
- 1(IE浏览器)由于无法验证发布者,所以Windows已经阻止此软件_由于无法验证发布者,windows已阻止此软件怎么办
- 2说说Mysql的四种隔离级别_mysql隔离级别
- 3linux安装mysql8详细教程
- 4JavaScript青少年简明教程:数组
- 5蓝易云 - 在Kubernetes(k8s)环境中无法删除持久卷(PV)和持久卷声明(PVC)的解决方案
- 6Qt Creator 打开.ui文件卡死闪退_qt打开ui文件闪退
- 7《学姐教我写代码(一)》十道题搞定C语言_写代码有哪些题
- 8Matlab中用到的bsxfun函数_matlab boxfun
- 9weblogic_11g集群部署_linux_weblogic11g集群部署
- 10【Android】java.lajng.NoClassDefFoundError: Failed resolution of: Landroid/support/v4/content/LocalBro
关于Modbus TCP 编码及解码方式分析_modbus编码方式
赞
踩
一.Modbus TCP 基本概念
1.基本概念
①Coil和Register
Modbus中定义的两种数据类型。Coil是位(bit)变量;Register是整型(Word,即16-bit)变量。
②Slave和Master与Server和Client
同一种设备在不同领域的不同叫法。
Slave: 工业自动化用语;响应请求;
Master:工业自动化用语;发送请求;
Server:IT用语;响应请求;
Client:IT用语;发送请求;
在Modbus中,Slave和Server意思相同,Master和Client意思相同。
2.Modbus数据模型
Modbus中,数据可以分为两大类,分别为Coil和Register,每一种数据,根据读写方式的不同,又可细分为两种(只读,读写)。
Modbus四种数据类型:
Discretes Input 位变量 只读
Coils 位变量 读写
Input Registers 16-bit整型 只读
Holding Registers 16-bit整型 读写
通常,在Slave端中,定义四张表来实现四种数据。
3.Modbus地址范围对应表
设备地址 Modbus地址 描述 功能 R/W
1~10000 address-1 Coils(Output) 0 R/W
10001~20000 address-10001 Discrete Inputs 01 R
30001~40000 address-30001 Input Registers 04 R
40001~50000 address-40001 Holding Registers 03 R/W
4.Modbus变量地址
映射地址 Function Code 地址类型 R/W 描述
0xxxx 01,05,15 Coil R/W -
1xxxx 02 离散输入 R -
2xxxx 03,04,06,16 浮点寄存器 R/W 两个连续16-bit寄存器表示一个浮点数(IEEE754)
3xxxx 04 输入寄存器 R 每个寄存器表示一个16-bit无符号整数(0~65535)
4xxxx 03,06,16 保持寄存器 R/W -
5xxxx 03,04,06,16 ASCII字符 R/W 每个寄存器表示两个ASCII字符
二.Modbus TCP 大小端概念
国内设备基本上是A B C D顺序,国外设备基本上是B A D C顺序。低位优先字节交换。使用两个寄存器。
使用IEEE 754规范,如显示不正常可进行 字节顺序 交换位置即可。如下:
Float Big-endian 字节顺序:A B C D
Float Little-endian 字节顺序:D C B A
Float Big-endian byte swap 字节顺序:B A D C
Float Little-endian byte swap 字节顺序:C D A B
举个栗子:41 8C E8 EE
字节顺序: A B C D
A B C D
B A D C
A B C D
B A D C
三.Modbus TCP 中常用编码解码方式
在本案例中,Proface 设备使用编码方式为 GB18030, 可以传输字符与汉字。
GB18030 与 Unicode
GB18030 和 Unicode 相当于两套单独的编码体系,它们都对世界上大部分字符进行编码,赋予每个字符一个唯一的编号,只不过对于同一个字符,GB18030 和 Unicode 对应的编号是不一样的, 比如:汉字 "中" 字的 GB18030 编码是 0xD6D0, 对应的 Unicode 码元是 0x4E2D, 从这一点上可以认为 GB18030 是一种 Unicode 的转换格式
注意:要表达 Unicode 的编码格式才真正算得上 Unicode 转换格式,所以严格意义上说 GB18030 并不是真正的 Unicode 转换格式
GB18030 既是字符集又是编码格式,也即字符在字符集中的编号以及存储是进行编码用的编号是完全相同的,而 Unicode 仅仅是字符集,它只规定了字符的唯一编号,它的存储是用其他的编码格式的,比如 UTF8、UTF16 等等
既然 GB18030 和 Unicode 都能表示世界上大部分字符,为什么要弄两套字符集呢,一套的话不更有利于信息的传播吗?
1、在 Unicode 出现之前,没有统一的字符编码,每个操作系统上都有自己的一套编码标准,像早期的 window 上需要安装字符集,才能支持中文,这里的字符集就是微软自定的标准,换个其他系统就会失效
2、对于大部分中文字符来说,采用 GB18030 编码的话,只需两个字节,如果采用 UTF8 编码,就需要三个字节, 所以用 GB18030 存储和传输更节省空间
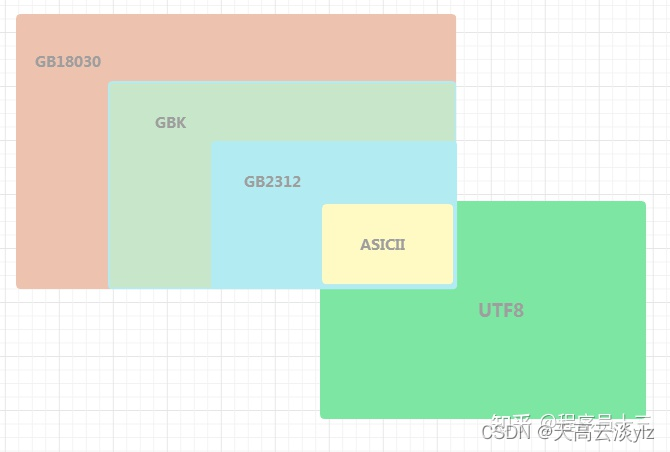
【转】彻底搞明白 GB2312、GBK 、GB18030和UTF-8-CSDN博客


编码解码网站:
三.解析案例
3.1源word array数组
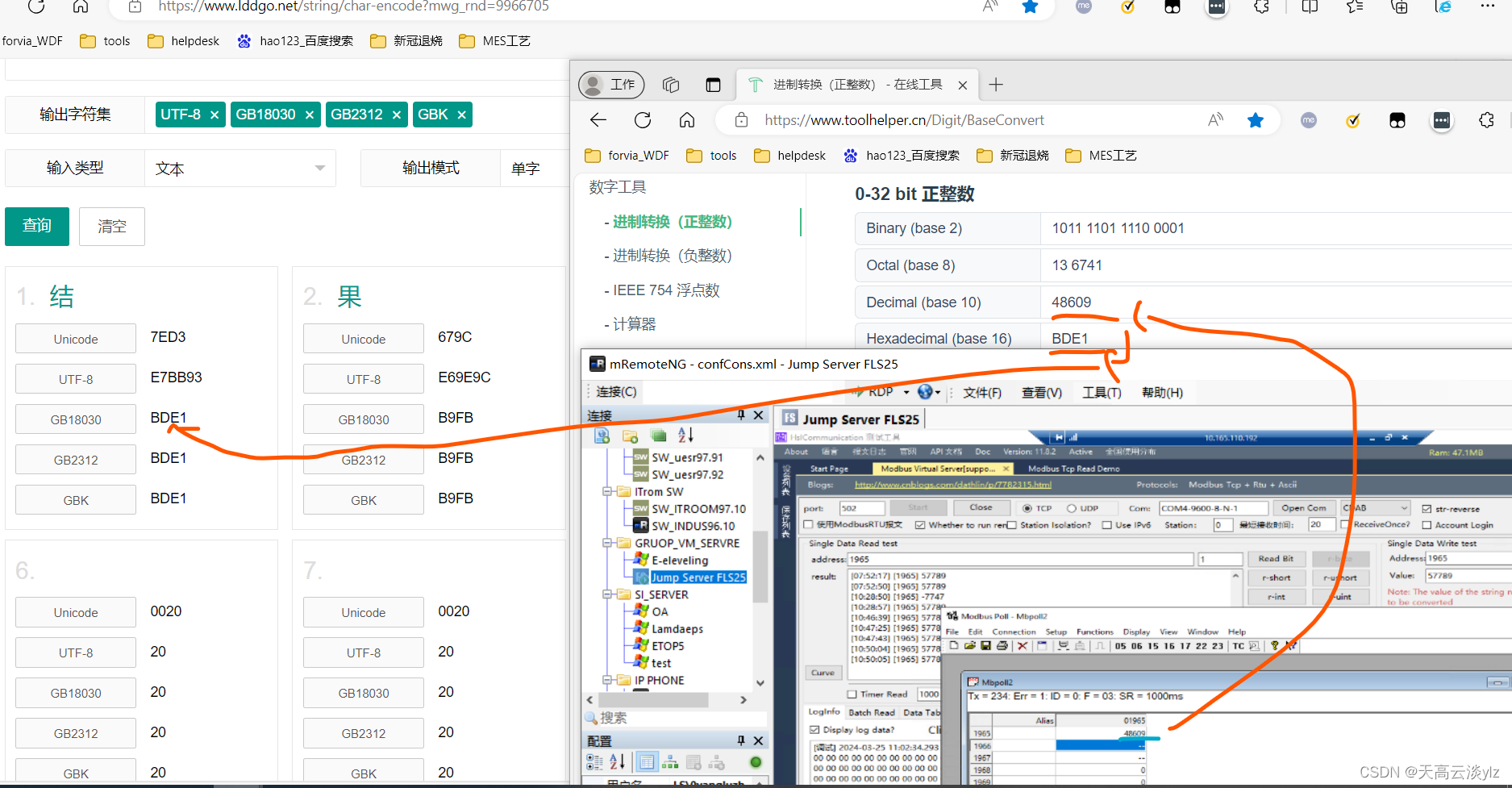
[57789,64441,20302,8267,8224,8224,8224,8224,8224,8224,21315,17952,16716,18765,18254,21536,13111,22319,12082,22612]

3.2 源word Aarry 对应中文描述
结果NOK CS FLAMING TL73/W2/TX
注意中间有空格,空格对应十进制为8224
3.3 利用网络编码解码工具进行解析
字符是先编码成二进制,然后再调大小端, 以上是发送端编码,接收端为逆序解码
3.3 利用AI 工具帮忙解析
提示词“ kepserver 使用Modbus-tcp 协议,作为Master 端,收到数据为word array 数据类型,其中数组第一个word 十进制值为“57789”,根据application显示对比,确定“57789” 对应的就是汉字“结”,请根据以上对应关系,推断出编码方式和大小端使用方式,详细点谢谢!”
Claude+ 免费在线 - 无需登录 - 立即聊天! |
人工智能 (hix.ai)
其实,AI做黑盒分析还是很难,至少免费的AI工具不行,需要多多训练。

