
- 1国内常用NTP服务器地址及IP_ntp服务器ip地址
- 2系统集成项目管理工程师(软考中级)—— 第十章 项目立项管理 笔记分享
- 32024年华为OD机试真题-二叉树的广度优先遍历-Java-OD统一考试(C卷)
- 4Python接口自动化测试实战系列
- 5本科应届生22K拿下字节跳动和顺丰offer,看看你都会吗?_顺丰科技后台java应届生白菜价
- 6启用dell服务器的iDRAC_dell服务器配置idrac ip地址
- 7什么是零代码开发平台?它有哪些功能模块—白码_0代码开发平台后期可以汇总数据吗
- 8算法巩固——旅行商问题
- 9超好用资源分享-VMware Workstation Pro 17.5.2(最新版)包含下载及安装教程_vmware下载哪个版本
- 102024年8月HarmonyOS鸿蒙应用开发者高级认证全新题库_鸿蒙认证考试
Rabin-Karp算法详解:高效字符串匹配的实现与优化
赞
踩
本文收录于专栏:算法之翼
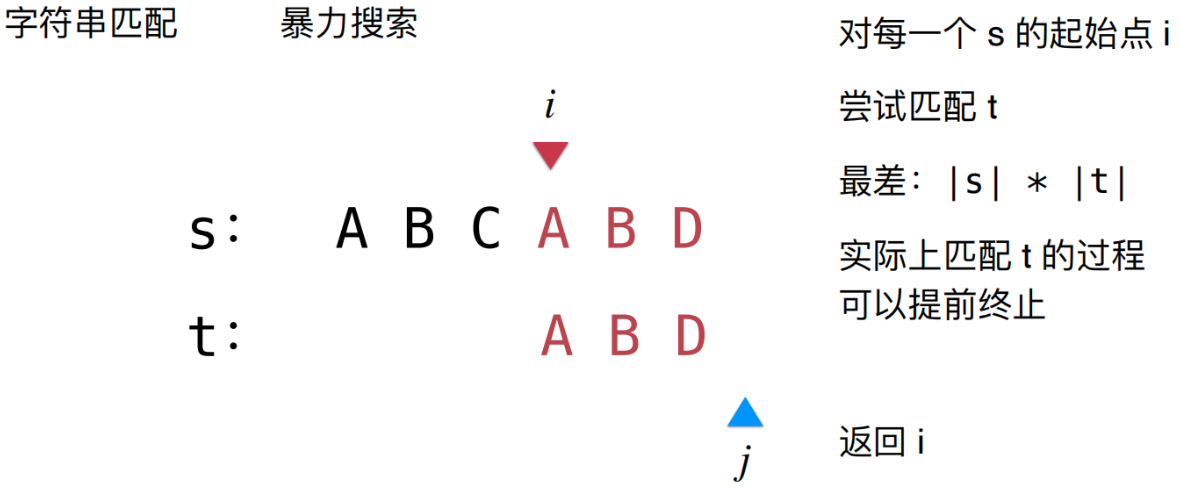
字符串匹配是计算机科学中的一个重要问题,在许多应用中都非常关键,例如文本编辑器中的搜索功能、基因序列分析、网络入侵检测等。本文将介绍一种高效的字符串匹配算法——Rabin-Karp算法,详细讨论其实现原理,并提供代码实例。同时,还将探讨一些优化技巧以提高其性能。
Rabin-Karp算法简介
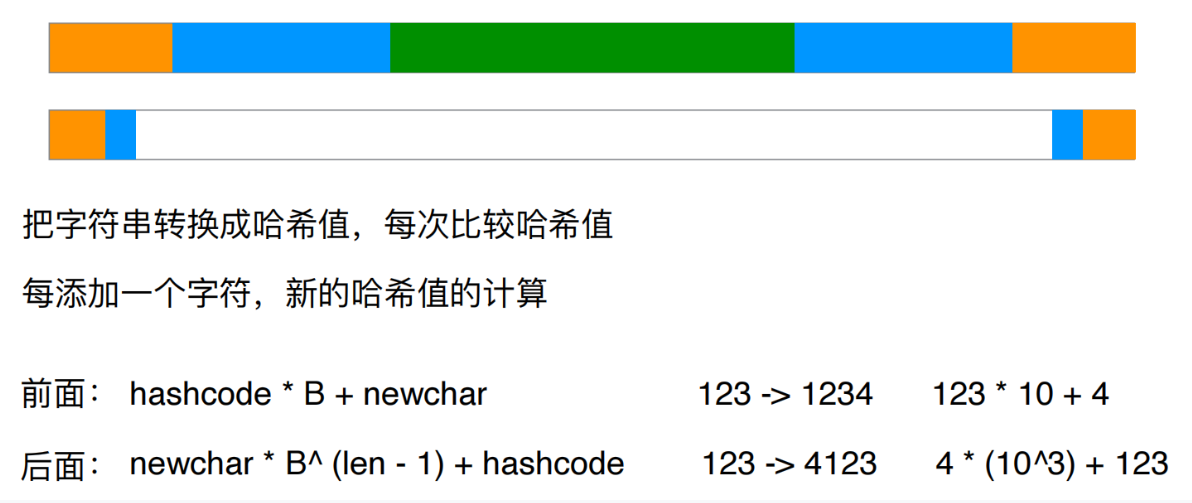
Rabin-Karp算法是一种基于哈希的字符串匹配算法。其基本思想是将模式字符串和文本中的每个子字符串都转换为哈希值,然后比较这些哈希值,而不是直接比较字符串本身。这种方法在平均情况下可以显著提高匹配效率。
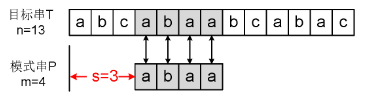
算法步骤
- 计算模式字符串的哈希值。
- 计算文本中与模式字符串长度相同的第一个子字符串的哈希值。
- 比较两个哈希值,如果相同,则进一步比较实际字符串(以避免哈希碰撞)。
- 滑动窗口:移动一个字符,更新子字符串的哈希值。
- 重复步骤3和4,直到找到匹配或遍历完整个文本。
哈希函数
Rabin-Karp算法通常使用滚动哈希技术来快速计算新子字符串的哈希值。常用的哈希函数形式如下:
[ \text{hash}(s) = (s_0 \cdot p^{m-1} + s_1 \cdot p^{m-2} + \cdots + s_{m-1} \cdot p^0) \mod q ]
其中,( p ) 是一个选定的质数,( q ) 是一个大素数以避免哈希碰撞,( m ) 是模式字符串的长度,( s_i ) 是字符串中的字符。
Rabin-Karp算法的实现
以下是Rabin-Karp算法的Python实现:
def rabin_karp(text, pattern): d = 256 # 字符集的大小(假设所有字符在ASCII范围内) q = 101 # 一个大素数,用于计算哈希值 m = len(pattern) n = len(text) p_hash = 0 # 模式字符串的哈希值 t_hash = 0 # 当前文本子字符串的哈希值 h = 1 # 计算 h = d^(m-1) % q for _ in range(m-1): h = (h * d) % q # 计算模式字符串和文本第一个子字符串的哈希值 for i in range(m): p_hash = (d * p_hash + ord(pattern[i])) % q t_hash = (d * t_hash + ord(text[i])) % q # 滑动窗口进行字符串匹配 for i in range(n - m + 1): # 如果哈希值相同,进一步检查实际字符串 if p_hash == t_hash: if text[i:i + m] == pattern: print(f"Pattern found at index {i}") # 计算下一个子字符串的哈希值 if i < n - m: t_hash = (d * (t_hash - ord(text[i]) * h) + ord(text[i + m])) % q if t_hash < 0: t_hash += q # 示例用法 text = "GEEKS FOR GEEKS" pattern = "GEEK" rabin_karp(text, pattern)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
优化技巧
选择合适的质数
选择合适的质数 ( p ) 和 ( q ) 是提高Rabin-Karp算法性能的关键。一般情况下,选择质数可以减少哈希碰撞的概率,从而提高算法的效率。
滚动哈希优化
滚动哈希是Rabin-Karp算法的核心,通过利用上一个子字符串的哈希值来计算下一个子字符串的哈希值,可以显著减少计算量。进一步优化可以使用更高效的哈希函数,或者在特定应用中使用自定义的哈希函数。
多模式匹配
在一些应用中,可能需要匹配多个模式字符串。此时,可以将所有模式字符串的哈希值存储在一个哈希表中,然后对文本中的子字符串计算哈希值并在哈希表中查找匹配。这种方法在处理多个模式字符串时效率更高。
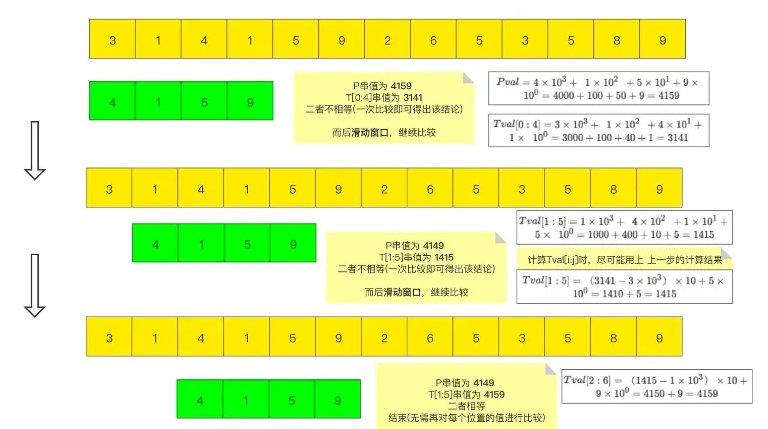
性能分析
Rabin-Karp算法的时间复杂度分析如下:
- 预处理阶段:计算模式字符串和文本第一个子字符串的哈希值,这一步需要 (O(m)) 时间,其中 (m) 是模式字符串的长度。
- 匹配阶段:在最坏情况下,所有的子字符串哈希值都需要计算和比较,总共需要 (O((n-m+1)m)) 时间,其中 (n) 是文本的长度。
不过,Rabin-Karp算法在平均情况下表现良好,时间复杂度接近 (O(n)),因为哈希碰撞的概率很低,实际字符串比较很少发生。
实际应用
Rabin-Karp算法适用于以下几种场景:
- 文本编辑器:用于实现高效的查找和替换功能。
- 网络安全:用于检测入侵和恶意软件,快速匹配已知的恶意模式。
- 基因序列分析:在生物信息学中用于快速匹配和比对DNA序列。
更高级的优化
1. 处理大文本
对于非常大的文本,Rabin-Karp算法的性能可能受到哈希碰撞的影响。可以采用以下方法进一步优化:
- 分块处理:将大文本分成若干块,分别计算哈希值,然后在每一块内使用Rabin-Karp算法进行匹配。
- 并行处理:利用多线程或分布式计算,将文本划分为多个部分并行处理,可以显著提高匹配效率。
2. 选择更好的哈希函数
虽然Rabin-Karp算法常用的哈希函数已经比较高效,但在特定应用中,选择更好的哈希函数可以进一步减少哈希碰撞。例如,可以使用更复杂的哈希函数,如SHA-1或MD5,但需要权衡计算复杂性和匹配效率。
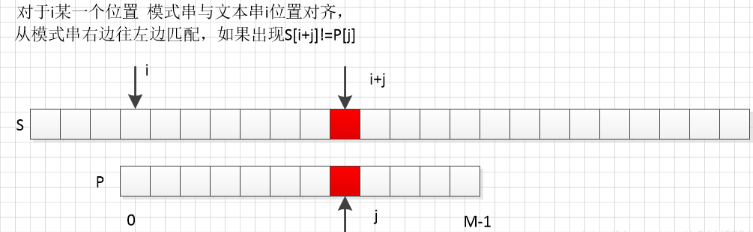
更复杂的匹配需求
对于一些更复杂的字符串匹配需求,如正则表达式匹配或模糊匹配,可以结合Rabin-Karp算法与其他算法,如KMP(Knuth-Morris-Pratt)算法或Boyer-Moore算法,以提高匹配效率。
Python代码优化
以下是对Rabin-Karp算法的进一步优化代码示例:
def optimized_rabin_karp(text, pattern): d = 256 # 字符集大小 q = 101 # 一个大素数 m = len(pattern) n = len(text) p_hash = 0 # 模式字符串的哈希值 t_hash = 0 # 当前文本子字符串的哈希值 h = 1 # 计算 h = d^(m-1) % q for _ in range(m - 1): h = (h * d) % q # 计算模式字符串和文本第一个子字符串的哈希值 for i in range(m): p_hash = (d * p_hash + ord(pattern[i])) % q t_hash = (d * t_hash + ord(text[i])) % q # 滑动窗口进行字符串匹配 for i in range(n - m + 1): # 如果哈希值相同,进一步检查实际字符串 if p_hash == t_hash: if text[i:i + m] == pattern: print(f"Pattern found at index {i}") # 计算下一个子字符串的哈希值 if i < n - m: t_hash = (d * (t_hash - ord(text[i]) * h) + ord(text[i + m])) % q if t_hash < 0: t_hash += q # 示例用法 text = "THIS IS A TEST TEXT" pattern = "TEST" optimized_rabin_karp(text, pattern)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
实际应用案例
为了更好地理解Rabin-Karp算法的实际应用,下面将展示几个应用案例。
1. 文本编辑器中的查找与替换
在文本编辑器中,用户经常需要查找并替换特定的字符串。Rabin-Karp算法可以快速找到所有匹配的位置,然后进行替换。
def rabin_karp_replace(text, pattern, replacement): d = 256 q = 101 m = len(pattern) n = len(text) p_hash = 0 t_hash = 0 h = 1 result = list(text) for _ in range(m - 1): h = (h * d) % q for i in range(m): p_hash = (d * p_hash + ord(pattern[i])) % q t_hash = (d * t_hash + ord(text[i])) % q for i in range(n - m + 1): if p_hash == t_hash: if text[i:i + m] == pattern: result[i:i + m] = replacement if i < n - m: t_hash = (d * (t_hash - ord(text[i]) * h) + ord(text[i + m])) % q if t_hash < 0: t_hash += q return ''.join(result) # 示例用法 text = "GEEKS FOR GEEKS" pattern = "GEEKS" replacement = "NERDS" new_text = rabin_karp_replace(text, pattern, replacement) print(new_text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
2. 网络安全中的入侵检测
在网络安全中,入侵检测系统需要快速匹配已知的恶意模式,以检测和阻止攻击。Rabin-Karp算法可以有效地处理这种情况。
def rabin_karp_network_security(logs, patterns): d = 256 q = 101 matches = [] for pattern in patterns: m = len(pattern) p_hash = 0 for i in range(m): p_hash = (d * p_hash + ord(pattern[i])) % q for log in logs: n = len(log) t_hash = 0 for i in range(m): t_hash = (d * t_hash + ord(log[i])) % q for i in range(n - m + 1): if p_hash == t_hash: if log[i:i + m] == pattern: matches.append((log, i, pattern)) if i < n - m: t_hash = (d * (t_hash - ord(log[i]) * h) + ord(log[i + m])) % q if t_hash < 0: t_hash += q return matches # 示例用法 logs = [ "192.168.1.1 - MaliciousActivityDetected - ExploitAttempt", "192.168.1.2 - NormalActivity", "192.168.1.3 - MaliciousActivityDetected - DataExfiltration" ] patterns = ["MaliciousActivityDetected", "ExploitAttempt", "DataExfiltration"] matches = rabin_karp_network_security(logs, patterns) for match in matches: print(f"Pattern '{match[2]}' found in log: '{match[0]}' at index {match[1]}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
3. 基因序列分析
在生物信息学中,基因序列分析需要快速匹配和比对DNA序列。Rabin-Karp算法可以高效处理这种任务。
def rabin_karp_dna_search(dna_sequence, pattern): d = 4 # DNA序列只有A, C, G, T四种碱基 q = 101 m = len(pattern) n = len(dna_sequence) p_hash = 0 t_hash = 0 h = 1 for _ in range(m - 1): h = (h * d) % q for i in range(m): p_hash = (d * p_hash + ord(pattern[i])) % q t_hash = (d * t_hash + ord(dna_sequence[i])) % q for i in range(n - m + 1): if p_hash == t_hash: if dna_sequence[i:i + m] == pattern: print(f"Pattern found at index {i}") if i < n - m: t_hash = (d * (t_hash - ord(dna_sequence[i]) * h) + ord(dna_sequence[i + m])) % q if t_hash < 0: t_hash += q # 示例用法 dna_sequence = "AGCTTAGCTAGCTTACGTA" pattern = "AGCTT" rabin_karp_dna_search(dna_sequence, pattern)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
Rabin-Karp算法的改进方向
尽管Rabin-Karp算法在许多应用场景中表现优异,但仍有改进空间。以下是一些潜在的改进方向:
1. 多模式匹配的优化
在某些情况下,我们需要在文本中同时匹配多个模式字符串。可以对Rabin-Karp算法进行扩展,使其能够处理多模式匹配的问题。这种方法称为多模式Rabin-Karp算法。
实现多模式匹配的一种方法是将所有模式字符串的哈希值存储在一个哈希表中,然后对文本中的子字符串计算哈希值并在哈希表中查找匹配。
def rabin_karp_multi_pattern(text, patterns): d = 256 q = 101 n = len(text) h = 1 m = len(patterns[0]) # 假设所有模式字符串长度相同 pattern_hashes = {} results = {} # 计算 h = d^(m-1) % q for _ in range(m - 1): h = (h * d) % q # 计算所有模式字符串的哈希值 for pattern in patterns: p_hash = 0 for char in pattern: p_hash = (d * p_hash + ord(char)) % q pattern_hashes[pattern] = p_hash results[pattern] = [] # 计算文本中第一个子字符串的哈希值 t_hash = 0 for i in range(m): t_hash = (d * t_hash + ord(text[i])) % q # 滑动窗口进行字符串匹配 for i in range(n - m + 1): if t_hash in pattern_hashes.values(): for pattern in patterns: if pattern_hashes[pattern] == t_hash: if text[i:i + m] == pattern: results[pattern].append(i) if i < n - m: t_hash = (d * (t_hash - ord(text[i]) * h) + ord(text[i + m])) % q if t_hash < 0: t_hash += q return results # 示例用法 text = "AABAACAADAABAAABAA" patterns = ["AABA", "BAA", "CAADA"] matches = rabin_karp_multi_pattern(text, patterns) for pattern, indices in matches.items(): print(f"Pattern '{pattern}' found at indices: {indices}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
2. 处理模糊匹配
在某些应用中,允许一定程度的错误匹配(如DNA序列比对中的突变和缺失)。可以将Rabin-Karp算法与模糊匹配技术结合,实现容错字符串匹配。
一种方法是使用动态规划算法(如Levenshtein距离)结合Rabin-Karp算法,在发现哈希值匹配时,通过动态规划算法验证实际字符串的相似度。
def levenshtein_distance(s1, s2): if len(s1) < len(s2): return levenshtein_distance(s2, s1) if len(s2) == 0: return len(s1) previous_row = range(len(s2) + 1) for i, c1 in enumerate(s1): current_row = [i + 1] for j, c2 in enumerate(s2): insertions = previous_row[j + 1] + 1 deletions = current_row[j] + 1 substitutions = previous_row[j] + (c1 != c2) current_row.append(min(insertions, deletions, substitutions)) previous_row = current_row return previous_row[-1] def rabin_karp_fuzzy(text, pattern, max_distance): d = 256 q = 101 m = len(pattern) n = len(text) p_hash = 0 t_hash = 0 h = 1 for _ in range(m - 1): h = (h * d) % q for i in range(m): p_hash = (d * p_hash + ord(pattern[i])) % q t_hash = (d * t_hash + ord(text[i])) % q matches = [] for i in range(n - m + 1): if p_hash == t_hash: if levenshtein_distance(text[i:i + m], pattern) <= max_distance: matches.append(i) if i < n - m: t_hash = (d * (t_hash - ord(text[i]) * h) + ord(text[i + m])) % q if t_hash < 0: t_hash += q return matches # 示例用法 text = "GEEKS FOR GEEKS" pattern = "GEEK" max_distance = 1 matches = rabin_karp_fuzzy(text, pattern, max_distance) print(f"Pattern '{pattern}' found at indices (with max distance {max_distance}): {matches}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
3. 并行处理
利用多核处理器的并行计算能力,可以将文本划分为多个部分,并行计算每个部分的哈希值和匹配结果,从而显著提高Rabin-Karp算法的执行速度。
from multiprocessing import Pool def rabin_karp_parallel_worker(args): text, pattern, start, end = args d = 256 q = 101 m = len(pattern) p_hash = 0 t_hash = 0 h = 1 for _ in range(m - 1): h = (h * d) % q for i in range(m): p_hash = (d * p_hash + ord(pattern[i])) % q t_hash = (d * t_hash + ord(text[start + i])) % q matches = [] for i in range(start, end - m + 1): if p_hash == t_hash: if text[i:i + m] == pattern: matches.append(i) if i < end - m: t_hash = (d * (t_hash - ord(text[i]) * h) + ord(text[i + m])) % q if t_hash < 0: t_hash += q return matches def rabin_karp_parallel(text, pattern, num_processes=4): chunk_size = len(text) // num_processes args = [(text, pattern, i * chunk_size, (i + 1) * chunk_size) for i in range(num_processes)] args[-1] = (text, pattern, (num_processes - 1) * chunk_size, len(text)) with Pool(num_processes) as pool: results = pool.map(rabin_karp_parallel_worker, args) return [match for sublist in results for match in sublist] # 示例用法 text = "AABAACAADAABAABA" pattern = "AABA" matches = rabin_karp_parallel(text, pattern) print(f"Pattern '{pattern}' found at indices: {matches}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
未来发展趋势
随着计算技术和数据处理需求的不断发展,字符串匹配算法将继续朝着高效、鲁棒和智能的方向发展。以下是一些可能的发展趋势:
- 智能化匹配:结合人工智能和机器学习技术,开发能够自动适应不同应用场景的字符串匹配算法,提高匹配的准确性和效率。
- 大数据处理:面对海量数据,开发分布式和并行化的字符串匹配算法,以应对大数据处理的挑战。
- 多模态数据匹配:处理不仅限于文本的多模态数据(如图像、音频等)的匹配需求,开发更通用的匹配算法。
希望通过本文的详细介绍和代码示例,您对Rabin-Karp算法有了更深入的理解,并能在实际应用中加以利用和优化。如果您有任何问题或建议,欢迎交流讨论。
总结
Rabin-Karp算法是一种高效的字符串匹配算法,特别适用于需要快速匹配的大规模文本数据。其核心思想是使用哈希技术将模式字符串和文本中的子字符串转换为哈希值,通过比较哈希值来快速定位匹配位置。本文详细介绍了Rabin-Karp算法的原理、实现及其优化方法,并提供了实际应用案例。
-
算法原理:
- Rabin-Karp算法通过计算模式字符串和文本子字符串的哈希值来实现字符串匹配。
- 使用滚动哈希技术快速更新子字符串的哈希值,提高匹配效率。
-
算法实现:
- 提供了Rabin-Karp算法的基本实现,包括哈希值计算和滑动窗口技术。
- 演示了如何在Python中实现该算法,并进行了详细的代码讲解。
-
优化技巧:
- 选择合适的质数来减少哈希碰撞。
- 使用多模式匹配和模糊匹配技术扩展算法功能。
- 利用并行处理技术提高算法的执行速度。
-
实际应用案例:
- 文本编辑器中的查找与替换:快速查找并替换特定字符串。
- 网络安全中的入侵检测:检测已知的恶意模式,保护系统安全。
- 基因序列分析:快速匹配和比对DNA序列。
-
改进方向与发展趋势:
- 多模式匹配的优化:同时匹配多个模式字符串。
- 处理模糊匹配:允许一定程度的错误匹配,提高匹配容错性。
- 并行处理:利用多核处理器的并行计算能力,提高算法执行速度。
- 智能化匹配:结合人工智能和机器学习技术,开发适应不同应用场景的匹配算法。
- 大数据处理:开发分布式和并行化的字符串匹配算法,处理海量数据。
- 多模态数据匹配:处理包括图像、音频等多模态数据的匹配需求,开发更通用的匹配算法。
通过本文的介绍,读者可以深入理解Rabin-Karp算法的原理和实现,并掌握一些优化技巧和应用案例。这些知识可以帮助解决实际应用中的字符串匹配问题,提高工作效率和解决问题的能力。希望本文对您理解和应用Rabin-Karp算法有所帮助,如果有任何问题或建议,欢迎交流讨论。

