
- 1ChatGPT 的核心 GPT 模型:探究其生成式预训练变换架构的革新与应用潜力_gpt模型基于什么框架
- 2失业在家怎么办?分享8个国家认可的赚钱软件让你不再焦虑_在家赚钱的软件
- 3使用代理IP实现Python爬虫中的随机IP请求_python随机代理
- 4ENSP实验抓取IP包分片_ensp抓包
- 5Linux中的超级用户是谁?底层原理是什么?_linux 超级用户
- 6MSSQLSERVER执行计划详解_mssql中使用function后function没有执行计划
- 710款非常实用的在线网站原型设计工具_网页原型图用什么软件做
- 8前端代码提交规范
- 9SQLServer -- 自定义无参数存储过程_sqlserver 存储过程无参数
- 10使用bert-service获取句向量和相似度计算_bert as service 文本相似
最详细的整个Spark运行时的内核架构以及架构思考_spark 最后阶段 sto
赞
踩
一: Spark内核架构
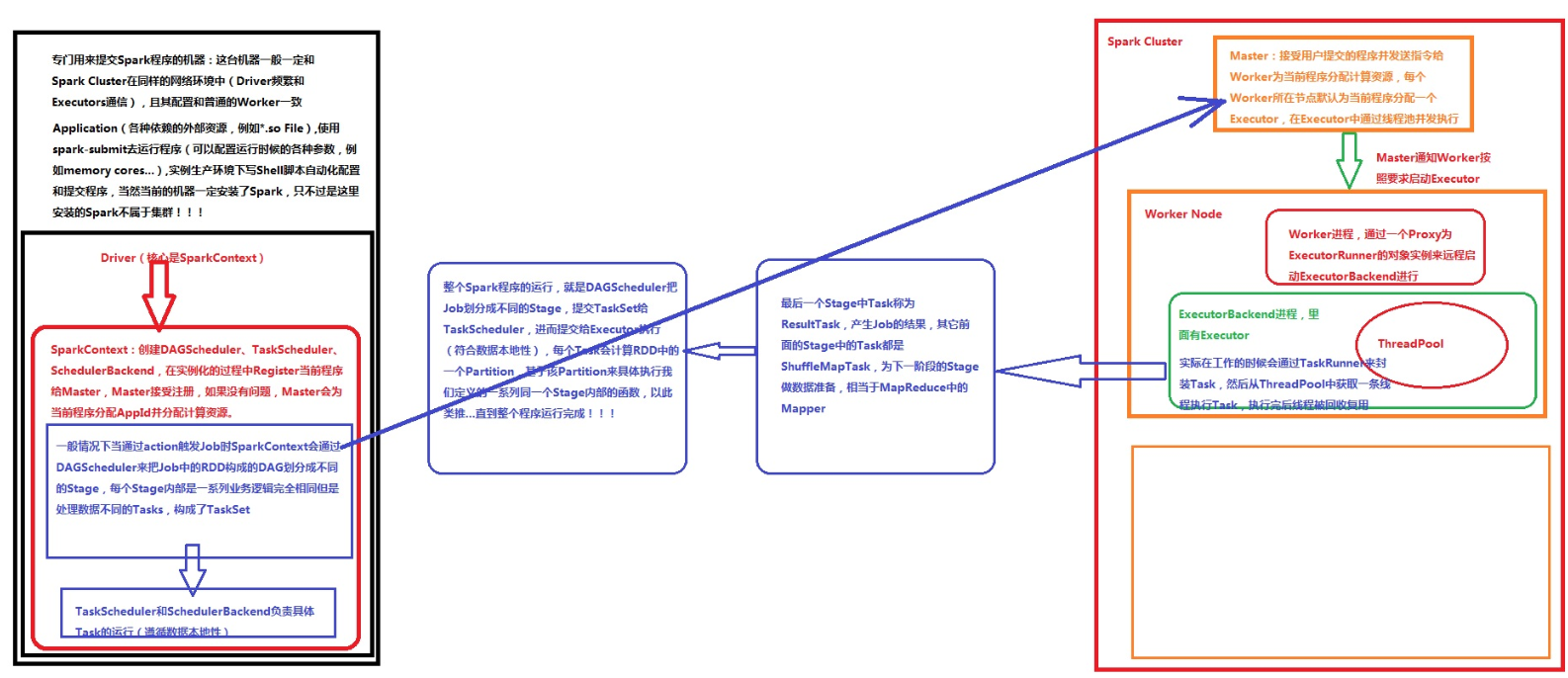
1,Drive是运行程序的时候有main方法,并且会创建SparkContext对象,是程序运行调度的中心,向Master注册程序,然后Master分配资源。
应用程序: Application = Driver(驱动程序) + Executor(执行程序)
Driver部分的代码:主要是SparkContext +SparkConf
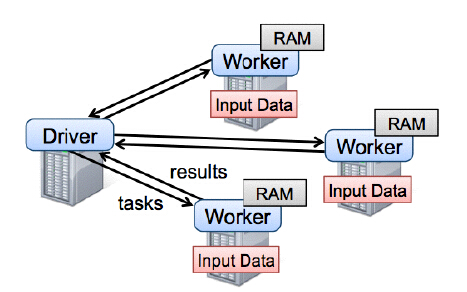
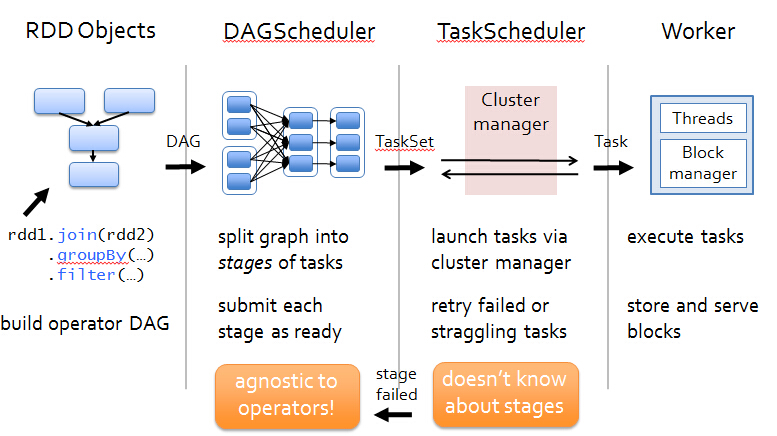
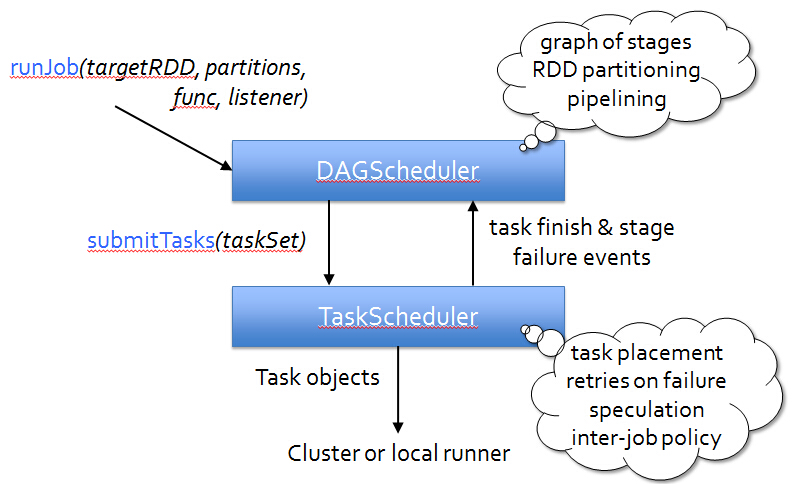
Application 的main 方法 、创建sparkcontext、这样 环境对象 sparkcontext 创建时要有程序的高层调度器DAGScheduler 分为几个阶段 、底层调度器TasKScheduler 一个阶段的任务处理 、SchedulerBackend向Master 注册程序 、分资源 、根据 job 许多RDD 从后向前倒推 如宽依赖划分不同的stage 然后提交给底层调度器TaskScheduler 然后根据 数据的本地性 发送到 Excutor 去执行,如出问题 向 Drive 部分 汇报 完成 关闭创建对象
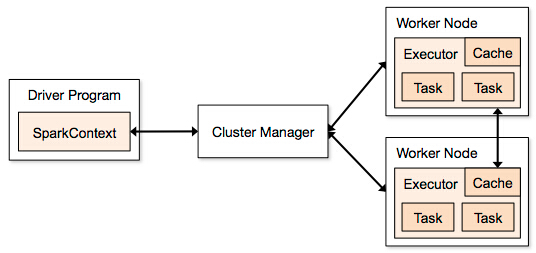
Executor 是运行在Worker所在节点上,为当前应用程序而开启的一个JVM进程里边的一个对象,这个对象负责具体Task的运行。这个JVM进程里面是通过 线程池并发 每个线程运行一个Task任务 ,完成后 进行 线程复用。
默认情况在一个节点上 只为当前程序 开启 一个 Excutor。
Cluster Manager(集群中获取资源的Web服务)
spark Aplication 运行不依赖 Cluster Manager
可插拔的 资源方式 粗粒度的
Worker 操作代码的节点,不运行 程序的代码,管理 当前 节点的资源(cup,Memory),并接收 Master指令来分配具体的计算资源的Excutor(在新的进程中分配)
并通过ExcutorRunner 来具体启动一个新进程,进程里面有Executor。
在此可以做一个比喻:Worker是工头,Cluster Manager:是项目经理
Master:是Boss
worker 不会 汇报 当前信息(发心跳) 给 Master
故障时候 发的心跳 只有 workid
Master 分配时 就知道 资源
Job 包含一系列的task 并行计算 一般由action 触发 action不会产生RDD
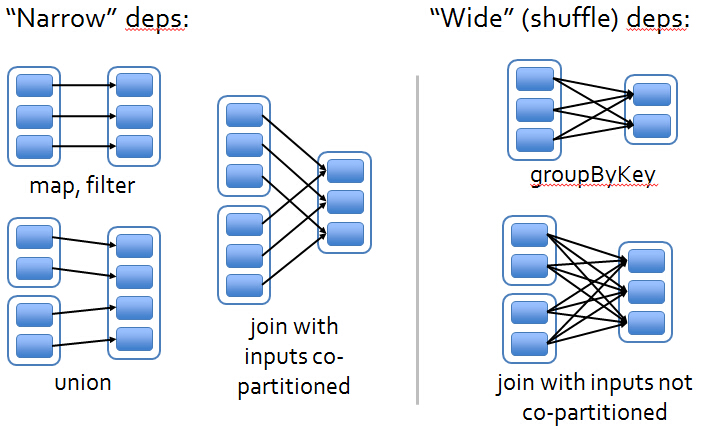
action前面的是RDD ,前面的RDD是Transformation级别的是lazy的执行方式,他是从后往前推,如果后面的RDD与前面的RDD是回溯的话是窄依赖(如果父RDD的一个Partition被一个子RDD的Partion所使用的话就是窄依赖,否则的话就是宽依赖,如果子RDD中的Partition对父RDD的Partition依赖的数量不会随着数据量规模的改变而改变的话就是窄依赖,否则的话就是宽依赖)的话就在内存中进行迭代。宽依赖导致stage的划分。
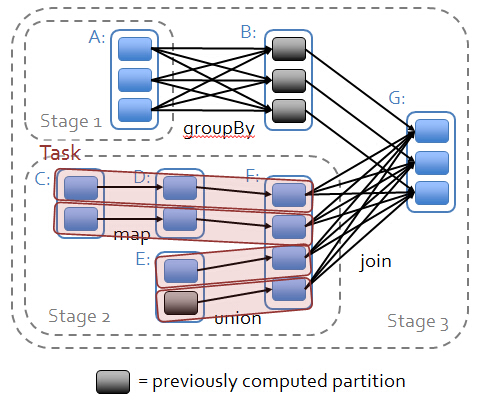
Spark快绝不是因为基于内存,最基本的是他的调度,然后是他的容错
如果 宽依赖
依赖构成了 DAG ,DAG导致 宽依赖
stage 是内存迭代 当然也可以 磁盘的迭代 ,如有100W 个数据分片 就有 100W 个task任务
stage内部:计算逻辑一样 只是 算的数据不一样而已
任务本身计算数据分片 ,一个pation是否精的 等于 一个 block大小?
默认情况下 是 一个数据分片 128MB 最后一个记录跨2个 block
怎么分配资源:通过spark-env.sh和spark-defaults.sh
Scheduling:
Dependency Types :
Event Flow :
本博客内容来自于 : 简介: 王家林:DT大数据梦工厂创始人和首席专家. 联系邮箱18610086859@126.com 电话:18610086859 QQ:1740415547 微信号:18610086859

