
- 1昇思25天学习打卡营第2天|张量Tensor
- 2Linux中的超级用户是谁?底层原理是什么?_linux 超级用户
- 3连接Sql Server时报错-无法通过使用安全套接字层加密与 SQL Server 建立安全连接_“encrypt”属性设置为“false”且 “trustservercertificate”属性设
- 4微软云计算Windows Azure(一)_window azure平台包括四个组成部分,其中云计算操作系统是
- 53 天,入门 TAURI 并开发一个跨平台 ChatGPT 客户端
- 6Ovirt 基本介绍
- 7图像篡改及防篡改_java opencv 图片识别篡改
- 8【学习笔记】鸿蒙应用开发工具 HUAWEI DevEco Studio_huawei previewer.exe 怎么用
- 9shell脚本报错:-bash: xxx: /bin/bash^M: bad interpreter: No such file or directory_-bash: keytool -importcert -keystore 没有那个文件或目录
- 10深度学习的强化学习:从人工智能到自主行动
技术前沿|Spark 3.3.0 中 DS V2 Push-down 的重构与新特性_spark limit pushdown
赞
踩
本文作者耿嘉安,畅销书《深入理解 Spark》和《Spark 内核设计的艺术》作者,Apache Spark Contributor,15 年 IT 经验的 Kyligence 高级性能工程师。
近日 Apache Spark 3.3.0 正式发布。在本文中,作者将对 Spark 3.2 DS V2 Push-down 框架进行深入分析,并分享 Kyligence 开源团队是如何在 Spark 3.3.0 中完成对 DS V2 Push-down 的重构与改进的,欢迎大家在评论区分享你的看法。
I. 引言
Spark 自正式开源以来,已到了第十个年头。如今,这样一款优秀的分布式大数据计算框架早已在国内获得普遍使用。笔者是在 Spark 1.2.0 版本时开始接触它,已有近八年时光。最初,广大用户主要将它作为“大数据 2.0”的新生儿看待,用来解决“大数据 1.0”批处理技术的不足。其实,这里所谓的 1.0 或者 2.0 都只是国内玩家创造的衍生物,甚至也有提出“大数据 3.0”。至于什么是 1.0,2.0 甚至 3.0,其实并没有什么严格的定义,更多的是商业战略。究竟什么才是 2.0 或是 3.0,交给后人评说更为恰当。
一开始,国内技术公司寄希望于 Spark,希望它能解决实时、流计算、批处理,更不用说什么数据异构、数据规模、分布式等问题。国内技术公司跟 Spark 磨合了很多年,发现它并没有像人们所说的那么符合期待。再加上其他大数据技术的异军突起,使得 Spark 的应用场景发生了很多变化。Spark 依然是批处理中加速 Hadoop 生态的产品,甚至也转变为其他大数据技术的底层引擎。越来越多的用户希望 Spark 不仅仅解决 Hadoop 生态的问题,于是 Spark 除了遵循 ANSI SQL 标准,也对 Parquet、Orc、Avro 等数据格式,对 SnowFlake、PostgreSQL、Teradata 等厂商做了更多的兼容。既然 Spark 支持了越来越多的数据源,那么对 Spark 的基本要求就是计算效率不能比数据源本身的计算效率低。
实际上,Spark 在一开始接入各种数据源都是通过早期提供的数据源 Connector 来完成的。Connector 可以作为 Plugin 接入 Spark 早期的批处理计算中,这种方式在当时以非常快速的方式让 Spark 在大数据生态中立足。但是批处理计算的过程,需要将数据源数据拉取到 Executor 本地,然后再进行计算。计算过程中如果产生了 Shuffle,那么写入磁盘的 Shuffle 数据也会很多,导致对网络传输有更高要求。
因此,批处理的方式未必是对数据源数据进行计算的最好方式——最典型的例子莫过数据流。当然,早期的 Spark 依然用批处理的经典理论来解决数据流的问题。为了一定程度解决数据延迟的问题,引入了“微批”。但是这种方式毕竟违背了数据流提供方的最初意愿,于是 Spark 渐渐开始解决数据流的实时处理问题,不得不舍弃批处理的一些樊笼。除此之外,Spark 对于其他数据源采用批处理的方式也是不适当的,笔者对这一点就深有感触。例如:一条 SQL 在 MySQL 中执行只需要几百毫秒,但是 Spark 却需要几十分钟。笔者最初遇到这种情况时,是通过魔改 Spark 算子的方式解决的。这种方式当然不值得提倡,但是迫于生产的需要,这是最快解决问题的方式。
随着 Spark 2.4.0 的发布,我们发现越来越多的数据源正在努力向 Spark 社区贡献将查询下推到数据源的能力。例如:Parquet 和 Orc 的 Filter 下推。Spark 3.0.0 发布了 Catalog Plugin API,这套 API 的设计比老的 Connector 更加高明,用户可以实现更加丰富的内容,比如:Catalog 和 Table。用户可以在此基础上实现更加自定义的物理行为。Spark 3.1.0 和 Spark 3.2.0 又陆续提供了列裁剪、Filter 下推、Aggregate 下推等可以影响物理执行的功能。在这里我们下一个定义——所有基于 Catalog Plugin API 的东西我们简单称其为 DS V2;基于 DS V2 实现的下推,我们简单称其为 DS V2 Push-down。
由于 Spark 之前版本提供的 DS V2 Push-down 有各种功能上的不足,因此 Kyligence 着力向 Spark 社区持续推动对它的改进。下面先来看看 DS V2 Push-down 在 Spark 3.2.0 版本时的情况。
II. Spark 3.2 DS V2 Push-down
Spark 3.2 DS V2 Push-down 的最根本能力需要影响 Spark 的物理计划,所有这一切发生在 V2ScanRelationPushDown 这个优化器规则中。
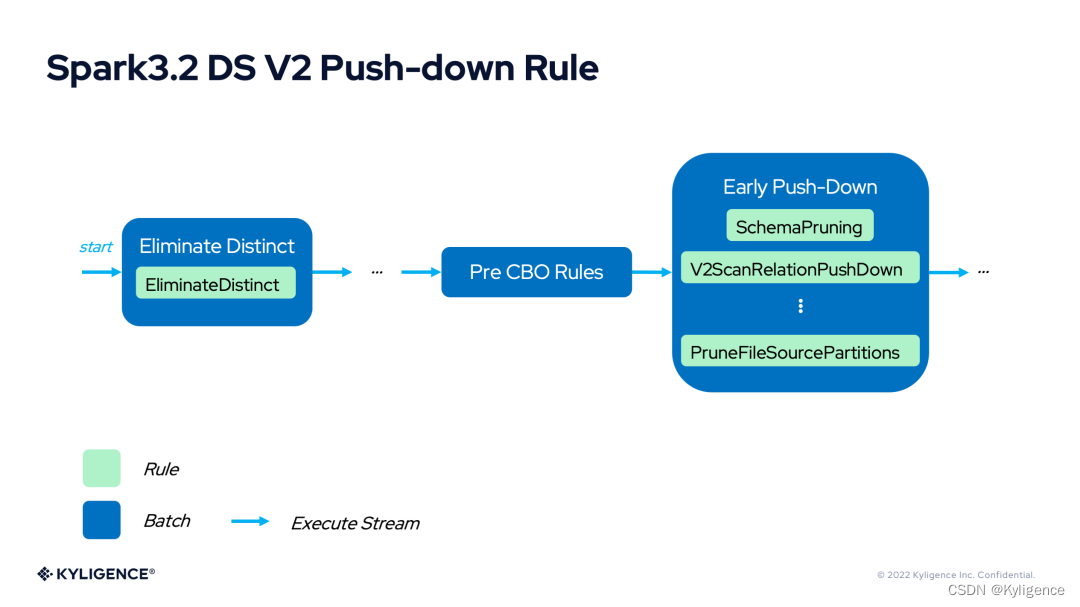
这个规则可以完成对列裁剪、Filter 下推、Aggregate 下推等功能的支持。下面对下推相关的功能进行简单介绍。
1. Spark 3.2 DS V2 Filter Push-down
Filter 下推干的事情很简单(为了行文方便,这里以 JDBC 数据源为例,后文不再赘述),那就是把 Filter 的计算交给数据源。因为数据源最清楚数据的结构、数据的分布、数据的索引还有缓存等信息,,因此数据源计算往往有最优的方案来处理。

上图是 Filter 下推的示意图。细心的读者会发现 WHERE 条件中多了id IS NOT NULL,这里额外做个说明——这是 Spark 对执行计划优化过程中添加的 Filter。所以真正下推到数据源的 SQL 未必是用户输入的原始 SQL。
既然 Filter 由数据源计算了,那么 Spark 就可以避免这些计算。更重要的是,可以减少磁盘 I/O 和网络 I/O,甚至减少 Spark Shuffle 的数据量。原先可能需要读取一张表所有的数据文件,现在数据源也许只需要读取几个文件,甚至不用读取数据了。Spark 得到了数据源返回的已经执行过 Filter 的数据后,再进行其他计算的初始数据量会有明显的下降,这对于整个 Spark Job 的生命周期都是有效的。
不过,Spark 在实现 Filter 下推的时候,用到的是 DS V1 的 Filter 表达式。DS V1 的 Filter 表达式有个缺陷,那就是只能表示基本的 Filter 表达式,无法表达复杂表达式。

例如,上图中的id IS NOT NULL和id > 1是 DS V1 的 Filter 能够表达的,但是cast(col as int) IS NOT NULL和cast(col as int) > 1却是不行的。这会对最终的 Filter 下推产生影响,请看下图。
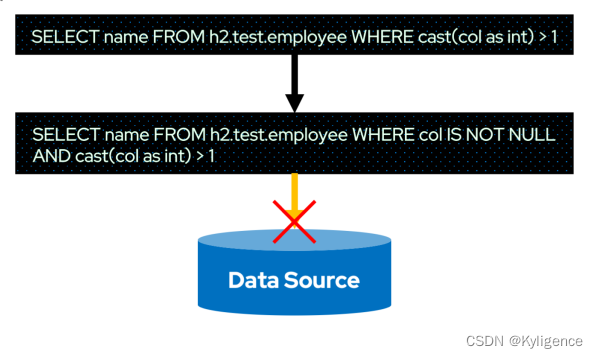
上图中的 Cast 表达式与比较表达式组成的复杂表达式,DS V1 的 Filter 表达式就无法表达。虽然cast(col as int) > 1无法下推,但是col IS NOT NULL依然是可以下推的。

具体的办法就是col IS NOT NULL交给数据源处理,而cast(col as int) > 1依然由 Spark 的 Filter 算子计算。其结果是显而易见的——大量业务场景中使用的WHERE条件都无法下推,因而无法有效减少 I/O。因此,Spark 3.2 时的 DS V2 Filter Push-down 很难在生产环境发挥作用。
2. Spark 3.2 DS V2 Aggregate Push-down
Aggregate 下推是将 Aggregate 的计算交给数据源。例如,SUM(SALARY)由数据源计算。同样因为数据源最清楚数据的结构、数据的分布、数据的索引还有缓存等信息,因此数据源计算往往有最优的方案来处理。

上图是 Aggregate 下推的示意图。细心的读者会发现,聚合既然已经下推到数据源计算了,那么Spark 为什么依然会保留 Aggregate 算子?依然以SUM(SALARY)为例,当数据源拥有多个 Partition 时,各个 Partition 返回到 Spark 的数据只是各个 Partition 分别计算得到的和,并不是最终需要的和。因此,Spark 需要再次通过 Sum 函数进行一次计算,所以 Aggregate 是需要保留的。
固执点的读者会说,如果 Partition 只有一个时呢?是不是不需要 Aggregate 算子了。是的,但是 Spark 3.2.0 最初实现 Aggregate 下推时,只是功能实现,还没有更加细化。本文将在介绍 Spark 3.3.0 的 Aggregate 下推时,介绍这个优化。
既然 Aggregate 由数据源计算了,那么 Spark 就可以避免这些计算。更重要的是,可以减少磁盘 I/O 和网络 I/O,甚至减少 Spark Shuffle 的数据量。原先可能需要读取一张表所有的数据文件,现在数据源也许只需要读取几个文件,甚至不用读取数据了。Spark 得到了数据源返回的已经执行了 Aggregate 的数据后,再进行其他计算的初始数据量会有明显的下降,这对于整个 Spark Job 的生命周期都是有效的。但是 Spark 3.2.0 始终保留了 Aggregate 算子,势必带来计算冗余与开销。
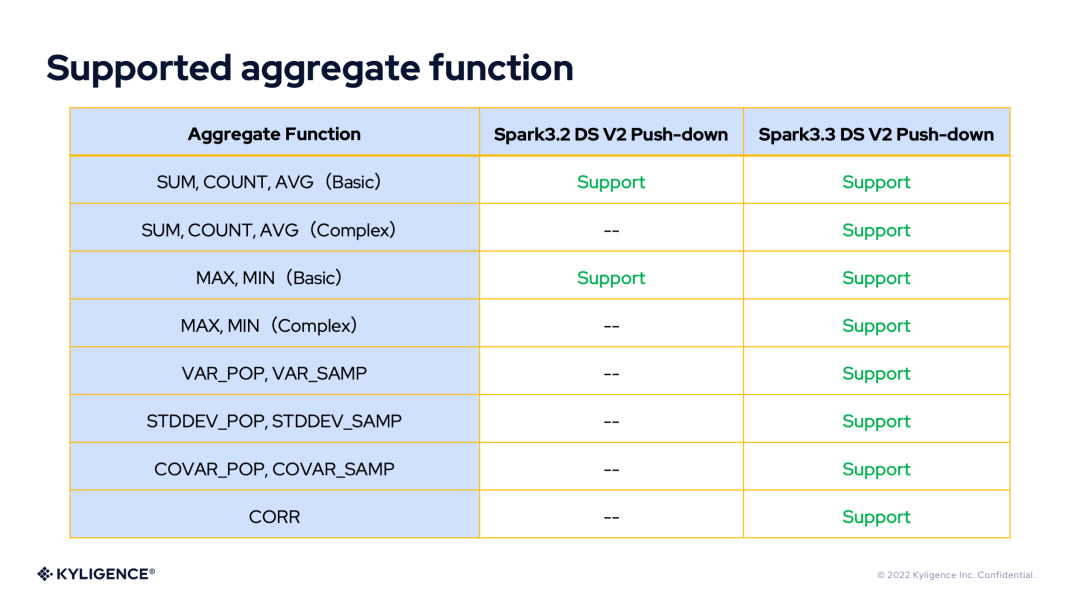
在表达式支持上,Aggregate 下推只支持 MIN、MAX、SUM、COUNT 四个聚合函数,而且只支持对列进行聚合,不支持对复杂表达式的聚合。

3. Spark 3.2 DS V2 Push-down 的问题归纳
根据前面对 Spark3.2 DS V2 Push-down 现有下推功能的分析,我们知道了一些问题。但除此之外,它依然有很多功能上的缺失,例如 Limit 下推。下面列出我们需要去改进的地方:
- 只支持简单 Filter 和Aggregate,导致无法在真实的业务场景应用
- SQL语法的不兼容性,导致无法在真实的业务场景应用
- Spark额外的 Aggregate 造成一定的开销
- 不支持 Limit 下推
- 不支持 Top N 下推
- 不支持分页下推
好了,有了以上分析,来看看 Kyligence 开源团队是如何在 Spark 3.3.0 中完成对 DS V2 Push-down 的重构与改进的。
III. Spark 3.3 DS V2 Push-down
Kyligence 开源团队经过对 Spark3.2 DS V2 Push-down 框架的分析,发现打通任督二脉的关键有三点:
- 强大的 Catalyst 表达式 Translate 能力
- 通用的 DS V2 表达式标准
- 自由的 DS V2 表达式 Compile 能力
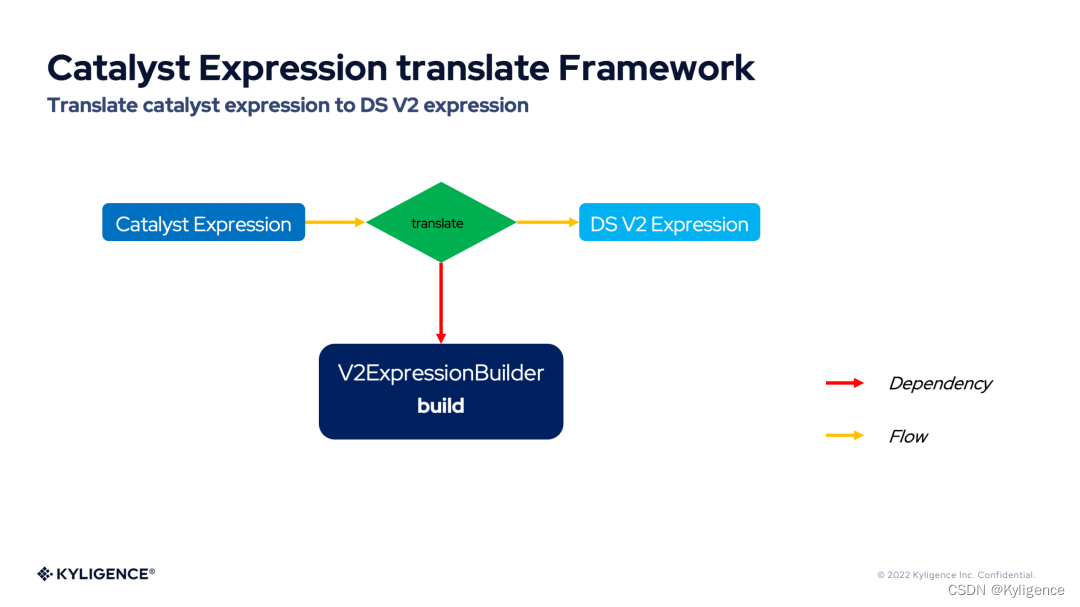
上图是 Spark3.3 DS V2 Push-down 框架的示意图。前两点与 Catalyst 表达式的 translate 的标准化相关,第三点则与 DS V2 表达式的 compile 的差异化相关。
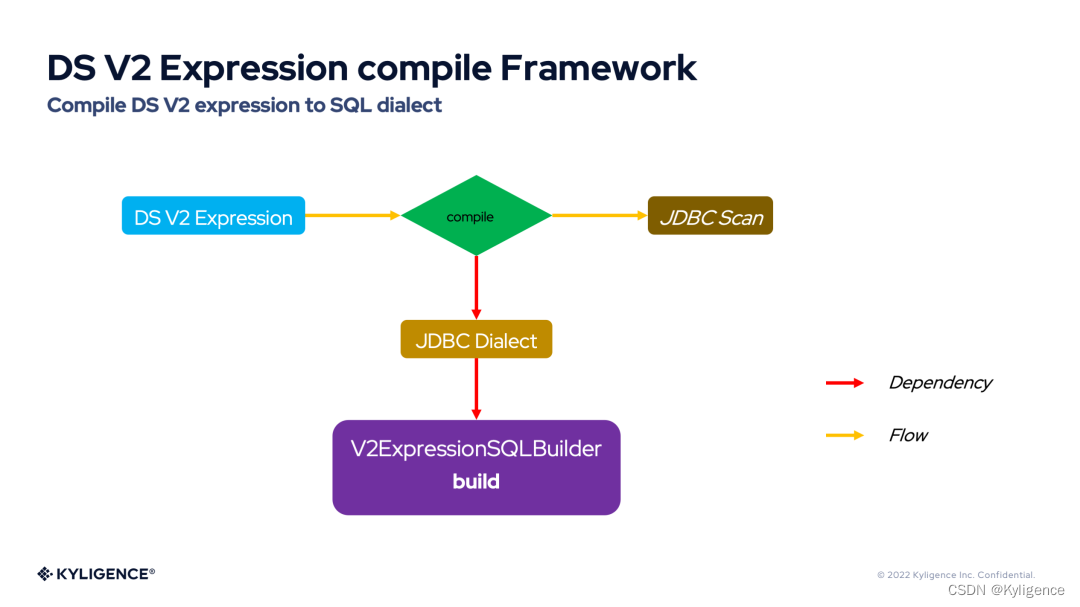
如果上图中的数据源为 JDBC,那么我们可以用下图来表示 Spark3.3 DS V2 Push-down 框架。
下面来看看 Spark3.3 DS V2 Push-down 框架是如何打通任督二脉的?
1. Catalyst Expression translate Framework
Catalyst 表达式翻译框架(Catalyst Expression translate Framework)提供了强大的 Catalyst 表达式 Translate 能力。Catalyst 表达式翻译框架提供了将各种 Catalyst 表达式翻译为 DS V2 表达式的切入点,无论是计算表达式,布尔表达式等基础表达式,还是 Filter 表达式,Aggregate 表达式,这些 Catalyst 表达式都可以被翻译为 DS V2 表达式。下图展示了 Catalyst 表达式翻译框架的流程图。
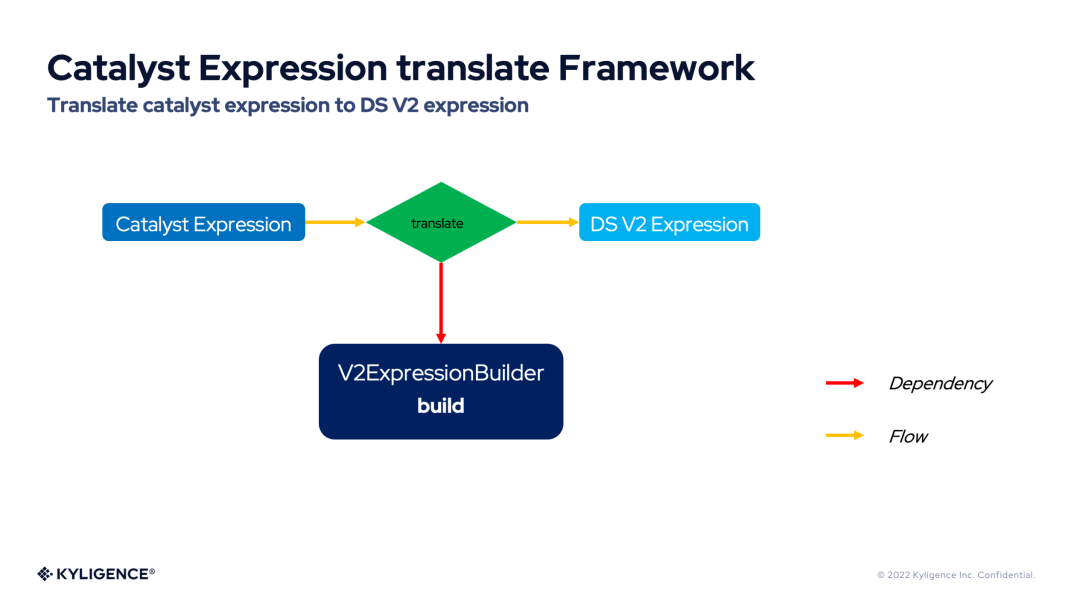
从上图可以看到,Catalyst 表达式翻译框架依赖于 V2ExpressionBuilder,表达式的翻译工作都交给它来完成。
2. General DS V2 Expression Standard
DS V2 表达式是一种通用的表达式形式,作为标准。Filter,Aggregate 等算子都可以复用它们。
这里对主要的 DS V2 表达式进行介绍:
- AggregateFunc:DS V2 聚合函数的统一接口,具体的实现有 Min,Max,Sum,Count,CountStar 和 Avg。这是最常用的聚合函数,DS V2 为它们提供了度身定制的表达式。
- GeneralAggregateFunc:AggregateFunc 的通用实现,用来表示一些符合 ANSI SQL 标准,但是使用频率不那么高的聚合函数(例如:VAR_POP和VAR_SAMP)。
- LiteralValue:DS V2 的字面量表达式,对应 Catalyst 的 Literal。
- NamedReference:代表字段或者列的 DS V2 表达式接口,目前只有 FieldReference 一个实现。
- FieldReference:DS V2 的字段表达式。
- GeneralScalarExpression:DS V2 表达式的通用实现,用于表示最广泛的表达式。
- Predicate:GeneralScalarExpression 的特殊实现,用于代表 Filter 表达式。Spark 社区将逐步统一DS V1 与 V2 的 Filter 表达式 。
- AlwaysTrue 和 AlwaysFalse:特殊的 Predicate,用于代表恒等于 true 或 false 的 Filter 表达式。
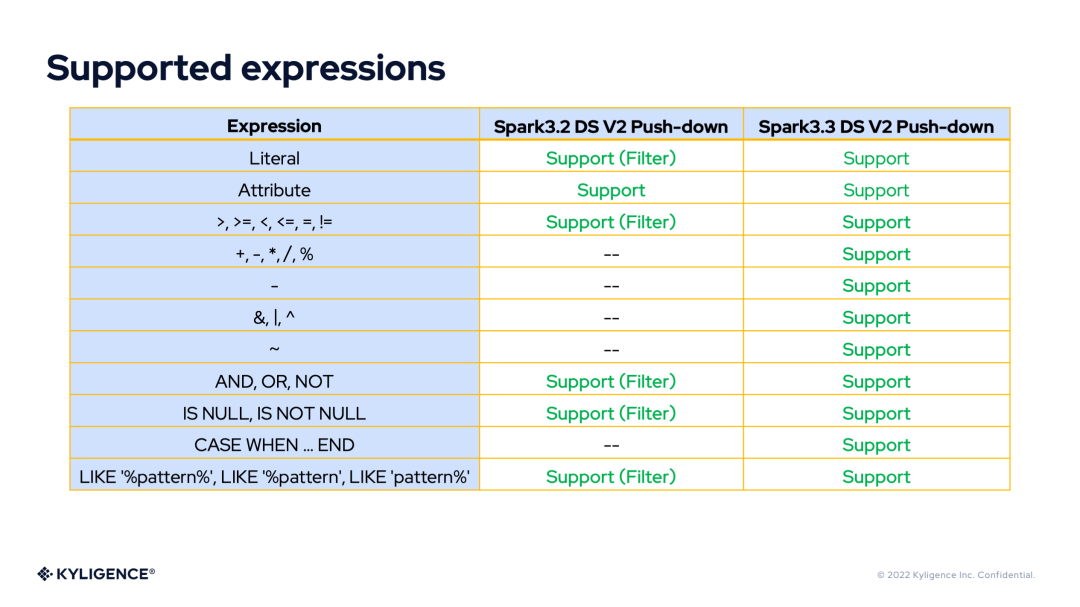
有了 DS V2 表达式的丰富表达能力,我们将 DS V2 Push-down 框架在 Spark 3.2 和 Spark 3.3 版本所支持的表达式或函数做个对比。
Supported Aggregate Functions
Supported Expressions
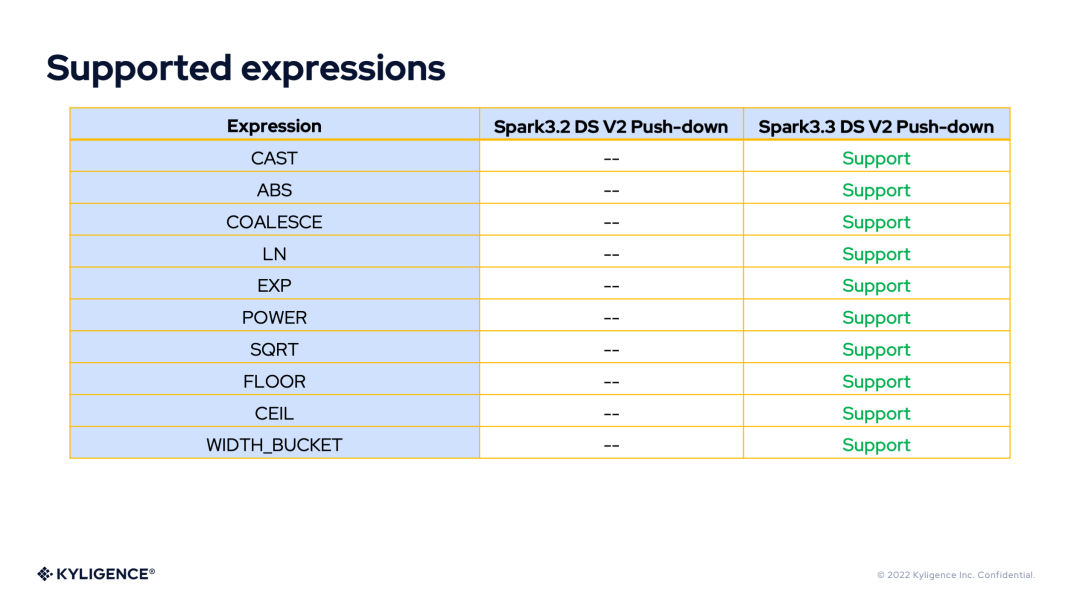
3. DS V2 Expression compile Framework
DS V2 表达式编译框架(DS V2 Expression compile Framework)提供了将 DS V2 表达式自由灵活的编译为 ANSI SQL 或 SQL 方言的能力。下图展示了 DS V2 表达式编译框架的流程图。
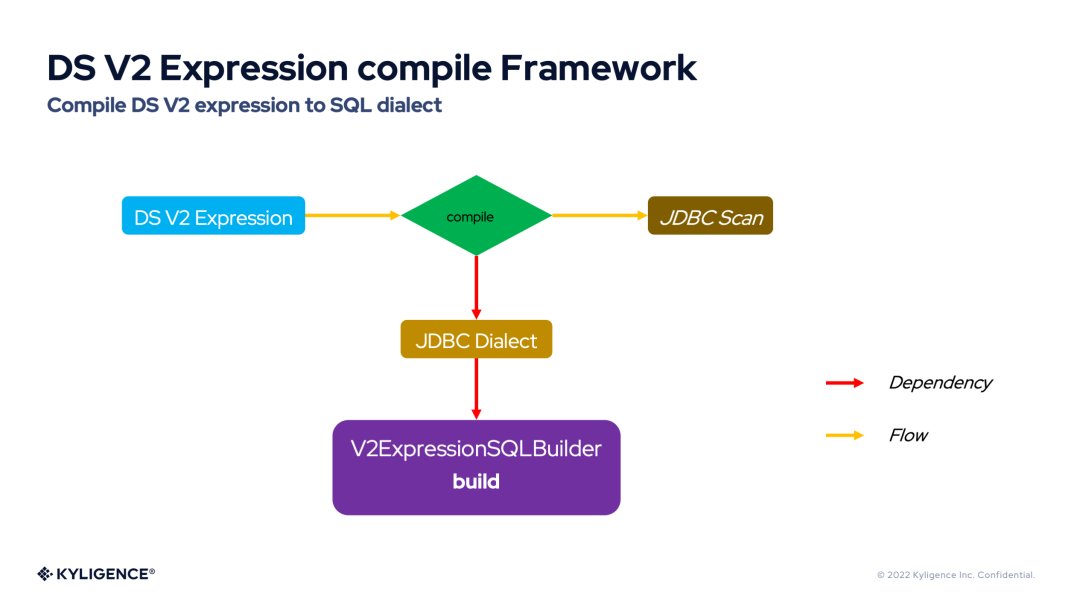
从上图可以看到——编译 DS V2 表达式依赖于 JDBC 方言(JDBC Dialect),默认的 JDBC 方言将 DS V2 表达式编译为 ANSI SQL。Spark 内置了很多 JDBC 方言,例如:H2Dialect,MySQLDialect。而 JDBC 方言对 DS V2 表达式的编译实际又依赖于 V2ExpressionSQLBuilder,V2ExpressionSQLBuilder 内部通过访问者模式提供了对各类表达式的 compile 接口。因此,每个 JDBC 方言都可以灵活定制自己的 V2ExpressionSQLBuilder 行为,符合数据库本身的语法特点。
4. Spark 3.3 DS V2 Filter Push-down
由于 Spark 3.3 DS V2 Push-down 框架有更加通用、丰富和灵活的 DS V2 表达式,因此 Spark3.3 DS V2 Filter Push-down 将可以下推更加丰富的 Filter 表达式。

因而,以前无法下推的 Filter 表达式也可以下推到数据源,就再也不用 Spark 做二次过滤了。

当常见的 Filter 表达式都可以下推时,这将极大的减少 I/O,并促进在生产环境的应用。
5. Spark 3.3 DS V2 Aggregate Push-down
同样由于 Spark 3.3 DS V2 Push-down 框架有更加通用、丰富和灵活的 DS V2 表达式,因此 Spark 3.3 DS V2 Aggregate Push-down 将可以下推更加丰富的 Aggregate 表达式。

因而,以前无法下推的 Aggregate 表达式也可以下推到数据源。但是 Spark 3.2 DS V2 Aggregate Push-down 之前一直保留着 Aggregate 算子,所以这个算子的额外计算就显得很不必要了。于是,Spark 3.3 DS V2 Aggregate Push-down 引入了聚合全下推(Aggregate Complete Push-down)和聚合部分下推(Aggregate Partial Push-down)。
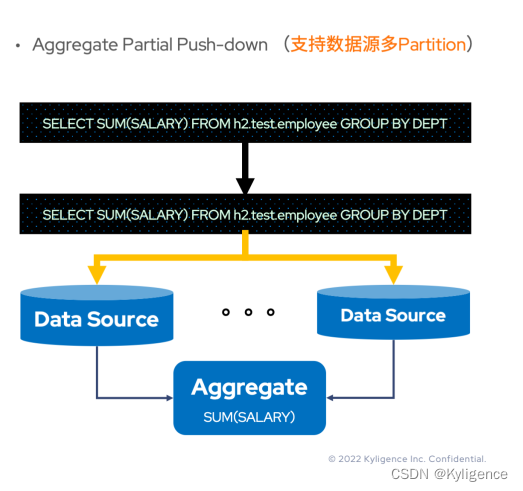
Aggregate Partial Push-down
即便所有的 Aggregate 表达式可以下推到数据源,那么 Aggregate 算子是否就真的不需要了?了解过 Hive 或者 Orc 的读者应当知道——很多文件存储本身是有 Partition 的概念。如果数据源有多个 Partition,并且SUM(SALARY)可以下推,那么 Spark 从多个分区 Task 拿到多份结果后该如何处理?是不是还应该求一次和?答案是肯定的。
既然 Aggregate 下推本身可以缩减 I/O,改进性能,那么还是需要下推的,所以这种下推后还需要由 Spark 进行 Aggregate 计算的 Aggregate 下推称为聚合部分下推(Aggregate Partial Push-down)。
Aggregate Complete Push-down
与聚合部分下推相对应,当 Aggregate 可以下推到数据源并且存储本身只有一个 Partition 时,也不需要 Spark 再进行额外的 Aggregate 计算了。此时,可以消除 Spark 进行 Aggregate 计算的开销。这种下推后不再需要 Spark 进行 Aggregate 计算的 Aggregate 下推称为聚合全下推(Aggregate Complete Push-down)。
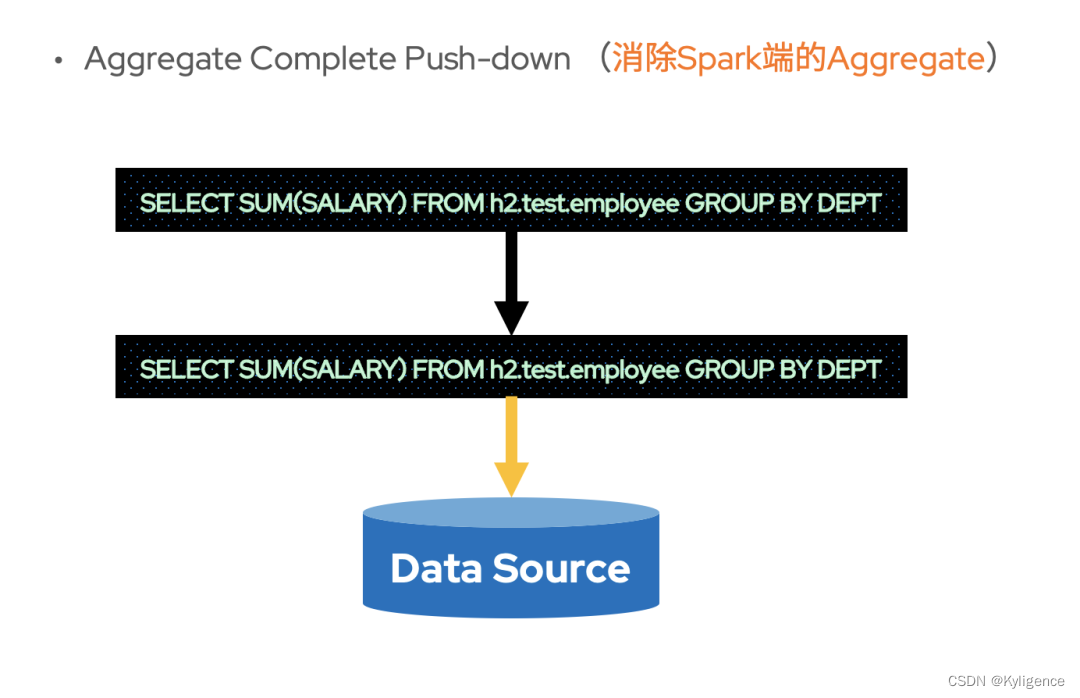
不过,在数据源拥有多 Partition 时,也未必不能够聚合全下推。以SELECT SUM(SALARY) FROM h2.test.employee GROUP BY DEPT这条 SQL 为例,当 Partition 字段为DEPT的时候,各个分区 Task 计算 Aggregate 得到的数据就是最终结果了。也就是说,当分区字段与GROUP BY的 key 相同时,也是可以聚合全下推的。
6. Spark 3.3 DS V2 Limit Push-down
Limit 是最常用的语法之一,如果能将其下推到数据源,其数据量的缩减显而易见,对于 I/O 和性能都有极大的优化空间。Spark 3.3 支持了 Limit 的下推。不过其实现类似于 Spark 3.2 DS V2 Aggregate Push-down,保留了 Limit 算子。
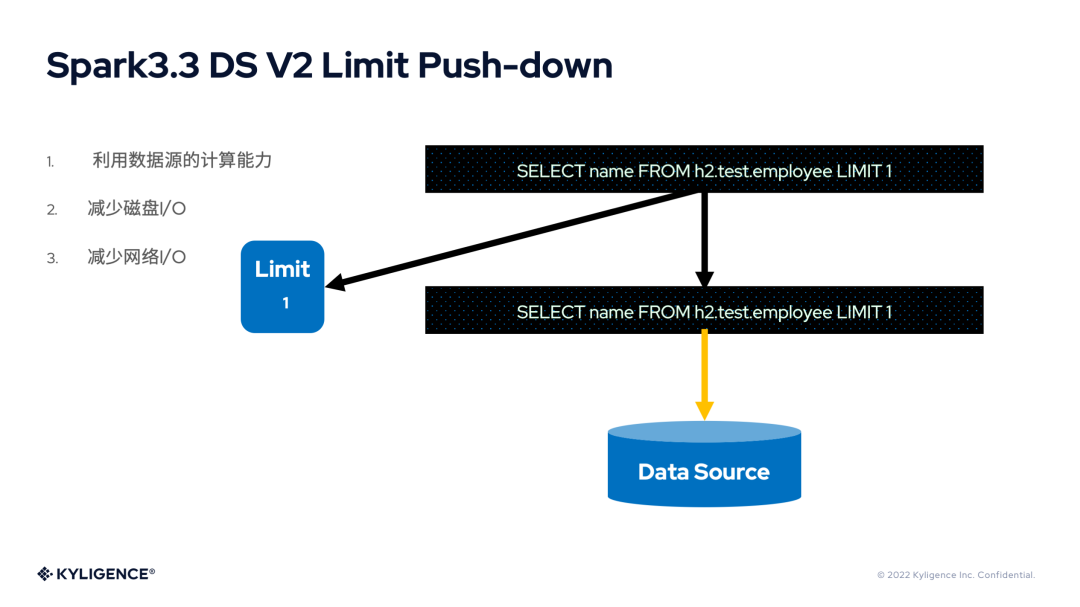
其实,在数据源单 Partition 的情况下,Limit 算子依然可以被优化掉。由于 Spark 社区版本发布的关系,这部分功能应该将在 Spark 3.4 版本中发布。
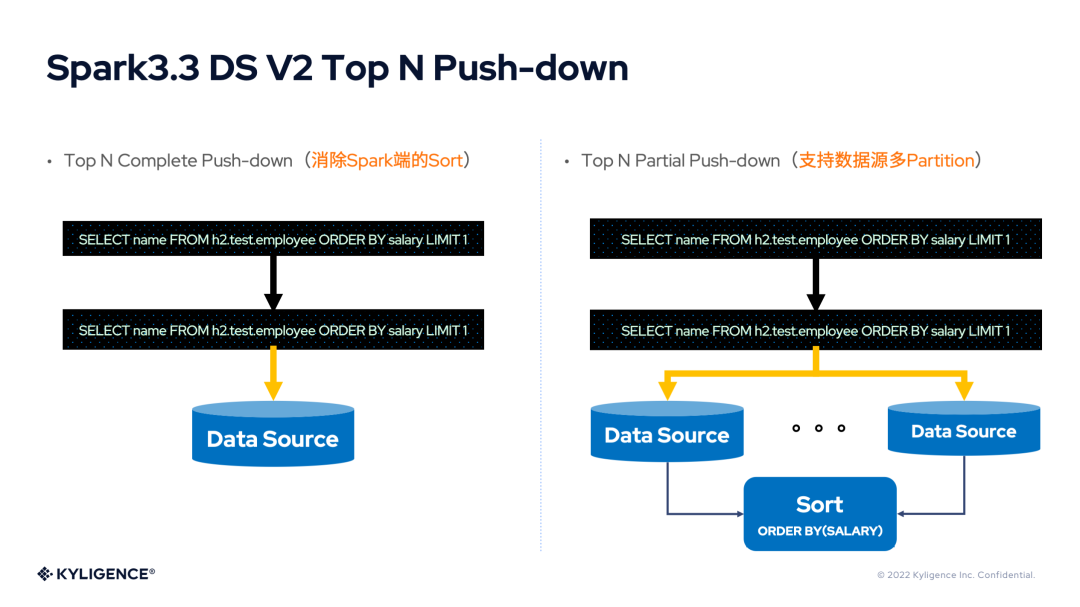
7. Spark 3.3 DS V2 Top N Push-down
Top N 查询在业务场景中非常常见,但是 Spark 对于 Top N 查询需要进行全局排序,当数据量很大时,性能表现不佳!如果能对这里进行性能改进,那么将取得极佳的效果。Top N 查询的处理根据 Partition 的数量分为 Top N 部分下推(Top N Partial Push-down)和 Top N 全下推(Top N Complete Push-down),与 Spark 3.3 DS V2 Aggregate Push-down 非常相似。
8. Differences between Spark 3.2 and Spark 3.3
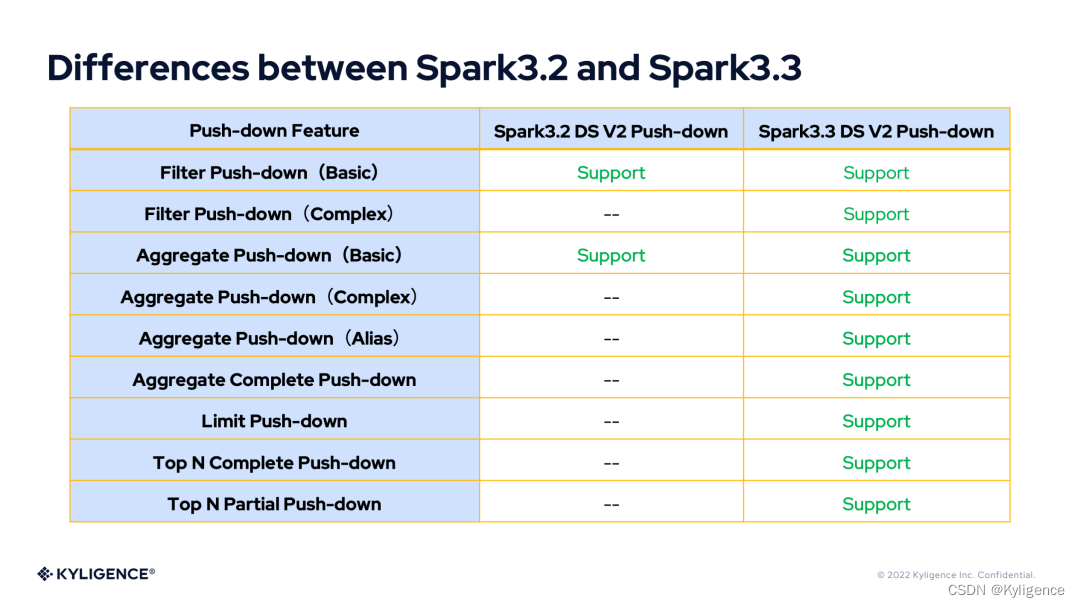
根据前面的介绍,下面用表格来对 Spark 3.2 DS V2 push-down 和 Spark 3.3 DS V2 push-down 的特性差异进行比较。
IV. Plan of Spark 3.4 DS V2 Push-down
1. Spark 3.4 DS V2 Limit Push-down
尽管,Spark 3.3 提供了 Limit 的下推,但是保留着 Limit 算子,始终是一笔开销。在 Spark 3.4 版本中将发布 Limit 部分下推(Limit Partial Push-down)和 Limit 全下推(Limit Complete Push-down)。

2. Spark 3.4 DS V2 Offset Push-down
由于 Spark 3.4 已经完成了对 Offset 算子的支持,因此可以将 Offset 下推到数据源。其下推原理类似于 Limit。
3. Spark 3.4 DS V2 Paging Push-down
由于 Spark 3.4 已经完成了对 Offset 算子的支持,业务场景已经可以使用 Spark 完成分页查询了。如果将分页查询下推到数据源,必然有很大的收益。其下推原理类似于 Top N。
4. Spark 3.4 DS V2 Aggregate Push-down supports push down group by expressions without aggregate function.
目前,Spark 3.4 DS V2 Aggregate Push-down 不支持select key from tab group by key。这个功能将在 Spark 3.4 发布。
5. Spark 3.4 DS V2 Top N Push-down supports order by expressions
目前,Spark 3.3 DS V2 Top N Push-down 只支持 order by 字段。由于 Spark 版本发布的原因,这个功能将在 Spark 3.4 发布。
6. Spark 3.4 DS V2 supports more expression
在 Spark 3.4 版本中继续扩充对表达式的支持,例如:字符串表达式和日期表达式等。
7. Spark 3.4 DS V2 supports UDF and UDAF
在 Spark 3.4 版本中增加对 UDF 的支持。此功能将继续释放外部开发者的自由度。
8. Spark 3.4 DS V2 supports more flexiable
在 Spark 3.4 版本中增加数据库方言的更多灵活性,例如:决定哪些函数可以下推,注册可以下推的 UDF 和 UDAF 等。
9. Orc/Parquet follows more features of DS V2 Push-down
目前,Orc,Parquet 等的下推,依然采用了早期的下推方案,可以将它们慢慢适配、迁移到新的下推框架中。
Kyligence 内部使用了 Kylin、Spark、ClickHouse等多种开源技术,Spark 3.3 DS V2 Push-down 能够大大加速 Spark 对 Clickhouse 数据的查询。如果想了解相关内容,请大家点击下方关注我们,我们后续将分享更多相关技术博客。
关于 Kyligence
上海跬智信息技术有限公司 (Kyligence) 由 Apache Kylin 创始团队于 2016 年创办,致力于打造下一代企业级智能多维数据库,为企业简化数据湖上的多维数据分析(OLAP)。通过 AI 增强的高性能分析引擎、统一 SQL 服务接口、业务语义层等功能,Kyligence 提供成本最优的多维数据分析能力,支撑企业商务智能(BI)分析、灵活查询和互联网级数据服务等多类应用场景,助力企业构建更可靠的指标体系,释放业务自助分析潜力。
Kyligence 已服务中国、美国、欧洲及亚太的多个银行、证券、保险、制造、零售等行业客户,包括建设银行、浦发银行、招商银行、平安银行、宁波银行、太平洋保险、中国银联、上汽、Costa、UBS、MetLife 等全球知名企业,并和微软、亚马逊、华为、Tableau 等技术领导者达成全球合作伙伴关系。目前公司已经在上海、北京、深圳、厦门、武汉及美国的硅谷、纽约、西雅图等开设分公司或办事机构。

