
热门标签
热门文章
- 1Golang 面试题(3) 两个协程轮流打印字母和数字
- 2android.hardware.camera2详解
- 3SpringBoot数据源——为什么平时默认线程池是Hikari_hikari线程池
- 4若依框架---权限控制角色设计_若依权限字符
- 5HarmonyOS应用开发者基础认证考试题目及答案_harmonyos应用开发者基础认证答案
- 6【Python】Django搭建个人博客系统简单记录_python+django个人博客
- 7194、基于STM32单片机智能小车循迹避障小车蓝牙遥控小车设计(程序+原理图+参考论文+硬件框图+芯片设计资料+元器件清单等)_stm32小车各部分电路原理图
- 8数据库课程设计(饭店点餐系统)_数据库课程设计餐饮管理系统的e-r图
- 92023认证杯D题:低光观察黄昏系数|数学中国数学建模国际赛(小美赛) |数学建模完整代码+建模过程全解全析
- 10[附源码]Sprintboot计算机毕业设计餐馆点餐管理系统【源码+数据库+LW+部署】_数据库课程设计饭店点菜系统
当前位置: article > 正文
Python:批量url链接保存为PDF
作者:程序诗人 | 2024-02-06 12:17:09
赞
踩
Python:批量url链接保存为PDF
我的数据是先把url链接获取到存入excel中,后续对excel做的处理,各位也可以直接在程序中做处理,下面就是针对excel中的链接做批量处理
excel内容格式如下(涉及具体数据做了隐藏)
| 标题 | 文件链接 | 文件日期 |
|---|---|---|
| 网页标题1 | http://www.aaabbbcc.com.cn | 2024.2.5 |

代码逻辑:先读取excel文件内容,循环转换每一行的链接
具体代码示例:
注意:pdfkit,wkhtmltopdf一般情况下是需要安装的,已安装的忽略,wkhtmltopdf需要去官网下载安装包手动安装才可以
wkhtmltopdf下载:https://wkhtmltopdf.org/downloads.html
安装pdfkit,wkhtmltopdf
pip install pdfkit
pip install wkhtmltopdf
- 1
- 2
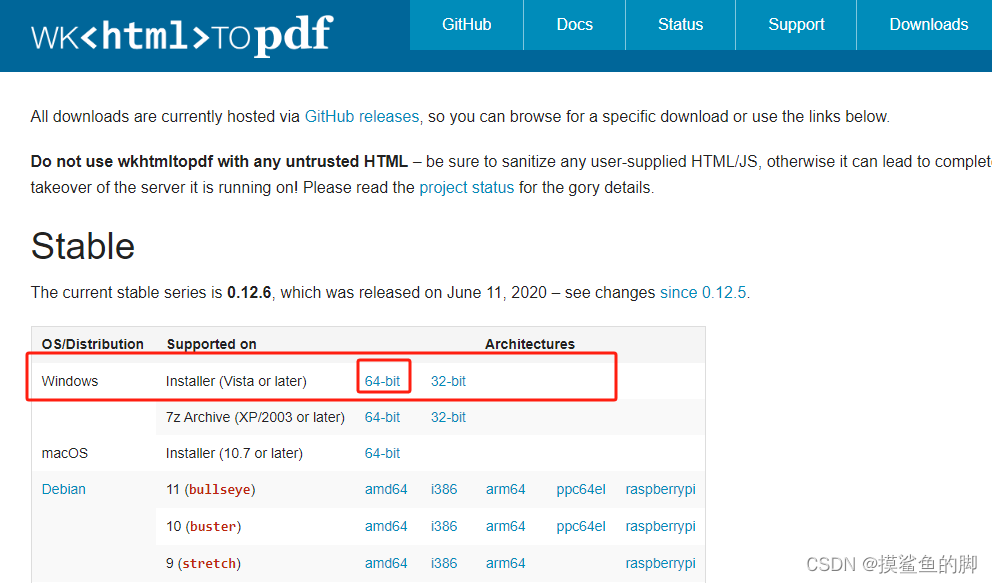
官网下载wkhtmltopdf
# 将链接的网页保存为 PDF
import pdfkit
import pandas as pd
#读取excel
df=pd.read_excel(r'D:\WeChat\WeChat Files\wxid_ec4y3bp7rexo22\FileStorage\File\2024-02\示例数据.xlsx')
#循环获取每一行数据
for index, row in df.iterrows():
url = row['文件链接'] #获取url
#配置wkhtmltopdf环境,如果在系统环境变量中已经存在可以忽略,为保证代码生效建议配置
config = pdfkit.configuration(wkhtmltopdf=r'D:\Program Files\wkhtmltopdf\bin\wkhtmltopdf.exe')
#调用URL并保存pdf,这里我把标题设置为pdf的文件名,具体设置看个人哈
pdfkit.from_url(url, r'E:\1-work\模型\爬取数据文档\pdf\{}.pdf'.format(row['标题']), configuration=config)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
运行完成!!!

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/程序诗人/article/detail/62704
推荐阅读

相关标签

