
- 10054期通过AI算法识别不同野生动物-含数据集_动物检测 数据集
- 2网络安全工程师必读的100本书籍,2024年最新一篇文章教你搞定计算机网络面试_成为一名合格的网络安全工程师要看哪些书
- 3【javaSE】String类(2)
- 4PostgreSQL 视图_postgres中视图的作用
- 5[ffmpeg]通过Qt调用ffmpeg命令
- 6国内超大型智能算力中心建设白皮书 2024_智算中心 架构
- 7机器学习在大数据分析中的自然语言处理
- 8Hive UDF UDTF UDAF 自定义函数详解_hive udaf函数编写
- 9一、Docker部署GitLab(详细步骤)_docker gitlab 重新生成配置
- 10YOLOv9改进策略 :小目标 | 新颖的多尺度前馈网络(MSFN) | 2024年4月最新成果_msfn模块
chatTTS打破人机对话的壁垒 短视频、小说配音营销场景大杀器_chattts 小说
赞
踩
过去我们让AI说话,它给出的总是不咸不淡的机器合成声音,毫无波澜的死板音调让人听得昏昏欲睡。但由于chatTTS的到来,一切都将会变得不一样。作为一款强大的对话式文本转语音模型,它完美解决了用户对于生动对话的需求。如此功能不可小觑,可以称得上在业界一骑绝尘。对于短视频内容创作,有声小说配音,数字营销推广以及日常办公,它都可以成为强有力的助手。此外,该项目还衍生出音色抽卡,长文本推理,角色扮演等功能。
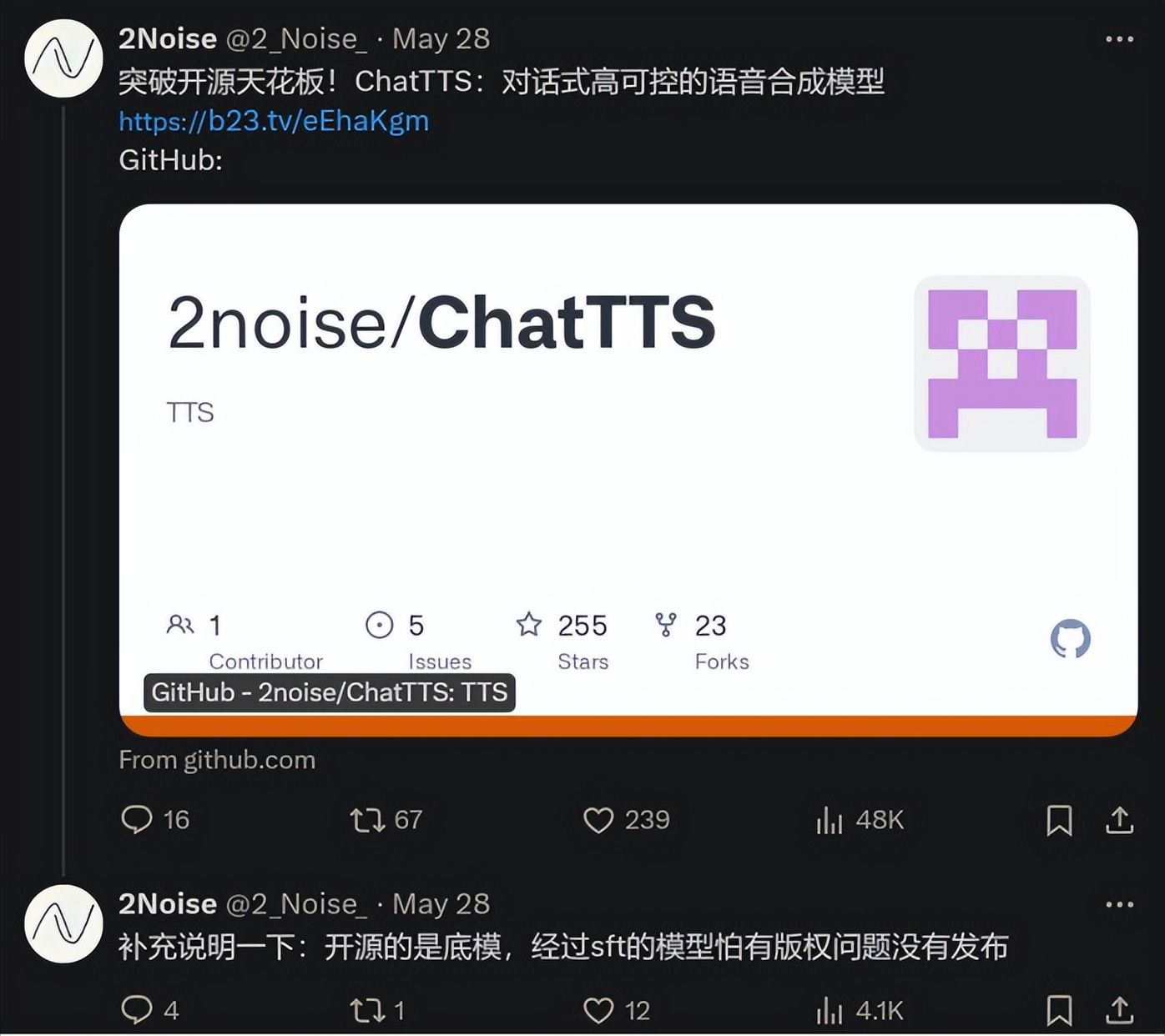
项目简介
ChatTTS由2noise推出,是专门为对话场景设计的文本转语音模型,例如LLM助手对话任务。使用非常简单,只需输入文本和信息,就可以生成相应的语音文件。它同时支持英文和中文,两种语言的发声效果都非常良好,甚至你可以输入中英文混搭的语句,它也能切换自如,轻松驾驭。
ChatTTS的训练量也是十分惊人。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本。
ChatTTS非常适合处理通常分配给大型语言模型LLM的对话框任务。当集成到各种应用程序和服务中时,它可以生成对话响应,并提供更自然、更流畅的交互体验。

核心功能
1. ChatTTS文本转语音
ChatTTS能够生成自然流畅的语音,输入的文本里允许加入笑声 [laugh] 和停顿 [uv_break] 作为韵律标记,可操作性很强。有了这些停顿和语气词等副语言现象,它听起来就像是我们在日常生活中的自然交流。它的发声也是不拘一格,比如你提问四川当地有哪些美食,它给出的回答还会带有一点口音!
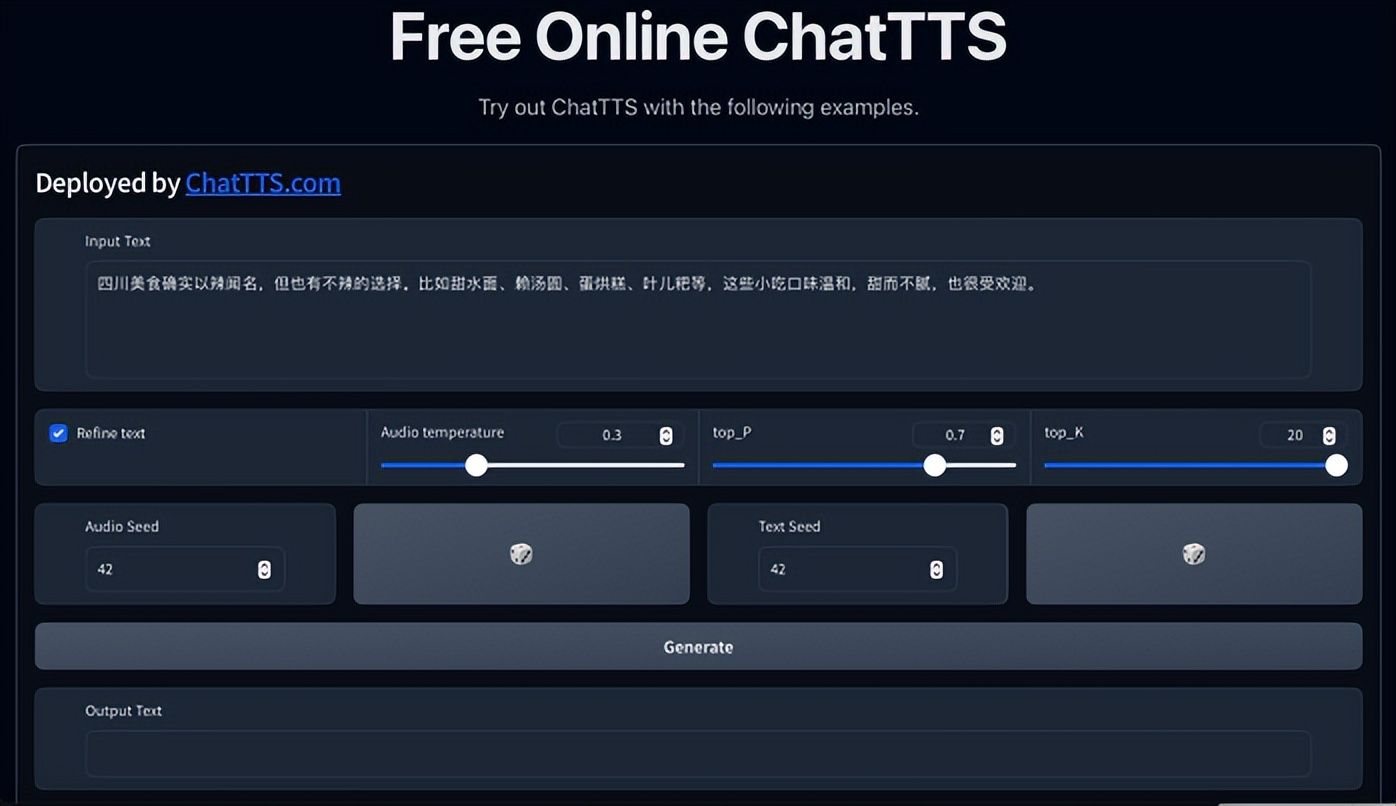
(几个示例https://colab.research.google.com/github/Kedreamix/ChatTTS/blob/main/ChatTTS_infer.ipynb#scrollTo=_xrONBIj9oxo)
如果让它朗读/陈述信息,可以听到音质相当不错,声音清晰饱满,背景噪音较少,语速适中,声调平稳,英文发音颇为地道。。。这简直是广播电台的播音员无疑了!当然,也存在发音词带有吞音之类的问题,不过还是瑕不掩瑜。
如果让它读故事,那听起来真是抑扬顿挫,它时而提升声调突出重点,时而放缓过渡,同时也能处理好断句。
总的来说,ChatTTS针对对话式任务进行了优化,实现了自然流畅的语音合成,同时支持多说话人。生成效果上,不论是语调还是语气的变化,都比较细腻,非常接近真人的说话方式,不会停留在单一的音调上显得生硬。整体上声音很连贯,不会有别扭的感觉。
2.细粒度控制--韵律调整:
该模型能够预测和控制细粒度的韵律特征,包括笑声、停顿和插入词等。前面我们有提到过韵律特征:停顿和笑声,实际上模型有许许多多种韵律的调整,不仅限于文本里常见的附加[uv_break]和[laugh](实际上笑声也有三种,[laugh_0]、[laugh_1]、[laugh_2]),还有[music]、[pure]、[oral_0]、[speed_3]、[Stts]、[Ptts]等,标记处上下文都会受到程度不一的影响,这样可以很好地做到控制情绪的表达而不显突兀。当然,目前运用参数自动地对文本的预处理还是不够精细的,可能还是需要一定的人工处理,不然将会更为理想。
言而总之,这个模型可以精确控制韵律元素包括笑声,停顿和语调等韵律元素。
项目实操
基础用法
import ChatTTS from IPython.display import Audio chat = ChatTTS.Chat() chat.load_models(compile=False) # Set to True for better performance texts = ["PUT YOUR TEXT HERE",] wavs = chat.infer(texts, ) torchaudio.save("output1.wav", torch.from_numpy(wavs[0]), 24000)
进阶用法
说话人生成的主要方法是先从高斯噪声中采样,然后得到一个固定长度的说话人向量,最后作为额外的信息,输入到网络。给出的项目音色本来是不能固定的,但我们可以通过固定随机种子,将音色固定,解决音色过于随机的问题
################################### # Sample a speaker from Gaussian. rand_spk = chat.sample_random_speaker() params_infer_code = { 'spk_emb': rand_spk, # add sampled speaker 'temperature': .3, # using custom temperature 'top_P': 0.7, # top P decode 'top_K': 20, # top K decode } ################################### # For sentence level manual control. # use oral_(0-9), laugh_(0-2), break_(0-7) # to generate special token in text to synthesize. params_refine_text = { 'prompt': '[oral_2][laugh_0][break_6]' } wav = chat.infer(texts, params_refine_text=params_refine_text, params_infer_code=params_infer_code) ################################### # For word level manual control. text = 'What is [uv_break]your favorite english food?[laugh][lbreak]' wav = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code) torchaudio.save("output2.wav", torch.from_numpy(wavs[0]), 24000) 
如有兴趣可以点击以下链接了解更多细节:
https://github.com/2noise/ChatTTS/blob/main/README_CN.md
https://github.com/ultrasev/ChatTTS/blob/master/README.md
https://colab.research.google.com/github/Kedreamix/ChatTTS/blob/main/ChatTTS_infer.ipynb#scrollTo=_xrONBIj9oxo
高性价比GPU资源:https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_tongyong_shemei

