
- 1Springboot项目如何设计接口中敏感字段的加密、解密?_springboot字段加密解密
- 2ncnn源码阅读(四)----模型推理过程_ex.extract("prob", @out);
- 3需求 sql提示器和格式化,用vue-codemirror,sql-formatter,vue-highlightjs_vue3 sql-formatter
- 4关于Arduino、STM32、树莓派的介绍与区别_arduino和stm32的区别
- 5华为 笔试 4.24 第二题:这一题只通过了36%why_华为实习笔试570分
- 6C语言程序自动查错,C语言陷阱与技巧20节,自定义“编译时”assert方法,在代码编译阶段检查“逻辑”错误...
- 7STM32调试MIPI RFFE协议_stm32 mipi
- 8如何在github上创建自己的个人网站_自己的网址github
- 9nan报错
- 10python创建字典的6种方式_create dictionary用法
如何很好的理解机器学习模型,为什么大数据(Big data) 和大语言模型(Large Language Model, LLM)会变得那么火,会变得有效?_大语言模型与大数据
赞
踩
图例
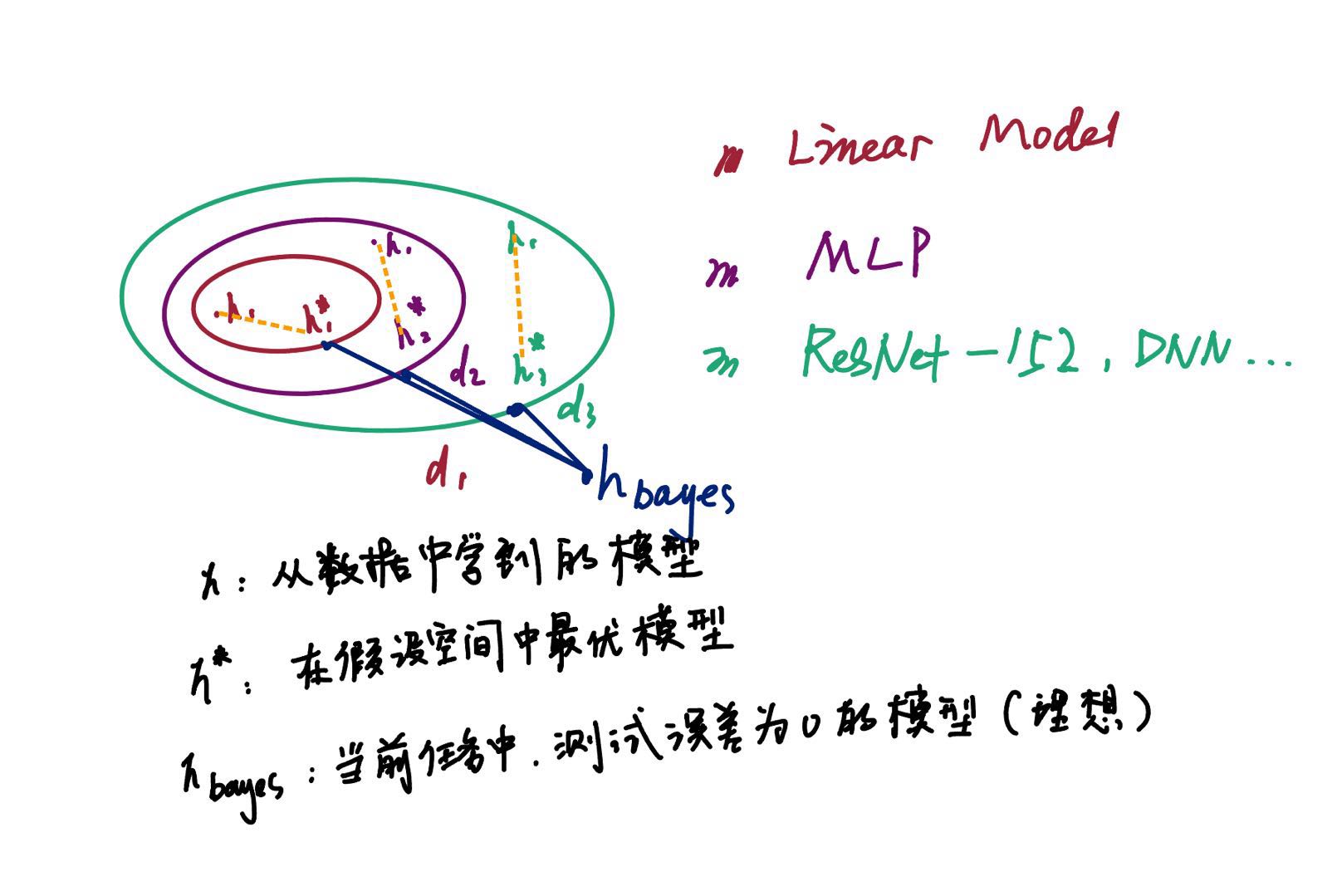
假设红色代表最简单的线性模型, 紫色代表多层感知机,绿色代表更深的模型比如ResNet-152等等.圈的大小代表假设空间(模型的参数复杂度), 复杂度越高,代表更可能接近,也就是泛化误差更小,在模型内部,如果数据干净,且数据量大,可以更好的让模型达到假设空间上的最优解(也就是更接近的模型,图中为所示),h代表使用现有数据学到的模型,它可能是在假设空间最优的,也可能是随机在假设空间的某个地方的模型. 大型语言模型(LLM)如GPT-3和GPT-4之所以有效,很大程度上归功于其庞大的数据量和巨大的假设空间。这两个因素共同作用,使得LLM在理解和生成自然语言方面表现出色。以下是详细解释:
大量数据
- 更好的泛化能力:
使用大量的数据训练LLM可以显著提高其泛化能力。模型在训练过程中遇到了多种多样的语言结构、话题和情境,因此它能够更好地理解并处理在实际使用中遇到的新样本。 - 丰富的语言知识:
大数据集包含了广泛的知识和信息,从常规对话到专业领域的术语,LLM能够学习到这些知识,并在需要时调用。 - 语境理解:
通过分析大量的上下文信息,LLM能更准确地捕捉到语言的细微差别,如同一词语在不同情境下的多种含义。 - 降低过拟合风险:
大数据集训练的模型不容易过拟合到特定的样本上,因为它接触到了多种多样的数据点,这减少了对于任何单一数据点的依赖。
巨大的假设空间
- 模型复杂性:
LLM通常拥有巨大的参数空间(如GPT-3的1750亿个参数),这使得它们有足够的复杂性来建模复杂的语言现象和细腻的语义关系。 - 特征提取:
大型假设空间允许模型学习和表示更高级的抽象特征,从单词和短语到完整的句子和段落级别的语境信息。 - 适应性:
模型可以适应各种不同的任务,无需针对特定任务进行重新训练或微调,因为庞大的假设空间让模型具备了强大的迁移学习能力。 - 细粒度的理解能力:
大型假设空间使得模型能够更精细地区分和理解语言的微妙差别,这在处理多义词、讽刺、幽默或复杂推理时尤为重要。
结合效应
当大数据量和大假设空间结合时,它们相互强化,提供了以下优势:
- 丰富的上下文感知:模型能够理解和记忆长距离的依赖关系,这对于理解复杂的语言结构和维持连贯的对话至关重要。
- 强大的推理能力:LLM可以进行更复杂的推理,包括常识推理和问题解决,这使得它们在某些任务上几乎能达到人类的水平。
- 极致的多任务学习能力:LLM在训练时不仅仅学会了一种单一任务,而是学会了多种语言任务,可以在不同任务之间进行有效切换。
综上所述,大量数据让LLM具备了广泛的知识和理解能力,而巨大的假设空间赋予了LLM足够的模型复杂性,这些因素共同作用,使得LLM在处理自然语言任务时表现出色。这种表现力使得LLM能够在多样的应用场景中发挥作用,如语言翻译、情感分析、自动文摘、问答系统、创造性写作等。事实上,大型语言模型正成为现代自然语言处理的基石,因为它们提供了一种前所未有的方式来处理和理解人类语言。
在机器学习中,( h_{bayes} ) 通常用来表示贝叶斯最优分类器(Bayes optimal classifier)。这是一个理论上的模型,它根据概率分布为每个输入选择能够使分类错误概率最小的类别标签。换句话说,( h_{bayes} ) 是在给定数据的真实分布的情况下,可能获得的最佳模型。
( h_{bayes} )与误差的关系
在理解机器学习中的误差时,( h_{bayes} )起着重要的作用,因为它定义了可能达到的最低错误率——即贝叶斯误差(Bayes error rate)。这个误差是由数据自身的噪声和不可预测性造成的,即使是最优的分类器也无法避免。贝叶斯误差实际上设定了所有模型可能达到的性能的下限。
误差类型与( h_{bayes} )
当我们讨论近似误差和估计误差时,( h_{bayes} )提供了一个参照点:
- 近似误差 可以理解为当前选择的模型类别(假设空间)中最好的模型 ( h ) 与 ( h_{bayes} ) 之间的差异。如果假设空间包含了 ( h_{bayes} ),那么理论上可以通过足够的训练数据将近似误差降低到零。然而,在实践中,我们的模型类别可能不足以捕捉所有的数据复杂性,导致近似误差不为零。
- 估计误差 是由于训练数据的有限性造成的误差,它衡量了在特定的数据集上训练得到的最佳模型 ( h ) 与实际使用的模型之间的差异。即使假设空间包含 ( h_{bayes} ),有限的数据也可能导致我们无法准确估计到 ( h_{bayes} )。
的理论价值
尽管在实际中我们可能永远无法达到或确定 ( h_{bayes} ),但它作为一个理论基准,帮助我们理解以下几点:
- 任何模型的性能都不可能超过 ( h_{bayes} )。
- 数据本身的不确定性和复杂性限制了模型的最佳可能性能。
- 在设计机器学习系统时,我们的目标是尽可能接近 ( h_{bayes} ) 对应的贝叶斯误差。
因此,( h_{bayes} ) 在机器学习中是一个理想化的概念,它帮助我们定义了模型性能的理论上限,并在评估近似误差和估计误差时提供了重要的参考。
机器学习中的**估计误差(estimation error)和近似误差(approximation error)**是理解模型性能的关键概念。它们分别描述了模型因数据限制和模型选择不完善而产生的性能损失。
Estimation Error & Approximation Error
近似误差 (Approximation Error)
近似误差是指模型因为复杂度受限而不能表示数据的真实分布的误差。这是由模型的假设容量决定的,也就是模型的功能类别的复杂性。一个模型的假设空间可能太小,以至于无法捕捉到数据的真实结构——即使给定了无限的数据和完美的训练过程。例如,在线性回归中,如果真实数据关系是非线性的,那么即使训练数据再多,线性模型也无法完美拟合数据,因为它缺乏表示非线性关系的能力。这部分误差通常与偏差(bias)的概念相关联,高偏差的模型往往有较高的近似误差。
估计误差 (Estimation Error)
估计误差是指由于训练样本有限导致的模型与训练数据的最优模型之间的差距。即使模型的假设空间包含了真实的数据分布,由于只有有限的数据点可用于训练,模型可能无法准确估计所有参数。这通常与模型的方差(variance)相关联,因为具有高方差的模型对训练数据中的随机波动更敏感,可能导致过拟合(overfitting)。换句话说,估计误差衡量的是模型对新数据泛化能力的不足。
总结
- 近似误差关注于模型复杂度与数据真实复杂度之间的不匹配,与模型的偏差相关。
- 估计误差关注于从有限数据中学习的不确定性,与模型的方差相关。
在实际的机器学习任务中,我们希望找到一个平衡点,即通过选择合适的模型复杂度来同时最小化近似误差和估计误差。这通常通过模型选择和正则化技术来实现,以避免过拟合和欠拟合,达到偏差-方差权衡(bias-variance tradeoff)。
补充问题–请问如何选择合适的模型复杂度来平衡近似误差和估计误差?
选择合适的模型复杂度来平衡近似误差和估计误差,通常需要采取一系列的策略和方法。以下是一些选择合适模型复杂度的方法:
1. 交叉验证 (Cross-Validation)
最常用的技术之一是交叉验证,尤其是k折交叉验证。通过将数据集分成k个子集,并将每个子集轮流用作验证集(其他子集用作训练集),可以评估模型在未见数据上的表现。选择在验证集上表现最佳的模型复杂度,通常可以得到较好的偏差-方差平衡。
2. 学习曲线 (Learning Curves)
学习曲线展示了模型在训练集和验证集上的表现随着训练样本数量的增加而变化的情况。如果训练误差和验证误差之间有很大的差距,那么模型可能过于复杂并且过拟合。如果两者非常接近但误差很高,则可能欠拟合。理想的模型复杂度应该能够达到两者较小的差距和相对较低的验证误差。
3. 正则化 (Regularization)
通过添加正则化项,如L1或L2正则化,可以惩罚模型权重的大小,从而降低模型复杂度。正则化参数的选择(例如,L2正则化中的λ)可以通过网格搜索(grid search)和交叉验证来确定。
4. 信息准则 (Information Criteria)
一些统计准则如赤池信息准则(AIC)和贝叶斯信息准则(BIC)可以用来选择模型。这些准则试图平衡模型的拟合好坏和模型的复杂度,从而避免过度拟合。
5. 模型选择技术
模型选择方法,如前向选择、后向消除或逐步选择,可以帮助确定保留哪些特征或模型组件。
6. 嵌入式方法 (Embedded Methods)
利用嵌入式选择方法,如决策树和基于惩罚的方法(如Lasso),这些算法在训练过程中自然地进行特征选择,从而调整模型复杂度。
7. 偏差-方差分析
理解偏差-方差权衡,并通过实验确定模型是否受到高偏差或高方差的影响,然后根据需要调整模型复杂度。
8. 集成方法 (Ensemble Methods)
使用集成方法,如随机森林或梯度提升机,可以在不显著增加单个模型复杂度的情况下,通过结合多个模型来提高整体模型的性能。
总结
选择合适的模型复杂度通常涉及到多种策略的结合使用,并且需要通过多次实验来评估不同模型复杂度下模型的性能。重点在于实现偏差和方差之间的最佳权衡,以提高模型的泛化能力。

