本地通过ollama下载模型,并使用python跑这个本地模型
赞
踩
1,这是ollama地址,下载对应的安装包
https://ollama.com/?viaurl=ainavpro.com
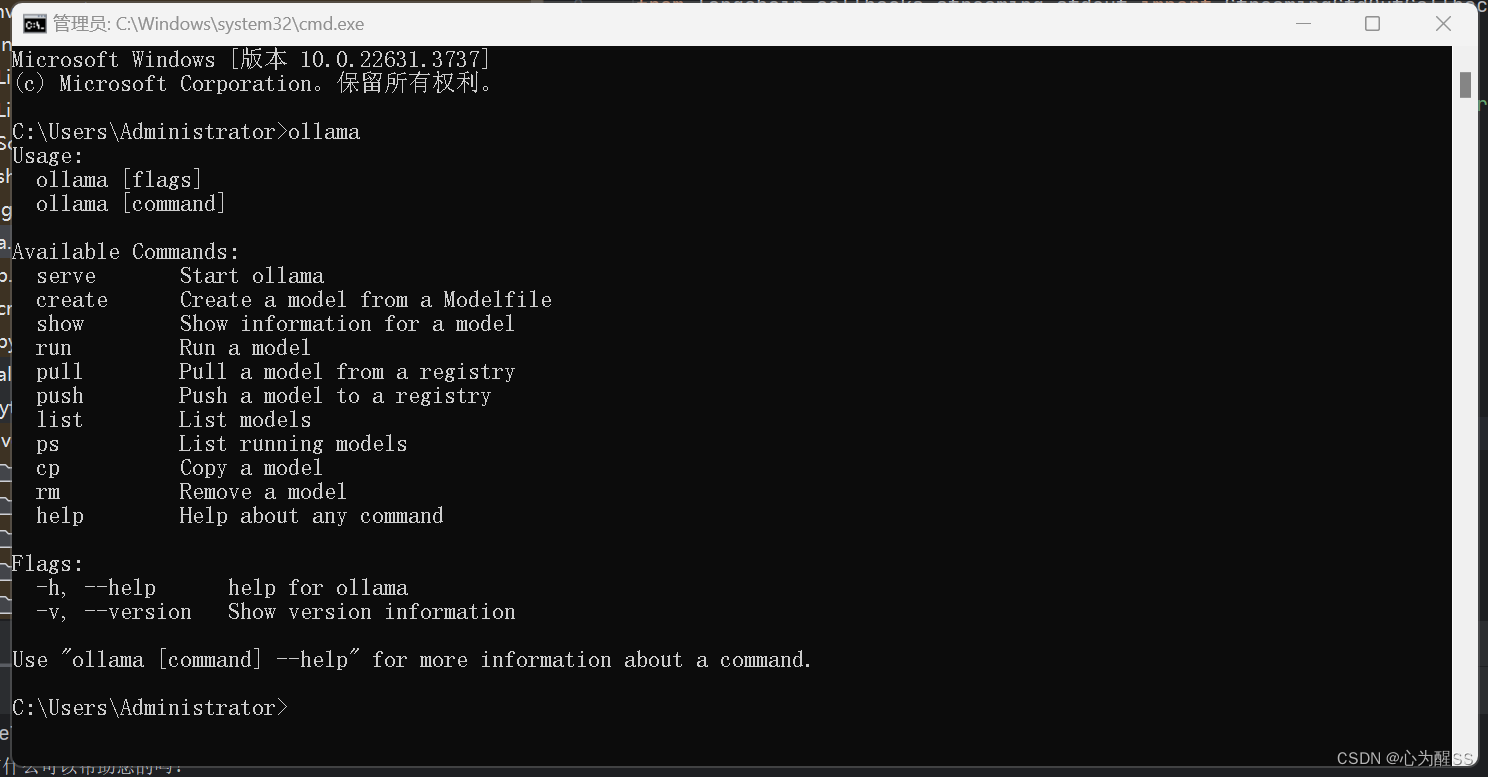
2,下载完直接安装即可,安装完后,win+r打开cmd,出现这个,基本就妥了
3,这里我们需要去下载模型, 这里推荐一下千问2的0.5b,不大,本地好跑,你也可以选择在ollama里面搜索别的,以千问2为例,他有很多选择,比如0.5b,1.5b等等,b就是亿,0.5就是0.5亿参数,我感觉一般是够用的
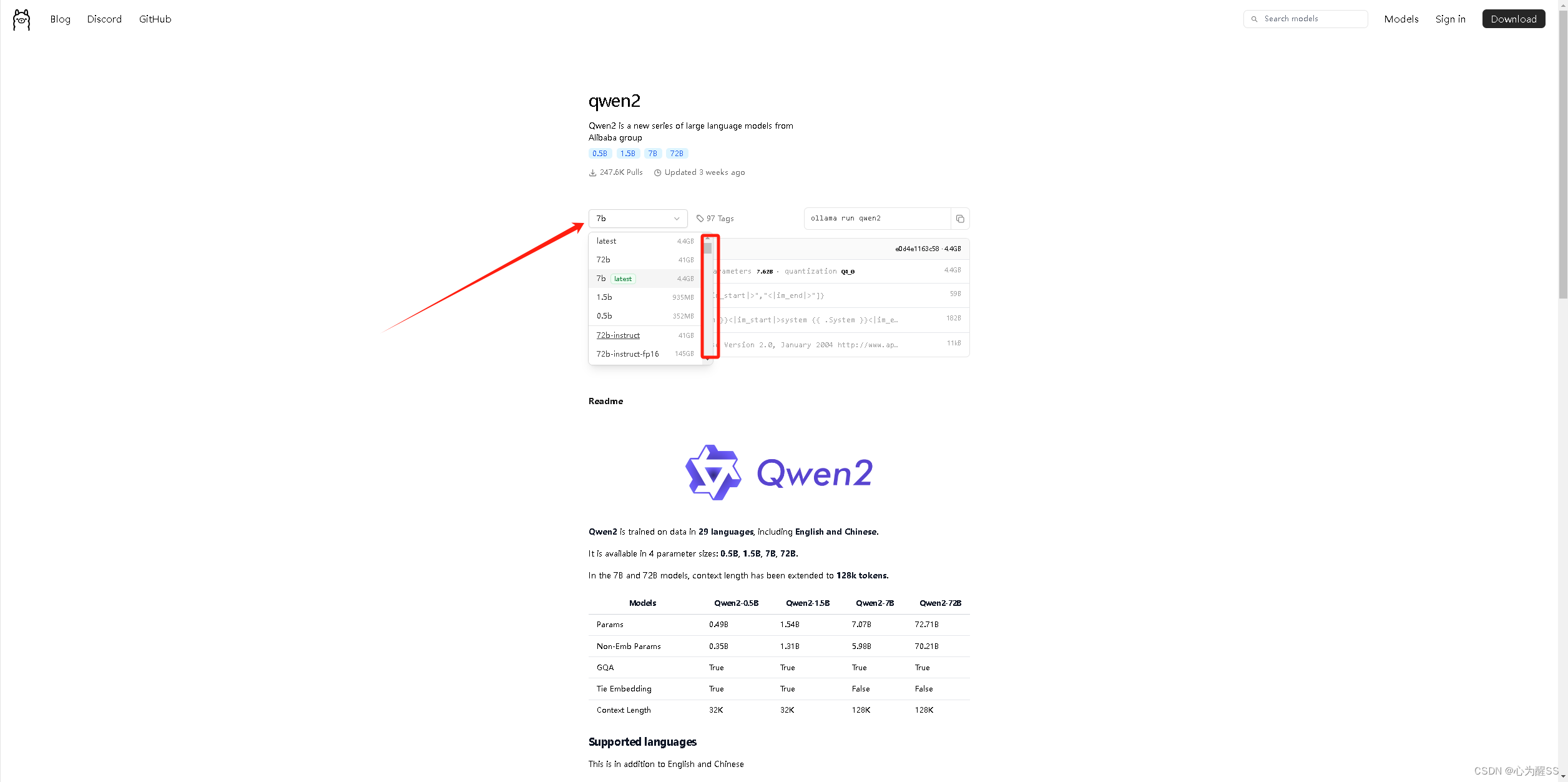
4,然后回到cmd ,输入 ollama list, 可以查看当前的模型,然后找到你想要下载的模型,运行
ollama run your_model -》your_model 就是你的模型名称
比如用的就是ollama run qwen2:0.5b-instruct-q8_0
5,下载完成后,本地运行ollama list,如下图
6,这里我们其实就可以在本地对qwen2大模型进行对话了
ollama run qwen2:0.5b-instruct-q8_0
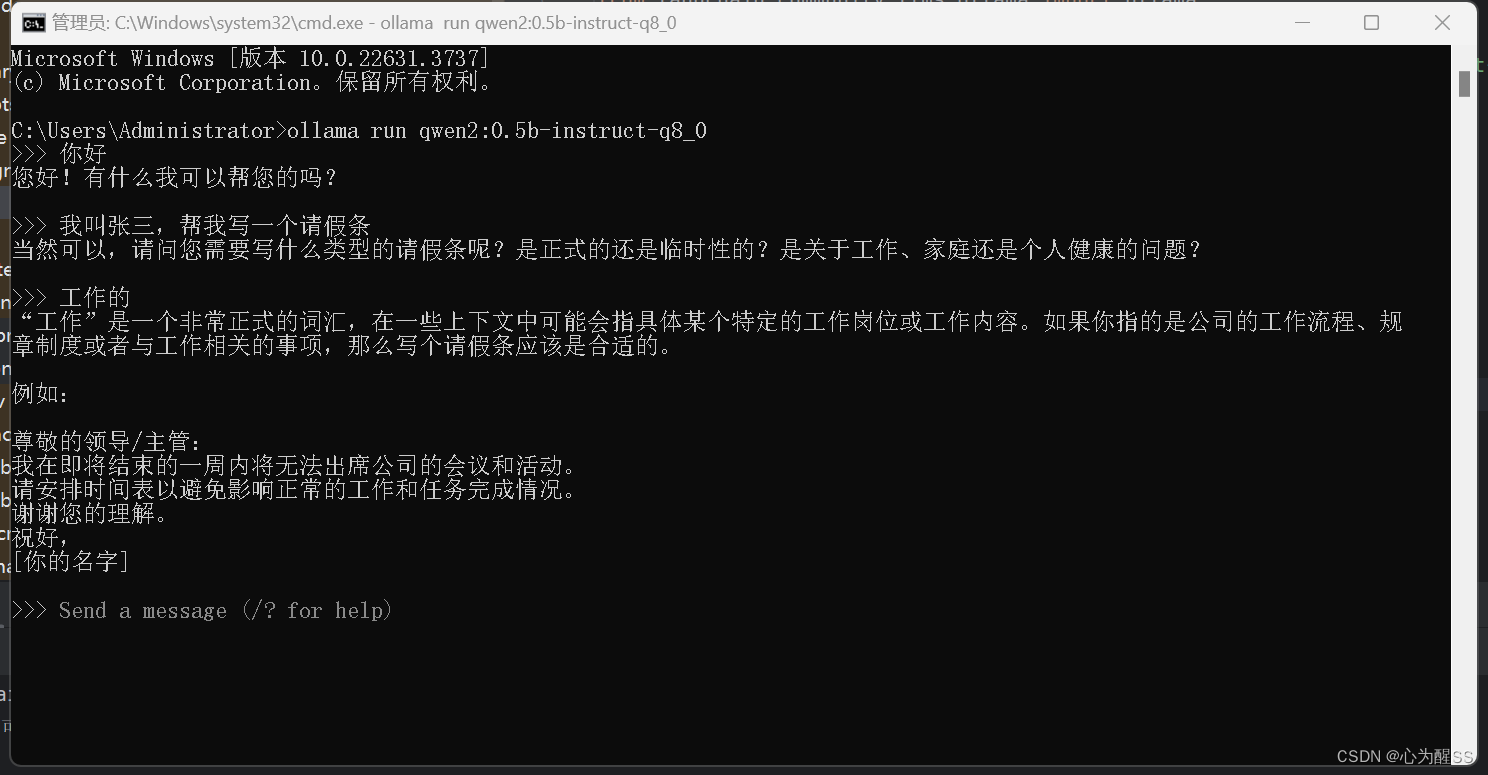
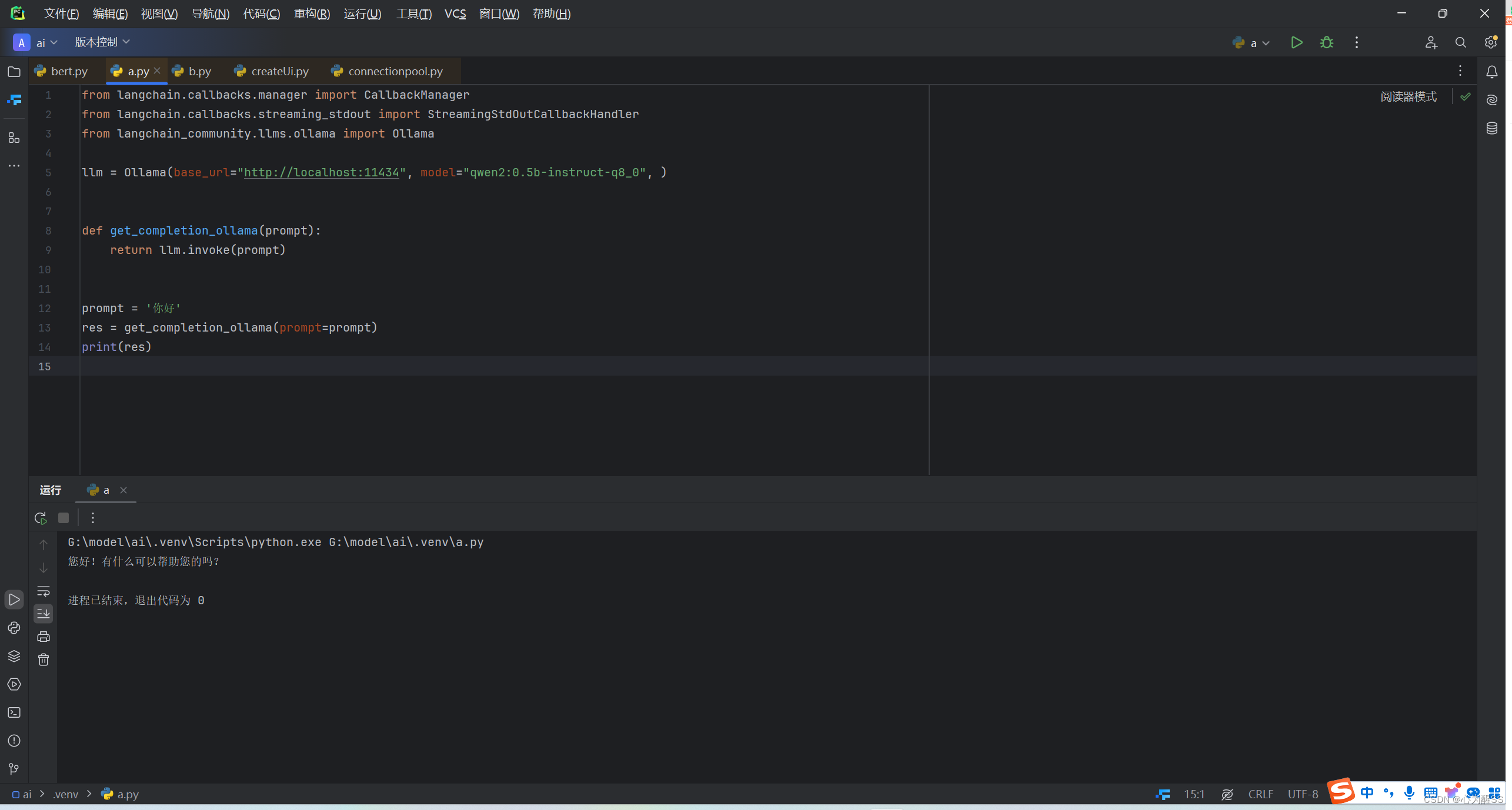
7, 如果没有特别需求,其实前面6个步骤就跑完本地模型了,但是我也想做一个chat的那种对话,那么我就需要在本地调用他,并返回数据,这一块其实大多数后端都是java,我不太会,这里抛砖引玉,用python实现一下简单的调用
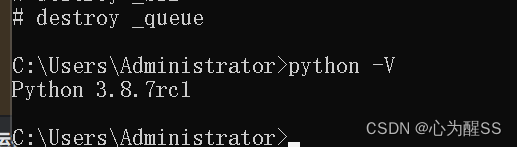
(1) python版本:3.8.7rc1
(2) 这里安装python后,还需要下载pycharm,然后打开目录,新建一个python文件,粘贴如下代码
from langchain.callbacks.manager import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
from langchain_community.llms.ollama import Ollama
llm = Ollama(base_url="http://localhost:11434", model="qwen2:0.5b-instruct-q8_0", )
def get_completion_ollama(prompt):
return llm.invoke(prompt)
prompt = '你好'
res = get_completion_ollama(prompt=prompt)
print(res)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
(3)下一步就是右键运行,这里运行可能需要下载一些依赖包,大概需要设置全局镜像源,下的会快一些
pip config --global set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip config --global set install.trusted-host pypi.tuna.tsinghua.edu.cn这里用的清华的,也可以用别的
(4)跑起来后,就会看到输出,这里本地调用就结束了