
- 1harmonyos官网申请完了几天推送,鸿蒙OS Beta3开发者版本申请指南!
- 2只有外包公司的offer,那没得选?_花华勤与软通
- 3MySQL数据库设计常用技巧和设计规范(三):数据库设计规范_数据库程序层dao层新代码不使用model,推荐使用手动平aql绑定变量传入参数的方
- 4神经网络模型——用户评论情感分析_用户评论情感分析模型
- 5系统安装 安装 win11 系统跳过微软账户登录_windows11安装跳过登录账户
- 6Android本地Gradle Plugin的创建以及使用
- 7应聘机器学习工程师?这是你需要知道的12个基础面试问题_robotics 面试问题
- 814、指针三剑客之二:树(结合LeetCode 104、110、543、437、101、1110、637、105、144、99、669、208学习)(99未进阶)(前缀树)_指针三剑客之三
- 9【github 仓库添加协作者 多人项目基本流程 使用token 登录 和push 时 SSL local certificate 问题结局】_github公有仓库可以有几个协作用户
- 10七大排序算法,冒泡排序 选择排序 插入排序 希尔排序 堆排序 快速排序 归并排序的深度讲解_比较说明冒泡算法,选择算法,希尔排序算法
自然语言处理(NLP)原理、用法、案例、注意事项_nlp如何使用
赞
踩
自然语言处理(Natural Language Processing,简称NLP)是人工智能(Artificial Intelligence,简称AI)领域的一个重要分支,旨在让计算机能够理解、理解和生成人类语言。
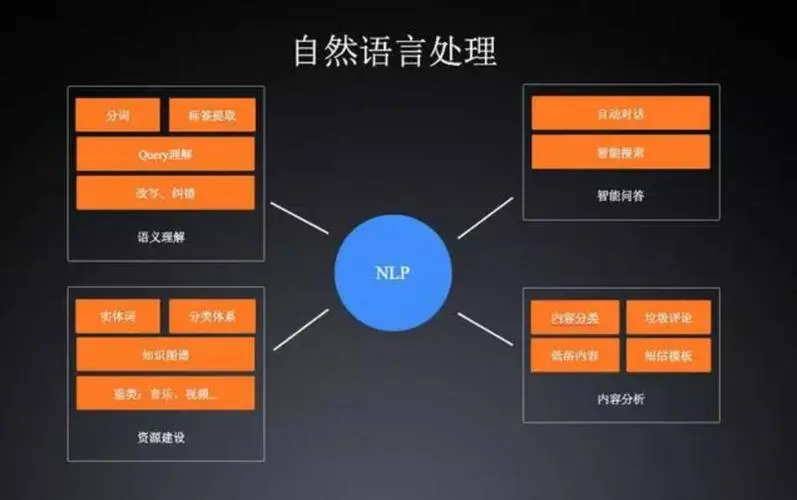
NLP的原理是基于统计建模和机器学习技术,通过对大量文本数据的分析和处理,从中提取语言规则、语义信息和模式,以实现对自然语言的处理。
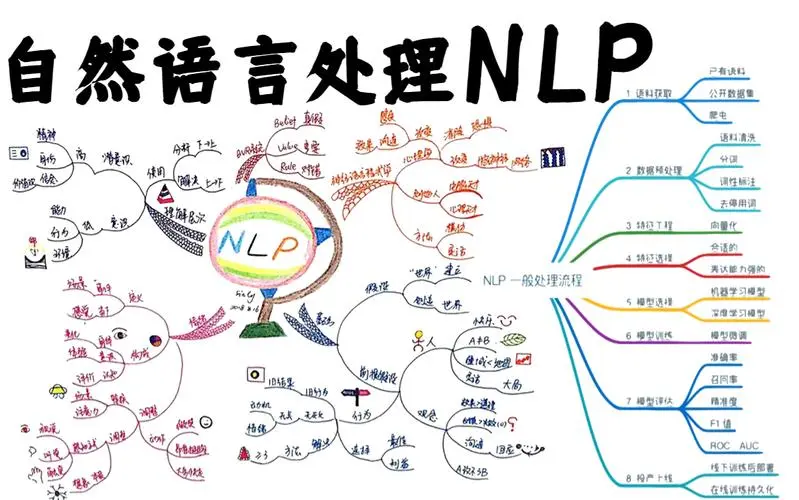
NLP的用法非常广泛,涵盖了文本分类、信息抽取、机器翻译、问答系统、情感分析、拼写纠错等方面。下面将介绍一些常见的NLP应用。
-
文本分类:通过机器学习算法将文本划分为不同的类别。例如,将电子邮件分类为垃圾邮件或正常邮件,将新闻文章分类为体育、政治、娱乐等类别。
-
信息抽取:从文本中提取出有价值的信息。例如,从新闻文章中提取出人名、地名、日期等实体信息;从电子商务网站的评论中提取出用户对产品的评价。
-
机器翻译:将一种自然语言翻译成另一种自然语言。例如,将英文翻译成中文,或将中文翻译成法文。
-
问答系统:回答用户提出的问题。例如,智能助手能够回答用户的天气查询、时间查询等问题。
-
情感分析:通过分析文本中的情感词汇,判断文本的情感倾向。例如,分析用户在社交媒体上的发言,判断其对某个话题的态度是积极的还是消极的。
-
拼写纠错:自动纠正拼写错误,提供正确的拼写建议。例如,将用户输入的“helo”纠正为“hello”。

在使用NLP技术时,有一些注意事项需要考虑:
-
数据准备:NLP的性能和效果很大程度上取决于训练数据的质量和数量。因此,在使用NLP技术之前,需要搜集和整理大量的语料库,并进行合适的预处理和标注。
-
选择合适的模型和算法:NLP涉及到词法分析、句法分析、语义理解等多个层面,每个层面都有不同的模型和算法可供选择。因此,在选择模型和算法时,需要根据具体任务的要求和数据的特点进行选择。
-
处理歧义和多义词:自然语言中存在很多歧义和多义词,这给NLP处理带来了困难。因此,在处理这些词语时,需要结合上下文信息和语境进行判断和处理。
-
处理大规模数据:NLP处理的文本数据通常非常庞大,因此需要考虑如何优化算法和模型,以提高处理效率和准确性。
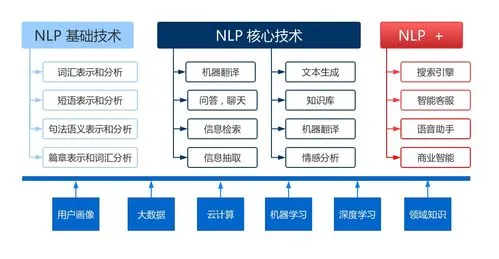
总之,NLP是一个非常有挑战性和广泛应用的领域,其应用范围涵盖了文本分类、信息抽取、机器翻译、问答系统、情感分析、拼写纠错等多个方面。在使用NLP技术时,需要注意数据准备、模型选择、歧义处理和大规模数据处理等问题。随着计算机性能的提高和数据资源的丰富,NLP的应用前景将更加广阔。

