
- 1企业支付宝账号开发接口教程--JAVA-UTF-8(实际操作------SpringMVC+JSP)
- 2自学也能学得会的《零基础入门学习Web开发》(HTML5 & CSS3)_零基础入门学习web开发pdf
- 3从隐私到隐私计算
- 4基于单片机的烟雾监测报警与控制系统_基于单片机的烟雾报警系统
- 5【开源物联网平台】FastBee使用EMQX5.0接入步骤_java 开源的物联网项目
- 6微信小程序中的加载更多(即列表分页)_小程序 分页加载更多
- 7五菱carplay车机固件升级教程-简洁桌面版_五菱carplay固件升级
- 8经典卷积模型回顾20—YOLOv1实现猫狗检测(matlab,Tensorflow2.0)_yolov1用matlab
- 9Python编写的超帅数独可视化解题器
- 10webgpu
K-近邻算法: k-nearest neighbor classification (kNN) 详细介绍_knn算法误差率
赞
踩
@创建于:2020.04.09
@修改于:2020.04.09
1、kNN介绍
kNN是一个基本而简单的分类算法,作为监督学习,那么KNN模型需要的是有标签的训练数据,对于新样本的类别由与新样本距离最近的k个训练样本点按照分类决策规则决定。k近邻法1968年由Cover和Hart提出。
k近邻法(k-nearest neighbor, kNN)是一种基本的分类与回归方法;是一种基于有标签训练数据的模型;是一种监督学习算法。
基本做法的三个要点是:
第一,确定距离度量;
第二,k值的选择(找出训练集中与带估计点最靠近的k个实例点);
第三,分类决策规则。
- 在 分类 任务中可使用“投票法”,即选择这k个实例中出现最多的标记类别作为预测结果;
- 在 回归 任务中可使用“平均法”,即将这k个实例的实值输出标记的平均值作为预测结果;
- 还可基于距离远近进行加权平均或加权投票,距离越近的实例权重越大。
k近邻法不具有显式的学习过程。它是懒惰学习(lazy learning)的著名代表,此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理。
参考链接:
2、k近邻法的三要素详解
距离度量、k值的选择及分类决策规则是k近邻法的三个基本要素。
如下图,根据欧氏距离,选择k=4个离测试实例最近的训练实例(红圈处),再根据多数表决的分类决策规则,即这4个实例多数属于“-类”,可推断测试实例为“-类”。
 参考链接:机器学习(二):k近邻法(kNN)
参考链接:机器学习(二):k近邻法(kNN)
2.1 距离度量
特征空间中的两个实例点的距离是两个实例点相似程度的反映。K近邻法的特征空间一般是n维实数向量空间
R
n
R_n
Rn。度量的距离是其他
L
p
L_p
Lp范式距离,一般为欧式距离。
L
p
(
x
i
,
x
j
)
=
(
∑
l
n
∣
x
i
(
l
)
−
x
j
(
l
)
∣
p
)
1
p
(1)
L_p(x_i, x_j) = (\sum_l^n|x_i^{(l)}-x_j^{(l)}|^p)^\frac{1}{p} \tag1
Lp(xi,xj)=(l∑n∣xi(l)−xj(l)∣p)p1(1)
- 这里 p ≥ 1 p\geq1 p≥1,
- 当p=1时,称为曼哈顿距离(Manhattan distance)
L 1 ( x i , x j ) = ∑ l n ∣ x i ( l ) − x j ( l ) ∣ (2) L_1(x_i, x_j) = \sum_l^n|x_i^{(l)}-x_j^{(l)}| \tag2 L1(xi,xj)=l∑n∣xi(l)−xj(l)∣(2) - 当p=2时,称为欧氏距离(Euclidean distance)
L 2 ( x i , x j ) = ( ∑ l n ∣ x i ( l ) − x j ( l ) ∣ 2 ) 1 2 (3) L_2(x_i, x_j) = (\sum_l^n|x_i^{(l)}-x_j^{(l)}|^2)^\frac{1}{2} \tag3 L2(xi,xj)=(l∑n∣xi(l)−xj(l)∣2)21(3) - 当p=∞时,它是各个坐标距离的最大值。
 参考链接:机器学习(二):k近邻法(kNN)
参考链接:机器学习(二):k近邻法(kNN)
2.2 k值的选择
常用的方法:
(1)从k=1开始,使用检验集估计分类器的误差率。
(2)重复该过程,每次K增值1,允许增加一个近邻。
(3)选取产生最小误差率的K。
注意:
(1)一般k的取值不超过20,上限是n的开方,随着数据集的增大,K的值也要增大。
(2)一般k值选取比较小的数值,并采用交叉验证法选择最优的k值。
说明:
- (1)过小的k值模型中,输入样本点会对近邻的训练样本点十分敏感,如果引入了噪声,则会导致预测出错。对噪声的低容忍性会使得模型变得过拟合。
- (2)过大的k值模型中,就相当于选择了范围更大的领域内的点作为决策依据,可以降低估计误差。但邻域内其他类别的样本点也会对该输入样本点的预测产生影响。
- (3)如果k=N,N为所有样本点,那么KNN模型每次都将会选取训练数据中数量最多的类别作为预测类别,训练数据中的信息将不会被利用。
参考链接:
2.3 分类决策规则
kNN的分类决策规则就是对输入新样本的邻域内所有样本进行统计数目。
邻域的定义就是,以新输入样本点为中心,离新样本点距离最近的k个点所构成的区域。
参考链接:KNN
3、k近邻法的实现:kd树
k近邻法最简单的实现方法是线性扫描(linear scan),这时要计算输入实例与每一个训练实例的距离,当训练集很大时,计算非常耗时。
kNN的时间复杂度为O(n),一般适用于样本数较少的数据集,当数据量大时,可以将数据以树的形式呈现,能提高速度,常用的有kd-tree和ball-tree。
下面介绍其中的kd树方法(平衡二叉树)。kd树是存储k维空间数据的树结构,这里的k与k近邻法的k意义不同。
依次选择坐标轴对空间切分,选择训练实例点在选定坐标轴上的中位数(一组数据按大小顺序排列起来,处于中间的一个数或最中间两个数的平均值。本文在最中间有两个数时选择最大值作中位数)为切分点,这样得到的kd树是平衡的。注意,平衡的kd树搜索时未必是最优的。
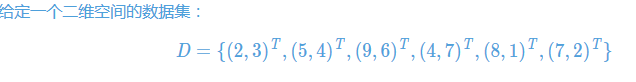
 参考链接:
参考链接:
4、Python实现过程
sklearn中的K近邻分类器在sklearn库中,可以使sklearn.neighbors.KNeighborsClassifier 创建一个K近邻分类器 。
主要参数有:
- n_ neighbors:用于指定分类器中K的大小(默认值为5,注意与kmeans的区别)。
- weights:设置选中的K个点对分类结果影响的权重(默认值为平均权重“uniform”,可以选择“distance"代表越近的点权重越高,或者传入自己编写的以距离为参数的权重计算函数)。
- algorithm:设置用于计算临近点的方法,因为当数据量很大的情况下计算当前点和所有点的距离再选出最近的k各点,这个计算量是很费时的,所以选项中有ball tree、kd_ tree和brute,分别代表不同的寻找邻居的优化算法,默认值为auto,根据训练数据自动选择。
from sklearn.neighbors import KNeighborsClassifier
# 设置最近的3个邻居作为分类的依据
neigh = KNeighborsClassifier(n_neighbors = 3, weights = 'uniform', algorithm = 'auto')
- 1
- 2
- 3
详细代码请参考链接:监督学习-分类(KNN算法)
5、优缺点
1、优点
- 简单,易于理解,易于实现,无需估计参数,无需训练;
- 适合对稀有事件进行分类(例如当流失率很低时,比如低于0.5%,构造流失预测模型);
- 特别适合于多分类问题(multi-modal,对象具有多个类别标签),例如根据基因特征来判断其功能分类,kNN比SVM的表现要好。
2、缺点
- 懒惰算法,对测试样本分类时的计算量大,内存开销大,评分慢;
- 可解释性较差,无法给出决策树那样的规则。
参考链接:数据挖掘十大算法——kNN
6、常见问题
1、k值设定为多大?
- k太小,分类结果易受噪声点影响;
- k太大,近邻中又可能包含太多的其它类别的点。(对距离加权,可以降低k值设定的影响)
- k值通常是采用交叉检验来确定(以k=1为基准)
- 经验规则:k一般低于训练样本数的平方根
2、类别如何判定最合适?
- 投票法没有考虑近邻的距离的远近,
- 距离更近的近邻也许更应该决定最终的分类,所以加权投票法更恰当一些。
3、如何选择合适的距离衡量?
- 高维度对距离衡量的影响:众所周知当变量数越多,欧式距离的区分能力就越差。
- 变量值域对距离的影响:值域越大的变量常常会在距离计算中占据主导作用,因此应先对变量进行标准化。
4、训练样本是否要一视同仁?
- 在训练集中,有些样本可能是更值得依赖的。
- 可以给不同的样本施加不同的权重,加强依赖样本的权重,降低不可信赖样本的影响。
5、性能问题?
- kNN是一种懒惰算法,平时不好好学习,考试(对测试样本分类)时才临阵磨枪(临时去找k个近邻)。
- 懒惰的后果:构造模型很简单,但在对测试样本分类地的系统开销大,因为要扫描全部训练样本并计算距离。
- 已经有一些方法提高计算的效率,例如压缩训练样本量等。
6、能否大幅减少训练样本量,同时又保持分类精度?
- 浓缩技术(condensing)
- 编辑技术(editing)
参考链接:数据挖掘十大算法——kNN

