
- 1前端在WebSocket中加入Token_websocket token
- 2程序员真是个悲哀的职业!_程序员的性格通病
- 3【论文翻译】Learning from Few Samples: A Survey 小样本学习综述_小样本图像分类英语论文
- 4docker的安装,以及通过docker拉取nacos镜像和启动_nacos docker镜像
- 54种 MySQL 同步 ES 方案_es 同步
- 6Django连接SQL Server配置指引_django.db.backend.odbc isnt an availablr
- 7互联网没有下半场
- 8程序员面试 10 大潜规则,千万不要踩坑!
- 92022最新Macbookpro M1芯片 搭建RocketMQ_mac pro 电脑安装rocketmq
- 10屠杀机器人和无处不在的监控:AI是我们最大的生存威胁?
Linux服务器集群LVS_lvs weight
赞
踩
本文主要介绍了Linux服务器集群系统–LVS(Linux Virtual Server),并简单描述下LVS集群的基本应用的体系结构以及LVS的三种IP负载均衡模型(VS/NAT、VS/DR和VS/TUN)的工作原理,以及它们的优缺点和LVS集群的IP负载均衡软件IPVS在内核中实现的各种连接调度算法。
参考文献 http://www.linuxvirtualserver.org/zh/index.html
前言
LVS(Linux Virtual Server)的简写,翻译为Linux虚拟服务器,即一个虚拟的服务器集群系统,是由我国章文嵩博士在1998年5月所研究成立,也是中国国内最早出现的自由软件项目之一。
宗旨
- 使用集群技术和Linux操作系统实现一个高性能、高可用的服务器.
- 提供很好的可伸缩性(Scalability)
- 提供很好的可靠性(Reliability)
- 提供很好的可管理性(Managerability)
实现负载均衡方式
硬件(Hardware)
- F5BIG-IP
- Citrix NetScaler(思杰)
- A10
软件(Software)
- 运行在TCP/IP四层协议上:
- LVS(Linux Virtual Server)
- 运行在TCP/IP七层协议上:
- nginx
- haproxy
- 运行在TCP/IP四层协议上:
基本LVS体系架构
集群LVS架构描述
LVS集群采用IP负载均衡技术和基于内容请求分发技术。调度器具有很好的吞吐率,将请求均衡地转移到不同的服务器上执行,且调度器自动屏蔽掉服务器的故障,从而将一组服务器构成一个高性能的、高可用的虚拟服务器。整个服务器集群的结构对客户是透明的,而且无需修改客户端和服务器端的程序。
架构基本构图
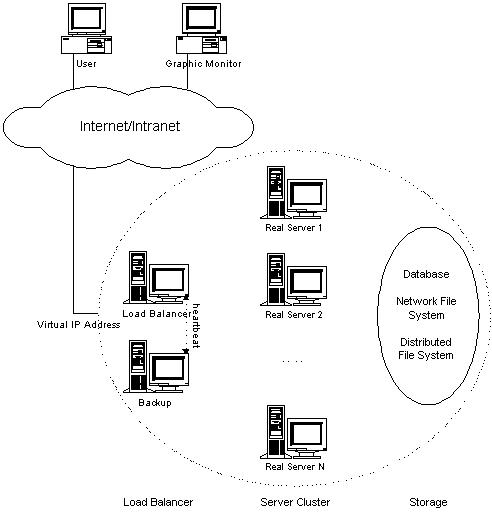
- 为此,在设计时需要考虑系统的透明性、可伸缩性、高可用性和易管理性。一般来说,LVS集群采用三层结构,其体系结构如图1所示,三层主要组成部分为:
- 负载调度器(load balancer),它是整个集群对外面的前端机,负责将客户的请求发送到一组服务器上执行,而客户认为服务是来自一个IP地址(我们可称之为虚拟IP地址)上的。
- 服务器池(server pool),是一组真正执行客户请求的服务器,执行的服务有WEB、MAIL、FTP和DNS等。
- 共享存储(shared storage),它为服务器池提供一个共享的存储区,这样很容易使得服务器池拥有相同的内容,为用户提供相同的服务.
LVS模型介绍
- NAT:Network Address Translation(地址转换)
- DR: Direct Routing(直接路由)
- TUN:IP Tunneling(IP隧道)
Virtual Server via Network Address Translation NAT(VS/NAT)
在一组real_server服务器前有一个Director,它们是通过Switch/HUB相连接的。这些服务器提供相同的网络服务、相同的内容,即不管请求被发送到后台哪一台RealServer,执行结果是一样的。服务的内容可以复制到每台RealServer的本地硬盘上,可以通过网络文件系统(如NFS)共享,也可以通过一个分布式文件系统来提供。所有的RealServer只需要将自己的网关指向Director即可。客户端可以是任意操作系统,但此方式下,一个Director能够带动的RealServer比较有限。在VS/NAT的方式下,Director也可以兼为一台RealServer。
VS/NAT的体系结构如图所示:
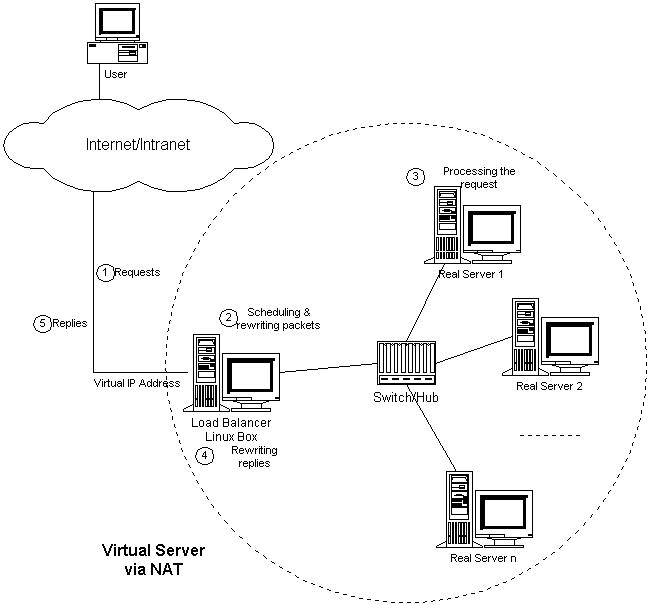
图2:VS/NAT的体系结构
客户通过Virtual IP Address(虚拟服务的IP地址)访问网络服务时,请求报文到达调度器,调度器根据连接调度算法从一组真实服务器中选出一台服务器,将报文的目标地址Virtual IP Address改写成选定服务器的地址,报文的目标端口改写成选定服务器的相应端口,最后将修改后的报文发送给选出的服务器。同时,调度器在连接Hash表中记录这个连接,当这个连接的下一个报文到达时,从连接Hash表中可以得到原选定服务器的地址和端口,进行同样的改写操作,并将报文传给原选定的服务器。当来自真实服务器的响应报文经过调度器时,调度器将报文的源地址和源端口改为Virtual IP Address和相应的端口,再把报文发给用户。我们在连接上引入一个状态机,不同的报文会使得连接处于不同的状态,不同的状态有不同的超时值。在TCP 连接中,根据标准的TCP有限状态机进行状态迁移,这里我们不一一叙述,请参见W. Richard Stevens的《TCP/IP Illustrated Volume I》;在UDP中,我们只设置一个UDP状态。不同状态的超时值是可以设置的,在缺省情况下,SYN状态的超时为1分钟,ESTABLISHED状态的超时为15分钟,FIN状态的超时为1分钟;UDP状态的超时为5分钟。当连接终止或超时,调度器将这个连接从连接Hash表中删除。
这样,客户所看到的只是在Virtual IPAddress上提供的服务,而服务器集群的结构对用户是透明的。对改写后的报文,应用增量调整Checksum的算法调整TCP Checksum的值,避免了扫描整个报文来计算Checksum的开销。
在一些网络服务中,它们将IP地址或者端口号在报文的数据中传送,若我们只对报文头的IP地址和端口号作转换,这样就会出现不一致性,服务会中断。所以,针对这些服务,需要编写相应的应用模块来转换报文数据中的IP地址或者端口号。我们所知道有这个问题的网络服务有FTP、IRC、H.323、CUSeeMe、Real Audio、Real Video、Vxtreme / Vosiac、VDOLive、VIVOActive、True Speech、RSTP、PPTP、StreamWorks、NTT AudioLink、NTT SoftwareVision、Yamaha MIDPlug、iChat Pager、Quake和Diablo。
下面,举个例子来进一步说明VS/NAT,如图3所示:
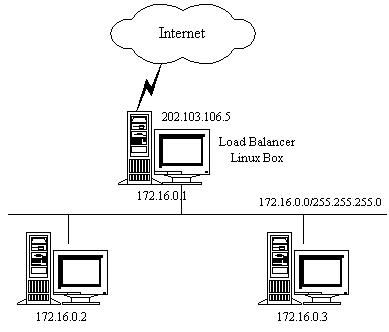
图3:VS/NAT的例子
VS/NAT的配置如下表所示,所有到IP地址为202.103.106.5和端口为80的流量都被负载均衡地调度的真实服务器172.16.0.2:80和172.16.0.3:8000上。目标地址为202.103.106.5:21的报文被转移到172.16.0.3:21上。而到其他端口的报文将被拒绝。
| Protocol | Virtual IP Address | Port | Real IP Address | Port | Weight |
| TCP | 202.103.106.5 | 80 | 172.16.0.2 | 80 | 1 |
| 172.16.0.3 | 8000 | 2 | |||
| TCP | 202.103.106.5 | 21 | 172.16.0.3 | 21 | 1 |
从以下的例子中,我们可以更详细地了解报文改写的流程。
访问Web服务的报文可能有以下的源地址和目标地址:
| SOURCE | 202.100.1.2:3456 | DEST | 202.103.106.5:80 |
- 调度器从调度列表中选出一台服务器,例如是172.16.0.3:8000。该报文会被改写为如下地址,并将它发送给选出的服务器。
| SOURCE | 202.100.1.2:3456 | DEST | 172.16.0.3:8000 |
- 从服务器返回到调度器的响应报文如下:
| SOURCE | 172.16.0.3:8000 | DEST | 202.100.1.2:3456 |
- 响应报文的源地址会被改写为虚拟服务的地址,再将报文发送给客户:
| SOURCE | 202.103.106.5:80 | DEST | 202.100.1.2:3456 |
- 这样,客户认为是从202.103.106.5:80服务得到正确的响应,而不会知道该请求是服务器172.16.0.2还是服务器172.16.0.3处理的。
Virtual Server via Direct Routing(VS/DR)
VS/DR利用大多数Internet服务的非对称特点,Director中只负责调度请求,而后台real_server服务器直接将响应返回给客户,不再通过Director进行转发。
DR方式是通过改写请求报文中的MAC地址部分来实现的。Director和RealServer必需在物理上有一个网卡通过不间断的局域网相连,如通过高速的交换机或者HUB相连。
VIP地址为Director和RealServer组共享,RealServer上绑定的VIP配置在各自Non-ARP的网络设备上(如eth0或lo),Director的VIP地址对外可见,而RealServer的VIP对外是不可见的,只是用于处理目标地址为VIP的网络请求,RealServer的地址即可以是内部地址,也可以是真实地址。
VS/DR的体系结构如图所示:
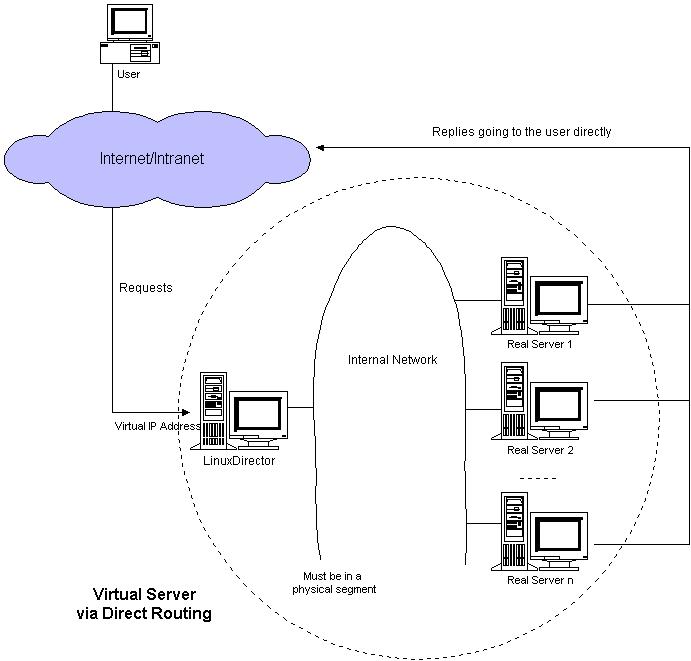
图4:VS/DR的体系结构
VS/DR 的工作流程如图5所示:它的连接调度和管理与VS/NAT和VS/TUN中的一样,它的报文转发方法又有不同,将报文直接路由给目标服务器。在VS/DR中,调度器根据各个服务器的负载情况,动态地选择一台服务器,不修改也不封装IP报文,而是将数据帧的MAC地址改为选出服务器的MAC地址,再将修改后的数据帧在与服务器组的局域网上发送。因为数据帧的MAC地址是选出的服务器,所以服务器肯定可以收到这个数据帧,从中可以获得该IP报文。当服务器发现报文的目标地址VIP是在本地的网络设备上,服务器处理这个报文,然后根据路由表将响应报文直接返回给客户。
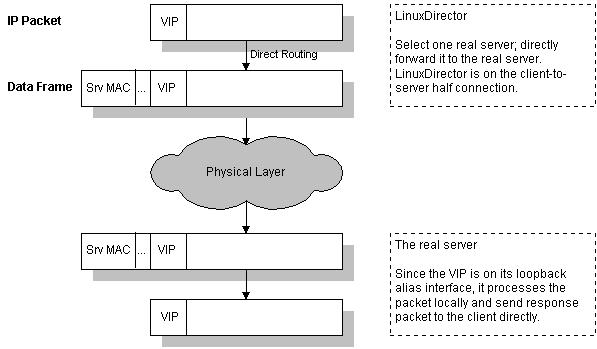
图5:VS/DR的工作流程
- 在VS/DR中,根据缺省的TCP/IP协议栈处理,请求报文的目标地址为VIP,响应报文的源地址肯定也为VIP,所以响应报文不需要作任何修改,可以直接返回给客户,客户认为得到正常的服务,而不会知道是哪一台服务器处理的。
- VS/DR负载调度器跟VS/TUN一样只处于从客户到服务器的半连接中,按照半连接的TCP有限状态机进行状态迁移。
Virtual Server via IP Tunneling(VS/TUN)
IP隧道(IP tunneling)是将一个IP报文封装在另一个IP报文的技术,这可以使得目标为一个IP地址的数据报文能被封装和转发到另一个IP地址。
IP隧道技术亦称为IP封装技术(IP encapsulation)。IP隧道主要用于移动主机和虚拟私有网络(Virtual Private Network),在其中隧道都是静态建立的,隧道一端有一个IP地址,另一端也有唯一的IP地址。它的连接调度和管理与VS/NAT中的一样,只是它的报文转发方法不同。
Director根据各个服务器的负载情况,动态地选择一台RealServer,将请求报文封装在另一个IP报文中,再将封装后的IP报文转发给选出的RealServer;RealServer收到报文后,先将报文解封获得原来目标地址为VIP 的报文,RealServer发现VIP地址被配置在本地的IP隧道设备上,所以就处理这个请求,然后根据路由表将响应报文直接返回给客户。
VS/TUN的体系结构如图所示:

图6:VS/TUN的体系结构
VS/TUN的工作流程如图7所示:它的连接调度和管理与VS/NAT中的一样,只是它的报文转发方法不同。调度器根据各个服务器的负载情况,动态地选择一台服务器,将请求报文封装在另一个IP报文中,再将封装后的IP报文转发给选出的服务器;服务器收到报文后,先将报文解封获得原来目标地址为VIP的报文,服务器发现VIP地址被配置在本地的IP隧道设备上,所以就处理这个请求,然后根据路由表将响应报文直接返回给客户。
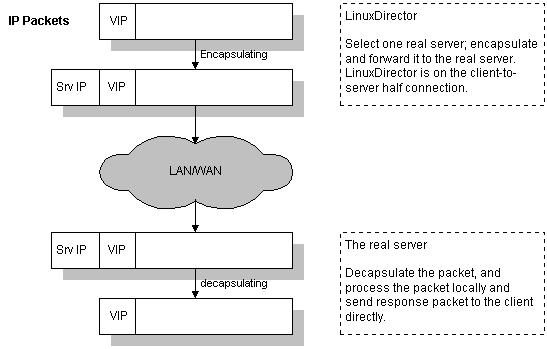
图7:VS/TUN的工作流程
- 在这里需要指出,根据缺省的TCP/IP协议栈处理,请求报文的目标地址为VIP,响应报文的源地址肯定也为VIP,所以响应报文不需要作任何修改,可以直接返回给客户,客户认为得到正常的服务,而不会知道究竟是哪一台服务器处理的。
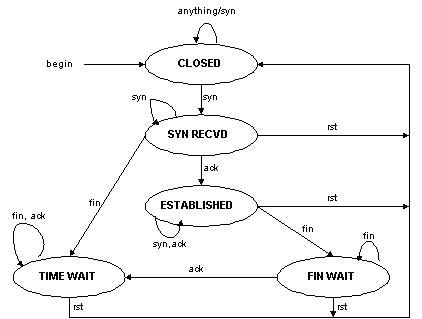
图8:半连接的TCP有限状态机
三种负载模型比较
Virtual Server via NAT
VS/NAT的优点是服务器可以运行任何支持TCP/IP的操作系统,它只需要一个IP地址配置在调度器上,服务器组可以用私有的IP地址。缺点是它的伸缩能力有限,当服务器结点数目升到20时,调度器本身有可能成为系统的新瓶颈,因为在VS/NAT中请求和响应报文都需要通过负载调度器。我们在Pentium166处理器的主机上测得重写报文的平均延时为60us,性能更高的处理器上延时会短一些。假设TCP报文的平均长度为536Bytes,则调度器的最大吞吐量为8.93MBytes/s.我们再假设每台服务器的吞吐量为800KBytes/s,这样一个调度器可以带动10台服务器。(注:这是很早以前测得的数据)
基于VS/NAT的的集群系统可以适合许多服务器的性能要求。如果负载调度器成为系统新的瓶颈,可以有三种方法解决这个问题:混合方法、VS/TUN和VS/DR。
在DNS混合集群系统中,有若干个VS/NAT负载调度器,每个负载调度器带自己的服务器集群,同时这些负载调度器又通过RR-DNS组成简单的域名。
但VS/TUN和VS/DR是提高系统吞吐量的更好方法。对于那些将IP地址或者端口号在报文数据中传送的网络服务,需要编写相应的应用模块来转换报文数据中的IP地址或者端口号。
这会带来实现的工作量,同时应用模块检查报文的开销会降低系统的吞吐率。
Virtual Server via Direct Routing
跟VS/TUN方法一样,VS/DR调度器只处理客户到服务器端的连接,响应数据可以直接从独立的网络路由返回给客户。这可以极大地提高LVS集群系统的伸缩性。
跟VS/TUN相比,这种方法没有IP隧道的开销,但是要求负载调度器与实际服务器都有一块网卡连在同一物理网段上,服务器网络设备(或者设备别名)不作ARP响应,或者能将报文重定向(Redirect)到本地的Socket端口上。
Virtual Server via IP Tunneling
在VS/TUN的集群系统中,负载调度器只将请求调度到不同的后端服务器,后端服务器将应答的数据直接返回给用户。这样,负载调度器就可以处理大量的请求,它甚至可以调度百台以上的服务器(同等规模的服务器),而它不会成为系统的瓶颈。即使负载调度器只有100Mbps的全双工网卡,整个系统的最大吞吐量可超过1Gbps。所以,VS/TUN可以极大地增加负载调度器调度的服务器数量。VS/TUN调度器可以调度上百台服务器,而它本身不会成为系统的瓶颈,可以 用来构建高性能的超级服务器。
VS/TUN技术对服务器有要求,即所有的服务器必须支持“IP Tunneling”或者“IP Encapsulation”协议。目前,VS/TUN的后端服务器主要运行Linux操作系统,我们没对其他操作系统进行测试。因为“IP Tunneling”正成为各个操作系统的标准协议,所以VS/TUN应该会适用运行其他操作系统的后端服务器。
三种模型的优缺点比较
三种IP负载均衡技术的优缺点归纳在下表中:
| VS/NAT | VS/TUN | VS/DR | |
| Server | any | Tunneling | Non-arp device |
| server_network | private | LAN/WAN | LAN |
| server_number | low (10~20) | High (100) | High (100) |
| server_gateway | load balancer | own router | Own router |
内核中负载均衡调度算法
IPVS在内核中的负载均衡调度是以连接为粒度的。在HTTP协议(非持久)中,每个对象从WEB服务器上获取都需要建立一个TCP连接, 同一用户的不同请求会被调度到不同的服务器上,所以这种细粒度的调度在一定程度上可以避免单个用户访问的突发性引起服务器间的负载不平衡在内核中的连接调度算法上,IPVS已实现了以下八种调度算法:
固定调度算法:
- RR : 轮叫调度(Round-Robin Scheduling)
- WRR : 加权轮叫调度(Weighted Round-Robin Scheduling)
- DH : 目标地址散列调度(Destination Hashing Scheduling)
- SH : 源地址散列调度(Source Hashing Scheduling)
动态调度算法:
- LC : 最小连接调度(Least-Connection Scheduling)
- WLC : 加权最小连接调度(Weighted Least-Connection Scheduling)
- LBLC : 基于局部性的最少链接(Locality-Based Least Connections Scheduling)
- LBLCR : 带复制的基于局部性最少链接(Locality-Based Least Connections with Replication Scheduling)
- SED : 最短预期延时调度(Shortest Expected Delay Scheduling)
- NQ : 不排队调度(Never Queue Scheduling)
轮叫调度(RR)
轮叫调度(Round Robin Scheduling)算法就是以轮叫的方式依次将请求调度不同的服务器,即每次调度执行i = (i +1) mod n,并选出第i台服务器。算法的优点是其简洁性,它无需记录当前所有连接的状态,所以它是一种无状态调度。
在系统实现时,我们引入了一个额外条件,当服务器的权值为零时,表示该服务器不可用而不被调度。这样做的目的是将服务器切出服务(如屏蔽服务器故障和系统维护),同时与其他加权算法保持一致。所以,算法要作相应的改动,它的算法流程如下:
轮叫调度算法流程:
假设有一组服务器S = {S0, S1, …, Sn-1},一个指示变量i表示上一次选择的
服务器,W(Si)表示服务器Si的权值。变量i被初始化为n-1,其中n > 0。
j = i;
do {
j = (j + 1) mod n;
if (W(Sj) > 0) {
i = j;
return Si;
}
} while (j != i);
return NULL;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
轮叫调度算法假设所有服务器处理性能均相同,不管服务器的当前连接数和响应速度。该算法相对简单,不适用于服务器组中处理性能不一的情况,而且当请求服务时间变化比较大时,轮叫调度算法容易导致服务器间的负载不平衡。
虽然Round-Robin DNS方法也是以轮叫调度的方式将一个域名解析到多个IP地址,但轮叫DNS方法的调度粒度是基于每个域名服务器的,域名服务器对域名解析的缓存会妨碍轮叫解析域名生效,这会导致服务器间负载的严重不平衡。这里,IPVS轮叫调度算法的粒度是基于每个连接的,同一用户的不同连接都会被调度到不同的服务器上,所以这种细粒度的轮叫调度要比DNS的轮叫调度优越很多。
加权轮叫调度(WRR)
加权轮叫调度(Weighted Round-Robin Scheduling)算法可以解决服务器间性能不一的情况,它用相应的权值表示服务器的处理性能,服务器的缺省权值为1。假设服务器A的权值为1,B的权值为2,则表示服务器B的处理性能是A的两倍。加权轮叫调度算法是按权值的高低和轮叫方式分配请求到各服务器。权值高的服务器先收到的连接,权值高的服务器比权值低的服务器处理更多的连接,相同权值的服务器处理相同数目的连接数。加权轮叫调度算法流程如下:
加权轮叫调度算法流程:
假设有一组服务器S = {S0, S1, …, Sn-1},W(Si)表示服务器Si的权值,一个
指示变量i表示上一次选择的服务器,指示变量cw表示当前调度的权值,max(S)
表示集合S中所有服务器的最大权值,gcd(S)表示集合S中所有服务器权值的最大
公约数。变量i初始化为-1,cw初始化为零。
while (true) {
i = (i + 1) mod n;
if (i == 0) {
cw = cw - gcd(S);
if (cw <= 0) {
cw = max(S);
if (cw == 0)
return NULL;
}
}
if (W(Si) >= cw)
return Si;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
例如,有三个服务器A、B和C分别有权值4、3和2,则在一个调度周期内(mod sum(W(Si)))调度序列为AABABCABC。加权轮叫调度算法还是比较简单和高效。当请求的服务时间变化很大,单独的加权轮叫调度算法依然会导致服务器间的负载不平衡。
从上面的算法流程中,我们可以看出当服务器的权值为零时,该服务器不被被调度;当所有服务器的权值为零,即对于任意i有W(Si)=0,则没有任何服务器可用,算法返回NULL,所有的新连接都会被丢掉。加权轮叫调度也无需记录当前所有连接的状态,所以它也是一种无状态调度。
目标地址散列调度(DH)
目标地址散列调度(Destination Hashing Scheduling)算法也是针对目标IP地址的负载均衡,但它是一种静态映射算法,通过一个散列(Hash)函数将一个目标IP地址映射到一台服务器。
目标地址散列调度算法先根据请求的目标IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。该算法的流程如下:
目标地址散列调度算法流程:
假设有一组服务器S = {S0, S1, ..., Sn-1},W(Si)表示服务器Si的权值,
C(Si)表示服务器Si的当前连接数。ServerNode[]是一个有256个桶(Bucket)的
Hash表,一般来说服务器的数目会运小于256,当然表的大小也是可以调整的。
算法的初始化是将所有服务器顺序、循环地放置到ServerNode表中。若服务器的
连接数目大于2倍的权值,则表示服务器已超载。
n = ServerNode[hashkey(dest_ip)];
if ((n is dead) OR
(W(n) == 0) OR
(C(n) > 2*W(n))) then
return NULL;
return n;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 在实现时,我们采用素数乘法Hash函数,通过乘以素数使得散列键值尽可能地达到较均匀的分布。所采用的素数乘法Hash函数如下:
素数乘法Hash函数
static inline unsigned hashkey(unsigned int dest_ip)
{
return (dest_ip* 2654435761UL) & HASH_TAB_MASK;
}
其中,2654435761UL是2到2^32 (4294967296)间接近于黄金分割的素数,
(sqrt(5) - 1) / 2 = 0.618033989
2654435761 / 4294967296 = 0.618033987- 1
- 2
- 3
- 4
- 5
- 6
- 7
源地址散列调度(SH)
源地址散列调度(Source Hashing Scheduling)算法正好与目标地址散列调度算法相反,它根据请求的源IP地址,作为散列键(Hash Key)从静态分配的散列表找出对应的服务器,若该服务器是可用的且未超载,将请求发送到该服务器,否则返回空。它采用的散列函数与目标地址散列调度算法的相同。它的算法流程与目标地址散列调度算法的基本相似,除了将请求的目标IP地址换成请求的源IP地址,所以这里不一一叙述。
- 在实际应用中,源地址散列调度和目标地址散列调度可以结合使用在防火墙集群中,它们可以保证整个系统的唯一出入口。
最小连接调度(LC)
最小连接调度(Least-Connection Scheduling)算法是把新的连接请求分配到当前连接数最小的服务器。最小连接调度是一种动态调度算法,它通过服务器当前所活跃的连接数来估计服务器的负载情况。调度器需要记录各个服务器已建立连接的数目,当一个请求被调度到某台服务器,其连接数加1;当连接中止或超时,其连接数减一。
在系统实现时,我们也引入当服务器的权值为零时,表示该服务器不可用而不被调度,它的算法流程如下:
最小连接调度算法流程:
假设有一组服务器S = {S0, S1, ..., Sn-1},W(Si)表示服务器Si的权值,
C(Si)表示服务器Si的当前连接数。
for (m = 0; m < n; m++) {
if (W(Sm) > 0) {
for (i = m+1; i < n; i++) {
if (W(Si) <= 0)
continue;
if (C(Si) < C(Sm))
m = i;
}
return Sm;
}
}
return NULL;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 当各个服务器有相同的处理性能时,最小连接调度算法能把负载变化大的请求分布平滑到各个服务器上,所有处理时间比较长的请求不可能被发送到同一台服务器上。但是,当各个服务器的处理能力不同时,该算法并不理想,因为TCP连接处理请求后会进入TIME_WAIT状态,TCP的TIME_WAIT一般为2分钟,此时连接还占用服务器的资源,所以会出现这样情形,性能高的服务器已处理所收到的连接,连接处于TIME_WAIT状态,而性能低的服务器已经忙于处理所收到的连接,还不断地收到新的连接请求。
加权最小连接调度(WLC)
加权最小连接调度(Weighted Least-Connection Scheduling)算法是最小连接调度的超集,各个服务器用相应的权值表示其处理性能。服务器的缺省权值为1,系统管理员可以动态地设置服务器的权值。加权最小连接调度在调度新连接时尽可能使服务器的已建立连接数和其权值成比例。加权最小连接调度的算法流程如下:
加权最小连接调度的算法流程:
假设有一组服务器S = {S0, S1, ..., Sn-1},W(Si)表示服务器Si的权值,
C(Si)表示服务器Si的当前连接数。所有服务器当前连接数的总和为
CSUM = ΣC(Si) (i=0, 1, .. , n-1)。当前的新连接请求会被发送服务器Sm,
当且仅当服务器Sm满足以下条件
(C(Sm) / CSUM)/ W(Sm) = min { (C(Si) / CSUM) / W(Si)} (i=0, 1, . , n-1)
其中W(Si)不为零
因为CSUM在这一轮查找中是个常数,所以判断条件可以简化为
C(Sm) / W(Sm) = min { C(Si) / W(Si)} (i=0, 1, . , n-1)
其中W(Si)不为零
因为除法所需的CPU周期比乘法多,且在Linux内核中不允许浮点除法,服务器的
权值都大于零,所以判断条件C(Sm) / W(Sm) > C(Si) / W(Si) 可以进一步优化
为C(Sm)*W(Si) > C(Si)* W(Sm)。同时保证服务器的权值为零时,服务器不被调
度。所以,算法只要执行以下流程。
for (m = 0; m < n; m++) {
if (W(Sm) > 0) {
for (i = m+1; i < n; i++) {
if (C(Sm)*W(Si) > C(Si)*W(Sm))
m = i;
}
return Sm;
}
}
return NULL;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
基于局部性的最少链接调度(LBLC)
基于局部性的最少链接调度(Locality-Based Least Connections Scheduling,以下简称为LBLC)算法是针对请求报文的目标IP地址的负载均衡调度,目前主要用于Cache集群系统,因为在Cache集群中客户请求报文的目标IP地址是变化的。这里假设任何后端服务器都可以处理任一请求,算法的设计目标是在服务器的负载基本平衡情况下,将相同目标IP地址的请求调度到同一台服务器,来提高各台服务器的访问局部性和主存Cache命中率,从而整个集群系统的处理能力。
LBLC调度算法先根据请求的目标IP地址找出该目标IP地址最近使用的服务器,若该服务器是可用的且没有超载,将请求发送到该服务器;若服务器不存在,或者该服务器超载且有服务器处于其一半的工作负载,则用“最少链接”的原则选出一个可用的服务器,将请求发送到该服务器。该算法的详细流程如下:
LBLC调度算法流程:
假设有一组服务器S = {S0, S1, ..., Sn-1},W(Si)表示服务器Si的权值,
C(Si)表示服务器Si的当前连接数。ServerNode[dest_ip]是一个关联变量,表示
目标IP地址所对应的服务器结点,一般来说它是通过Hash表实现的。WLC(S)表示
在集合S中的加权最小连接服务器,即前面的加权最小连接调度。Now为当前系统
时间。
if (ServerNode[dest_ip] is NULL) then {
n = WLC(S);
if (n is NULL) then return NULL;
ServerNode[dest_ip].server = n;
} else {
n = ServerNode[dest_ip].server;
if ((n is dead) OR
(C(n) > W(n) AND
there is a node m with C(m) < W(m)/2))) then {
n = WLC(S);
if (n is NULL) then return NULL;
ServerNode[dest_ip].server = n;
}
}
ServerNode[dest_ip].lastuse = Now;
return n;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 此外,对关联变量ServerNode[dest_ip]要进行周期性的垃圾回收(Garbage
Collection),将过期的目标IP地址到服务器关联项进行回收。过期的关联项是指哪些当前时间(实现时采用系统时钟节拍数jiffies)减去最
近使用时间超过设定过期时间的关联项,系统缺省的设定过期时间为24小时。
带复制的基于局部性最少链接调度(LBLCR)
带复制的基于局部性最少链接调度(Locality-Based Least Connections with Replication Scheduling,以下简称为LBLCR)算法也是针对目标IP地址的负载均衡,目前主要用于Cache集群系统。它与LBLC算法的不同之处是它要维护从一个目标IP地址到一组服务器的映射,而LBLC算法维护从一个目标IP地址到一台服务器的映射。对于一个“热门”站点的服务请求,一台Cache服务器可能会忙不过来处理这些请求。这时,LBLC调度算法会从所有的Cache服务器中按“最小连接”原则选出一台Cache服务器,映射该“热门”站点到这台Cache服务器,很快这台Cache服务器也会超载,就会重复上述过程选出新的Cache服务器。这样,可能会导致该“热门”站点的映像会出现在所有的Cache服务器上,降低了Cache服务器的使用效率。LBLCR调度算法将“热门”站点映射到一组Cache服务器(服务器集合),当该“热门”站点的请求负载增加时,会增加集合里的Cache服务器,来处理不断增长的负载;当该“热门”站点的请求负载降低时,会减少集合里的Cache服务器数目。这样,该“热门”站点的映像不太可能出现在所有的Cache服务器上,从而提供Cache集群系统的使用效率。
LBLCR算法先根据请求的目标IP地址找出该目标IP地址对应的服务器组;按“最小连接”原则从该服务器组中选出一台服务器,若服务器没有超载,将请求发送到该服务器;若服务器超载;则按“最小连接”原则从整个集群中选出一台服务器,将该服务器加入到服务器组中,将请求发送到该服务器。同时,当该服务器组有一段时间没有被修改,将最忙的服务器从服务器组中删除,以降低复制的程度。LBLCR调度算法的流程如下:
LBLCR调度算法流程:
假设有一组服务器S = {S0, S1, ..., Sn-1},W(Si)表示服务器Si的权值,
C(Si)表示服务器Si的当前连接数。ServerSet[dest_ip]是一个关联变量,表示
目标IP地址所对应的服务器集合,一般来说它是通过Hash表实现的。WLC(S)表示
在集合S中的加权最小连接服务器,即前面的加权最小连接调度;WGC(S)表示在
集合S中的加权最大连接服务器。Now为当前系统时间,lastmod表示集合的最近
修改时间,T为对集合进行调整的设定时间。
if (ServerSet[dest_ip] is NULL) then {
n = WLC(S);
if (n is NULL) then return NULL;
add n into ServerSet[dest_ip];
} else {
n = WLC(ServerSet[dest_ip]);
if ((n is NULL) OR
(n is dead) OR
(C(n) > W(n) AND
there is a node m with C(m) < W(m)/2))) then {
n = WLC(S);
if (n is NULL) then return NULL;
add n into ServerSet[dest_ip];
} else
if (|ServerSet[dest_ip]| > 1 AND
Now - ServerSet[dest_ip].lastmod > T) then {
m = WGC(ServerSet[dest_ip]);
remove m from ServerSet[dest_ip];
}
}
ServerSet[dest_ip].lastuse = Now;
if (ServerSet[dest_ip] changed) then
ServerSet[dest_ip].lastmod = Now;
return n;- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 此外,对关联变量ServerSet[dest_ip]也要进行周期性的垃圾回收(Garbage Collection),将过期的目标IP地址到服务器关联项进行回收。过期的关联项是指哪些当前时间(实现时采用系统时钟节拍数jiffies)减去最近使用时间(lastuse)超过设定过期时间的关联项,系统缺省的设定过期时间为24小时。
最短预期延时调度(SED)
不考虑非活动状态,使用(活动状态+1)*256/weigh,数字小的将接收下次访问请求,+1主要是为了提高权重大的服务器的响应能力
不排队调度(NQ)
假设有两台服务器A,B,权重比为10:1,按照sed算法,只有当A服务器已经响应了10个请求之时两者的计算数值才相同,为了避免权重小的服务器过于空闲,nq沿用sed算法但是确保让每个服务器都不空闲,只有在不考虑非活动连接的情况下nq才能取代wlc算法
本文理论参考于Linux Virutal Server官方文档,接下来我们要进行实际环境下LVS三种模型集群的搭建。

