
热门标签
热门文章
- 1vite+vue3+typeScript+elementPlus(elementUI)搭建项目_使用vue3 + elementplus 快速搭建项目
- 2都说B站难爬?这也不难!_为什么爬虫爬不到哔哩哔哩的
- 3CrossOver 23 震撼发布,会哪些新功能呢?_crossover 游戏
- 4springboot教程第一课_服务搭建及接口开发_接口挡板开发
- 5L1-036 A乘以B-java
- 6软件需求说明书(系统)_系统需求书
- 7蓝桥杯之Python算法设计系列(一)_蓝桥杯可以使用pycharm吗
- 8eclipse启动无法找到类(自定义监听器)_eclipse运行项目提示找不到类
- 9CVPR2021论文列表(中英对照)_stylemix: separating content and style for enhance
- 10常用的adb shell命令
当前位置: article > 正文
数据结构之单向链表
作者:程序安全守护者 | 2024-02-05 17:41:27
赞
踩
单向链表
单向链表中的每个结点都有一个数据域、一个指针域。
数据域用来存储结点的数据,指针域用来存储下一个结点所在的内存空间地址。
这里完成了单向链表的五个基本功能,初始化、头插法、尾插法、删除结点、遍历链表。
一、代码结构
1.1单向链表的数据结构
- typedef struct node
- {
- int data;//数据域
- struct node * next;//指针域
- }Node;
结点结构体中,数据域用整型变量data存储数据,指针域用指针变量next存储后继结点所在的内存空间地址。
1.2操作单向链表的五个方法
1.2.1 Node * initialize()
初始化单向链表,返回头结点指针
1.2.2 void headInsert(Node * head,int data)
头插法,每次插入的新结点都会出现在首结点(第一个结点)的位置,也就是头结点的后面
1.2.3 void tailInsert(Node * head,int data)
尾插法,每次插入的新结点都会成为末结点的后继结点,变成新的末结点
1.2.4 int delete(Node * head,int data)
删除结点,根据指定的数据,删除对应的结点,删除成功返回1,删除失败返回0
1.2.5 void reveal(Node * head)
遍历单向链表
二、主要代码
- /*
- 单向链表
- 初始化
- 头插法
- 尾插法
- 删除元素
- 遍历链表
- */
- #include<stdio.h>
- #include<stdlib.h>
- //定义单向链表的数据结构
- typedef struct node
- {
- int data;//数据域
- struct node * next;//指针域
- }Node;
-
- //初始化链表
- Node * initialize()
- {
- Node * head=(Node*)(malloc(sizeof(Node)));//头结点(我更愿意称它为源结点)
- head->data=0;//头结点的数据域用来存储单链表中结点的个数
- head->next=NULL;//头结点指针域中当前为空,无指向
- return head;
- }
- //头插法
- void headInsert(Node * head,int data)
- {
- Node * newborn=(Node*)(malloc(sizeof(Node)));//创建新结点
- newborn->data=data;//给新结点的数据域赋值
- newborn->next=head->next;//给新结点的指针域赋值,值为头结点指针域的值
- head->next=newborn;//将头结点指针域指向新结点
- head->data++;//头结点的数据域自增,即单链表的结点个数增加
- }
- //尾插法
- void tailInsert(Node * head,int data)
- {
- Node * newborn=(Node*)(malloc(sizeof(Node)));//创建新结点
- newborn->data=data;//给新结点的数据域赋值
- newborn->next=NULL;//新结点的指针域值为空
- Node * start=head->next;//指针变量start通过头结点的指针域指向单链表中第一个结点
- while(start->next)//指针变量start的指针域若为NULL,则当前结点为末结点,循环终止
- {
- start=start->next;//结点向后遍历
- }
- start->next=newborn;//末结点指针域指向新结点
- head->data++;//头结点数据域自增
- }
- //删除元素
- int delete(Node * head,int data)
- {
- Node * start=head->next;//指针变量start通过头结点的指针域指向第一个结点
- Node * previousNode=head;//指针变量previousNode用来存储当前结点的前驱结点,
- while(start)//若指针变量start为NULL时,则说明没有找到指定数据,循环结束
- {
- if(start->data==data)//找到指定数据
- {
- previousNode->next=start->next;//当前结点的前驱结点指针域指向当前结点的后继结点
- free(start);//释放当前结点
- head->data--;//头结点的数据域自减,即链表中的结点数减少一个
- return 1;
- }
- previousNode=start;//previousNode存储当前结点,在下一轮循环中,将变为当前结点的前驱结点
- start=start->next;//start从当前结点向后遍历
- }
- return 0;
- }
- //遍历链表
- void reveal(Node * head)
- {
- printf("[");
- Node * start=head->next;
- for(;;start=start->next)
- {
- if(start->next!=NULL)//如果没有到达最后一个结点
- {
- printf("%d,",start->data);
- }else//否则,到达最后一个结点
- {
- printf("%d",start->data);
- break;
- }
- }
- printf("]\n");
- }
-
- int main(int argc,char * argv[])
- {
- Node * head=initialize();
- printf("head=\t%p\n",head);
-
- puts("-------------头插法-------------");
- //头插法
- headInsert(head,1);
- headInsert(head,2);
- headInsert(head,3);
- reveal(head);
- printf("length:%d\n\n",head->data);
-
- puts("-------------尾插法-------------");
- //尾插法
- tailInsert(head,4);
- tailInsert(head,5);
- tailInsert(head,6);
- reveal(head);
- printf("length:%d\n\n",head->data);
-
- puts("-------------删除结点-------------");
- puts("现有结点");
- reveal(head);
- puts("删除数据为3的结点");
- printf("%s\n",delete(head,3)==1?"删除成功":"删除失败");
- reveal(head);
- printf("length:%d\n\n",head->data);
-
- puts("删除数据为6的结点");
- printf("%s\n",delete(head,6)==1?"删除成功":"删除失败");
- reveal(head);
- printf("length:%d\n\n",head->data);
-
- puts("删除数据为1314的结点");//单链表中无此结点
- printf("%s\n",delete(head,1314)==1?"删除成功":"删除失败");
- reveal(head);
- printf("length:%d\n\n",head->data);
-
-
- }

三、运行展示
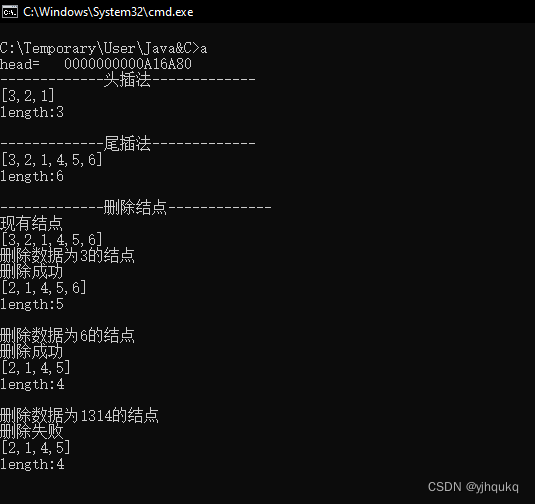
四、感受
认真学习、研究数据结构,你会发现数据结构挺有意思的。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/程序安全守护者/article/detail/61310
推荐阅读


相关标签

