
- 1我的秋招经验分享(研发方向,已拿bat头条网易华为)_华为优先招聘和秋招有啥区别
- 2天池 odps_SQL 常用函数和方法_odps保留两位小数
- 3植物大战僵尸2android最新版,植物大战僵尸2
- 4大数据薪水大概多少_大数据就业岗位有哪些?薪资多少?
- 5vue加载中展示【nprogress(进度条)&Lottie(动画)】_进度条的lottie文件
- 6大数据入门书籍推荐_大数入门是什么书
- 7Apollo 10 — adminService 全量发布
- 8git clone 或者 pod install 出现错误 smudge filter lfs failed Clone succeeded, but checkout failed.
- 9uniapp 微信授权获取用户信息和手机号_uni-app h5 获取微信手机号
- 10Hbase总结,Hbase安装部署,Hbase shell命令_hbase的安装部署与hbase基本操作总结
java面试题梳理_java运维面经
赞
踩
学习前准备,大家一起努力吧!
【钢琴音乐】4小时宫崎骏音乐自习室 | 轻音乐陪你学习
今天有19个小伙伴一起~
以下内容个人整理,如有错误,望请指出,互相学习!
一、面试题1(整理时间:2023.01.31)
面试题内容来自:在看机会的小白很贪玩-南京小米java补录面经
1.java支持多继承么?
java类中不支持多继承,只支持单继承。但java中的接口支持多继承,即一个子类可以拥有多个父接口。接口的主要作用是扩展对象的功能。
更多:java支持多继承么?
2.线程的生命周期
包含5个阶段,新建、就绪、运行、阻塞、死亡。
补充:线程进入运行状态后,一般的操作系统采用抢占式的方式让线程获取CPU。所以CPU需要在多条线程之间来回切换,于是线程状态也在运行、阻塞、就绪之间来回切换。
更多:线程的生命周期
3.线程和进程的区别
根本区别:进程是操作系统进行资源分配的最小单元,线程是操作系统运算调度的最小单元。
线程属于进程,一个进程可能包含多个线程。每个进程都有自己的内存和资源,一个进程中的线程共享这些内存和资源。因此创建、切换、销毁进程的开销远比线程大。
更多:线程和进程的区别
4.单例模式有几种
5种,饿汉模式、懒汉模式、双重锁懒汉模式、静态内部类模式、枚举模式。
饿汉模式:线程安全但是会浪费内存空间。
懒汉模式:线程不安全。
双重锁懒汉模式:线程安全且不会造成内存空间的浪费。
静态内部类模式:线程安全且不会造成内存空间的浪费。
枚举模式:线程安全且不会造成内存空间的浪费。
补充:
一般面试要求会手写双重锁懒汉模式、静态内部类模式这两种模式,其他三种了解即可。
双重锁懒汉模式:
public class SingleTon3 {
private SingleTon3 instance;
private SingleTon3() {
}
public SingleTon3 getInstance() {
if (instance == null) {
synchronized(SingleTon3.class) {
if (instance == null) {
instance = new SingleTon3();
}
}
}
return instance;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
静态内部类模式
public class SingleTon4 {
private SingleTon4() {
}
private static class SingleTonInside {
private static final SingleTon4 INSTANCE = new SingleTon4();
}
public static SingleTon4 getInstance() {
return SingleTonInside.INSTANCE;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
更多:单例模式(五种详解)
5.写一下双重锁的单例
不要觉得题目重复了,这边刚好可以默写下这题。下面这个就是我默写的。
public class SingleTon3 {
private SingleTon3 instance;
private SingleTon3(){
}
public SingleTon3 getInstance() {
if (instance == null) {
synchronized(SingleTon3.class) {
if (instance == null) {
instance = new SingleTon3();
}
}
}
return instance;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
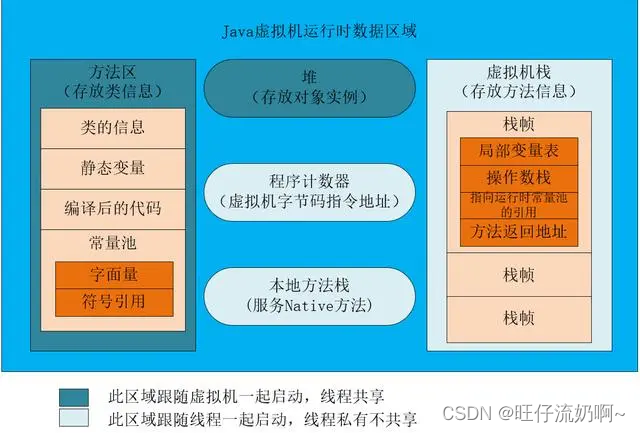
6.jvm有哪些区域?
jvm主要有5大内存区域:方法区、虚拟机栈、堆、程序计数器、本地方法栈。
每个区域的主要功能:
方法区:存放类信息。包括类的信息、静态变量、编译后的代码、常量池、字面量、符号引用等。
虚拟机栈:存放方法信息。由多个栈帧组成,每个栈帧由局部变量表、操作数栈、指向运行时常量池的引用和方法返回地址组成。
堆:存放对象实例。
程序计数器:虚拟机字节码指令地址。
本地方法栈:服务Native方法。
jvm的分区可以分为两种:线程私有的内存区和线程共享的内存区。
线程共享的内存区域:方法区、堆。
线程私有的内存区域:程序计数器、本地方法栈、虚拟机栈。
以上内容可根据以下图片自行梳理!
更多:
JVM中的五大内存区域划分详解及快速扫盲
JVM有哪些分区?
7.jvm哪些区域是线程共享的,哪些是线程私有的?
复习下上一题。
线程共享的区域有:方法区、堆。
线程私有的区域有:程序计数器、本地方法栈、虚拟机栈。
8.gc中判断对象可回收的方式有哪些?
有两种。
1.引用计数器:每个对象都有一个属性,用于记录被引用的次数,当前对象被引用一次该值+1,引用被释放该值-1,若该值为0,则可以判定该对象可以被回收。
2.可达性分析:从GC Roots作为起点向下进行搜索,搜索所走过的路径称为引用链,当一个对象到GC Roots没有任何引用链时,则证明该对象是不可用的,虚拟机则可以判断该对象是可以被回收的。
更多:
Gc如何判断对象可以被回收?
GC如何判断对象可以被回收
9.gc垃圾回收算法有哪些?
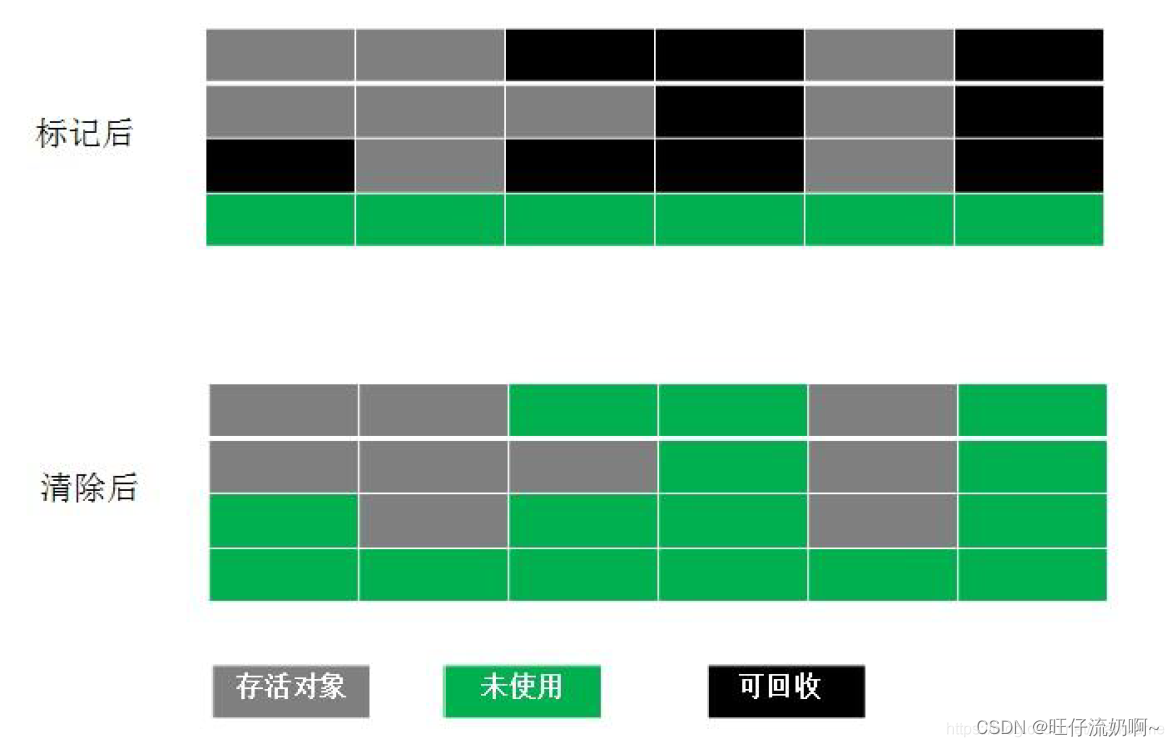
1.标记清除算法
==》最基础的垃圾回收算法,分标记和清除两个步骤。
顾名思义,先标记需要清除的内存块,然后一块一块清除标记内存块。
缺点:算法效率低,会产生较多内存碎片,可能会导致大对象无法存储问题。
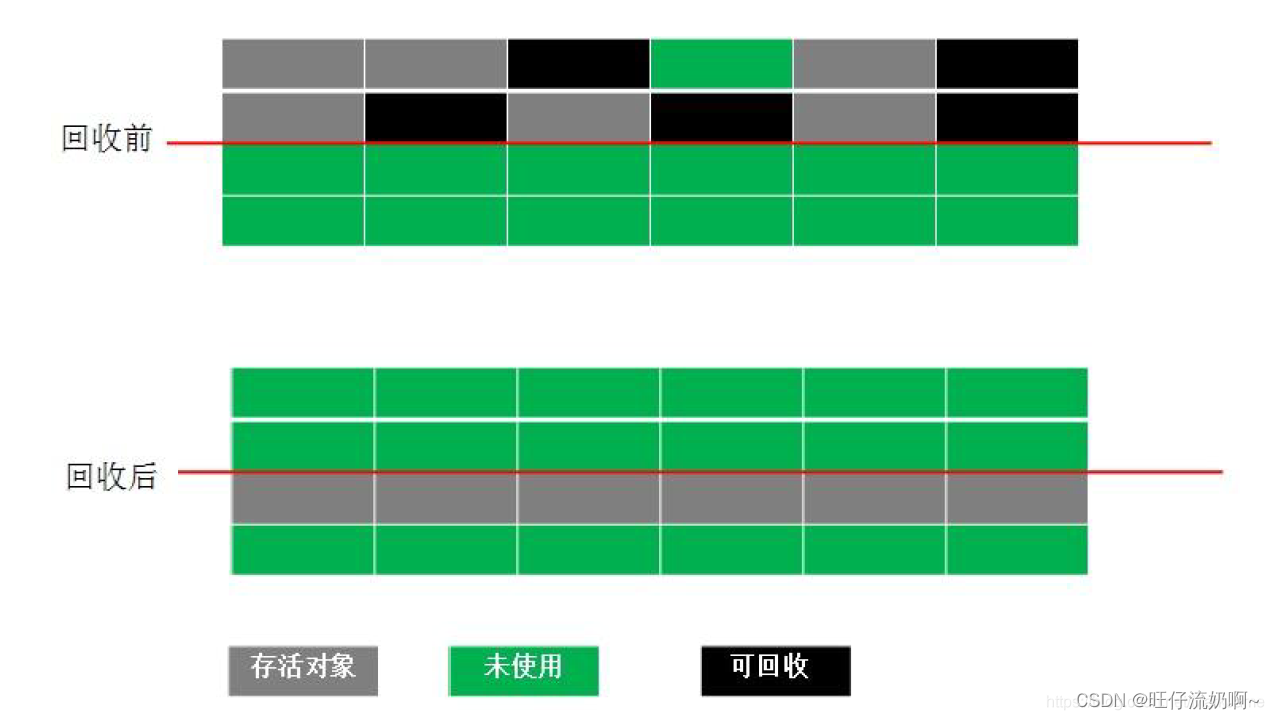
2.复制算法
==》顾名思义就是将内存空间划分成两块大小相同的区域,当其中一块区域需要进行垃圾回收时,先将这块区域存活对象渎职到另一块区域,再将剩余已使用的区域回收掉。
优点:实现简单,算法效率高,不易产生内存碎片。
缺点:总的内存空间被压缩一半。
3.标记整理算法
==》顾名思义,分标记和整理两个步骤。该算法结合了标记清除算法和复制算法。标记阶段和标记清除算法一致,整理阶段先将存活的内存块移到一段,清除回收边界外的内存区域。
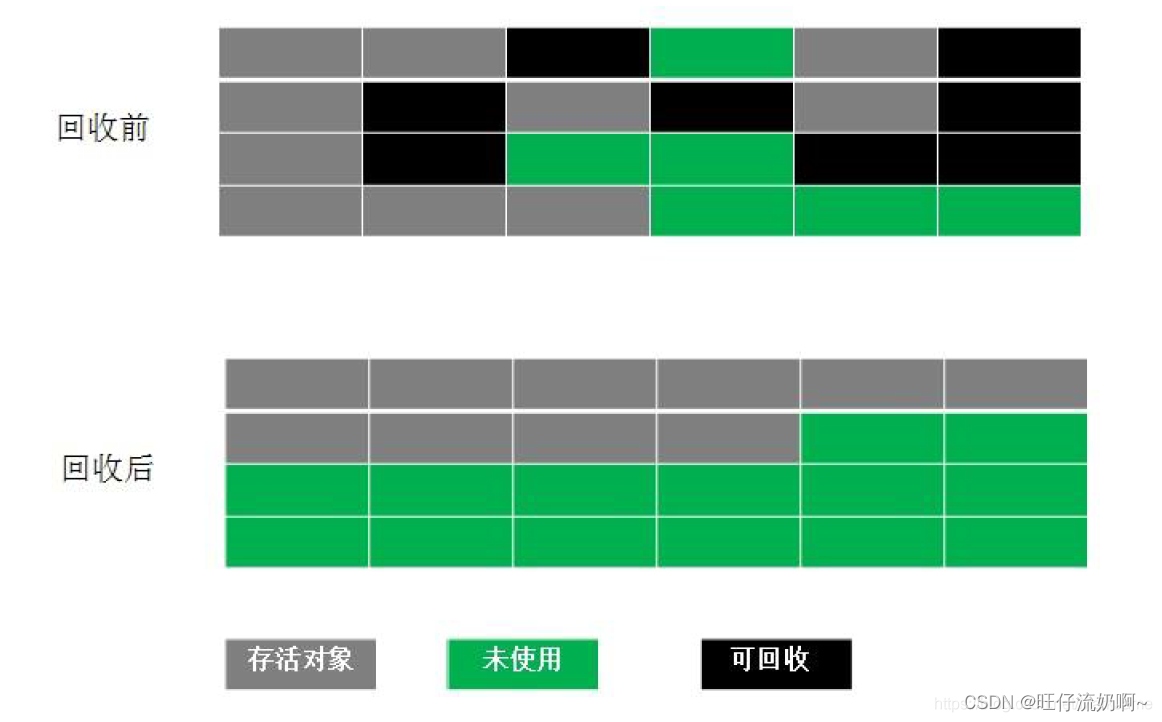
4.分代收集算法
==》目前jvm大部分采用的都是分代收集算法,是根据对象存活的不同生命周期将内存划分为不同的存储区域。
主要将GC堆内存划分为新生代(Young Generation)和老年代(Tenured/Old Generation)。新生代的特点是每次垃圾回收都要大量垃圾被回收,采用的是复制算法;老年代的特点是每次进行垃圾回收时只有少数对象需要回收。

回顾一下,垃圾回收算法主要有哪些?(大致是怎么处理的,自行脑图补充)
主要有4种,标记删除算法、复制算法、标记整理算法、分代收集算法。
更多:GC 垃圾回收算法
10.哪些对象可以作为gc root?
总共有4种(那张图,从左到右回忆下,有哪几块区域,末尾+...引用的对象)。
1.方法区中的类静态属性引用的对象(一般指static修饰的对象,在类加载的时候就被加载到内存中)。
2.方法区中的常量引用的对象(final修饰的)。
3.本地方法栈中的JNI(native方法)引用的对象。
4.虚拟机栈中引用的对象。
11.gc中的引用计数法有哪些缺陷?
引用计数法最大的缺陷就是其循环引用问题。例如对象A引用了对象B,对象B又引用了对象A,此时两者的引用计数值都不为0 ,虽然这两个对象在虚拟机中都是无用对象,但是由于其计数值不为0导致对象无法被垃圾回收,进而导致内存泄露问题。
更多:
引用计数法的原理和优缺点
面经复盘系列之「Java GC中使用引用计数法所存在的缺点」问题应该如何去思考
12.抽象类和接口的区别?
接口可以支持多继承;抽象类只支持单继承。
接口是一组行为规范;抽象类是一个不完全的类,着重族的概念。
接口只能定义抽象规则;抽象类不仅可以定义抽象规则,还能提供已实现的成员。
更多:
抽象类和接口的区别
13.sleep和wait的区别?
sleep和wait方法都可以让线程进入休眠状态,并且它们都可以响应intercept中断,不同点在于:语法使用不同、所属类不同、唤醒方式不同、释放锁资源不同和线程进入的状态不同。
补充:
语法使用不同:wait方法需要配合synchronized关键字使用,否则会报错;而sleep不需要。
所属类不同:wait方法属于Object类;sleep方法属于Thread类。
唤醒方式不同:wait方法需要使用notify或notifyAll方法唤醒;sleep方法在指定时间内会自动唤醒。
释放锁资源不同:wait方法由于不确定休眠时间多少,进入休眠的时候便会释放锁;sleep方法在休眠期间会一直占用着锁,直到休眠结束。
线程进入的状态不同:wait方法休眠的时候是处于WATING一直等待状态;sleep休眠有时间限制,处于TIMED_WATING状态。
14.浏览器中的一个网址如何去返回给你的界面?在网络中经历了什么?
总共经历了8个步骤。
1.输入网址。
2.DNS解析域名获取到对应的IP地址。
3.web浏览器向对应IP地址服务器建立TCP连接。
4.web浏览器向web服务器发送HTTP请求。
5.服务器的永久重定向请求。
6.web服务器作出应答。
7.浏览器显示HTML页面。
8.web服务关闭TCP连接。
15.springboot的依赖注入是什么?
控制反转是一种思想,将原本耦合的两个类进行松耦合,实例化操作的控制权交由第三方IOC处理,依赖注入就是最典型的实现方法,把它通过构造函数、属性或者工厂模式等方法注入到所依赖的类中。
更多:
【springboot】什么是依赖注入
22 springboot依赖注入三种方式
简单理解springboot的依赖注入
16.springboot的自动装载是如何实现的?
自动装配的入口是复合注解@SpringBootApplication注解,它主要由以下三个注解组成:
@SpringBootConfiguration@EnableAutoConfiguration@ComponentScan
配置步骤如下:
@SpringBootConfiguration注解的作用是将配置了@Configuration注解的类加载到IOC容器中。@ComponentScan注解的作用是扫描指定路径下带有形如@Controller、@Service、@Component、@Repository等的类,自动装配到spring的IOC容器里面。@EnableAutoConfiguration注解的作用是扫描MATE-INF下面的spring-autoconfiguration-matedata.properties和spring.factories文件最后进行合并,判断哪些组件需要注入,进行动态条件生成,判断哪些组件不需要注入IOC容器。
更多:
面试题:SpringBoot 的自动装配是怎样实现的?
17.juc中的类了解哪些?
1.ReentrantLock 可重入锁(所谓可重入锁,指的是一个线程可以对共享资源进行多次加锁)
2.Semaphore 信号量
3.CountDownLatch 计数器
4.CyclicBarrier 循环屏障
更多:JUC包下的常见类
18.spring中bean的生命周期?
Bean的生命周期主要包含四个阶段:实例化Bean、Bean属性初始化、初始化Bean、销毁Bean。
更多:
Spring中bean的生命周期
19.用过线程池么?说下线程池常用的参数?
线程池的7大参数。
1.核心线程数 corePoolSize
2.最大线程数 maximumPoolSize
3.空闲线程存活时间 keepAliveTime
4.时间单位 TimeUnit
5.阻塞队列 BlockingQueue
6.创建线程的工厂 ThreadFactory
7.拒绝策略 RejectedExecutionHandler
补充:
使用线程池的好处:线程复用、可以控制线程最大并发数、管理线程。
线程池必会内容:3大方法、7大参数、4种拒绝策略。
创建线程池的3大方法:
// 单个线程的线程池
ExecutorService service1 = Executors.newSingleThreadExecutor();
// 固定线程数的线程池
ExecutorService service2 = Executors.newFixedThreadPool(5);
// 可伸缩的线程池
ExecutorService service3 = Executors.newCachedThreadPool();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
线程池的4种拒绝策略:
// 队列满了,不处理请求,直接抛异常
ThreadPoolExecutor.AbortPolicy abortPolicy = new ThreadPoolExecutor.AbortPolicy();
// 谁是调用创建一个新线程,返回给谁处理
ThreadPoolExecutor.CallerRunsPolicy callerRunsPolicy = new ThreadPoolExecutor.CallerRunsPolicy();
// 队列满了,丢掉任务,不会抛异常
ThreadPoolExecutor.DiscardPolicy discardPolicy = new ThreadPoolExecutor.DiscardPolicy();
// 队列满了,尝试和最早的竞争,不会抛异常
ThreadPoolExecutor.DiscardOldestPolicy discardOldestPolicy = new ThreadPoolExecutor.DiscardOldestPolicy();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
什么叫拒绝策略?
是当所有可用线程(最大线程池大小)都在执行且阻塞队列也满了,对于再进入线程池的线程(任务)的处理即拒绝策略。
【强制】 线程池不允许作用Executor()去创建,而是通过ThreadPoolExecutor的方式。这样
的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险(就是避免出现OOM问题)。
更多:线程池7个参数描述
20.mysql的底层是什么?b树结构是什么?
mysql的底层是B+树。B树是一种平衡的多分树。
更多:
B树、B+树详解
21.mysql执行一条select语句是如何执行的?
在客户端已连接MySQL服务端的情况下,
首先会进行权限管理校验,判断当前连接用户是否具有访问当前库表的操作权限;
确定具有访问权限时,如果开启了查询缓存,优先查询缓存数据,当命中缓存时会直接返回数据(由于历史查询的结果以键值对的形式缓存存储在内存中,以查询语句作为key,查询结果作为value);
未命中缓存时,就会进入分析器,进行词法、语法分析,过滤掉不符合规范的查询操作;
接着进入优化器,生成执行计划,选择要执行的索引,就是选择出最高效的查询方式;
最后进入执行器,调用执行引擎,返回结果数据。
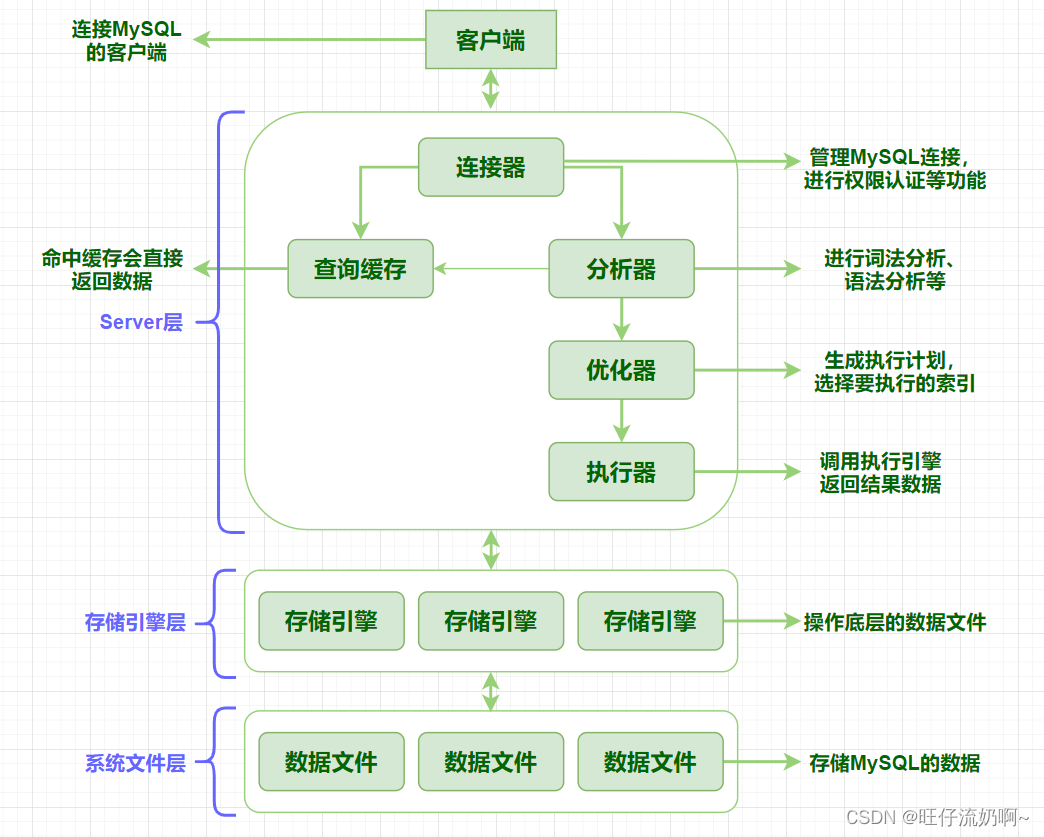
更多:原来 select 语句在 MySQL 中是这样执行的!看完又涨见识了!这回我要碾压面试官!
22.mysql如何调优?
sql的优化主要分为四层,
1、业务上的优化
数据量多时,优先考虑分库分表、集群处理。
2、代码层的优化
如果连表查询比较多,建索引已经效果不太明显了,这时候可以代码层面做优化,拆分成两个SQL,查询出来数据做拼装。
3、sql层面的优化(包含索引优化)
最简单最直接的就是创建联合索引,减少回表。
4、硬件层面的优化(硬件层优化其实都是运维处理,我们这边了解有这层就好)
最后总结一些常见的SQL优化规则:
1、SQL的查询一定要基于索引来进行数据扫描。
2、避免索引列上使用函数或者运算符,这样会导致索引失效。
3、where字句中的like %号尽量放置在右边。
4、使用索引扫描联合索引中的列,从左到右,命中越多越好。
5、尽可能使用SQL语句用到的索引完成排序,避免使用文件排序的方式。
6、查询有效的列信息即可,少用*代替列信息,避免回表查询。
7、永远用小的结果集驱动大的结果集。
更多:
(全网讲的最好)面试被问到mysql调优如何回答
高频面试题:关于MySQL性能优化,这么回答分分钟拿下高薪offer!【Java面试】
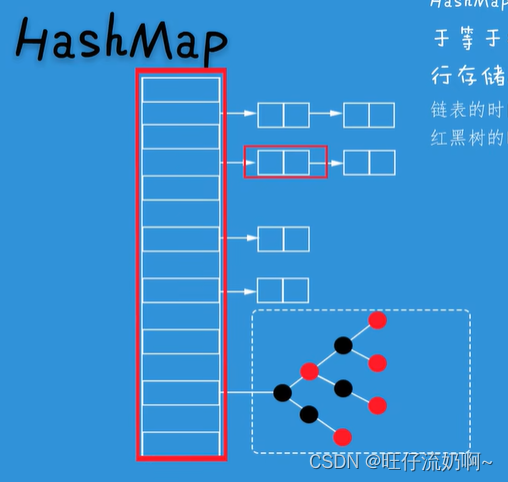
23.HashMap底层是如何实现的?
HashMap采用了数组+链表+红黑树的存储结构(jdk1.8)。
HashMap数组部分称为哈希桶。当数组长度大于等64且链表长度大于等于8时,链表数据将以红黑树的形式进行存储,当长度降到6时,转成链表。
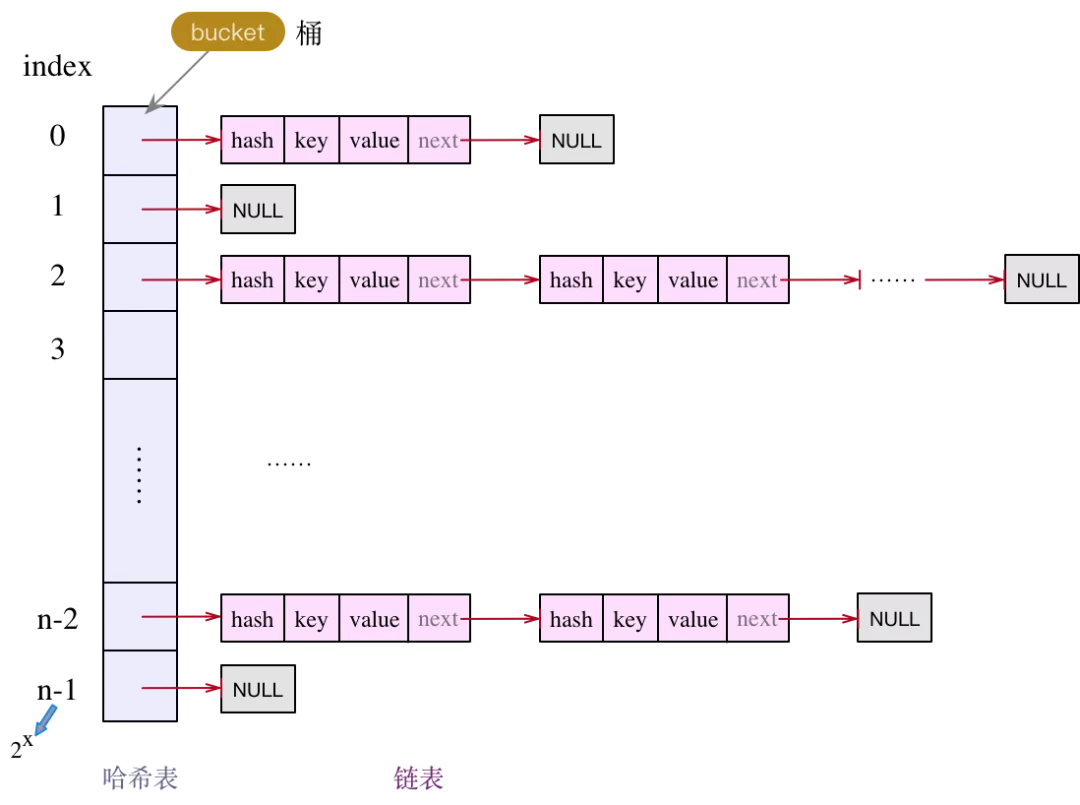
每个Node节点存储着用来定位数据索引位置的hash值,k键,v值以及指向链表下一个节点的Node<k,v> next节点组成。Node是HashMap的内部类,实现了Map.Entry接口,本质是一个键值对。
补充:
HashMap是基于哈希表对Map接口的实现,HashMap具有较快的访问速度,但是遍历顺序却是不确定的。HashMap提供所有可选的映射操作,并允许使用null值和null键。HashMap并非线程安全,当存在多个线程同时写入HashMap时,可能会导致数据不一致。
loadFactor称为负载因子,默认为0.75;
threshold表示所能容纳的键值对的临界值,threshold的计算公式为:数组长度 * 负载因子;
size是HashMap中实际存在的键值对数量;
modCount字段用来记录HashMap内部结构发生变化的次数;
HashMap默认容量INITIAL_CAPACITY为16。
例如:
size=8,loadFactor=0.75,length=16,threshold=12 =》16 * 0.75;
size=14,loadFactor=0.75,length=32,threshold=24 =》32 * 0.75;
更多:
HashMap底层实现原理概述
【Java源码精选】3分钟轻松理解HashMap原理 面试不再下饭
24.redis有哪几种数据类型?
redis有5种数据类型,String字符串、Hash哈希、List列表、Set集合以及ZSet有序集合。
25.redis如何实现分布式锁?
26.线程池最大线程数该怎么定义?
分两种。
1)CPU密集型。几核就是几,可以保持CPU的效率最高。
通过程序获取方式:
Runtime.getRuntime().availableProcessors();
- 1
2)IO密集型。判断程序中比较消耗CPU的IO线程,该值即为线程池最大线程数。
27.四大函数式接口
新时代程序员:lambda表达式、链式编程、函数式接口、Stream流式计算。
1.Function函数型接口:传入参数为T,返回参数为R。
// 原版本
Function<String, String> function = new Function<String, String>() {
@Override
public String apply(String s) {
return s;
}
};
// 简化版
Function<String, String> function1 = (str) -> str;
// 调用
System.out.println(function1.apply("zwd"));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
2.Predicate断定型接口:传入泛型返回boolean类型。
// 原版
Predicate<String> predicate = new Predicate<String>() {
@Override
public boolean test(String s) {
return s.isEmpty();
}
};
// 简化版
Predicate<String> predicate1 = (str) -> str.isEmpty();
// 测试
System.out.println(predicate1.test("zwd"));
System.out.println(predicate1.test(""));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
3.消费者型接口:只有输入没有返回值。
// 原始版
Consumer<String> consumer = new Consumer<String>() {
@Override
public void accept(String s) {
System.out.println(s + ",你好~");
}
};
// 精简版
Consumer<String> consumer1 = (str) -> System.out.println(str + ",你好~");
// 测试
consumer1.accept("zwd");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
4.供给型接口:没有参数,只有返回值类型(泛型)。
// 原版本
Supplier supplier = new Supplier() {
@Override
public Object get() {
return "zwd";
}
};
// 简化版
Supplier supplier1 = () -> "zwd";
// 测试
System.out.println(supplier1.get());
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
28.java中线程实现的方式?
java中线程实现的方式有4种,
1、继承Thread类,重写run方法。
2、实现Runnable接口,重写run方法。
3、实现Callable接口,重写call方法,配个FutureTask使用。
4、基于线程池创建。
究其底层都是基于Runnable接口实现。
package zwd.demo.threadtest; import java.util.concurrent.*; /** * @Description 线程创建的4种方式 * 1、继承Thread类,重写run方法 * 2、实现Runnable接口,重写run方法 * 3、实现Callable接口,重写call方法,配合FutureTask使用 * 4、基于线程池构建 * 究其底层都是基于Runnable接口实现。 * @Author zhengwd * @Date 2023/2/12 10:07 **/ public class FourThreadTest { public static void main(String[] args) throws ExecutionException, InterruptedException { // 1、继承Thread类,重写run方法 // ExtendThread extendThread = new ExtendThread(); // extendThread.start(); // 2、实现Runnable接口,重写run方法 // ImRunnable imRunnable = new ImRunnable(); // new Thread(imRunnable).start(); // 3、实现Callable接口,重写call方法,配合FutureTask使用 // CallThread callThread = new CallThread(); // FutureTask futureTask = new FutureTask(callThread); // new Thread(futureTask).start(); // // 做一些操作 // Object count = futureTask.get(); // System.out.println("总和为:" + count); // 4、基于线程池去构建 ThreadPoolExecutor threadPoolExecutor = new ThreadPoolExecutor( 3, 5, 10, TimeUnit.SECONDS, new LinkedBlockingQueue<>(3), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); threadPoolExecutor.execute(() -> System.out.println("基于线程池去构建的线程")); threadPoolExecutor.shutdown(); } } class CallThread implements Callable { @Override public Object call() throws Exception { int count = 0; for (int i = 0; i < 50; i++) { count += i; } return count; } } class ExtendThread extends Thread { @Override public void run() { System.out.println("ExtendThread run..."); } } class ImRunnable implements Runnable { @Override public void run() { System.out.println("ImRunnable run..."); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
29.java中线程的状态?
java源码中有6种线程状态,NEW-新建状态,RUNNABLE-运行/就绪状态,BLOCKED-阻塞状态,WATING-等待状态,TIMED_WATING时间等待状态,TERMINATED-结束状态。
补充:
NEW状态:Thread对象被创建,还没有执行start方法。
RUNNABLE状态:Thread对象调用了,start方法。
BLOCKED状态:synchronized没有拿到资源,被放到EntryList中阻塞。
WATING状态:Thread对象调用了wait方法。
TIMED_WATING状态:Thread对象调用了sleep或join方法。
TERMINATED状态:线程结束。
PS小写:new、runnable、blocked、wating、timed_wating、terminated。
package zwd.demo.threadtest; /** * @Description * #### 29.java中线程的状态? * java源码中有6种线程状态,NEW-新建状态,RUNNABLE-运行/就绪状态,BLOCKED-阻塞状态,WATING-等待状态,TIMED_WATING时间等待状态,TERMINATED-结束状态。 * * 补充: * NEW状态:Thread对象被创建,还没有执行start方法。 * RUNNABLE状态:Thread对象调用了,start方法。 * BLOCKED状态:synchronized没有拿到资源,被放到EntryList中阻塞。 * WATING状态:Thread对象调用了wait方法。 * TIMED_WATING状态:Thread对象调用了sleep或join方法。 * TERMINATED状态:线程结束。 * * PS小写:new、runnable、blocked、wating、timed_wating、terminated。 * @Author zhengwd * @Date 2023/2/12 21:06 **/ public class ThreadStateTest { public static void main(String[] args) throws Exception { // NEW状态 // Thread thread = new Thread(() -> System.out.println("zwd")); // System.out.println(thread.getState()); // RUNNABLE状态 // Thread thread = new Thread(() ->{ // while (true) { // System.out.println("线程运行中..."); // } // }); // thread.start(); // Thread.sleep(500); // System.out.println(thread.getState()); // BLOCKED状态 // Object obj = new Object(); // Thread thread = new Thread(() ->{ // // thread线程拿不到obj的锁资源,导致变为BLOCKED状态 // synchronized (obj) { // System.out.println("thread线程执行...."); // } // }); // // main主线程拿到obj的锁资源 // synchronized (obj) { // thread.start(); // Thread.sleep(500); // System.out.println(thread.getState()); // } // WATING状态 // Object obj = new Object(); // Thread thread = new Thread(() ->{ // synchronized (obj) { // try { // obj.wait(); // } catch (InterruptedException e) { // e.printStackTrace(); // } // } // }); // thread.start(); // Thread.sleep(500); // System.out.println(thread.getState()); // TIMED_WATING状态 // Object obj = new Object(); // Thread thread = new Thread(() ->{ // synchronized (obj) { // try { // Thread.sleep(1000); // } catch (InterruptedException e) { // e.printStackTrace(); // } // } // }); // thread.start(); // Thread.sleep(500); // System.out.println(thread.getState()); // TERMINATED状态 Thread thread = new Thread(() ->{ try { Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } }); thread.start(); Thread.sleep(1000); System.out.println(thread.getState()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
30.java中如何停止线程?
线程结束的方式有很多,最常用的就是让线程的run方法结束,无论是return结束还是抛出异常,都可以。
1、stop方法。强制结束线程,无论线程当前是否有在执行任务。太过暴力,不建议使用。
2、使用共享变量(很少会用)。
3、使用inertrupt方法。
package zwd.demo.threadtest; /** * @Description * #### 30.java中如何停止线程? * 线程结束的方式有很多,最常用的就是让线程的run方法结束,无论是return结束还是抛出异常,都可以。 * 1、stop方法。强制结束线程,无论线程当前是否有在执行任务。太过暴力,`不建议使用`。 * 2、使用共享变量(`很少会用`)。 * 3、使用inertrupt方法。 * @Author zhengwd * @Date 2023/2/12 21:40 **/ public class StopThreadTest { static volatile boolean flag = true; public static void main(String[] args) throws InterruptedException { // 1、stop方法。强制结束线程,无论线程当前是否有在执行任务。 Thread t1 = new Thread(() ->{ while (flag) { // 线程执行任务 } }); t1.start(); Thread.sleep(500); t1.stop(); System.out.println("任务强制结束"); // 2、使用共享变量(`很少会用`) 通过修改共享变量,破坏死循环,结束线程run方法 // Thread t1 = new Thread(() ->{ // while (flag) { // // 线程执行任务 // } // System.out.println("任务结束"); // }); // t1.start(); // Thread.sleep(500); // flag = false; // 3、使用inertrupt方法 线程默认情况下,interrupt标记位:false // System.out.println(Thread.currentThread().isInterrupted()); // // 执行interrupt之后,再次查看标记位 // Thread.currentThread().interrupt(); // // interrupt标记位:true // System.out.println(Thread.currentThread().isInterrupted()); // // 返回当前线程interrupt标记位true,并归位为false // System.out.println(Thread.interrupted()); // // 再次查询,发现已经归位为false // System.out.println(Thread.interrupted()); // Thread thread = new Thread(() -> { // while (!Thread.currentThread().isInterrupted()) { // // 处理业务 // } // System.out.println(Thread.currentThread().isInterrupted()); // System.out.println("thread结束..."); // }); // // interrupt标记位false // System.out.println(Thread.currentThread().isInterrupted()); // thread.start(); // Thread.sleep(500); // thread.interrupt(); // // interrupt归位,标记位还原为默认true // Thread.interrupted(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
31.MySQL中的LIKE查询能否用的到索引?
单值索引使用like x%时会用到索引,使用like %x或like %x%时不会用到索引。
联合索引使用like x%、like %x、like %x%查询且x为联合索引的第一个参数时,都会用到索引。但是like %x、like %x%虽然用到了索引,却会遍历整棵索引B+树,过滤出满足条件的数据。

