
- 1【极简版】一篇文章理解UGC、PGC、POI运营管理与O2O行业
- 2抓取静态网页数据
- 3免费期刊类表
- 42024最新Keilv5下载安装注册及添加ARM5编译器_mdk540
- 5【Python笔记-FastAPI】后台任务+WebSocket监控进度_fastapi list[websocket]
- 6数学建模大师手册:全国大学生数学建模竞赛模板(附Word模版)_数学建模模板csdn
- 7域内提权之CVE-2020-1472复现打域控_cve-2020-1472下载
- 8Python 3.x 学习:Python 简介、安装(一)_python官网python3.x安装包其中包括什么
- 9BIO、NIO、AIO你会用了吗,java高级技术经理面试题_byte[] bytes =new byte[1]; int value = socket.geti
- 10hadoop—haddop部署、yarn管理器使用、hdfs的高可用、yarn的高可用、Hbase分布式部署_哈道普分布式部署安装是什么原理
LLM-阿里云 DashVector + ModelScope 多模态向量化实时文本搜图实战总结
赞
踩
前言
本文使用阿里云的向量检索服务(DashVector),结合 ONE-PEACE多模态模型,构建实时的“文本搜图片”的多模态检索能力。整体流程如下: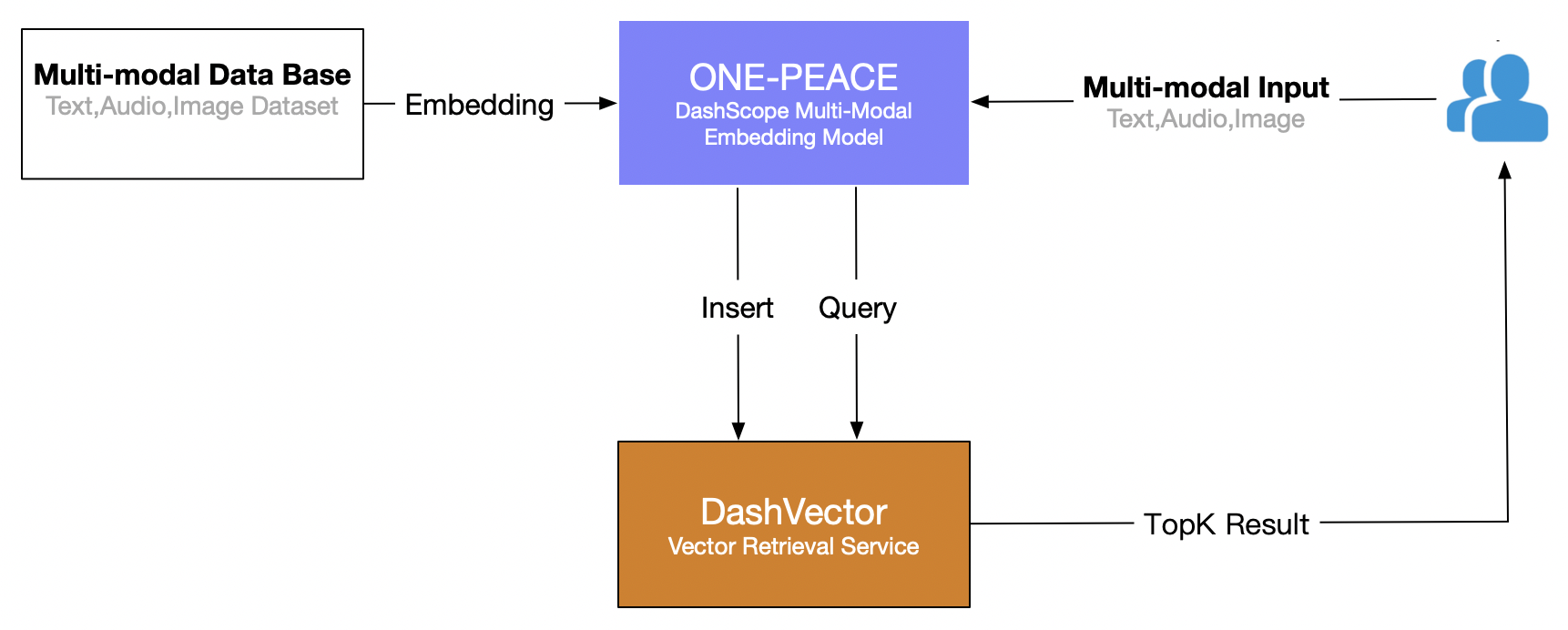
- 多模态数据Embedding入库。通过ONE-PEACE模型服务Embedding接口将多种模态的数据集数据转化为高维向量。
- 多模态Query检索。基于ONE-PEACE模型提供的多模态Embedding能力,我们可以自由组合不同模态的输入,例如单文本、文本+音频、音频+图片等多模态输入,获取Embedding向量后通过DashVector跨模态检索相似结果。
前提条件
- 开通灵积模型服务,并获得API-KEY:开通DashScope并创建API-KEY
- 开通向量检索服务:请参见开通服务。
- 创建向量检索服务API-KEY:请参见API-KEY管理。
环境准备
# 安装 dashscope 和 dashvector sdk
pip3 install dashscope dashvector
# 显示图片
pip3 install Pillow
- 1
- 2
- 3
- 4
- 5
数据准备
说明
由于DashScope的ONE-PEACE模型服务当前只支持URL形式的图片、音频输入,因此需要将数据集提前上传到公共网络存储(例如 oss/s3),并获取对应图片、音频的url地址列表。
步骤
图片数据Embedding入库
我使用了阿里云的 OSS 保存了图片,通过 OSS Browser 界面获取图片外部可以访问的 URL: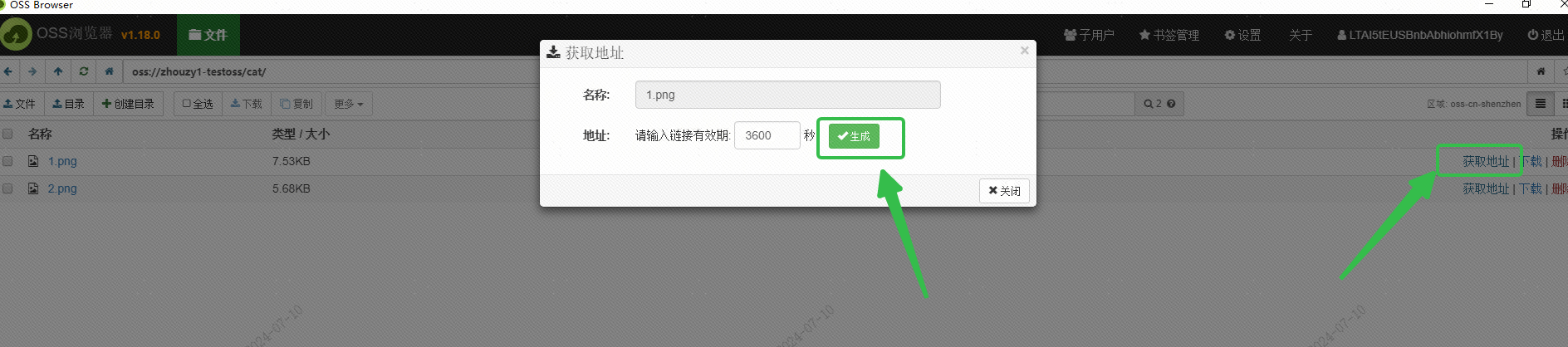
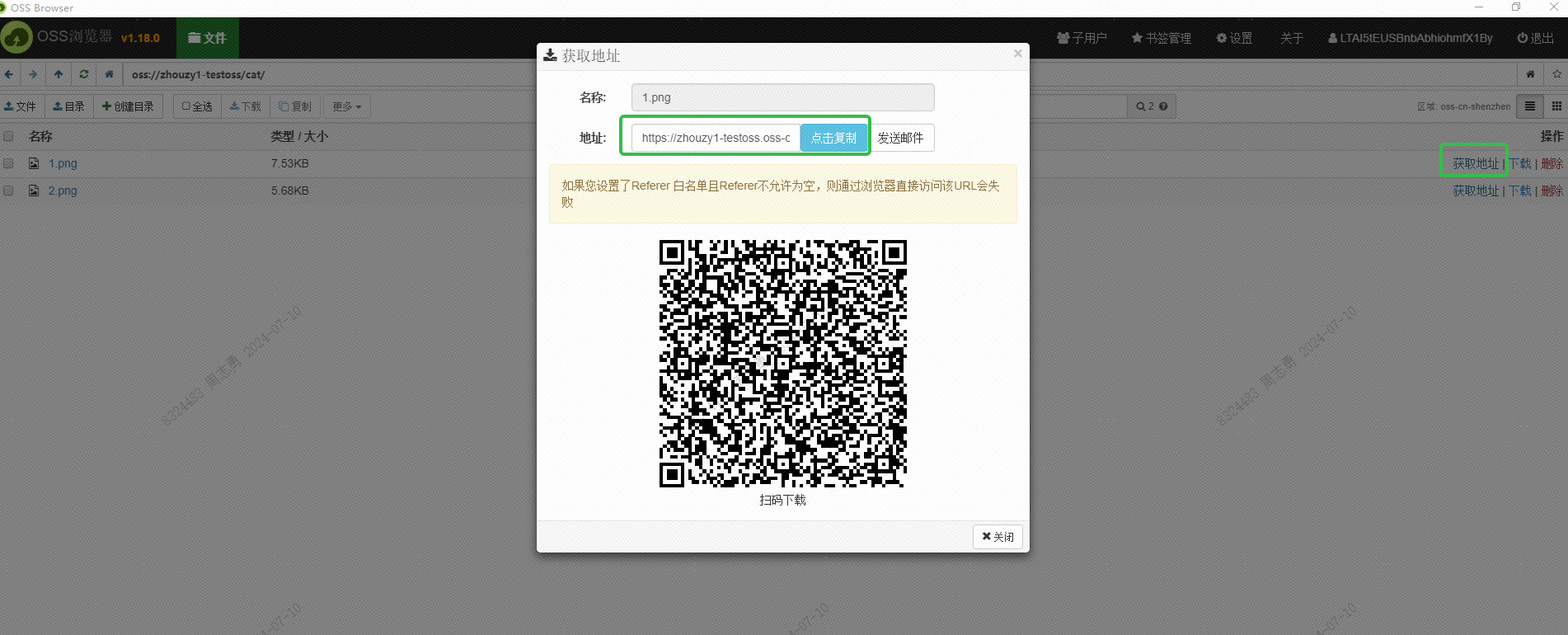
这个 URL 应该也可以通过接口的方式获取,这个还没有研究,感兴趣的小伙伴可以尝试用接口批量获取下,获取这个 URL 的目的是为了让阿里云的 DashScope 服务能够读取到该图片进行 embedding 保存到 DashVector 向量数据库中。
获取到该URL 后,就将该URL 写入到我们的 imagenet1k-urls.txt 文件中,等会我们的代码会读取该文件进行嵌入: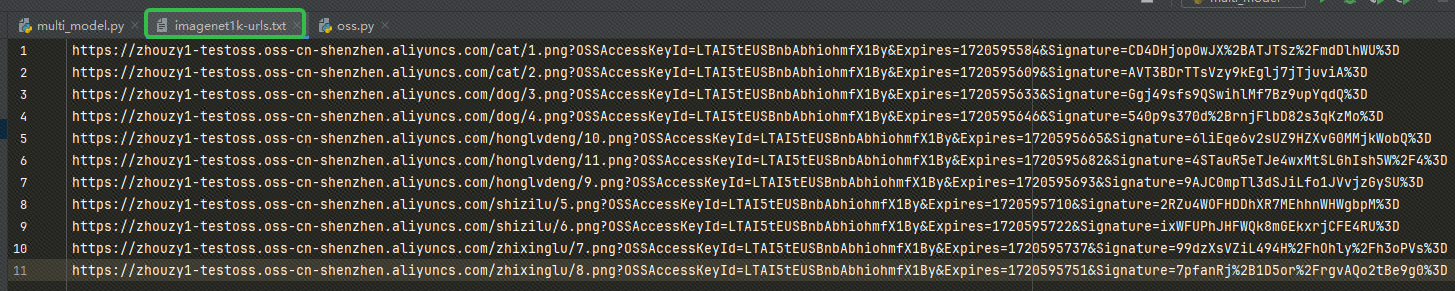
执行嵌入的代码如下(我在后边会将完整代码和目录结构贴出,这里只贴出嵌入的代码):
def index_image(self): # 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维 collection = self.vector_client.get(self.vector_collection_name) if not collection: rsp = self.vector_client.create(self.vector_collection_name, 1536) collection = self.vector_client.get(self.vector_collection_name) if not rsp: raise DashVectorException(rsp.code, reason=rsp.message) # 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file: for i, line in enumerate(file): url = line.strip('\n') input = [{'image': url}] result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1, input=input, api_key=os.environ["DASHSCOPE_API_KEY"], auto_truncation=True) if result.status_code != 200: print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}") continue embedding = result.output["embedding"] collection.insert( Doc( id=str(i), vector=embedding, fields={'image_url': url} ) ) if (i + 1) % 100 == 0: print(f"---- Succeeded to insert {i + 1} image embeddings")

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 读取
IMAGENET1K_URLS_FILE_PATH中的图片 URL,然后执行请求 DashScope 请求,将我们的图片向量化存储。 - 在插入向量数据库的时候带上了图片的 URL 作为向量属性。
执行完毕后可以通过向量检索服务控制台,查看下向量数据: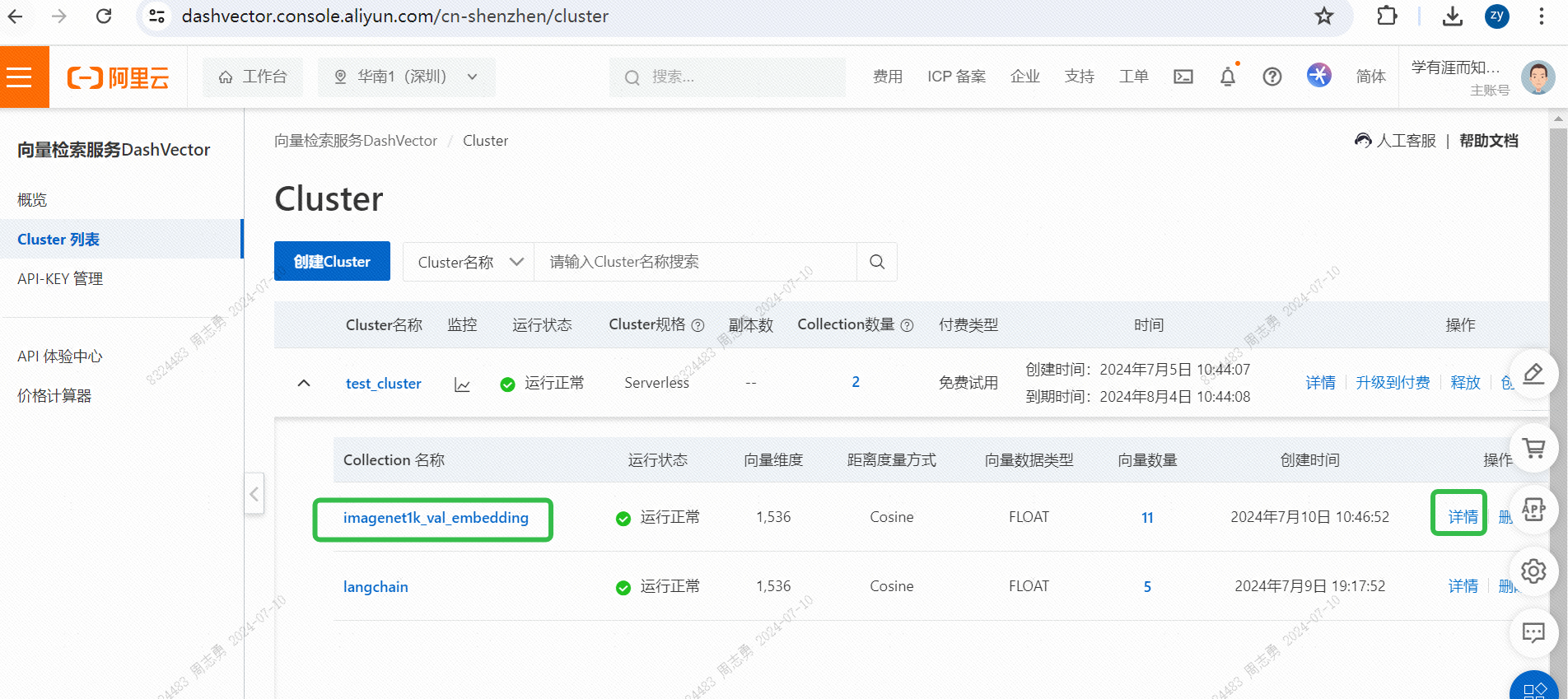
文本检索
通过文本检索向量数据库中的数据,我输入cat检索出三张(我们代码中设置的 topk=3)图片, 可以查看下效果,两张是猫的照片,但是有一张是狗的照片: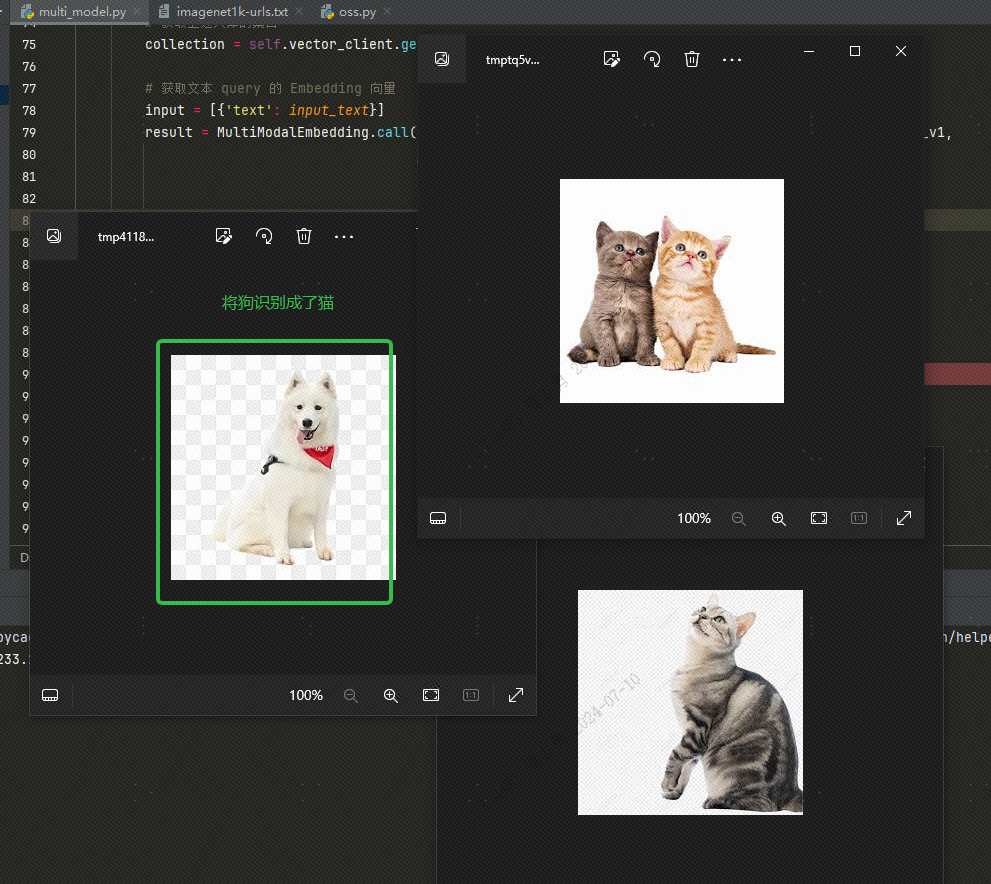
这是因为这张狗和猫是存在相似性的,接下来我们将topk设置为2,理论上就检测不出这个狗了,我们看下效果,果然就没有狗了: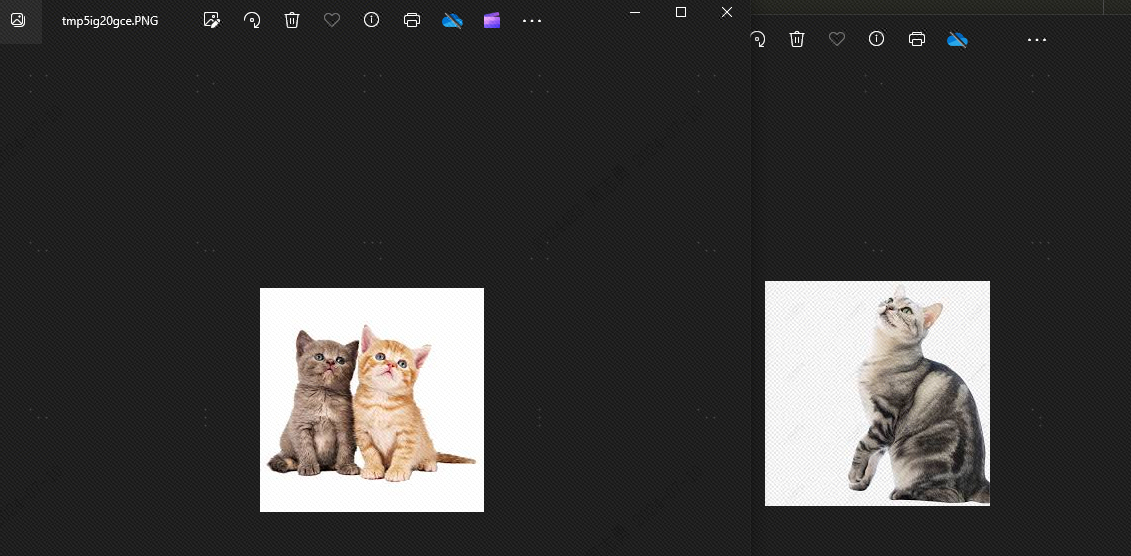
之所以会出现狗,是因为我往向量库中存入了4张动物图片,2张猫的,2张狗的,如果我们的 topk 设置为3,就会多检测出一张狗的。
完整代码
multi_model.py文件如下:
import os import dashscope from dashvector import Client, Doc, DashVectorException from dashscope import MultiModalEmbedding from dashvector import Client from urllib.request import urlopen from PIL import Image class DashVectorMultiModel: def __init__(self): # 我们需要同时开通 DASHSCOPE_API_KEY 和 DASHVECTOR_API_KEY os.environ["DASHSCOPE_API_KEY"] = "" os.environ["DASHVECTOR_API_KEY"] = "" os.environ["DASHVECTOR_ENDPOINT"] = "" dashscope.api_key = os.environ["DASHSCOPE_API_KEY"] # 由于 ONE-PEACE 模型服务当前只支持 url 形式的图片、音频输入,因此用户需要将数据集提前上传到 # 公共网络存储(例如 oss/s3),并获取对应图片、音频的 url 列表。 # 该文件每行存储数据集单张图片的公共 url,与当前python脚本位于同目录下 self.IMAGENET1K_URLS_FILE_PATH = "imagenet1k-urls.txt" self.vector_client = self.init_vector_client() self.vector_collection_name = 'imagenet1k_val_embedding' def init_vector_client(self): return Client( api_key=os.environ["DASHVECTOR_API_KEY"], endpoint=os.environ["DASHVECTOR_ENDPOINT"] ) def index_image(self): # 创建集合:指定集合名称和向量维度, ONE-PEACE 模型产生的向量统一为 1536 维 collection = self.vector_client.get(self.vector_collection_name) if not collection: rsp = self.vector_client.create(self.vector_collection_name, 1536) collection = self.vector_client.get(self.vector_collection_name) if not rsp: raise DashVectorException(rsp.code, reason=rsp.message) # 调用 dashscope ONE-PEACE 模型生成图片 Embedding,并插入 dashvector with open(self.IMAGENET1K_URLS_FILE_PATH, 'r') as file: for i, line in enumerate(file): url = line.strip('\n') input = [{'image': url}] result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1, input=input, api_key=os.environ["DASHSCOPE_API_KEY"], auto_truncation=True) if result.status_code != 200: print(f"ONE-PEACE failed to generate embedding of {url}, result: {result}") continue embedding = result.output["embedding"] collection.insert( Doc( id=str(i), vector=embedding, fields={'image_url': url} ) ) if (i + 1) % 100 == 0: print(f"---- Succeeded to insert {i + 1} image embeddings") def show_image(self, image_list): for img in image_list: # 注意:show() 函数在 Linux 服务器上可能需要安装必要的图像浏览器组件才生效 # 建议在支持 jupyter notebook 的服务器上运行该代码 img.show() def text_search(self, input_text): # 获取上述入库的集合 collection = self.vector_client.get('imagenet1k_val_embedding') # 获取文本 query 的 Embedding 向量 input = [{'text': input_text}] result = MultiModalEmbedding.call(model=MultiModalEmbedding.Models.multimodal_embedding_one_peace_v1, input=input, api_key=os.environ["DASHSCOPE_API_KEY"], auto_truncation=True) if result.status_code != 200: raise Exception(f"ONE-PEACE failed to generate embedding of {input}, result: {result}") text_vector = result.output["embedding"] # DashVector 向量检索 rsp = collection.query(text_vector, topk=2) image_list = list() for doc in rsp: img_url = doc.fields['image_url'] img = Image.open(urlopen(img_url)) image_list.append(img) return image_list if __name__ == '__main__': a = DashVectorMultiModel() # 执行 embedding 操作 a.index_image() # 文本检索 text_query = "Traffic light" a.show_image(a.text_search(text_query))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 开通 DashScope 和 DashVector 的 API KEY 后替换上边的
DASHSCOPE_API_KEY,DASHVECTOR_API_KEY,DASHVECTOR_ENDPOINT
代码目录结构如下,将 txt 文件和py 文件放在同级目录下: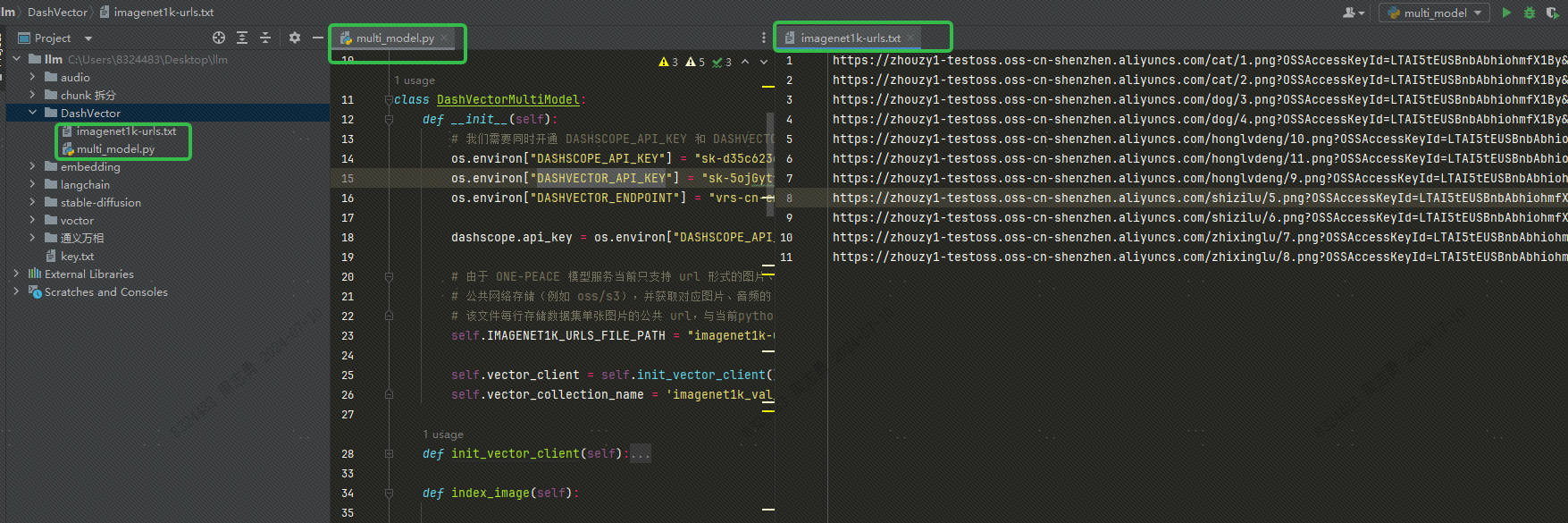
补充说明
-
使用本地图片:我是将图片上传至 OSS 的,也可以使用本地的图片文件,将 txt 中的文件路径替换为本地图片路径,如下:
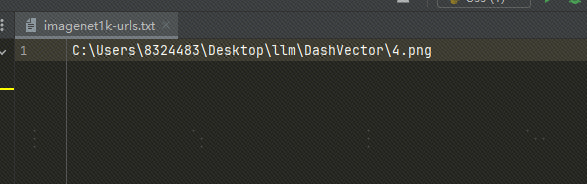
-
如果使用本地图片的话,我们就得修改下上边的代码了,修改下边的代码:
# 将 img = Image.open(urlopen(img_url)) 替换为下边的代码 img = Image.open(img_url)- 1
- 2

