
- 1报名 | 2024中国高校计算机大赛——大数据挑战赛报名启动!
- 2产品设计_产品脑图是什么
- 3数据库中 Plugin ‘caching_sha2_password‘ /‘mysql_native_password‘ is not loaded.问题解决..._mysql native password is not loaded
- 4rabbitmq充分利mysql_Celery+rabbitmq+mysql+flower
- 5论文阅读 - Is Space-Time Attention All You Need for Video Understanding?
- 6JDBC实现java数据库连接(附完整例子+超详细注解)_java jdbc
- 7BERT模型在多语言处理中的应用与挑战_bert多语言模型
- 8Win11新系统设置跳过联网及微软账户解决方案(实测方案)_解锁你的microsoft体验如何跳过,已联网
- 9清除 Conda 缓存_conda clean --all
- 10Django-rest-framework框架之JWT认证_djangorestframework-jwt
为边缘开发由生成式 AI 驱动的视觉 AI 代理
赞
踩
为边缘开发由生成式 AI 驱动的视觉 AI 智能体

AI 技术的一项令人振奋的突破——视觉语言模型 (VLM)——为视频分析提供了一种更加动态和灵活的方法。VLM 使用户能够使用自然语言与图像和视频输入进行交互,从而使该技术更易于访问和适应。这些模型可以在 NVIDIA Jetson Orin 边缘 AI 平台或通过 NIM 在独立 GPU 上运行。这篇博文探讨了如何构建可以从边缘运行到云的基于 VLM 的可视化 AI 智能体。
什么是可视化 AI 智能体?
可视化 AI 智能体由 VLM 提供支持,您可以在其中用自然语言提出广泛的问题,并获得反映录制或直播视频中真实意图和背景的见解。这些智能体可以通过易于使用的 REST API 进行交互,并与其他服务甚至移动应用程序集成。这种新一代可视化 AI 智能体有助于总结场景、创建各种警报并使用自然语言从视频中提取可操作的见解。
NVIDIA Metropolis 带来了视觉 AI 智能体工作流,这些参考解决方案可加速由 VLM 驱动的 AI 应用程序的开发,以从视频中提取具有上下文理解的见解,无论是部署在边缘还是云端。
对于云部署,开发人员可以使用 NVIDIA NIM,这是一组推理微服务,包括行业标准 API、领域特定代码、优化的推理引擎和企业运行时,为视觉 AI 智能体提供支持。首先访问 API 目录,直接从浏览器探索和尝试基础模型。在 Metropolis NIM Workflows GitHub 页面上查看 NIM 驱动的视觉 AI 智能体示例。
这篇博文重点介绍 Jetson Orin 上边缘用例的实现,我们将探讨如何使用 NVIDIA JetPack SDK 的一项新功能 Jetson Platform Services 进行边缘部署。我们将构建一个生成式 AI 应用程序,该应用程序能够检测用户在实时视频流中以自然语言设置的事件,然后通知用户,如下图所示。

使用 Jetson 平台服务为边缘构建视觉 AI 智能体
Jetson 平台服务是一套预构建的微服务,可提供在 NVIDIA Jetson Orin 上构建计算机视觉解决方案的基本开箱即用功能。这些微服务中包含支持生成 AI 模型(例如零样本检测和最先进的 VLM)的 AI 服务。在此博客文章中了解有关 Jetson 平台服务功能亮点的更多信息。

VLM 将大型语言模型与视觉转换器相结合,从而能够对文本和视觉输入进行复杂的推理。这种灵活性使 VLM 能够用于各种用例,并且可以通过调整提示进行动态调整。
Jetson 上首选的 VLM 是 VILA,因为它具有 SOTA 推理能力,并且通过优化每个图像的标记来提高速度。下图显示了 VILA 架构和基准性能的概述。
在文章“视觉语言智能和边缘 AI 2.0”中了解有关 VILA 及其在 Jetson 上的性能的更多信息。
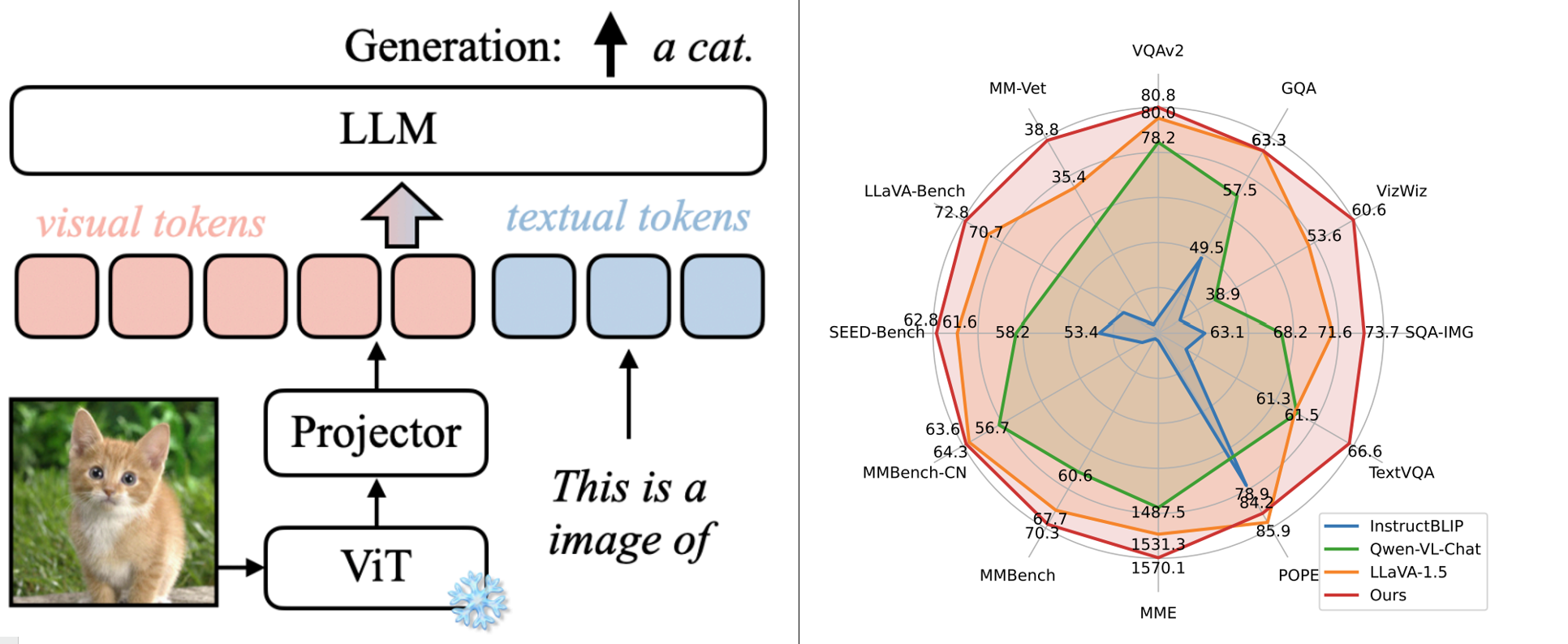
虽然 VLM 很有趣,可以用于实验并实现对输入图像的交互式对话,但将这项技术应用于实际场景至关重要。
找到让大型语言模型执行有用任务的方法并将其整合到更大的系统中非常重要。通过将 VLM 与 Jetson Platform Services 相结合,我们可以创建一个基于 VLM 的视觉 AI 智能体应用程序,该应用程序可检测直播摄像头上的事件并通过移动应用程序向用户发送通知。
该应用程序由生成式 AI 提供支持,并使用 Jetson Platform Services 中的多个组件。图 4 说明了这些组件如何协同工作以创建完整的系统。它还可以与防火墙、IoT 网关和云服务一起使用,以实现安全的远程访问。
构建基于 VLM 的视觉 AI 智能体应用程序
以下部分将介绍使用 Jetson Platform Services 构建视觉 AI 智能体系统的高级步骤。此应用程序的完整源代码位于 GitHub 上。
VLM AI 服务
第一步是围绕 VLM 构建微服务。
nanoLLM 项目提供了 Jetson Orin 上的 VLM 支持。我们可以使用 nanoLLM 库通过 Python API 在 Jetson 上下载、量化和运行 VLM,并将其转换为微服务,如图 4 所示。
我们采取以下步骤:
-
将模型包装在易于调用的函数中。
-
使用 FastAPI 添加 REST API 和 WebSocket。
-
使用 mmj_utils 添加 RTSP 流输入和输出。
-
将元数据输出到所需的通道,例如 Prometheus、Websocket 或 Redis。
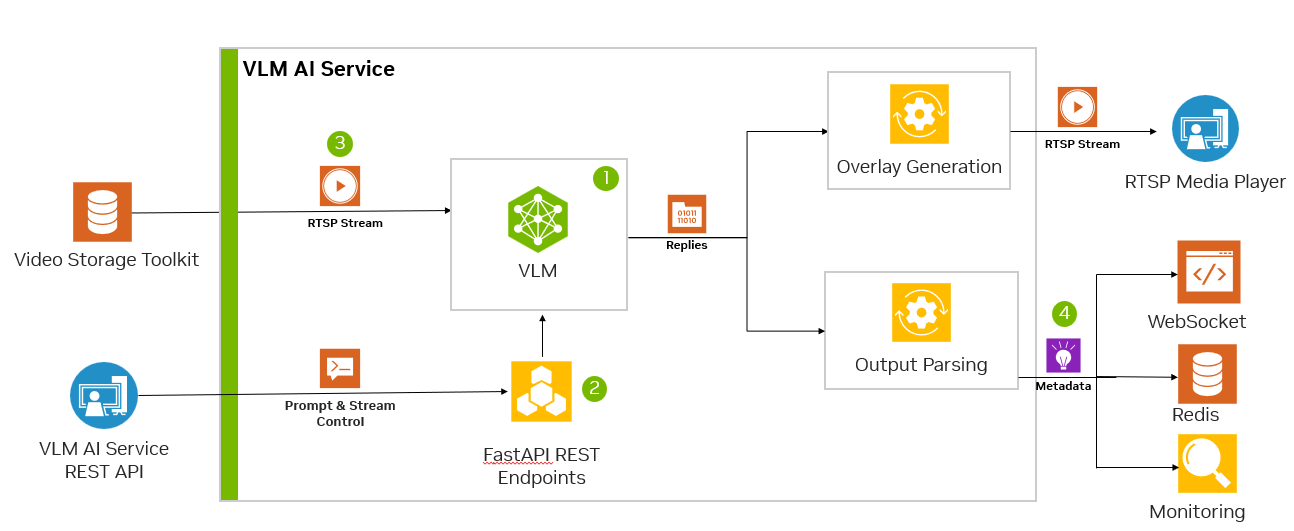
然后,微服务有一个主循环,用于检索帧、从 REST API 更新提示、调用模型,然后输出结果。以下伪代码捕获了此过程:
# Add REST API api_server = APIServer(prompt_queue) api_server.start() # Add Monitoring Metrics prometheus_metric = Gauge() prometheus.start_http_server() # Add RTSP I/O v_input = VideoSource(rtsp_input) v_output = VideoOutput(rtsp_output) # Load Model Model = model.load() While True: #Update Image & Prompt image = v_input.capture() prompt = prompt_queue.get() # Inference Model model_output = predict(image, prompt) # Generate outputs metadata = generate_metadata(image, model_output) overlay = generate_overlay(image, model_output) # Output to Redis, Monitoring, RTSP redis_server.xadd(metadata) Prometheus_metric.set(metadata) v_output.render(overlay)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
我们提供了一个实用程序库,可用作集成许多这些常见组件的起点,并在 GitHub 上提供完整的参考示例。
提示工程
VLM 提示有三个主要组件:系统提示、用户提示和输入框,如下图所示。我们可以调整 VLM 的系统和用户提示,教它如何评估直播中的警报,并以可解析和与其他服务集成的结构化格式输出结果。
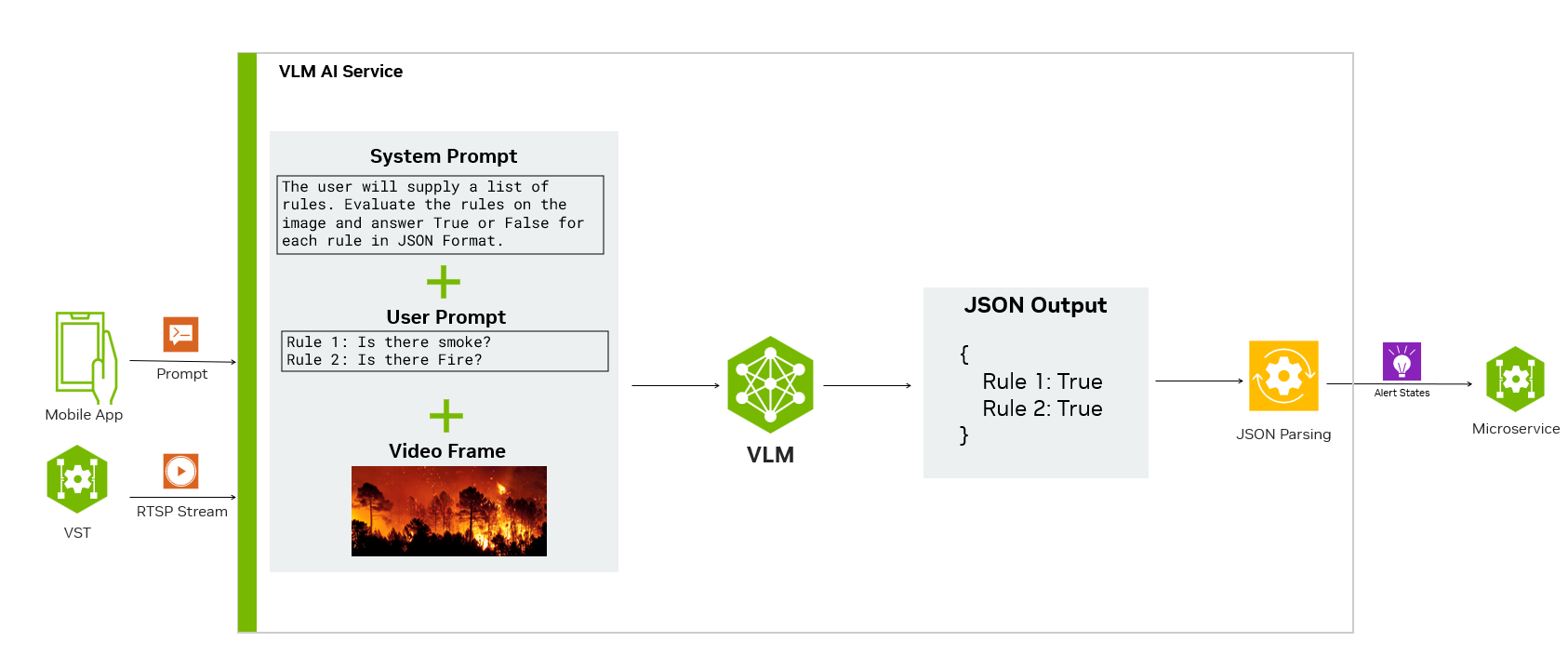
在此示例中,我们使用系统提示来解释模型的输出格式和目标。系统提示可以告知用户正在提供警报列表。提示将在输入帧上将每个警报评估为真或假,并以 JSON 格式输出结果。
然后可以通过 REST API 提供用户提示。将公开一个端点,以启用查询和警报输入。用户输入与系统提示相结合,并与来自输入实时流的帧一起提供给 VLM。然后,VLM 评估帧上的完整提示并生成响应。
此响应被解析并以 JSON 形式提供,我们使用它与警报监控服务和 WebSockets 集成,以跟踪和向移动应用程序发送警报。
与 Jetson 平台服务和移动应用程序集成
完整的端到端系统现在可以整合在一起并与移动应用程序集成,以构建由 VLM 驱动的 Visual AI 智能体。下图显示了 VLM、Jetson 平台服务、云和移动应用程序的架构图。
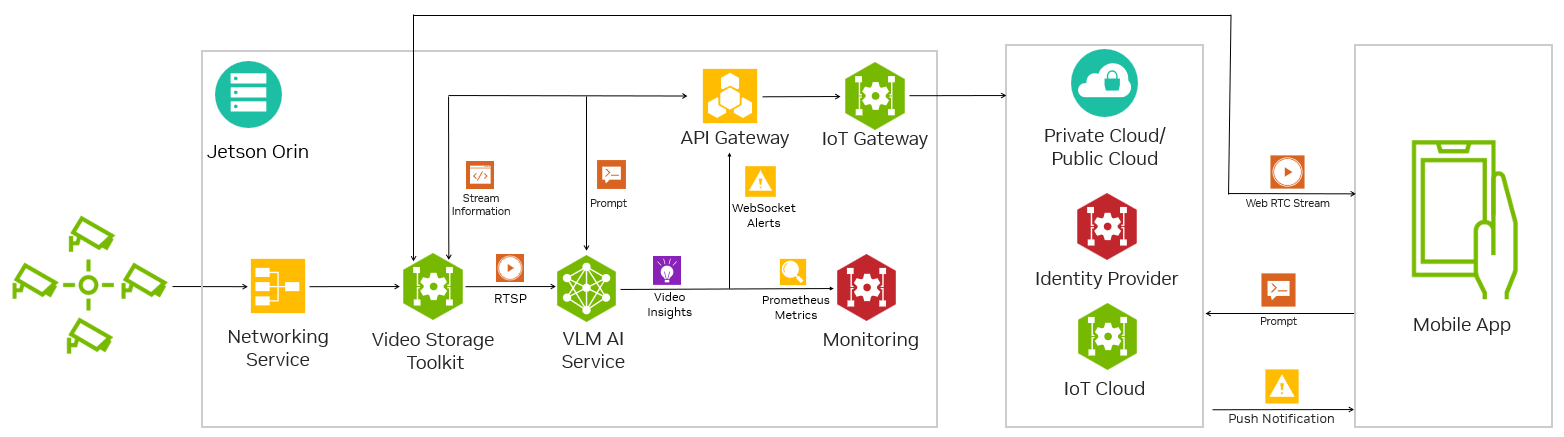
为了获取 VLM 的视频输入,Jetson Platform Services 网络服务和 VST 会自动发现并提供服务到网络的 IP 摄像头。这些通过 VST REST API 自动提供给 VLM 服务和移动应用程序。
移动应用程序通过 API 网关访问 VST 和 VLM 服务公开的 API。移动应用程序现在可以使用 VST API 获取直播流列表,并在应用程序的主屏幕上向用户显示它们的预览。
然后,用户可以从应用程序中以自然语言设置自定义警报,例如在他们选择的直播流上设置“有火吗”等警报。提交后,应用程序将从 VLM 服务调用流控制 API,告诉它使用哪个直播摄像头作为输入。然后,它将调用警报 API 来设置 VLM 的警报规则。收到这两个请求后,VLM 将开始评估直播流上的警报规则。
当 VLM 确定警报为 True 时,它会在连接到移动应用程序的 WebSocket 上输出警报状态。这将在移动设备上触发一个弹出通知,用户可以点击该通知进入聊天模式并询问后续问题。

如上图所示,用户可以与 VLM 来回聊天,讨论输入的直播流,甚至可以使用 VST 的 WebRTC 直接在应用程序中查看直播流。
借助 VLM、Jetson 平台服务和移动应用程序,您现在可以在连接到 Jetson 的直播摄像头上设置任何自定义警报并获取实时通知。

