
- 1四种常用的标准自定义View方法(上)_使用过那些自定义view
- 2mac 生成目录结构tree brew安装_tree brew下载
- 3MySQL8.4 安装配置与卸载_mysql8.4安装
- 4linux桌面安全审计,Linux安全审计功能的实现——audit详解
- 5使用ExcelWriter导出数据到excel表时出现字段缺失的问题 2021.6.30_excelwriter.write() 导出没数据
- 6python 堆的使用 heapq_heapq 包
- 7如何不使用代理服务从hugging face上下载大模型?_hugging face 代理
- 8GitBook 从懵逼到入门
- 9Android程序设计之音乐播放器实现_android开发音乐播放器
- 10转--Hadoop集群部署案例
用深度学习实现命名实体识别(NER)_领域命名实体识别语料库
赞
踩
目录
前言
几乎所有的NLP都依赖一个强大的语料库,本项目实现NER的语料库如下(文件名为train.txt,一共42000行,这里只展示前15行,可以在文章最后的Github地址下载该语料库):
played on Monday ( home team in CAPS ) :
VBD IN NNP ( NN NN IN NNP ) :
O O O O O O O O O O
American League
NNP NNP
B-MISC I-MISC
Cleveland 2 DETROIT 1
NNP CD NNP CD
B-ORG O B-ORG O
BALTIMORE 12 Oakland 11 ( 10 innings )
VB CD NNP CD ( CD NN )
B-ORG O B-ORG O O O O O
TORONTO 5 Minnesota 3
TO CD NNP CD
B-ORG O B-ORG O
……
简单介绍下该语料库的结构:该语料库一共42000行,每三行为一组,其中,第一行为英语句子,第二行为每个句子的词性,第三行为NER系统的标注,具体的含义会在之后介绍。
我们的NER项目的名称为DL_4_NER,结构如下:
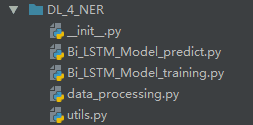
项目中每个文件的功能如下:
-
utils.py: 项目配置及数据导入
-
data_processing.py: 数据探索
-
Bi_LSTM_Model_training.py: 模型创建及训练
-
Bi_LSTM_Model_predict.py: 对新句子进行NER预测
接下来,笔者将结合代码文件,分部介绍该项目的步骤,当所有步骤介绍完毕后,我们的项目就结束了,而你,也就知道了如何用深度学习实现命名实体识别(NER)。
Let's begin!
项目配置
第一步,是项目的配置及数据导入,在utils.py文件中实现,完整的代码如下:
- # -*- coding: utf-8 -*-
- import numpy as np
- import pandas as pd
-
- # basic settings for DL_4_NER Project
- BASE_DIR = "F://NERSystem"
- CORPUS_PATH = "%s/train.txt" % BASE_DIR
-
- KERAS_MODEL_SAVE_PATH = '%s/Bi-LSTM-4-NER.h5' % BASE_DIR
- WORD_DICTIONARY_PATH = '%s/word_dictionary.pk' % BASE_DIR
- InVERSE_WORD_DICTIONARY_PATH = '%s/inverse_word_dictionary.pk' % BASE_DIR
- LABEL_DICTIONARY_PATH = '%s/label_dictionary.pk' % BASE_DIR
- OUTPUT_DICTIONARY_PATH = '%s/output_dictionary.pk' % BASE_DIR
-
- CONSTANTS = [
- KERAS_MODEL_SAVE_PATH,
- InVERSE_WORD_DICTIONARY_PATH,
- WORD_DICTIONARY_PATH,
- LABEL_DICTIONARY_PATH,
- OUTPUT_DICTIONARY_PATH
- ]
-
- # load data from corpus to from pandas DataFrame
- def load_data():
- with open(CORPUS_PATH, 'r') as f:
- text_data = [text.strip() for text in f.readlines()]
- text_data = [text_data[k].split('\t') for k in range(0, len(text_data))]
- index = range(0, len(text_data), 3)
-
- # Transforming data to matrix format for neural network
- input_data = list()
- for i in range(1, len(index) - 1):
- rows = text_data[index[i-1]:index[i]]
- sentence_no = np.array([i]*len(rows[0]), dtype=str)
- rows.append(sentence_no)
- rows = np.array(rows).T
- input_data.append(rows)
-
- input_data = pd.DataFrame(np.concatenate([item for item in input_data]),\
- columns=['word', 'pos', 'tag', 'sent_no'])
-
- return input_data

在该代码中,先是设置了语料库文件的路径CORPUS_PATH,KERAS模型保存路径KERAS_MODEL_SAVE_PATH,以及在项目过程中会用到的三个字典的保存路径(以pickle文件形式保存)WORD_DICTIONARY_PATH,LABEL_DICTIONARY_PATH, OUTPUT_DICTIONARY_PATH。然后是load_data()函数,它将语料库中的文本以Pandas中的DataFrame结构展示出来,该数据框的前30行如下:
- word pos tag sent_no
- 0 played VBD O 1
- 1 on IN O 1
- 2 Monday NNP O 1
- 3 ( ( O 1
- 4 home NN O 1
- 5 team NN O 1
- 6 in IN O 1
- 7 CAPS NNP O 1
- 8 ) ) O 1
- 9 : : O 1
- 10 American NNP B-MISC 2
- 11 League NNP I-MISC 2
- 12 Cleveland NNP B-ORG 3
- 13 2 CD O 3
- 14 DETROIT NNP B-ORG 3
- 15 1 CD O 3
- 16 BALTIMORE VB B-ORG 4
- 17 12 CD O 4
- 18 Oakland NNP B-ORG 4
- 19 11 CD O 4
- 20 ( ( O 4
- 21 10 CD O 4
- 22 innings NN O 4
- 23 ) ) O 4
- 24 TORONTO TO B-ORG 5
- 25 5 CD O 5
- 26 Minnesota NNP B-ORG 5
- 27 3 CD O 5
- 28 Milwaukee NNP B-ORG 6
- 29 3 CD O 6
在该数据框中,word这一列表示文本语料库中的单词,pos这一列表示该单词的词性,tag这一列表示NER的标注,sent_no这一列表示该单词在第几个句子中。
数据探索
接着,第二步是数据探索,即对输入的数据(input_data)进行一些数据review,完整的代码(data_processing.py)如下:
- # -*- coding: utf-8 -*-
-
- import pickle
- import numpy as np
- from collections import Counter
- from itertools import accumulate
- from operator import itemgetter
- import matplotlib.pyplot as plt
- import matplotlib as mpl
- from utils import BASE_DIR, CONSTANTS, load_data
-
- # 设置matplotlib绘图时的字体
- mpl.rcParams['font.sans-serif']=['SimHei']
-
- # 数据查看
- def data_review():
-
- # 数据导入
- input_data = load_data()
-
- # 基本的数据review
- sent_num = input_data['sent_no'].astype(np.int).max()
- print("一共有%s个句子。\n"%sent_num)
-
- vocabulary = input_data['word'].unique()
- print("一共有%d个单词。"%len(vocabulary))
- print("前10个单词为:%s.\n"%vocabulary[:11])
-
- pos_arr = input_data['pos'].unique()
- print("单词的词性列表:%s.\n"%pos_arr)
-
- ner_tag_arr = input_data['tag'].unique()
- print("NER的标注列表:%s.\n" % ner_tag_arr)
-
- df = input_data[['word', 'sent_no']].groupby('sent_no').count()
- sent_len_list = df['word'].tolist()
- print("句子长度及出现频数字典:\n%s." % dict(Counter(sent_len_list)))
-
- # 绘制句子长度及出现频数统计图
- sort_sent_len_dist = sorted(dict(Counter(sent_len_list)).items(), key=itemgetter(0))
- sent_no_data = [item[0] for item in sort_sent_len_dist]
- sent_count_data = [item[1] for item in sort_sent_len_dist]
- plt.bar(sent_no_data, sent_count_data)
- plt.title("句子长度及出现频数统计图")
- plt.xlabel("句子长度")
- plt.ylabel("句子长度出现的频数")
- plt.savefig("%s/句子长度及出现频数统计图.png" % BASE_DIR)
- plt.close()
-
- # 绘制句子长度累积分布函数(CDF)
- sent_pentage_list = [(count/sent_num) for count in accumulate(sent_count_data)]
-
- # 寻找分位点为quantile的句子长度
- quantile = 0.9992
- #print(list(sent_pentage_list))
- for length, per in zip(sent_no_data, sent_pentage_list):
- if round(per, 4) == quantile:
- index = length
- break
- print("\n分位点为%s的句子长度:%d." % (quantile, index))
-
- # 绘制CDF
- plt.plot(sent_no_data, sent_pentage_list)
- plt.hlines(quantile, 0, index, colors="c", linestyles="dashed")
- plt.vlines(index, 0, quantile, colors="c", linestyles="dashed")
- plt.text(0, quantile, str(quantile))
- plt.text(index, 0, str(index))
- plt.title("句子长度累积分布函数图")
- plt.xlabel("句子长度")
- plt.ylabel("句子长度累积频率")
- plt.savefig("%s/句子长度累积分布函数图.png" % BASE_DIR)
- plt.close()
-
- # 数据处理
- def data_processing():
- # 数据导入
- input_data = load_data()
-
- # 标签及词汇表
- labels, vocabulary = list(input_data['tag'].unique()), list(input_data['word'].unique())
-
- # 字典列表
- word_dictionary = {word: i+1 for i, word in enumerate(vocabulary)}
- inverse_word_dictionary = {i+1: word for i, word in enumerate(vocabulary)}
- label_dictionary = {label: i+1 for i, label in enumerate(labels)}
- output_dictionary = {i+1: labels for i, labels in enumerate(labels)}
-
- dict_list = [word_dictionary, inverse_word_dictionary,label_dictionary, output_dictionary]
-
- # 保存为pickle形式
- for dict_item, path in zip(dict_list, CONSTANTS[1:]):
- with open(path, 'wb') as f:
- pickle.dump(dict_item, f)
-
- #data_review()
调用data_review()函数,输出的结果如下:
- 一共有13998个句子。
-
- 一共有24339个单词。
- 前10个单词为:['played' 'on' 'Monday' '(' 'home' 'team' 'in' 'CAPS' ')' ':' 'American'].
-
- 单词的词性列表:['VBD' 'IN' 'NNP' '(' 'NN' ')' ':' 'CD' 'VB' 'TO' 'NNS' ',' 'VBP' 'VBZ'
- '.' 'VBG' 'PRP$' 'JJ' 'CC' 'JJS' 'RB' 'DT' 'VBN' '"' 'PRP' 'WDT' 'WRB'
- 'MD' 'WP' 'POS' 'JJR' 'WP$' 'RP' 'NNPS' 'RBS' 'FW' '$' 'RBR' 'EX' "''"
- 'PDT' 'UH' 'SYM' 'LS' 'NN|SYM'].
-
- NER的标注列表:['O' 'B-MISC' 'I-MISC' 'B-ORG' 'I-ORG' 'B-PER' 'B-LOC' 'I-PER' 'I-LOC'
- 'sO'].
-
- 句子长度及出现频数字典:
- {1: 177, 2: 1141, 3: 620, 4: 794, 5: 769, 6: 639, 7: 999, 8: 977, 9: 841, 10: 501, 11: 395, 12: 316, 13: 339, 14: 291, 15: 275, 16: 225, 17: 229, 18: 212, 19: 197, 20: 221, 21: 228, 22: 221, 23: 230, 24: 210, 25: 207, 26: 224, 27: 188, 28: 199, 29: 214, 30: 183, 31: 202, 32: 167, 33: 167, 34: 141, 35: 130, 36: 119, 37: 105, 38: 112, 39: 98, 40: 78, 41: 74, 42: 63, 43: 51, 44: 42, 45: 39, 46: 19, 47: 22, 48: 19, 49: 15, 50: 16, 51: 8, 52: 9, 53: 5, 54: 4, 55: 9, 56: 2, 57: 2, 58: 2, 59: 2, 60: 3, 62: 2, 66: 1, 67: 1, 69: 1, 71: 1, 72: 1, 78: 1, 80: 1, 113: 1, 124: 1}.
-
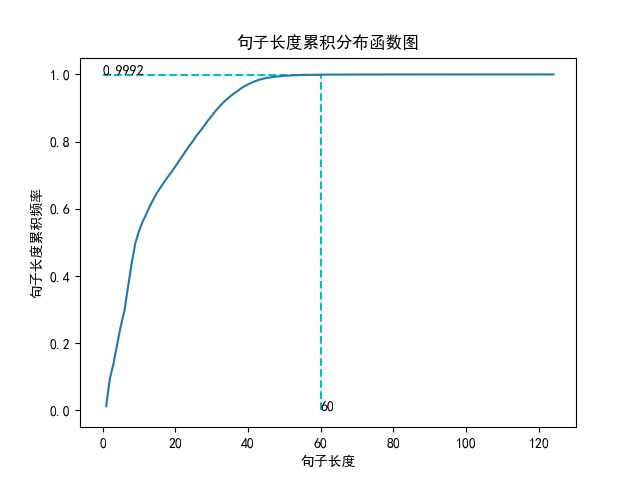
- 分位点为0.9992的句子长度:60.
在该语料库中,一共有13998个句子,比预期的42000/3=14000个句子少两个。一个有24339个单词,单词量还是蛮大的,当然,这里对单词没有做任何处理,直接保留了语料库中的形式(后期可以继续优化)。我们需要注意的是,NER的标注列表为['O' ,'B-MISC', 'I-MISC', 'B-ORG' ,'I-ORG', 'B-PER' ,'B-LOC' ,'I-PER', 'I-LOC','sO'],因此,本项目的NER一共分为四类:PER(人名),LOC(位置),ORG(组织)以及MISC,其中B表示开始,I表示中间,O表示单字词,不计入NER,sO表示特殊单字词。
接下来,让我们考虑下句子的长度,这对后面的建模时填充的句子长度有有参考作用。句子长度及出现频数的统计图如下:
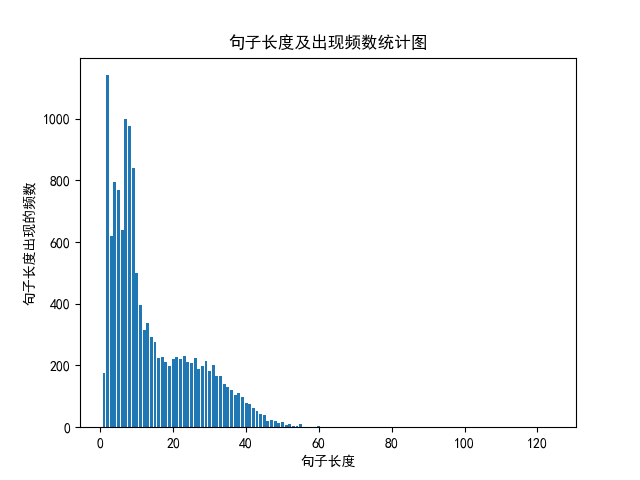
可以看到,句子长度基本在60以下,当然,这也可以在输出的句子长度及出现频数字典中看到。那么,我们是否可以选在一个标准作为后面模型的句子填充的长度呢?答案是,利用出现频数的累计分布函数的分位点,在这里,我们选择分位点为0.9992,对应的句子长度为60,如下图:
接着是数据处理函数data_processing(),它的功能主要是实现单词、标签字典,并保存为pickle文件形式,便于后续直接调用。
建模
在第三步中,我们建立Bi-LSTM模型来训练训练,完整的Python代码(Bi_LSTM_Model_training.py)如下:
- # -*- coding: utf-8 -*-
- import pickle
- import numpy as np
- import pandas as pd
- from utils import BASE_DIR, CONSTANTS, load_data
- from data_processing import data_processing
- from keras.utils import np_utils, plot_model
- from keras.models import Sequential
- from keras.preprocessing.sequence import pad_sequences
- from keras.layers import Bidirectional, LSTM, Dense, Embedding, TimeDistributed
-
-
- # 模型输入数据
- def input_data_for_model(input_shape):
-
- # 数据导入
- input_data = load_data()
- # 数据处理
- data_processing()
- # 导入字典
- with open(CONSTANTS[1], 'rb') as f:
- word_dictionary = pickle.load(f)
- with open(CONSTANTS[2], 'rb') as f:
- inverse_word_dictionary = pickle.load(f)
- with open(CONSTANTS[3], 'rb') as f:
- label_dictionary = pickle.load(f)
- with open(CONSTANTS[4], 'rb') as f:
- output_dictionary = pickle.load(f)
- vocab_size = len(word_dictionary.keys())
- label_size = len(label_dictionary.keys())
-
- # 处理输入数据
- aggregate_function = lambda input: [(word, pos, label) for word, pos, label in
- zip(input['word'].values.tolist(),
- input['pos'].values.tolist(),
- input['tag'].values.tolist())]
-
- grouped_input_data = input_data.groupby('sent_no').apply(aggregate_function)
- sentences = [sentence for sentence in grouped_input_data]
-
- x = [[word_dictionary[word[0]] for word in sent] for sent in sentences]
- x = pad_sequences(maxlen=input_shape, sequences=x, padding='post', value=0)
- y = [[label_dictionary[word[2]] for word in sent] for sent in sentences]
- y = pad_sequences(maxlen=input_shape, sequences=y, padding='post', value=0)
- y = [np_utils.to_categorical(label, num_classes=label_size + 1) for label in y]
-
- return x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary
-
-
- # 定义深度学习模型:Bi-LSTM
- def create_Bi_LSTM(vocab_size, label_size, input_shape, output_dim, n_units, out_act, activation):
- model = Sequential()
- model.add(Embedding(input_dim=vocab_size + 1, output_dim=output_dim,
- input_length=input_shape, mask_zero=True))
- model.add(Bidirectional(LSTM(units=n_units, activation=activation,
- return_sequences=True)))
- model.add(TimeDistributed(Dense(label_size + 1, activation=out_act)))
- model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- return model
-
-
- # 模型训练
- def model_train():
-
- # 将数据集分为训练集和测试集,占比为9:1
- input_shape = 60
- x, y, output_dictionary, vocab_size, label_size, inverse_word_dictionary = input_data_for_model(input_shape)
- train_end = int(len(x)*0.9)
- train_x, train_y = x[0:train_end], np.array(y[0:train_end])
- test_x, test_y = x[train_end:], np.array(y[train_end:])
-
- # 模型输入参数
- activation = 'selu'
- out_act = 'softmax'
- n_units = 100
- batch_size = 32
- epochs = 10
- output_dim = 20
-
- # 模型训练
- lstm_model = create_Bi_LSTM(vocab_size, label_size, input_shape, output_dim, n_units, out_act, activation)
- lstm_model.fit(train_x, train_y, epochs=epochs, batch_size=batch_size, verbose=1)
-
- # 模型保存
- model_save_path = CONSTANTS[0]
- lstm_model.save(model_save_path)
- plot_model(lstm_model, to_file='%s/LSTM_model.png' % BASE_DIR)
-
- # 在测试集上的效果
- N = test_x.shape[0] # 测试的条数
- avg_accuracy = 0 # 预测的平均准确率
- for start, end in zip(range(0, N, 1), range(1, N+1, 1)):
- sentence = [inverse_word_dictionary[i] for i in test_x[start] if i != 0]
- y_predict = lstm_model.predict(test_x[start:end])
- input_sequences, output_sequences = [], []
- for i in range(0, len(y_predict[0])):
- output_sequences.append(np.argmax(y_predict[0][i]))
- input_sequences.append(np.argmax(test_y[start][i]))
-
- eval = lstm_model.evaluate(test_x[start:end], test_y[start:end])
- print('Test Accuracy: loss = %0.6f accuracy = %0.2f%%' % (eval[0], eval[1] * 100))
- avg_accuracy += eval[1]
- output_sequences = ' '.join([output_dictionary[key] for key in output_sequences if key != 0]).split()
- input_sequences = ' '.join([output_dictionary[key] for key in input_sequences if key != 0]).split()
- output_input_comparison = pd.DataFrame([sentence, output_sequences, input_sequences]).T
- print(output_input_comparison.dropna())
- print('#' * 80)
-
- avg_accuracy /= N
- print("测试样本的平均预测准确率:%.2f%%." % (avg_accuracy * 100))
-
- model_train()
在上面的代码中,先是通过input_data_for_model()函数来处理好进入模型的数据,其参数为input_shape,即填充句子时的长度。然后是创建Bi-LSTM模型create_Bi_LSTM(),模型的示意图如下:
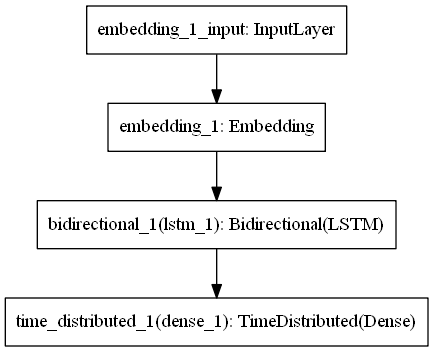
最后,是在输入的数据上进行模型训练,将原始的数据分为训练集和测试集,占比为9:1,训练的周期为10次。
模型训练
运行上述模型训练代码,一共训练10个周期,训练时间大概为500s,在训练集上的准确率达99%以上,在测试集上的平均准确率为95%以上。以下是最后几个测试集上的预测结果:
- ......(前面的输出已忽略)
- Test Accuracy: loss = 0.000986 accuracy = 100.00%
- 0 1 2
- 0 Cardiff B-ORG B-ORG
- 1 1 O O
- 2 Brighton B-ORG B-ORG
- 3 0 O O
- ################################################################################
-
- 1/1 [==============================] - 0s 10ms/step
- Test Accuracy: loss = 0.000274 accuracy = 100.00%
- 0 1 2
- 0 Carlisle B-ORG B-ORG
- 1 0 O O
- 2 Hull B-ORG B-ORG
- 3 0 O O
- ################################################################################
-
- 1/1 [==============================] - 0s 9ms/step
- Test Accuracy: loss = 0.000479 accuracy = 100.00%
- 0 1 2
- 0 Chester B-ORG B-ORG
- 1 1 O O
- 2 Cambridge B-ORG B-ORG
- 3 1 O O
- ################################################################################
-
- 1/1 [==============================] - 0s 9ms/step
- Test Accuracy: loss = 0.003092 accuracy = 100.00%
- 0 1 2
- 0 Darlington B-ORG B-ORG
- 1 4 O O
- 2 Swansea B-ORG B-ORG
- 3 1 O O
- ################################################################################
-
- 1/1 [==============================] - 0s 8ms/step
- Test Accuracy: loss = 0.000705 accuracy = 100.00%
- 0 1 2
- 0 Exeter B-ORG B-ORG
- 1 2 O O
- 2 Scarborough B-ORG B-ORG
- 3 2 O O
- ################################################################################
- 测试样本的平均预测准确率:95.55%.
该模型在原始数据上的识别效果还是可以的。
训练完模型后,BASE_DIR中的所有文件如下:
模型预测
最后,也许是整个项目最为激动人心的时刻,因为,我们要在新数据集上测试模型的识别效果。预测新数据的识别结果的完整Python代码(Bi_LSTM_Model_predict.py)如下:
- # -*- coding: utf-8 -*-
- # Name entity recognition for new data
-
- # Import the necessary modules
- import pickle
- import numpy as np
- from utils import CONSTANTS
- from keras.preprocessing.sequence import pad_sequences
- from keras.models import load_model
- from nltk import word_tokenize
-
- # 导入字典
- with open(CONSTANTS[1], 'rb') as f:
- word_dictionary = pickle.load(f)
- with open(CONSTANTS[4], 'rb') as f:
- output_dictionary = pickle.load(f)
-
- try:
- # 数据预处理
- input_shape = 60
- sent = 'New York is the biggest city in America.'
- new_sent = word_tokenize(sent)
- new_x = [[word_dictionary[word] for word in new_sent]]
- x = pad_sequences(maxlen=input_shape, sequences=new_x, padding='post', value=0)
-
- # 载入模型
- model_save_path = CONSTANTS[0]
- lstm_model = load_model(model_save_path)
-
- # 模型预测
- y_predict = lstm_model.predict(x)
-
- ner_tag = []
- for i in range(0, len(new_sent)):
- ner_tag.append(np.argmax(y_predict[0][i]))
-
- ner = [output_dictionary[i] for i in ner_tag]
- print(new_sent)
- print(ner)
-
- # 去掉NER标注为O的元素
- ner_reg_list = []
- for word, tag in zip(new_sent, ner):
- if tag != 'O':
- ner_reg_list.append((word, tag))
-
- # 输出模型的NER识别结果
- print("NER识别结果:")
- if ner_reg_list:
- for i, item in enumerate(ner_reg_list):
- if item[1].startswith('B'):
- end = i+1
- while end <= len(ner_reg_list)-1 and ner_reg_list[end][1].startswith('I'):
- end += 1
-
- ner_type = item[1].split('-')[1]
- ner_type_dict = {'PER': 'PERSON: ',
- 'LOC': 'LOCATION: ',
- 'ORG': 'ORGANIZATION: ',
- 'MISC': 'MISC: '
- }
- print(ner_type_dict[ner_type],\
- ' '.join([item[0] for item in ner_reg_list[i:end]]))
- else:
- print("模型并未识别任何有效命名实体。")
-
- except KeyError as err:
- print("您输入的句子有单词不在词汇表中,请重新输入!")
- print("不在词汇表中的单词为:%s." % err)
输出结果为:
- ['New', 'York', 'is', 'the', 'biggest', 'city', 'in', 'America', '.']
- ['B-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'O']
- NER识别结果:
- LOCATION: New York
- LOCATION: America
接下来,再测试三个笔者自己想的句子:
输入为:
sent = 'James is a world famous actor, whose home is in London.'
输出结果为:
- ['James', 'is', 'a', 'world', 'famous', 'actor', ',', 'whose', 'home', 'is', 'in', 'London', '.']
- ['B-PER', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'O']
- NER识别结果:
- PERSON: James
- LOCATION: London
输入为:
sent = 'Oxford is in England, Jack is from here.'
输出为:
- ['Oxford', 'is', 'in', 'England', ',', 'Jack', 'is', 'from', 'here', '.']
- ['B-PER', 'O', 'O', 'B-LOC', 'O', 'B-PER', 'O', 'O', 'O', 'O']
- NER识别结果:
- PERSON: Oxford
- LOCATION: England
- PERSON: Jack
输入为:
sent = 'I love Shanghai.'
输出为:
- ['I', 'love', 'Shanghai', '.']
- ['O', 'O', 'B-LOC', 'O']
- NER识别结果:
- LOCATION: Shanghai
在上面的例子中,只有Oxford的识别效果不理想,模型将它识别为PERSON,其实应该是ORGANIZATION。
接下来是三个来自CNN和wikipedia的句子:
输入为:
sent = "the US runs the risk of a military defeat by China or Russia"
输出为:
- ['the', 'US', 'runs', 'the', 'risk', 'of', 'a', 'military', 'defeat', 'by', 'China', 'or', 'Russia']
- ['O', 'B-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'O', 'B-LOC']
- NER识别结果:
- LOCATION: US
- LOCATION: China
- LOCATION: Russia
输入为:
sent = "Home to the headquarters of the United Nations, New York is an important center for international diplomacy."
输出为:
- ['Home', 'to', 'the', 'headquarters', 'of', 'the', 'United', 'Nations', ',', 'New', 'York', 'is', 'an', 'important', 'center', 'for', 'international', 'diplomacy', '.']
- ['O', 'O', 'O', 'O', 'O', 'O', 'B-ORG', 'I-ORG', 'O', 'B-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
- NER识别结果:
- ORGANIZATION: United Nations
- LOCATION: New York
输入为:
sent = "The United States is a founding member of the United Nations, World Bank, International Monetary Fund."
输出为:
- ['The', 'United', 'States', 'is', 'a', 'founding', 'member', 'of', 'the', 'United', 'Nations', ',', 'World', 'Bank', ',', 'International', 'Monetary', 'Fund', '.']
- ['O', 'B-LOC', 'I-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'B-ORG', 'I-ORG', 'O', 'B-ORG', 'I-ORG', 'O', 'B-ORG', 'I-ORG', 'I-ORG', 'O']
- NER识别结果:
- LOCATION: United States
- ORGANIZATION: United Nations
- ORGANIZATION: World Bank
- ORGANIZATION: International Monetary Fund
这三个例子识别全部正确。
总结
到这儿,笔者的这个项目就差不多了。我们有必要对这个项目做个总结。
首先是这个项目的优点。它的优点在于能够让你一步步地实现NER,而且除了语料库,你基本熟悉了如何创建一个识别NER系统的步骤,同时,对深度学习模型及其应用也有了深刻理解。因此,好处是显而易见的。当然,在实际工作中,语料库的整理才是最耗费时间的,能够占到90%或者更多的时间,因此,有一个好的语料库你才能展开工作。
接着讲讲这个项目的缺点。第一个,是语料库不够大,当然,约14000条句子也够了,但本项目没有对句子进行文本预处理,所以,有些单词的变形可能无法进入词汇表。第二个,缺少对新词的处理,一旦句子中出现一个新的单词,这个模型便无法处理,这是后期需要完善的地方。第三个,句子的填充长度为60,如果输入的句子长度大于60,则后面的部分将无法有效识别。
因此,后续还有更多的工作需要去做,当然,做一个中文NER也是可以考虑的。

