
- 1AI电销机器人系统源码部署二:freeswitch安装Windows_电销系统源码
- 2element-ui简单笔记
- 3mysql 5.7 多主一从_MySQL 5.7 多主一从(多源复制)同步配置
- 4深入浅出块I/O子系统(四)请求处理过程
- 5利用 Databend 生态构建现代数据湖工作流
- 6Android 外接基于UVC协议的摄像头并实现预览_android uvc摄像头
- 7最新最详细的配置Node.js环境教程_node环境配置
- 8【Stable Diffusion】最强模型——Flux推荐和下载_flux模型下载
- 9Word Embeddings 原理与代码实战案例讲解
- 103DGS学习(四)—— 快速高斯光栅化_3dgs原始论文
查收一份来自南极的Iceberg数据治理指南
赞
踩
背景
Apache Iceberg 作为面向超大型湖存储的新一代表格式,由于在元数据管理、数据时效性以及解决传统Hive在海量分区操作耗时方面具备显著优势,目前正在被越来越多的企业用户认可。如腾讯云的新一代Lakehouse产品数据湖计算 DLC,其底层存储同样基于Iceberg深度优化。

作为传统Hive数仓的替代, Iceberg 逐渐被广泛应用于数据湖管理和数据仓库构建中。相比传统Hive,Iceberg 具备完整的ACID语义、支持行级数据更新及时间旅行,支持Schema演进并且凭借更灵活的文件组织方式,能够支持高效的数据过滤从而达到更优性能。
更进一步,Iceberg 结合流式写入可构建近实时数仓,从而将传统Hive离线数仓的数据实时性提高到分钟级。例如在腾讯云数据湖 DLC 产品中,结合InLong可实现高达百万级/秒写入的实时入湖应用,从而在不增加成本下满足各种对数据新鲜度有极高要求的业务场景。
Iceberg 治理痛点
虽然原生Iceberg 能够带来上述事务性、实时更新等好处,但作为一个正在高速迭代中的开源项目,Iceberg 在使用过程中也伴随了一系列的痛点。例如频繁流式写入下带来的小文件问题,以由于Iceberg 元数据组织方式所导致的delete-file、matadata冗余文件随着使用不断增多。
另外要充分发挥Iceberg 性能优势,旨在提升Data Skipping效率、减少对底层对象存储IO压力的数据文件编排也必不可少,但遗憾的是目前Iceberg 对此并未有自适应优化的实现,需要用户根据实际场景进行负载的配置与实现。
本文首先简单总结了几个Iceberg 的典型治理问题,如您熟悉Iceberg 运维可快速跳过。

Iceberg 在尤其是流式写入的场景下,由于commit机制会产生大量的小文件。
小文件如未得到有效的清理则会严重拖慢上层计算系统的性能。虽然用户可以通过手动任务方式使用Iceberg 内置的org.apache.Iceberg.actions.RewriteDataFiles来实现小文件合并,但仍需配合delete-after-commit等配置来进一步实现历史快照清理等一系列动作,如涉及表格过多(如上千张)其维护成本相对较大。

Iceberg 数据治理另一核心问题是随着时间推移将产生大量的冗余数据。
如每次写入Iceberg 时,除insert操作产生数据文件外,delete操作也会同时产生大量的equality-delete-file及position-delete-file,以及各种过期的Snapshot快照文件。一旦这些文件随时间推移再也没有被Iceberg 元数据所引用到,则成为了实际上业务不需要的孤儿文件。

由于Iceberg 通常结合对象存储构建海量一体化湖存储,相比传统存算一体的HDFS系统,对象存储在吞吐带宽、元数据操作效率上的不足,在大数据量扫描下Iceberg 将对底层对象存储系统造成大量的IO压力。因此调整 Iceberg 表的分布来提高数据在特定字段上的聚集性,以及构建Bloom Filter、稀疏索引等索引机制过滤当前查询实际无需读取的数据文件,对于Iceberg 的查询加速非常关键。
除上述三点以外,Iceberg 数据治理还存在需要周期性检验MetaData 元文件大小、避免过大引起查询引擎OOM,以及数据优化任务周期性调度与成本控制等一系列挑战。
Iceberg 治理破局
Iceberg 目前在数据治理上的局限,像极了10年前的安卓系统。
对于上述Iceberg 数据治理问题,虽然Iceberg 提供了小文件合并、过期Snapshot删除等功能,社区以也逐渐总结出了一系列最佳实践和解决方案,但目前社区仍缺乏自动化实现。用户需自行规划治理方案以及周期性手动操作,无疑大大增加了用户使用、优化Iceberg 的门槛的成本,而熟悉Iceberg 数据治理的人才也较为紧缺。

为解决安卓系统使用一段时间后的垃圾文件膨胀及严重卡顿,各种旨在自动智能清理的手机管家类产品应运而生。如腾讯手机管家曾服务近10亿国内安卓用户。
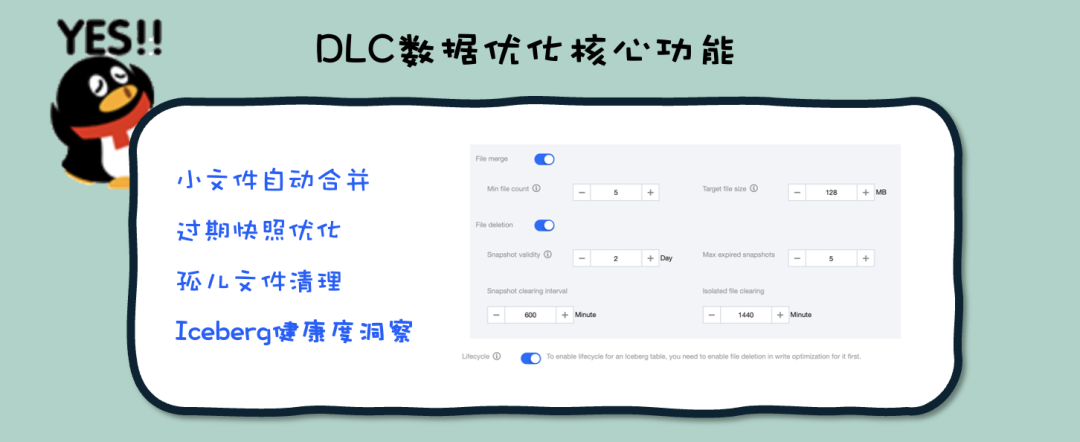
对于Iceberg ,是否能有屏蔽底层运维复杂性的一站式的Lakehouse优化管家?腾讯云数据湖计算 DLC 产品目前已具备成熟的自适应数据优化功能,用户在使用DLC托管存储后可开启原生表数据优化功能,DLC将自动对小文件及Iceberg 过期快照进行周期性优化,无需用户手动运维。
如国内某大型泛互客户因业务需要,通过腾讯云InLong将实时业务数据通过upsert方式实时入湖,其QPS超过了百万条数据每秒,整体为Iceberg 带来了巨大的小文件与冗余文件压力。该客户使用了DLC数据优化后,通过约256 CU的弹性资源即完成了全链路约2000张表治理优化的需求,日均稳定运行超3万作业数。
DLC Iceberg 洞察
更进一步,DLC目前推出了Iceberg 健康度洞察功能,在DLC控制台——数据管理——数据库即可查看到相关库表的健康度情况。
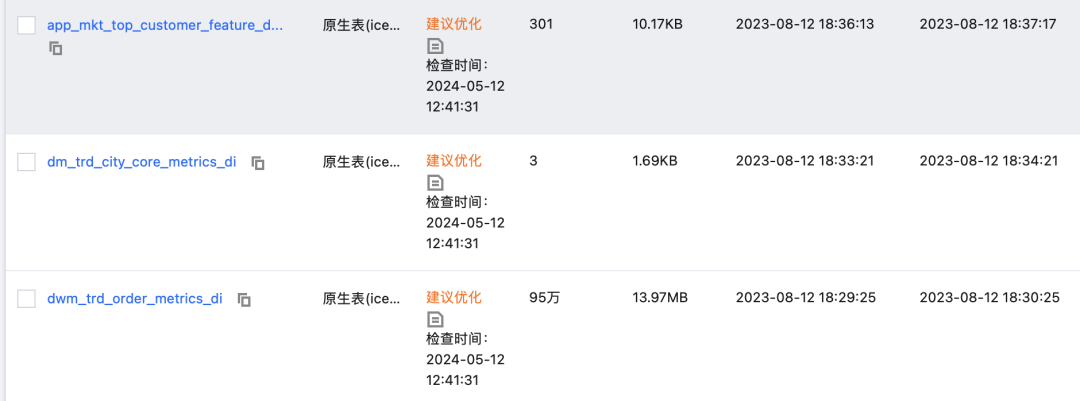
此外,还能看到Iceberg 快照信息、文件信息、数据优化效果可视化展示。
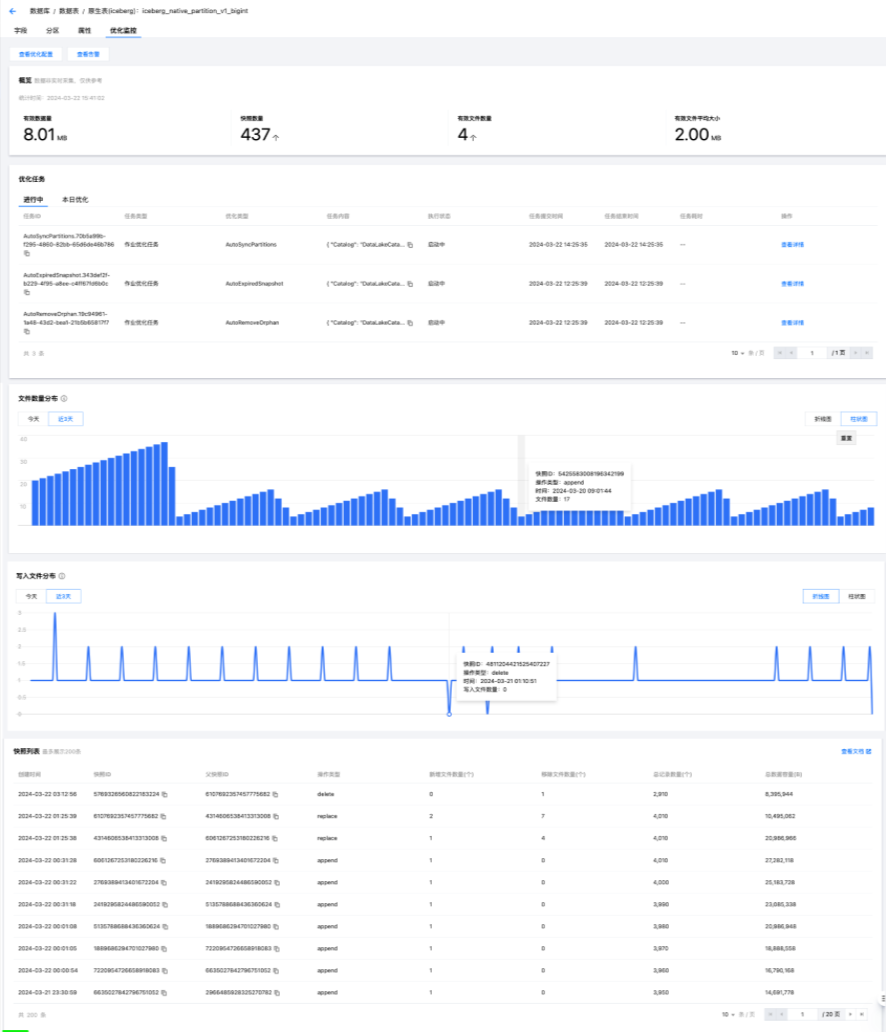
对于每一张DLC原生表,可进一步查看健康度明细情况,帮助和提示用户优化。如发现健康度较差的原生表,可按照控制台相关指引开启DLC数据优化,后台自动执行任务后将恢复原生表健康度。
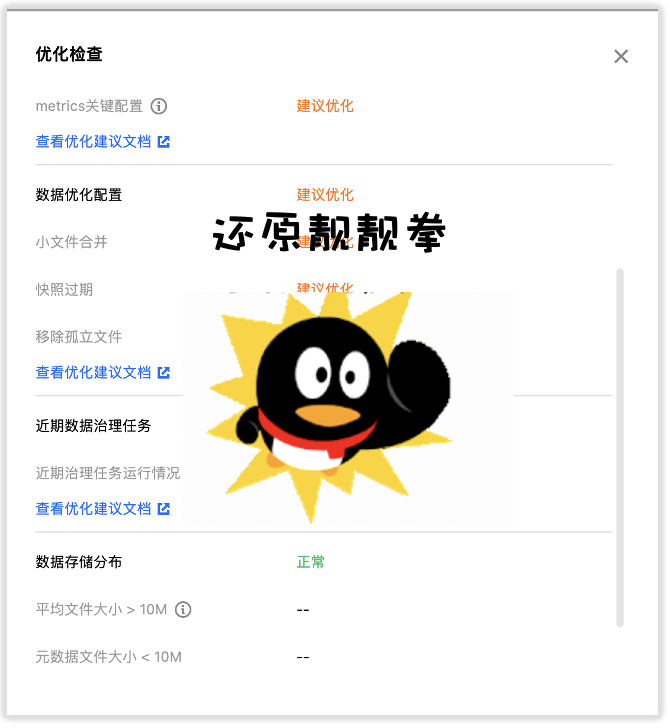
具体DLC数据优化将会根据内置优化策略周期性执行优化策略,过程无需用户主动参与,相关优化任务信息可在DLC的历史任务中查看。
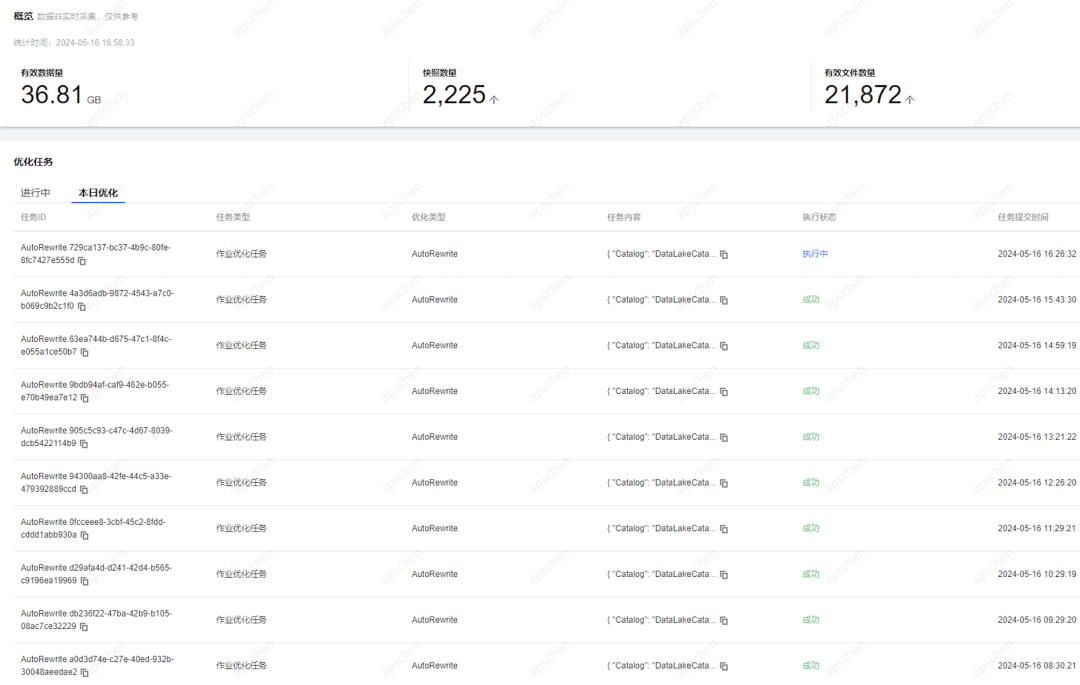
当前DLC的Iceberg 健康度洞察核心检查项如下:

DLC Iceberg 健康度洞察将在原数据优化基础上,进一步通过可视化方式帮助用户了解当前存储系统的健康度和风险情况。如您对Iceberg 健康度及DLC数据优化感兴趣,可进一步通过 DLC官网文档 获得更多信息。
未来更多工作
Iceberg 数据治理正是当前很多企业用户选型Iceberg 决策的犹豫不确定因素之一。腾讯云数据湖计算 DLC 产品作为Serverless Lakehouse产品,我们深知数据优化作为Iceberg 的最关键后勤保障,近年来投入了大量资源进行相关的特性开发。在未来,DLC团队将持续在Iceberg 治理优化上投入,在稀疏索引、zorder产品化构建等方面更多的关键产品能力。
同时在不远的将来,我们计划将DLC数据优化升级为服务腾讯云数据湖全系列产品的通用组件。届时腾讯云弹性MapReduce(EMR)用户同样可以使用到与DLC一致的Iceberg 数据治理能力,从而可根据自身业务和架构需要,使用EMR或DLC产品构建自己的云原生数据湖,而其背后数据湖复杂的治理运维将可通过统一数据优化解决。
此外,DLC 将进一步投入到基于 Iceberg 的统一+开放Lakehouse架构建设,支持对包括Starrocks、Doris在内的更多计算引擎适配,整体实现 DLC 一份开放的湖存储支持多种上层引擎。用户可根据实际业务场景需求,设计高度灵活的Lakehouse应用体系,充分释放 Iceberg 技术和数据价值。
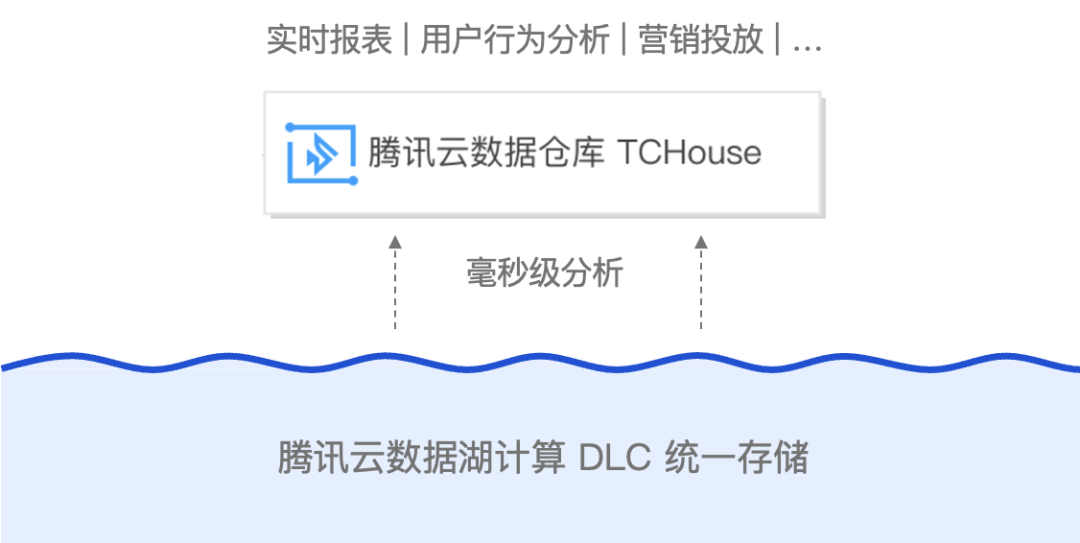
例如,结合腾讯云数据仓库 TCHouse,腾讯云数据湖计算 DLC 即将发布全新 Lakehouse 加速模式,TCHouse可直接查询 DLC 内部托管湖数据,过程无需经过任何数据复制和同步。TCHouse作为覆盖云数仓全场景的云原生全托管数据仓库服务,具备极致云原生弹性、高并发查询、高性能执行引擎等优势,TCHouse在Lakehouse加速模式下,基于DLC湖存储可提供毫秒级高性能查询,满足各类严苛的低时延业务场景需求,同时用户可享受到 DLC 数据湖灵活性和低成本一体化存储的优势。

