
- 1python opencv中文显示cv2 imshow()窗口中文标题乱码解决办法 python win32gui按装_cv2.imshow中文乱码
- 22024 年十大 Vue.js UI 库_vue组件库
- 3C++学习笔记03-智能指针(shared_ptr,unique_ptr)和动态分配的数组_智能指针申请类数组
- 4我是怎么把博客粉丝转到公众号的
- 5使用Github做永久免费的个人网站~最新最全、看完包会!!!_github免费入口
- 6【笔记】nlp_nlp entity-grid
- 7基于opencv的图像处理系统的设计与实现_图像处理模块设计
- 8Java-SpringBoot:用户认证(Authentication)和用户授权(Authorization)_java authentication
- 912.企业安全建设入门(基于开源软件打造企业网络安全) --- 办公网准入系统和安全加固_开源准入系统
- 10第一章 使用开发者模式快速入门 Odoo 12_odoo开发入门与精通
NLP经典论文阅读:从神经网络语言模型(NNLM)到词向量(word2vec)_nnlm论文
赞
踩
本文仅供自己日后复习所用,参考了很多博客和知乎回答的内容,中途没有及时记录所以无法一一列出,希望谅解。
NLP的发展过程中的核心技术代表
2001 - Neural language models(神经语言模型)
2008 - Multi-task learning(多任务学习)
2013 - Word embeddings(词嵌入)
2013 - Neural networks for NLP(NLP神经网络)
2014 - Sequence-to-sequence models
2015 - Attention(注意力机制)
2015 - Memory-based networks(基于记忆的网络)
2018 - Pretrained language models(预训练语言模型)
本篇博客涉及其中之二。
1. 基于统计的语言模型
语言模型与维数灾难
语言模型是NLP领域一个基本且重要的任务,本质是对一段自然语言的文本进行概率的预测,一般通过计算某种语言的词序列的联合概率实现。
假设句子S长度为 T,词用 x 表示,那么这个句子的概率可用如下公式表示:
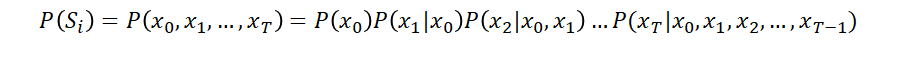
利用条件概率公式计算词语序列的联合概率,会带来一个问题:维数灾难(curse of dimensionality)
即模型参数太多,会导致过拟合。
假设要建模一个有10个单词的句子的联合概率分布,词表大小为100000,参数量为
10000
0
10
−
1
100000^{10} - 1
10000010−1
N-Gram模型
为了解决维数灾难的问题,引入马尔可夫假设:假定一个句子中的词只与它前面的 n-1 个词相关。
这样得到的就是N-Gram模型。
例如n=2时,得到bigram model:
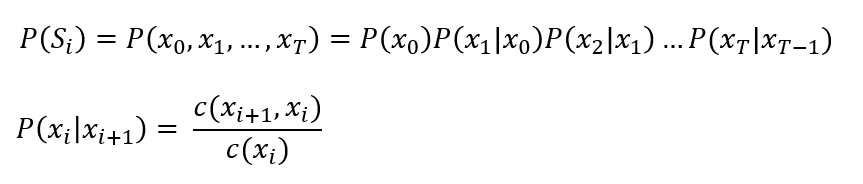 C是词频的统计函数。
C是词频的统计函数。
训练语料里面有些 n 元组没有出现过,其对应的条件概率就是 0,导致计算一整句话的概率为 0。尤其在 n 取值较大时,这种数据稀疏导致的计算为 0 的现象变得特别严重
所以统计语言模型中一个很重要的方向便是设计各种平滑方法来处理这种情况。
除了数据稀疏,N-Gram还有两个缺点。
一是基于统计的语言模型无法把 n 取得很大, 3-gram 比较常见。因此统计语言模型无法对语言中上下文较长的依赖关系建模。虽然用马尔可夫假设限定了窗口,但参数量还是随着窗口大小指数增长。
假设词表中词的个数为20000
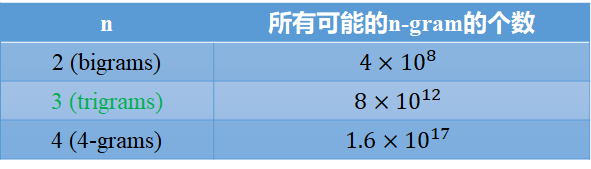
二是N-Grams不考虑单词之间的“相似性”。
如训练语料中有一句“The cat is walking in the bedroom.”,那么,语言模型生成句子“a dog is running in a room”的概率应该相近。但N-Grams模型仅仅靠每个n元组出现的频次计算概率,无法解决词语相似性的问题。
下一节介绍的《A Neural Probabilistic Language Model》一文将着力解决这两个问题。
2. 神经网络语言模型(NNLM)
2003年,Bengio在他的经典论文《A Neural Probabilistic Language Model》中,首次将深度学习的思想融入到语言模型中,并发现将训练得到的NNLM(Neural Net Language Model)模型的第一层参数当做词的分布式表征时,能够很好地获取词语之间的相似度。
具体来说,如果一句话在训练数据中从来没见过,但组成它的单词和已经训练的句子中的单词相似,那么模型生成它的几率会较高。

以上图为例,对NNLM模型,红框中的句子如果在训练语料中出现了很多次,那么绿框中没在训练语料中出现的句子(语义与语法角色与之相近)经模型预测出的概率比较高。
而N-Gram模型则不能做到这一点。
NNLM模型公式
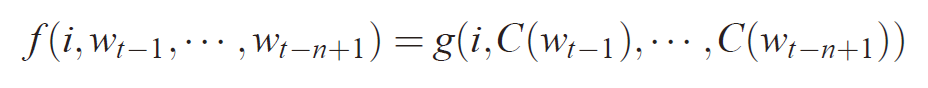
f为一个概率输出函数
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

