
- 1大数据技术之Hive(一)_大数据hive技术
- 2软件工程导论_软件工程导论目录
- 3android studio自定义文件头的两种方式_android studio file head
- 4PyTorch实战6:好莱坞明星识别--VGG16_pytorch vgg16 参数设置
- 5Mysql中concat()和concat_ws() 的用法
- 6前端面试题之浏览器_前端面试浏览器
- 7Python应用开发——30天学习Streamlit Python包进行APP的构建(1)_python 安装streamlit
- 8基于OMAPL138的Linux字符驱动_GPIO驱动AD9833(一)之miscdevice和ioctl_omapl138 vpif linux驱动程序
- 9mysql分组时取日期最新的一条数据_一批数据分组打标识只保留日期最新的数据
- 10接口测试面试题汇总(含答案)
【LLM大模型】只需三步,本地打造自己的AI大模型个人专属知识库_ai大模型自建数据库
赞
踩
一、引言
本文会手把手教你如何部署本地大模型以及搭建个人知识库,使用到的工具和软件有:
- Ollama
- Open WebUI
- Docker
- AnythingLLM
本文主要分享三点
- 如何用Ollama在本地运行大模型
- 使用现代Web UI和本地大模型"聊天"
- 如何打造完全本地化的知识库:Local RAG
读完本文,你会学习到
- 如何使用最好用的软件Ollama部署本地大模型
- 通过搭建本地的聊天软件,了解ChatGPT的信息是如何流转的
- RAG的概念以及所用到的一些核心技术
- 如何通过AnythingLLM这款软件搭建完全本地化的数据库
二、ollama的安装以及大模型下载
2.1 安装ollama
官方下载地址:ollama.com/download
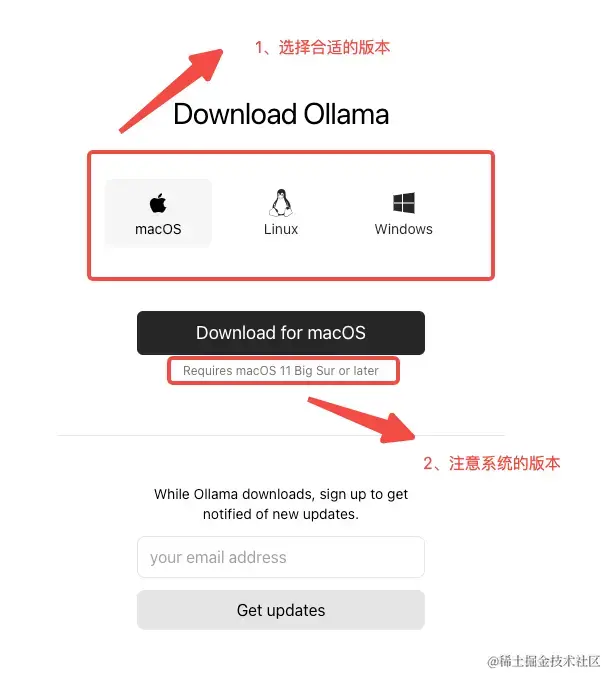

当安ollama之后,我们可以通过访问如下链接来判断ollama是否安装成功
arduino
复制代码
http://127.0.0.1:11434/
- 1
- 2
- 3

2.2 使用ollama运行本地大模型
当安装完成ollama之后,我们就可以在命令行中运行如下命令既可以
arduino
复制代码
ollama run [model name]
- 1
- 2
- 3
其中[model name]就是你想运行的本地大模型的名称,如果你不知道应该选择哪个模型,可以通过model library进行查看。这里我们选择llama2大模型:llama2
考虑到我机器的配置以及不同版本的内存要求,我这里选择7b参数的模型



当我们运行大模型的时候,ollama会自动帮我们下载大模型到我们本地。

三、通过Open WebUI使用大模型
在默认的情况下,我们需要在终端中跟大模型进行交互,但是这种方法太古老了。就跟我们基本不会使用终端命令跟Mysql打交道,而是使用Navcat等客户端和Mysql进行交互。大模型也有其交互客户端,这就是Open WebUI
3.1 安装Open WebUI
Open WebUI是github上的一个开源项目,这里我们参考其官方文档进行下载和安装。
- 在安装之前,我们需要先安装Docker,安装说明如下:
-
如果是Win或者Mac系统,参考文档:Docker Desktop release notes:
- 注意:要下载跟自己的电脑系统适配的版本
- 例如目前的最新版本的Docker仅支持Mac OS12.0以后的系统
-
如果Linux系统,请自己上网找教程(日常都可以使用Linux系统了,安装Docker小Case!)
- 在官方文档中我们会看到两种安装Open WebUI的方式:
- ollama和open webui一起安装
- 仅仅安装open webui
由于我们已经安装了ollama,因此我们只需要安装open webui即可,复制如下命令:
kotlin
复制代码
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
- 1
- 2
- 3

当Open WebUI安装下载完成之后,我们就可以愉快的玩耍啦!
3.2 使用Open WebUI
- 首先访问如下网址
bash
复制代码
http://localhost:3000/auth/
- 1
- 2
- 3
当你打开这个页面的时候,会让你登陆,这个时候我们随便使用一个邮箱注册一个账号即可

- 和本地大模型进行对话
登陆成功之后,如果你已经使用过ChatGPT等类似的大模型对话网站,我相信你对这个页面并不陌生。
Open WebUI一般有两种使用方式
- 第一种是聊天对话

- 第二种是RAG能力,也就是可以让模型根据文档内容来回答问题。这种能力就是构建知识库的基础之一

如果你的要求不高的话,我们已经搭建了一个本地大模型了,并且通过Web UI实现了和大模型进行对话的功能。
相信通过这么一通折腾,你就理解了ChatGPT的信息流,至于为什么ChatGPT的访问速度比我们自己的要快,而且回答效果要好,就两个原因
- 快:是因为GPT大模型部署的服务器配置高
- 好:是因为GPT大模型的训练参数多,数据更优以及训练算法更好
如果你想要更加灵活的掌握你的知识库,请接着往下看
四、RAG是什么
在进行本地知识库的搭建实操之前,我们需要先对RAG有一个大概的了解。
因为利用 大模型 的能力搭建知识库本身就是一个RAG技术的应用。
以下内容会有些干,我会尽量用通俗易懂的描述进行讲解。
我们都知道大模型的训练数据是有截止日期的,那当我们需要依靠不包含在大模型训练集中的数据时,我们该怎么做呢?实现这一点的主要方法就是通过检索增强生成RAG(Retrieval Augmented Generation)。在这个过程中,首先检索外部数据,然后在生成步骤中将这些数据传递给LLM。
我们可以将一个RAG的应用抽象为下图的5个过程:

-
文档加载(Document Loading) :从多种不同来源加载文档。LangChain提供了100多种不同的文档加载器,包括PDF在内的非结构化的数据、SQL在内的结构化的数据,以及Python、Java之类的代码等
-
文本分割(Splitting) :文本分割器把Documents 切分为指定大小的块,我把它们称为“文档块”或者“文档片”
-
存储(Storage): 存储涉及到两个环节,分别是:
- 将切分好的文档块进行嵌入(Embedding)转换成向量的形式
- 将Embedding后的向量数据存储到向量数据库
-
检索(Retrieval) :一旦数据进入向量数据库,我们仍然需要将数据检索出来,我们会通过某种检索算法找到与输入问题相似的嵌入片
-
Output (输出) :把问题以及检索出来的嵌入片一起提交给LLM,LLM会通过问题和检索出来的提示一起来生成更加合理的答案
4.1 文本加载器(Document Loaders)
文本加载器就是将用户提供的文本加载到内存中,便于进行后续的处理
4.2 文本切割器(Text Splitters)
文本分割器把Documents 切分为指定大小的块,我把它们称为“文档块”或者“文档片”
文本切割通常有以下几个原因
- 为了更好的进行文本嵌入以及向量数据库的存储
- 通常大语言模型都有上下文的限制,如果不进行切割,文本在传递给大模型的时候可能超出上下文限制导致大模型随机丢失信息
文本切割器的概念是非常容易理解的,这里我们简单了解下文本切割器的工作流程
- 将文本切割成小的,语义上有意义的块(通常是句子)
- 开始将这些小块组成一个较大的块,直到达到某个块的大小(这个会通过某种函数测量)
- 一旦达到该大小,就将该块作为自己的文本片段,并开始创建一个新的文本块,同时保留一些重叠(以保持块之间的上下文)。
4.3 文本嵌入模型(Text Embedding models)
文本嵌入模型是用来将文本转换成数值向量的工具,这些向量能够捕捉文本的语义信息,使得相似的文本在向量空间中彼此接近。这对于各种自然语言处理任务,如文本相似性比较、聚类和检索等,都是非常有用的。下面是一段对嵌入的解释
词嵌入(Word Embedding)是自然语言处理和机器学习中的一个概念,它将文字或词语转换为一系列数字,通常是一个向量。简单地说,词嵌入就是一个为每个词分配的数字列表。这些数字不是随机的,而是捕获了这个词的含义和它在文本中的上下文。因此,语义上相似或相关的词在这个数字空间中会比较接近。
举个例子,通过某种词嵌入技术,我们可能会得到:
“国王” -> [1.2, 0.5, 3.1, …]
“皇帝” -> [1.3, 0.6, 2.9, …]
“苹果” -> [0.9, -1.2, 0.3, …]
从这些向量中,我们可以看到“国王”和“皇帝”这两个词的向量在某种程度上是相似的,而与“苹果”这个词相比,它们的向量则相差很大,因为这两个概念在语义上是不同的。
词嵌入的优点是,它提供了一种将文本数据转化为计算机可以理解和处理的形式,同时保留了词语之间的语义关系。这在许多自然语言处理任务中都是非常有用的,比如文本分类、机器翻译和情感分析等。
4.4 向量数据库(Vector Stores)

向量存储(Vector stores)是用于存储和检索文本嵌入向量的工具。这些向量是文本数据的数值表示,它们使得计算机能够理解和处理自然语言。向量存储对于支持复杂的搜索和检索任务至关重要,尤其是在处理大量文本数据时。
向量存储的主要功能包括:
- 高效地存储大量的文本向量
- 快速检索与给定向量最相似的文本向量
- 支持复杂的查询操作,如范围搜索和最近邻搜索
4.5 文本检索
一旦数据进入向量数据库,我们仍然需要将数据检索出来,我们会通过某种检索算法找到与输入问题相似的嵌入片。这里主要利用了大模型的能力
五、本地知识库进阶
如果想要对知识库进行更加灵活的掌控,我们需要一个额外的软件:AnythingLLM,这个软件包含了所有Open WebUI的能力,并且额外支持了以下能力
- 选择文本嵌入模型
- 选择向量数据库
5.1 AnythingLLM安装和配置
当我们安装完成之后,会进入到其配置页面,这里面主要分为三步
- 第一步:选择大模型

- 第二步:选择文本嵌入模型

- 第三步:选择向量数据库

5.2 构建本地知识库
AnythingLLM中有一个Workspace的概念,我们可以创建自己独有的Workspace跟其他的项目数据进行隔离。
- 首先创建一个工作空间

- 上传文档并且在工作空间中进行文本嵌入

- 选择对话模式
AnythingLLM提供了两种对话模式:
- Chat模式:大模型会根据自己的训练数据和我们上传的文档数据综合给出答案
- Query模式:大模型仅仅会依靠文档中的数据给出答案

- 测试对话
当上述配置完成之后,我们就可以跟大模型进行对话了

六、总结
虽然对于大多数人来讲,由于我们的电脑配置等原因,部署本地大模型并且达到很好的效果是很奢侈的一件事情。
但是这并不妨碍我们对其中的流程和原理进行详细的了解
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/神奇cpp/article/detail/977866
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

