- 1Datawhale AI 夏令营 第四期 AIGC task 01
- 2Chromium 实战(一) -- 构建chromium_chromium开发教程
- 3【Nacos】docker部署nacos服务
- 4python新手练手项目-推荐:一个适合于Python新手的入门练手项目
- 5Kubernetes存储Volume_kubernetes deployment volume
- 6python入门基础-格式化输出(f-string、%s、format)、基础运算符(in、and、or、...)(超详细!!!)(4)
- 7pip升级报错(权限问题)_win11 pip 更新 文件夹 没有权限
- 8高级加密标准AES的工作模式(ECB、CBC、CFB、OFB)_aes加解密cfb模式_aes cfb
- 9arm svc
- 10Linux安装JDK步骤_linux下载jdk-8u131
CLIP是啥?_clip 库是做什么的
赞
踩
论文地址:https://arxiv.org/pdf/2103.00020v1
题目解读
Transferable Visual model指不使用特定数据集的数据训练模型,但是得到的模型却可以在多个不同的特定数据集上表现出良好的性能,该模型具有Transferable的性质。
From natural language supervision指从语言文本中提取有效的信息,辅助CV模型的构建和训练。
一、CLIP是什么?
答:CLIP是一个预训练模型,就像BERT、GPT、ViT等预训练模型一样。首先使用大量无标签数据训练这些模型,然后训练好的模型就能实现,输入一段文本(或者一张图像),输出文本(图像)的向量表示。CLIP和BERT、GPT、ViT的区别在于,CLIP是多模态的,包含图像处理以及文本处理两个方面内容,而BERT、GPT是单文本模态的,ViT是单图像模态的。
二、作者提出CLIP的动机?
答:1.现有CV模型大多都只能预测已知的图像类别,对于没有见过的图像类别,需要额外的信息才能识别。那么文本其实就提供了这样的额外信息。所以利用图像对应的文本数据,也许就能使模型能够分辨未见类的图像。
2.最近NLP领域中出现的BERT、GPT等预训练模型表明,用大规模的无监督数据训练模型,可以在多个下游NLP任务上获得非常好的结果,有些甚至超过使用人工标注的数据训练出的模型。而现有的CV模型基本都是基于人工标注的数据集训练的(比如ImageNet),那么仿照NLP中预训练模型,如果使用大量无监督(也就是非人工标注)的图像,CV模型能否实现突破呢?
3.目前也有很多研究者注意到natural language在CV中的作用,并尝试利用起来。但是实际的实验结果通常低于其他特殊设计的使用有监督数据的模型。但是作者认为,他们在CV模型中加入natural language数据后实际结果不够好的原因可能是数据规模仍然不够大,而不是natural language数据对CV无用。
三、CLIP的预训练数据是什么?
预训练数据是作者新构建的WIT数据集。鉴于现有CV数据集仍然不够大,且很少包含足够的natural language数据(大多CV数据集中的文本数据只是图像的类别指示,比如dog,cat等单词),所以作者从网上爬了4亿个图像-文本对,构建了数据集WIT(WebImageText)。WIT数据集中的文本都是图像相关的sentence,而不是single word,因此提供了足够的natural language数据。
四、CLIP的预训练任务是什么?
CLIP的预训练任务是预测给定的图像和文本是否是一对(paired),使用对比学习(contrastive learning)的loss。
我们知道,为了能够充分利用大量的无监督数据,预训练任务一般都是自监督的,比如BERT的预训练任务是masked language model(MLM)和next sentence prediction(NSP)。VirTex的预训练任务是预测图像的caption。按照这种思路,本文先尝试将预测图像的caption(也就是WIT数据集中图像对应的text sentence)作为预训练任务,如下图中蓝色线条预测text中的一个个words,结果甚至不如简单的直接预测text的bag-of-words encoding来得又快又好(如下图中橙色线条)。但是作者认为,上述两种方法都是预测文本的exact words,这样显然是很难的,因为文本表达具有丰富性和多样性,同一张图像能够有非常多不同的与之对应的合理表述文本。
所以本文采取了对比学习的方法来预训练CLIP。直接将image对应的text sentence作为一个整体,来判断text和image是否是一对。对于一个包含N个图像-文本对的batch而言,其中正样本是每张图像及其对应的文本,一共有N个,而其他所有图像和文本的组合都是不成对的,也就是负样本是N×N-N个。实验发现该方法在效果和性能上都很好,如下图绿色线条。
五、CLIP的结构?
CLIP的主要结构是一个文本编码器Text Encoder和一个图像编码器Image Encoder,然后计算文本向量和图像向量的相似度以预测它们是否为一对。
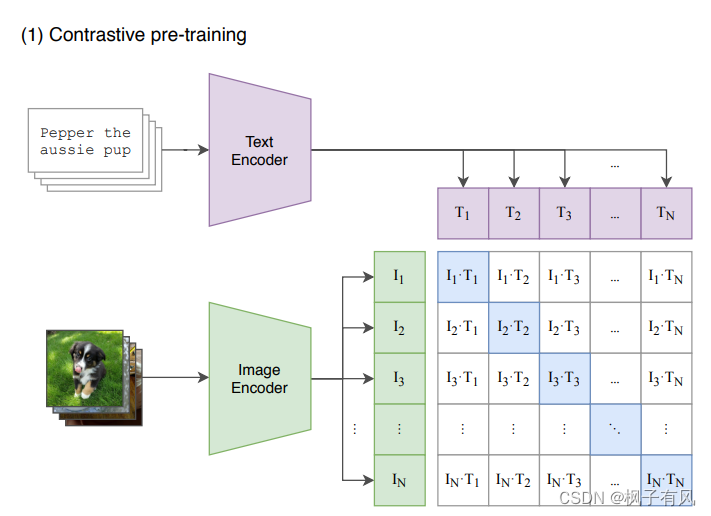
CLIP将图像和文本先分别输入一个图像编码器image_encoder和一个文本编码器text_encoder,得到图像和文本的向量表示 I-f 和 T_f 。然后将图像和文本的向量表示映射到一个joint multimodal sapce,得到新的可直接进行比较的图像和文本的向量表示 I_e 和T_e (这是多模态学习中常用的一种方法,不同模态的数据表示之间可能存在gap,无法进行直接的比较,因此先将不同模态的数据映射到同一个多模态空间,有利于后续的相似度计算等操作)。然后计算图像向量和文本向量之间的cosine相似度。最后,对比学习的目标函数就是让正样本对的相似度较高,负样本对的相似度较低。
经过上述训练过程,CLIP实际上得到了两个训练好的文本编码器和图像编码器,后续的工作就围绕这两个编码器展开。
作者在本文中实验了5种ResNet模型和3种Visual Transformer模型作为图像编码器,文本编码器则用了Transformer。经过实验发现,这些不同的图像编码器中效果最好的是ViT-L/14@336px。
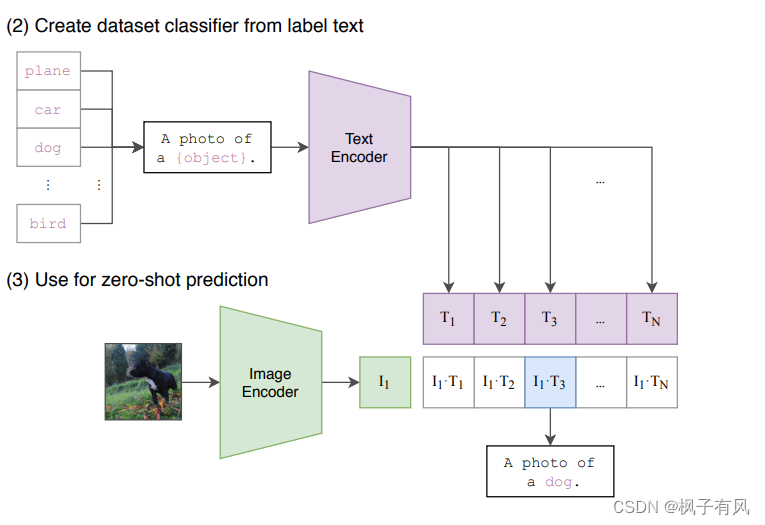
六、文中多次提到的Zero shot transfer of CLIP 是什么意思?
本文的CLIP预训练时使用的数据集是WIT,而在ImageNet、STL10、Food101、CIFAR10、MNIST等其他数据集上直接测试。这意味着CLIP在训练时没有见过ImageNet这些数据集中的图像,那么这种测试实际上就是zero shot的。

一个测试例子可以看下图,假设要测试的数据集是ImageNet,那么,因为CLIP在训练时用的所有数据来自WIT,而没有任何ImageNet的数据,所以CLIP在ImageNet上进行测试实际上就是Zero shot的。由于ImageNet中text数据只有表示图像类别的car,dog,bird等single word,而CLIP训练时text数据是sentence,为了弥补训练和测试的gap,作者将ImageNet中所有类别单词扩展为一句话“ A photo of a {car/dog/.../bird}. ” ,作为图像对应的sentence(该操作实际上是prompt engineering)。
下图中Text Encoder和Image Encoder是已经训练好的CLIP中的文本和图像编码器,要对任意一张来自ImageNet的图像进行分类,只需要将该图像输入Image Encoder中得到它的向量表示I1。然后将ImageNet数据集中所有类别标签扩展成的sentence输入Text Encoder,得到所有类别的向量表示T1---TN,然后计算I1与T1---TN的相似度,其中相似度最高的就是该图像对应的text数据,也就是该图像的分类结果。