
热门标签
热门文章
- 1JNI中的log日志_jnilog1699437787981.txta
- 2人工智能和机器学习相关的比较活跃的论坛网址列表_人工智能论坛网站
- 3sklearn包中K近邻分类器 KNeighborsClassifier的使用_from sklearn.neighbors import kneighborsclassifier
- 4【demo】用opencv+qt识别人脸与眼睛_qt opencv获取瞳孔
- 5局域网安全17 dot1x
- 6androidStudio配置安装git以及下载项目_android studio从git上下载项目
- 7【Kafka】Kafka的重复消费和消息丢失问题_kafka重复消费
- 8使用STM32芯片ID作为MAC地址_0x1fff7a10
- 9韩国Meetup | Trias,区块链公链底层的一条“高速公路”
- 10如何在自定义数据集上训练YOLOv8的各个模型_yolov8训练示例
当前位置: article > 正文
Python网络爬虫过程中,构建网络请求的时候,参数`stream=True`的使用
作者:空白诗007 | 2024-06-24 11:03:11
赞
踩
stream=true
点击上方“Python共享之家”,进行关注
回复“资源”即可获赠Python学习资料
今
日
鸡
汤
海内存知己,天涯若比邻。
大家好,我是皮皮。
一、前言
前几天在Python最强王者交流群【德善堂小儿推拿-瑜亮老师】分享了一个关于Python网络爬虫的问题,这里拿出来给大家分享下,一起学习。
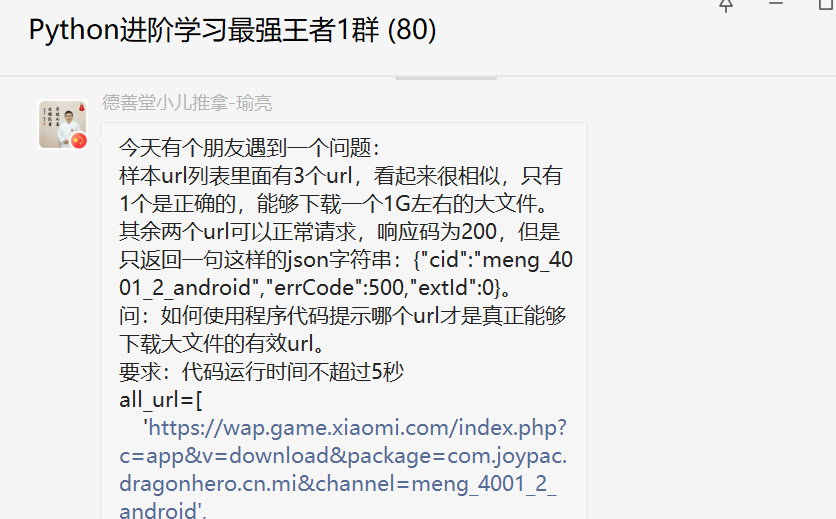
二、解决过程
这里【PI】大佬提出了思路,的确可行。
 【皮皮】给了一份代码,取巧,这里就不展示了。后来【月神】给了一份可行的代码,如下所示:
【皮皮】给了一份代码,取巧,这里就不展示了。后来【月神】给了一份可行的代码,如下所示:
- for url in all_url:
- resp = requests.get(url, headers=header, stream=True)
- content_length = resp.headers.get('content-length')
- if content_length and int(content_length) > 10240:
- print(url)
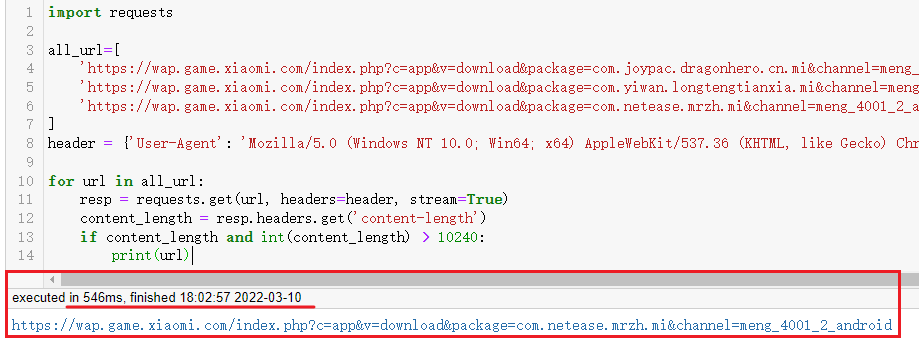
程序运行之后,不到1秒就出来结果了,没想到jupyter里边可以自动显示时间,以前也有看到,但是没有留意,Pycharm里边是没有的,这里来看,jupyter还是蛮香,Pycharm还得自己设置打印时间。
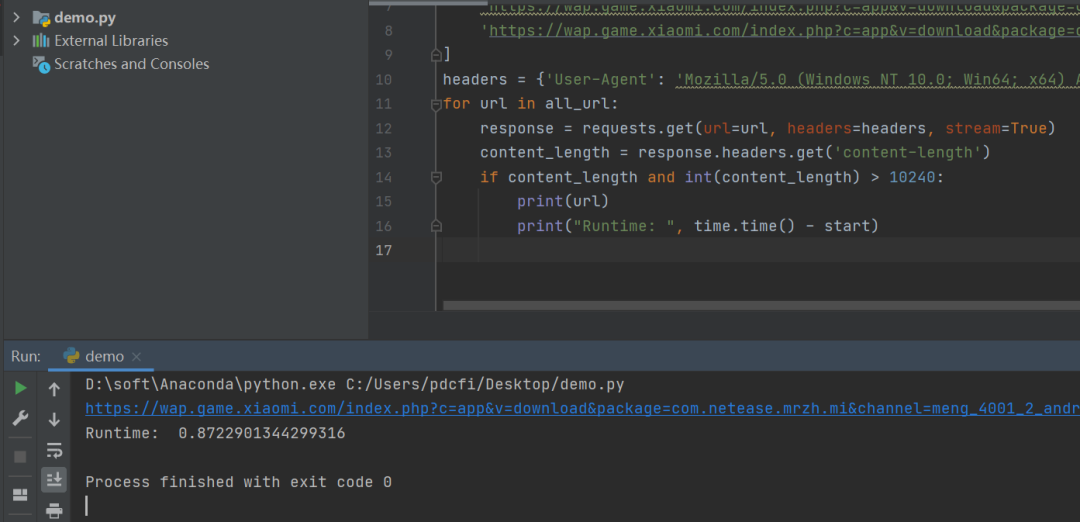
【月神】的方法完全满足题目要求,不过这个文件解析有点慢。
后来【德善堂小儿推拿-瑜亮老师】大佬摊牌了:题目就考这一个知识点:stream=True,别的都是简单的很。这里给出了代码:
- import requests
- import time
-
- url = ['https://wap.game.xiaomi.com/index.php?c=app&v=download&package=com.joypac.dragonhero.cn.mi&channel=meng_4001_2_android',
- 'https://wap.game.xiaomi.com/index.php?c=app&v=download&package=com.yiwan.longtengtianxia.mi&channel=meng_4001_2_android',
- 'https://wap.game.xiaomi.com/index.php?c=app&v=download&package=com.netease.mrzh.mi&channel=meng_4001_2_android']
- header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
-
- start = time.time()
- # 方法一:判断response.headers里面的内容
- for i in url:
- resp = requests.get(i, headers=header, stream=True)
- if 'Content-Length' in resp.headers:
- print(f'有效url有:\n {i}')
- end = time.time()
- print(f'测试完毕!共耗时: {end - start:.2f}秒')
-
- # 方法二:判断响应的字节流大小
- start2 = time.time()
- for i in url:
- resp = requests.get(i, headers=header, stream=True)
- chunk_size = 1024
- for data in resp.iter_content(chunk_size=chunk_size):
- if len(data) > 800:
- print(f'有效url有:\n {i}')
- break
- end2 = time.time()
- print(f'测试完毕!共耗时: {end2 - start2:.2f}秒')

下面是代码截图:
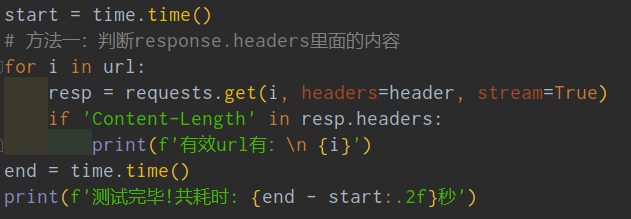
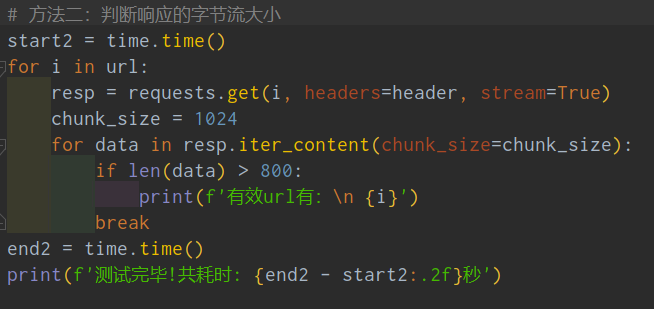 那小伙伴们就问了,那个stream参数是干啥用的啊?不慌,【月神】丢来一个解析。
那小伙伴们就问了,那个stream参数是干啥用的啊?不慌,【月神】丢来一个解析。
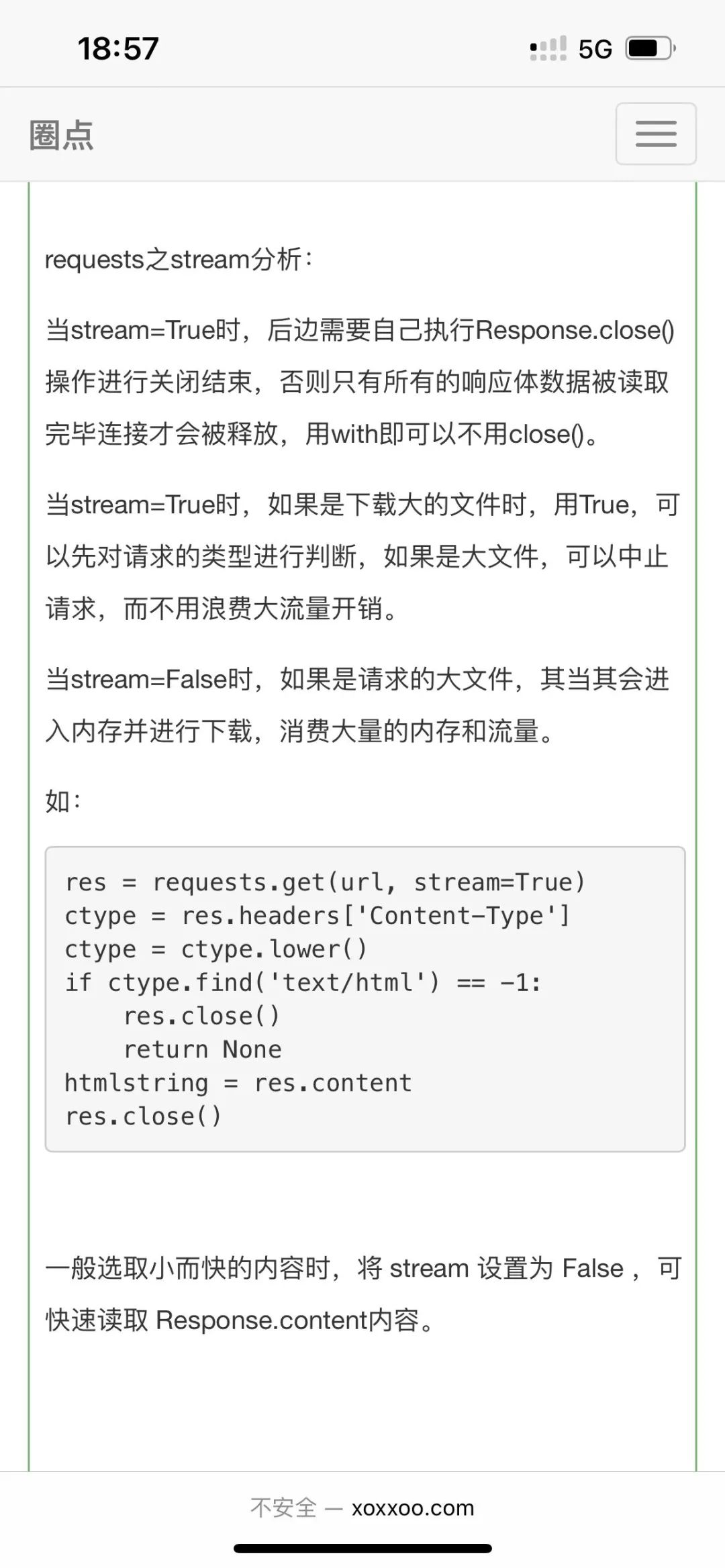
如此就清晰多了。
三、总结
大家好,我是皮皮。这篇文章主要分享了在Python网络爬虫过程中,构建网络请求的时候,参数stream=True的使用,使用了一个具体的实例给大家演示了该参数的具体用法!关于该参数的介绍,请参考文中的解析。
最后感谢【德善堂小儿推拿-瑜亮老师】分享,感谢【皮皮】、【PI】、【月神】大佬给出的思路和代码支持,感谢粉丝【冫马讠成】、【孤独】等人参与学习交流。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/空白诗007/article/detail/752568
推荐阅读

相关标签

