
- 1ubuntu use commandline download files_ubuntu command download
- 2如何设置手机的DNS_手机修改dns
- 3设计模式-04.模板方法模式_模板方法模式使用场景
- 4大数据技术原理与应用期末复习_大数据技术原理与应用期末考试试题
- 5《JavaScript高级程序设计 第三版》学习笔记 (十二)Ajax详解_javascript高级编程 ajax
- 6MongoDB——文档增删改查命令使用_mongodb 修改字段
- 7动态规划算法:路径问题_动态规划 路径规划
- 8基于javaweb jsp ssm电子竞技管理平台的设计与实现(源码+lw+部署文档+讲解等)
- 9用AI写自己的音乐_ai生成音乐,描述怎么写
- 10基于Java+Spring+Vue超市库存管理系统设计和实现_超市仓库管理系统vue
深度学习-Dropout详解_深度学习dropout
赞
踩
前言
Dropout是深度学习中被广泛的应用到解决模型过拟合问题的策略,相信你对Dropout的计算方式和工作原理已了如指掌。这篇文章将更深入的探讨Dropout背后的数学原理,通过理解Dropout的数学原理,我们可以推导出几个设置丢失率的小技巧,通过这篇文章你也将对Dropout的底层原理有更深刻的了解。同时我们也将对Dropout的几个改进进行探讨,主要是讨论它在CNN和RNN中的应用以及它的若干个经典的变种。
1、什么是Dropout
- 没有添加Dropout的网络是需要对网络的每一个节点进行学习的,而添加了Dropout之后的网络层只需要对该层中没有被Mask掉的节点进行训练,如图1所示。Dropout能够有效缓解模型的过拟合问题,从而使得训练更深更宽的网络成为可能。
下图中左侧是普通的两层MLP(多层感知机网络),右侧是添加了Dropout之后的网络结构
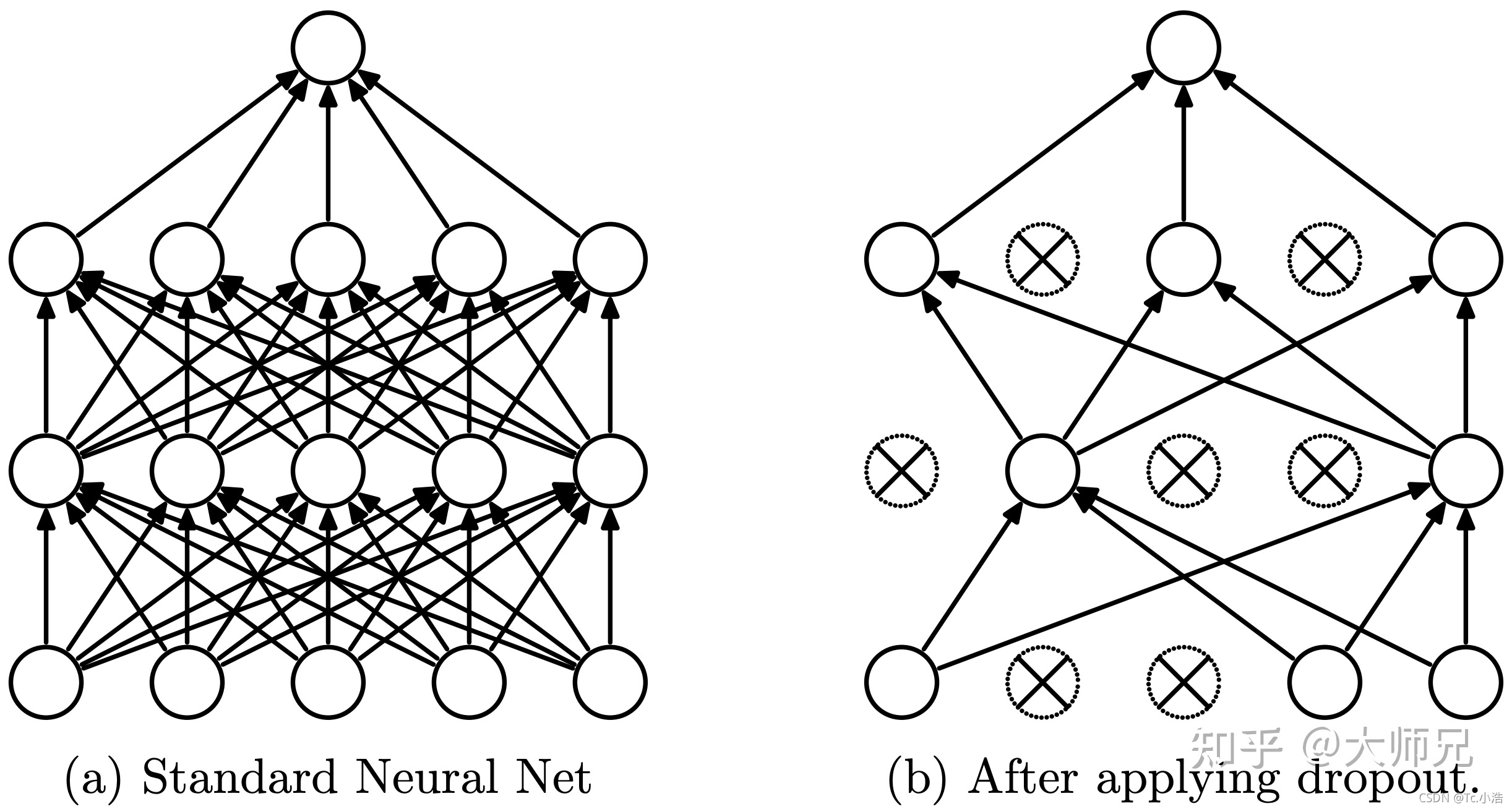
在Dropout之前,正则化是主要的用来缓解模型过拟合的策略,例如l1正则和l2正则。但是它们并没有完全解决模型的过拟合问题,原因就是网络中存在co-adaption(共适应)问题。所谓co-adaption,是指网络中的一些节点会比另外一些节点有更强的表征能力。这时,随着网络的不断训练,具有更强表征能力的节点被不断的强化,而更弱的节点则不断弱化直到对网络的贡献可以忽略不计。这时候只有网络中的部分节点才会被训练,浪费了网络的宽度和深度,进而导致模型的效果上升收到限制。而Dropout的提出解决了co-adaption问题,从而使得训练更宽的网络成为可能。
2、Dropout的数学原理
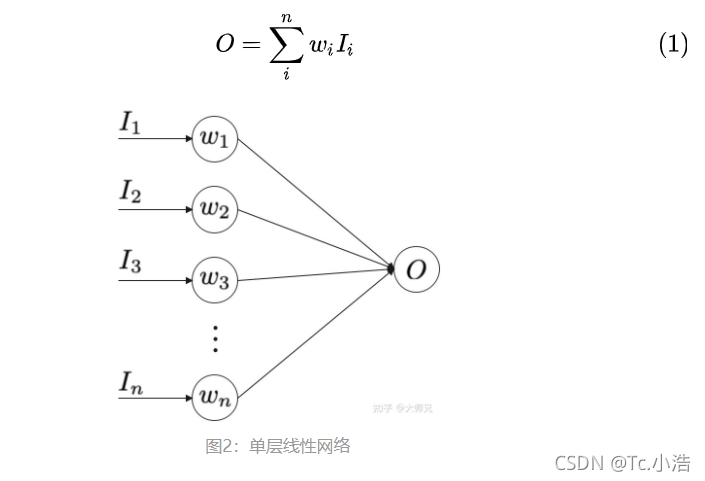
图2是一个线性的神经网络,它的输出是输入的加权和,表示为式(1)。这里我们只考虑最简单的线性激活函数,这个原理也适用于非线性的激活函数,只是推导起来更加复杂。
对于图2的无Dropout的网络,它的误差可以表示为式(2),其中
t
t
t 是目标值。
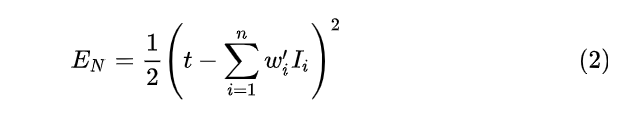
(2)式之所以使用
w
‘
w^`
w‘是为了找到之后要介绍的加入Dropout的网络的关系,其中
w
‘
=
p
w
w^`=pw
w‘=pw 。那么(2)可以表示为式(3)。
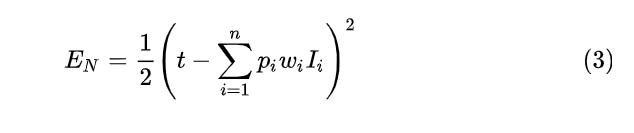
关于
w
i
w_i
wi的导数表示为(4)
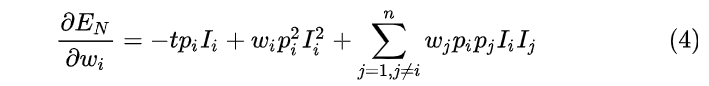
当我们向图2中添加Dropout之后,它的误差表示为式(5)。 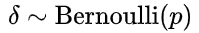
是丢失率,它服从伯努利分布,即它有
p
p
p的概率值为 1,
1
−
p
1-p
1−p 的概率值为0 。
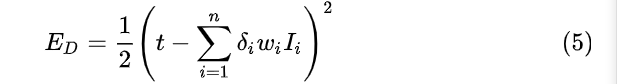
它关于
w
i
w_i
wi的导数表示为(6)
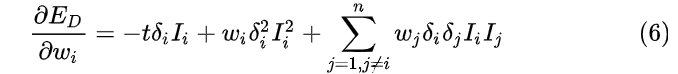

3、Dropout是一个正则网络
通过上面的分析我们知道最小化含有Dropout网络的损失等价于最小化带有正则项的普通网络,如式(8)。
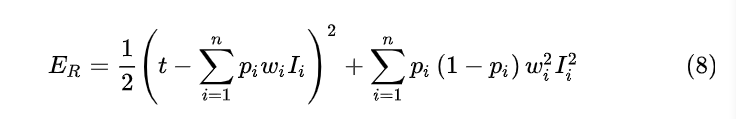
也就是说当我们对式(8)的
w
i
w_i
wi 进行求偏导,会得到(4)式的带有Dropout网络对
w
i
w_i
wi 的求偏导相同的结果。因此可以得到使用Dropout的几个技巧:
1.当丢失率为0.5 时,Dropout会有最强的正则化效果。因为 p(1-p)在 p=0.5时取得最大值。
2. 丢失率的选择策略:在比较深的网络中,使用 0.5的丢失率是比较好的选择,因为这时Dropout能取到最大的正则效果;在比较浅层的网络中,丢失率应该低于 0.2,因为过多的丢失率会导致丢失过多的输入数据对模型的影响比较大;不建议使用大于 0.5的丢失率,因为它在丢失过多节点的情况下并不会取得更好的正则效果。
3. 在测试时需要将使用丢失率对
w
w
w进行缩放:基于前面
w
‘
=
p
w
w^`=pw
w‘=pw的假设,我们得知无Dropout的网络的权值相当于对Dropout的网络权值缩放了 1-p倍。在含有Dropout的网络中,测试时不会丢弃节点,这相当于它是一个普通网络,因此也需要进行 1-p倍的缩放。

4、CNN的Dropout
不同于MLP的特征层是一个特征向量,CNN的Feature Map是一个由宽,高,通道数组成的三维矩阵。按照传统的Dropout的理论,它丢弃的应该是Feature Map上的若干个像素点,但是思想方法在CNN中并不是十分奏效的,一个重要的原因便是临近像素点之间的相似性。因为他们不仅在输入的值上非常接近,而且他们拥有相近的邻居,相似的感受野以及相同的卷积核。因此Dropout在CNN上也有很多优化。
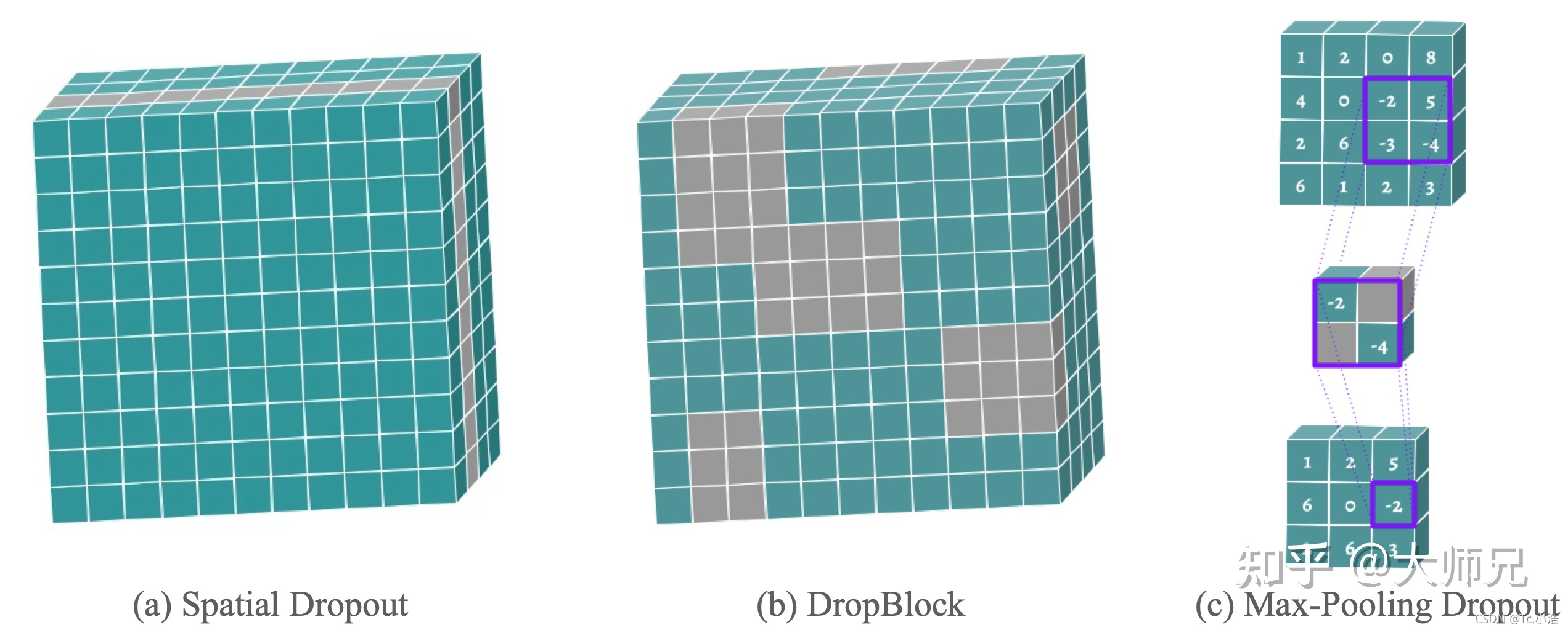
在CNN中,我们可以以通道为单位来随机丢弃,这样可以增加其它通道的建模能力并减轻通道之间的共适应问题,这个策略叫做Spatial Dropout [6]。我们也可以随机丢弃Feature Map中的一大块区域,来避免临近像素的互相补充,这个方法叫做DropBlock[7]。还有一个常见的策略叫做Max-pooling Dropout [8],它的计算方式是在执行Max-Pooling之前,将窗口内的像素进行随机mask,这样也使的窗口内较小的值也有机会影响后面网络的效果。Spatial Dropout,DropBlock和Max-Pooling Dropout的可视化如图3所示。
5、Dropout的变种
5.1 高斯Dropout
在传统的Dropout中,每个节点以 1-p的概率被mask掉。反应到式(5)中,它表示为使用权值乘以 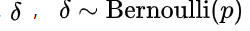
服从伯努利分布。式(5)相当于给每个权值一个伯努利的Gate,如图4所示。
Dropout可以看做给每个权值添加一个伯努利的gate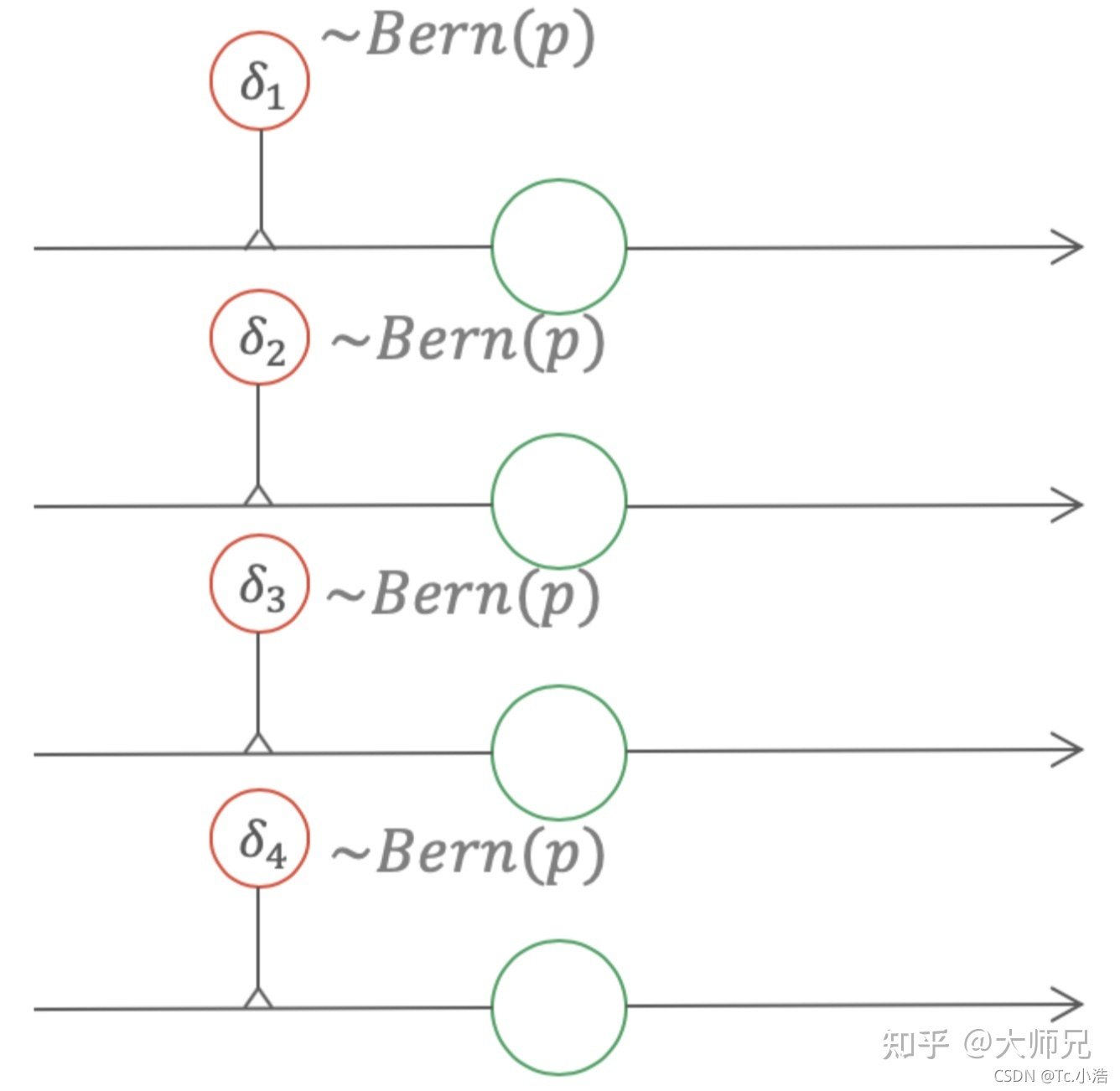
如果将图4中的伯努利gate换成高斯gate,那么此时得到的Dropout便是高斯Dropout,如图5所示。在很多场景中,高斯Dropout能够起到等价于甚至高于普通Dropout的效果。
高斯Dropout
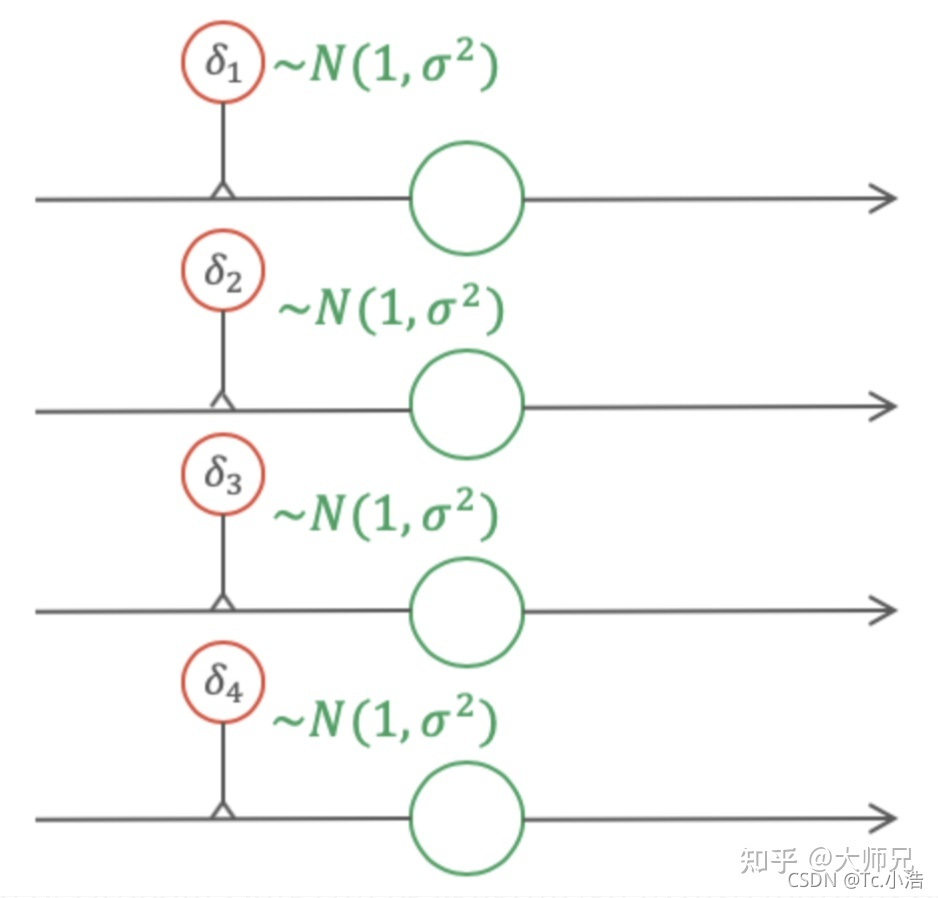
在使用高斯Dropout时,因为激活值保持不变,因此高斯Dropout在测试时不需要对权重进行缩放。因为在高斯Dropout中,所有节点都参与训练,这样对提升训练速度也有帮助。在高斯Dropout中,每个节点可以看做乘以了p(1-p) ,这相当于增熵,而Dropout丢弃节点的策略相当于减熵。在Srivastava等人的论文中,他们指出增熵是比减熵更好的策略,因此高斯Dropout会有更好的效果。
6、总结
在这篇文章中我们对Dropout背后的数学原理进行了深入的分析,从而得出了“Dropout是一个正则方法”的背后原理,通过对Dropout的数学分析,我们还得出了使用Dropout的几个技巧:
丢失率设置为 0.5时会取得最强的正则化效果;
不建议使用大于 0.5的丢失率。

