
- 1单位内网访问外网的二种方式_nat模式和非nat模式
- 2ICML2021会议论文整理
- 3TeamSpeakaudiobot在windos服务器的部署_win安装ts3audiobot
- 4FPGA读写操作SRAM_CY7C1051DV33
- 5解决: -bash: docker-compose: command not found、linux 安装 docker-compose_docker-compose: command not found...
- 6汽车行业标准 ISO 26262案例研究_threadx满足iso26262
- 7【EI会议征稿通知】2024第三届云计算、大数据应用与软件工程国际学术会议 (CBASE 2024)_cbase2024会议
- 8OpenAI Images Generations API 申请及使用
- 9利用stm32来产生1M,1K,1Hz的3个方波(转)_stm32f411发方波
- 109款优秀的开源版本控制和源代码管理系统 转载
AccidentGPT: 多模态大模型做V2X环境感知的事故分析和预防_多模态大模型安全
赞
踩
23年12月来自北航、上海AI实验室、香港中文大学、同济大学和华盛顿大学的论文“AccidentGPT: Accident Analysis and Prevention From V2X Environmental Perception with Multi-modal Large Model“。
交通事故是造成人员伤亡和财产损失的重要原因,长期以来一直是交通安全领域许多学者的研究热点。然而,以前的研究,无论是侧重于静态环境评估还是动态驾驶分析,或者是事故前预测还是事故后规则分析,通常都是孤立进行的。缺乏一个有效的框架来发展对交通安全的全面理解和应用。为了弥补这一差距,本文引入综合事故分析和预防的多模态大模型AccidentGPT。AccidentGPT建立了一个基于多传感器感知的多模态信息交互框架,从而实现了交通安全领域事故分析和预防的整体方法。具体而言,能力分为以下几类:自动驾驶汽车,提供全面的环境感知和理解,控制车辆并避免碰撞;人类驾驶车辆,提供主动的远程安全警告和盲点警报,同时通过人机对话和互动提供安全驾驶建议和行为规范;此外,对于交通警察和管理机构,通过多车和道路测试设备实现包括行人、车辆、道路和环境的协同感知,支持交通安全的智能实时分析。该系统还能够对车辆碰撞后的事故原因和责任进行全面分析。
如图所示,AccidentGPT概览图,描绘一个全面的结构,强调其系统的任务和功能组件。该框架旨在加强交通安全研究,包括人工驾驶车辆的人机交互安全对话和相关部门的交通安全规划研究。
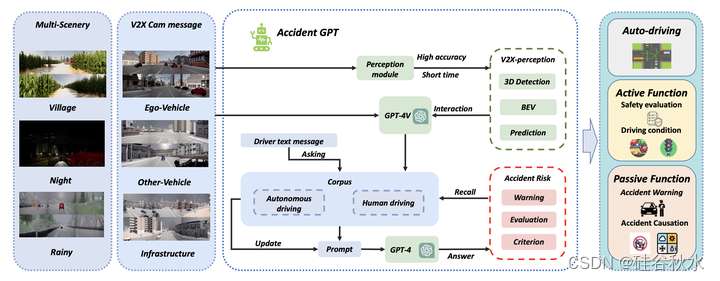
AccidentGPT主要由两个主要组件组成。
第一个是V2X感知,作为V2X架构中的综合场景感知模块。它利用来自多个车辆和路边设备的全景多摄像头信息构建了一个图像提取和分析网络。该模块的关键元素包括图像处理主干、用于图像姿态转换的视图转换器、用于多场景融合感知的融合BEV,以及用于目标检测、BEV感知和轨迹预测的多头模块。
第二个核心组件是GPT推理模块,作为自然语言的推理交互模块。这包括标准的GPT-4V模块、语料库融合下多级优先级的采样提示模块、主动-被动任务提示模块以及用于事故相关任务的多输出模块。这种配置旨在促进无缝的人机协作,利用机器语言感知和人类思维驱动的知识来提高交通安全。
对于感知模块,该任务涉及利用来自多个设备和视角的输入生成3D目标检测框、BEV感知和轨迹预测。在自然语言推理任务方面,重点是用query模块查询的感知任务输入和输出信息。这还包括构建一个可学习和更新的LLM提示语料库,通过驾驶员的主动询问和模型的被动提示来实现主动提示,为驾驶员提供被动提示,如交通安全事件的预告和警告。此外,它还包括回应驾驶员的积极询问,处理交通部门发起的任务,如道路交通安全风险评估和确定交通事故责任。
总之来说,该综合框架旨在解决与交通和车辆安全相关的各种任务,特别是在自动驾驶和人机交互的背景。
V2X感知框架是AccidentGPT感知工作的核心组成部分。该框架无缝集成并提取多辆车和道路测试设备的全景多图像特征。通过构建良好的深度学习框架,它有效地为车辆生成准确的3D检测框、BEV视角下的感知结果和轨迹预测结果。这些输出是GPT推理的关键输入,使框架成为AccidentGPT感知过程的重要元素。V2X感知框架在增强整体路边交通环境感知和地图重建方面发挥着关键作用。这将有助于推进自动驾驶汽车的协同安全驾驶、人类驾驶汽车的远程和盲点安全警报、人机交互以及交通环境和事故的实时评估。
具体来说,在协作感知领域,从BEVerse和DeepAccident中汲取灵感,开发了V2X架构下的全局感知模块,称为V2X感知,如图所示。
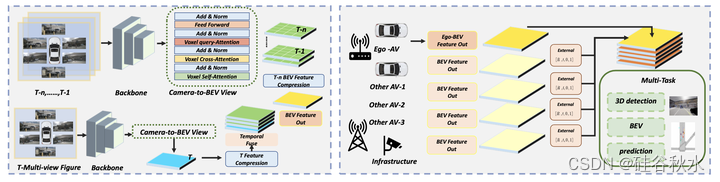
对于来自图像的输入数据,基于图像主干对每个图像进行预处理,提取不同的信息和特征。随后,由每辆车或每台设备中的环视摄像头捕获的信息被输入到cross-transformer网络中。此外,基于摄像头参数建立了一种摄像头-到-BEV,有助于将各种车辆或道路测试设备的信息转换为BEV的视角。
为了提高全局感知的全面性和识别精度,在Ego-motion-T的变换下,对每辆车和道路测试设备在不同时间序列提取感知信息进行对齐。这种对齐导致构造表示完整状态的BEV特征。
为了优化任务的输出类型、效率和质量,作者设计多个检测头来实现各种任务输出。其中包括传统的3D目标检测、BEV透视图构建和多车轨迹预测。这些任务统一采用BEV特征输出进行采样和检测提取,从而提高了多任务感知工作的准确性和完整性。
GPT推理框架是AccidentGPT功能的核心元素。对感知信息和各种收集的数据进行复杂的融合和提取,这样在GPT-4V的语义mega模型中引入多个模块。这些模块有效地为人机协作和被动信息检索提供了先进的主动提示。目标是增强人机协作的语义交互框架,解决交通安全警告和警报中的主动和被动任务。其反过来又旨在提升人类和计算机之间的双向安全使命。
具体而言,在V2X感知模块中,构建的模型实现多辆车和道路测试的全面协同感知,产生了3D目标检测和轨迹预测等输出。该模块为GPT推理提供了先验知识,有助于更高效、更准确的感知信息支持。
在推理模块中,定义多个决策任务,建立了语料库融合下多级优先级的采样提示模块、被动和主动任务提示模块,以及各种事故相关任务的输出模块。这种方法在标准GPT-4V框架的支持下,准确感知和描述决策任务,为驾驶员提供先进的主动和被动提示,或为交通和规划部门提供实时道路交通环境评估和事故原因分析报告。这有助于减少人-机的不等,从而提高人-车互动效率,最终减少交通事故的发生。
具体而言,推理的计算和交互过程如图所示,包括输入、查询、语料库采样、提示生成、LLM计算、主动/被动提示、语料库更新和输出模块。
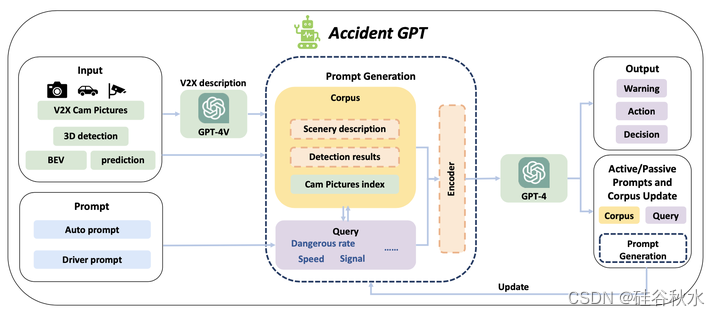
人机对话和互动,提供主动远程安全警告和盲点警报,改进安全驾驶建议和行为指南。这个旨在为驾驶员实施两套不同的提示规则,调整提示频率以确保安全余地。具体来说,在主动/被动提示和语料库更新模块中,可以利用LLM在提示模块的帮助下执行主动和被动提示任务。LLM评估正在进行的行为是否与驾驶员的预期安全风险提示范围一致,从而实现主动提示。提示的信息随后被用作后续提示的先验知识,积累了宝贵的安全余地经验,丰富了语料库模块。在系统识别出重大安全风险的情况下,无论驾驶员的提示要求如何,都需要发出风险提示,可能涉及自适应驾驶策略。
对于语料库更新,作者引入了一种迭代更新方法,该方法不断从过去的事故案例和决策中学习,逐步增强模块的稳健性和推理准确性,将推理能力提升到更高的维度,如图所示。
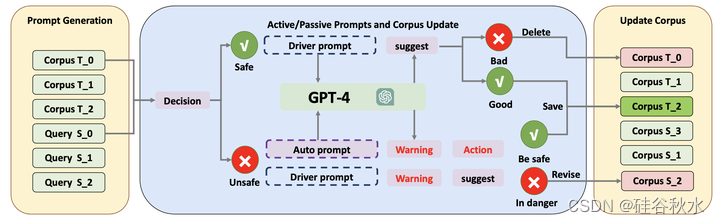
具体来说,在驾驶任务中,基于驾驶场景的输入,记录使用的提示,以及LLM为每个决策帧生成的相应决策。一旦驾驶会话在没有碰撞或危险事件的情况下结束,表示成功完成,AccintGPT将从序列中对关键决策帧进行采样。这些帧是评估风险体验必须的,所以能丰富语料库模块。相反,如果当前场景导致危险情况,例如由于误判和决策导致的碰撞,表明系统决策存在偏差,则会对其进行语义记录,改善未来的决策结果。这个迭代过程逐渐让AccidentGPT系统能够从错误中吸取教训。
文章提供了三个案例研究,来说明了AccidentGPT的主要功能。
如图所示,对于自动驾驶车,该模型基于个体车辆智能、车-车协同和车-路协同进行全面的环境感知和理解。它实现了精确的场景感知、目标检测和轨迹预测,实现了有效的防撞。
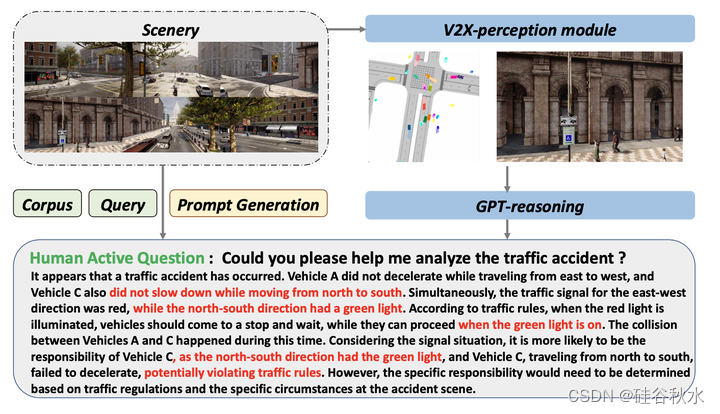
对于人类驾驶的车辆,如图所示,驾驶员主动询问交通状况。AccidentGPT模型利用V2X感知模块来解释图像,将其与GPT推理网络相结合,并为驾驶员提供有关车辆、道路和特定地标的判断和预测。这种互动的结果是向驾驶员提供警告和建议。
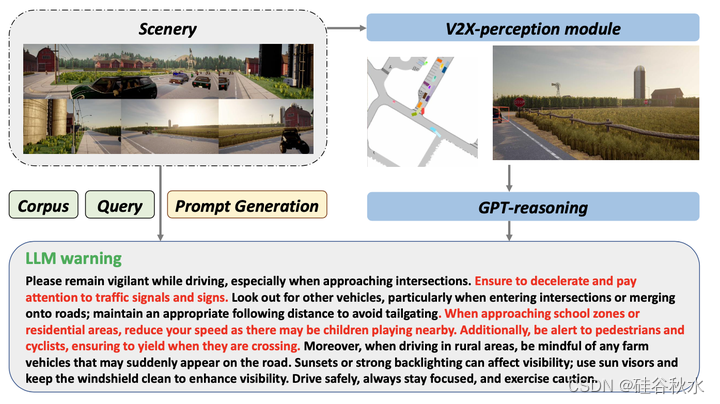
如图所示,在驾驶员在上一次对话中设置的安全警报阈值指导下,当车辆接近复杂的十字路口或区域时,大模型采取积极主动的姿态,提供安全驾驶建议。它建议驾驶员在没有信号的十字路口保持谨慎,并强调黄昏时背光条件带来的能见度挑战。这种积极主动的方法旨在根据当前的环境条件及时向驾驶员发出警告。因此,它可以为驾驶员提供主动的远程安全警告和盲点警报,并通过人机对话和互动提供更好的安全驾驶建议和行为指南。
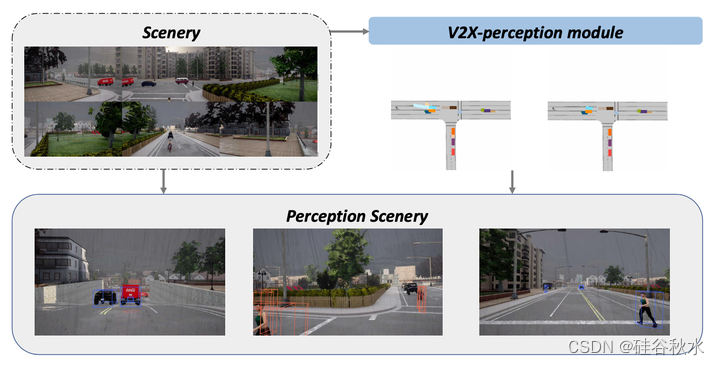
如图所示,对于交通警察和管理机构,可以通过多辆车辆和道路测试设备的协同感知,实现对行人、车辆、道路和环境的智能实时交通安全分析和综合评估报告。这包括对交通安全的深入分析,对车辆碰撞后的事故原因和责任进行全面评估和分析。
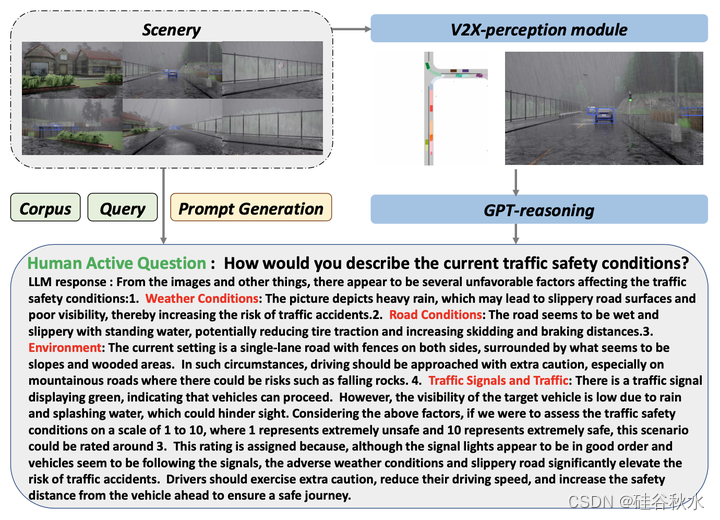
注:该文对LLM的应用比较直接。

