 和不同的 NLP tasks。
Super-Natural Instruction 是 Natural Instruction 的超级加量版,其包含了超过 1600 个不同的 NLP 任务,光是不同种类的 NLP 任务(例如:分类,抽取,序列标注)就超过 76 个:
https://arxiv.org/pdf/2204.07705.pdf
Natural/Super-Natural Instruction 数据均在以下网址开源:
https://instructions.apps.allenai.org/

PromptSource/P3-BigScience
BigScience 由 Hugging Face 和法国 CNRS,IDRIS,GENCI 等联合组织,是当下最大的开源 LLMs 组织之一。
BigScience 在 2021 年末开发了PromptSource项目,开源了一系列工具 toolkits,帮助研究者基于现有NLP 任务构建 prompt。截止目前,PromptSource 项目包含了 270 个 NLP 任务的超过 2000 个 prompt 模版:
https://github.com/bigscience-workshop/promptsource
在此基础上,BigScience 构建了 P3 数据集。在 Hugging Face Hub 上你可以找到 P3 数据,P3 的数据规模在 100M-1B 之间:
https://huggingface.co/datasets/bigscience/P3

xMTF - BigScience
BigScience 在英语 prompt 的基础上,扩展其 prompt 到多种非英语语言。
https://arxiv.org/pdf/2211.01786.pdf
https://github.com/bigscience-workshop/xmtf
该项目包含了 13 个 NLP 任务,并采用了 46 个不同的语言的版本。对应的 prompt 包含的语种个数不定。
在 multilingual 的基础上微调后,BLOOM 和 T0 都变现出了理想的多语言能力。

HH-RLHF - Anthropic
Anthropic 公司旗下的 Claud 是 ChatGPT 的主要竞品之一。
Anthropic 开源了其在自己产品线中使用的 RLHF 数据集:
https://huggingface.co/datasets/Anthropic/hh-rlhf
HH-RLHF 项目的初衷在于训练 Helpful and Harmless(HH)的 LLMs。故该项目除了回复质量外,是否为有害信息也体现在了其 human feedback 中:
https://arxiv.org/pdf/2204.05862.pdf
论文中记录了如何使用 RLHF 数据 Align 模型的 behaviour 到人类的价值观上,同时记录了数据集的构建方式和标准。

Unnatural Instruction
https://arxiv.org/pdf/2212.09689.pdf
https://github.com/orhonovich/unnatural-instructions
使用 LLMs 自主生成 instruction 数据是 instruct-tuning 领域较为活跃的一个方向。
Unnatural Instruction 使用 GPT3(text-davinci-002)生成了 64k 的 instruction prompt 数据。并使用同样的模型将 64k 的 prompt 进行改写,最终得到了 240k 条 instruction 数据。
论文中显示,在 Instruct-Tuning 中 LLMs 自主生成的 prompt 表现出了良好的效果,甚至超过了在 P3 等数据上进行微调的 T0 等模型。

Self-Instruct
https://arxiv.org/pdf/2212.10560.pdf
https://github.com/yizhongw/self-instruct
Self-Instruct 同样是使用 LLMs 生成 prompt 进行 instruct-tuning 的思路。不过使用了更 fine-grained 的生成流程。
Task pool 和 Quality filtering 等概念被引入,部分缓解了 self-intrauct 类型数据的 noise 问题。

UnifiedSKG - HKU
https://arxiv.org/pdf/2201.05966.pdf
UnifiedSKG 在 Text-to-Text 的框架中加入了 knowledge grounding,也就是在 prompt-output 的框架中,加入了结构化数据做辅助。
举个例子,某些 NLP 任务非常依赖结构化的知识库/数据库。UnifiedSKG 的思路是将需要的数据库序列化,并嵌入到 prompt 中。如下图所示。

UnifiedSKG 代表了 LLMs 领域中尝试使用结构化知识增强性能的一个方向。
我在 EMNLP 上和作者本人聊天时,被这个项目的思路吸引,感觉这是个很有前途的方向(好像作者本人也在知乎,当时忘了加好友很可惜)。
该项目的网站如下,网站上有较为详细的使用说明:
https://unifiedskg.com/

Flan Collection-Google
Google 在这个项目中将自己的 Flan 2021 数据与一些开源的 instruction 数据(P3,super-natural instruction 等)进行了合并:
https://github.com/google-research/FLAN/tree/main/flan/v2
https://arxiv.org/pdf/2301.13688.pdf
在 Flan Collection 的论文中,google 也总结了 Flan 系列模型训练/推理中的一些关键点,可能会有不错的参考价值。

InstructDial
https://arxiv.org/pdf/2205.12673.pdf
https://github.com/prakharguptaz/Instructdial/tree/main/datasets
InstructDial 是在特定的一种任务类型上进行指令微调的尝试。实验结果表明,在对话指令数据上微调后,模型在对话任务上的表现强于在超大规模任务集上的结果。

Alpaca -Stanford
https://github.com/tatsu-lab/stanford_alpaca
Stanford release 的 Alpaca 是在 Meta Ai LLaMA 模型基础上进行 instruct-tuning 的微调模型。
Alpaca 使用 GPT-3.5 自动生成了 52k 的指令数据,并用其微调 LLaMA 模型。实验结果表明,其能够达到/甚至超过 GPT-3.5 在一些任务上的效果。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

