
- 1搭建Mac Flutter开发环境
- 2Zookeeper(Kafka内置)单独添加SASL认证及ACL_zk配置ssal认证
- 3腾讯位置服务Flutter业务实践——地图SDK Flutter插件实现(一)_flutter 腾讯地图定位
- 4【Linux】进程创建和终止 | slab分配器
- 5【C++历练之路】哈希思想的应用——位图、布隆过滤器
- 6【JavaScript 算法】栈与队列:解决括号匹配问题
- 7渗透测试-DNS重绑定
- 8彻底改变时尚:使用 GAN 实现 AI 的未来
- 92024年超详细JDK下载与安装步骤_jdk下载与安装教程(1),2024年最新面试加分的话_java的jdk下载
- 10CiteSpace关键词共现图谱含义详细解析_citespace网络密度的判断标准
lstm 文本纠错_AI LIVE | 文本纠错技术探索和实践
赞
踩
· 小PAI导读 ·
「AI LIVE」是平安人寿AI团队打造的AI专业知识分享和学习专栏,将通过直播、沙龙等形式,分享平安寿险AI技术及创新成果,推动实现与AI领域同行共成长。
本期「AI LIVE」将回顾我们在“AI研习社”直播间进行的主题为「文本纠错技术探索和实践」的技术分享,由平安人寿AI团队高级算法工程师陈乐清老师主讲。
为了让大家能够快速get本期直播干货,小PAI特别整理了这篇直播内容文字稿,一起来复习一下吧~
全文框架概览
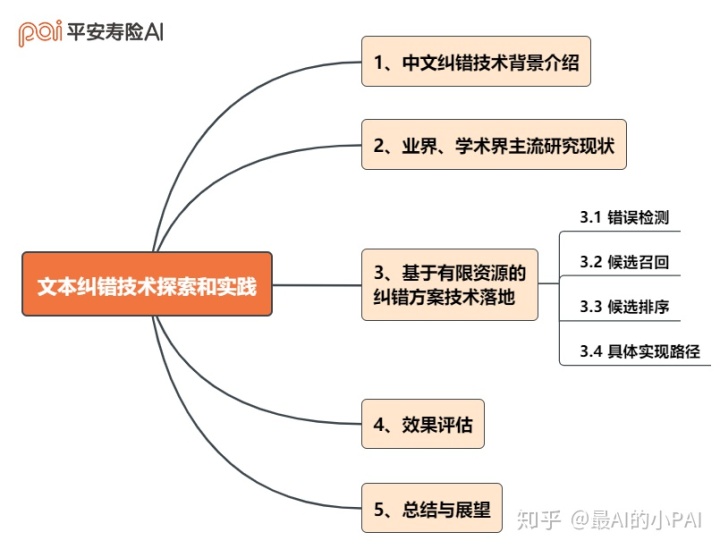
一、背景与意义
中文纠错技术是实现中文语句自动检查、自动纠错的一项重要技术,其目的是提高语言正确性的同时减少人工校验成本。纠错模块作为自然语言处理最基础的模块,其重要程度不言而喻。
在日常生活中,我们经常会在微信、微博等社交工具或公众号文章中发现许多错别字。我们在几个方面对文本出错概率进行了统计:在微博等新媒体领域中,文本出错概率在2%左右;在语音识别领域中,出错率最高可达8-10%;而在平安人寿问答领域中,用户提问出错率在去重后仍高达9%。
在平安人寿问答领域的用户问题中,我们发现多种类型错误。其中占比最高的错误是语言转化和发音不标准的错误,占错误总量的50%。比如一款保险产品“少儿平安福”被语言识别转化为“少儿平安符”、“飞机”因方言差异被读成“灰机”、“难受想哭”变成“难受香菇”等。
占比第二高的错误类型是拼写错误,占错误总量的35%。这些错误主要发生在通过拼音、五笔和手写输入文本的场景。比如“眼镜蛇”-“眼睛蛇”、“缺铁性贫血”-“缺铁性盆血”等。剩余的错误我们将其分类为语法和知识错误,语法错误包括多字少字乱序,如“地中海投保”-“投保地中海”,知识关联错误如“福田平安金融中心”错写为“南山平安金融中心”。
文本中大量的错误对上层nlp技术来说无疑是一项巨大挑战,输入数据的准确性是自然语言处理常见任务的基本前提,也是提高上层应用性能的关键。

二、研究现状
在通用领域中,中文文本纠错问题是从互联网起始时就一直在解决的问题。在搜索引擎中,一个好的纠错系统能够对用户输入的查询词进行纠错提示,或直接展示正确答案。
在此给大家介绍一个比较受欢迎的纠错项目:Pycorrector。该项目由规则纠错和深度学习纠错两部分组成。深度学习纠错项目中提到一些前沿的方法,比如机器翻译,但作者未提供直接调用接口;而规则纠错虽然可以直接调用,但因其性能和准确率无法满足我们项目需求,无法直接使用。下面简单介绍一下规则纠错,主要分为经典三步曲:第一步通过常用词词典匹配结合统计语言模型的方式进行错误检测;第二步利用近音字,近形字和混淆字进行候选召回;最后一步利用统计语言模型进行打分排序。

