
热门标签
热门文章
- 1MySQL MVCC
- 2深度学习笔记: Sigmoid激活函数_sigmoid函数
- 3leetcode 224:基本计算器_给你个字符串表达式s,请使用一种您熟悉的语言(c java, python)实现一个基本计算器
- 4第一章 Web应用基础_在web应用软件的基本结构中,客户端的基础是
- 5Docker安装jenkins,并且创建maven任务_docker下jenkins配置maven
- 6万字长文!用文本挖掘深度剖析54万首诗歌
- 7C语言[编程入门]链表之报数问题(环链表)_链表 报数问题
- 8Python中的时间序列分析与预测技术_python时间序列相关性什么指标最好
- 9springboot中 druid数据源密码加密_passwordcallbackclassname
- 10QNX在车机系统的应用_车机qnx
当前位置: article > 正文
【Redis】八股文必背_redis集群八股
作者:空白诗007 | 2024-07-14 06:45:26
赞
踩
redis集群八股
缓存穿透、缓存击穿、缓存雪崩
| 缓存穿透 | 缓存击穿 | 缓存雪崩 | |
|---|---|---|---|
| 描述 | 查询不存在的数据 | 某小段时间大量相同查询达到存储层 | 缓存无法提供服务,大量请求打到存储层 |
| 可能原因 | 1. 缓存和库中数据被删除 2. 恶意攻击 | 某些热点数据过期失效 | 大量数据过期,或Redis宕机 |
| 解决方法 | 1. 缓存空对象,未命中时将空值存入缓存 2. 布隆过滤器拦截 | 1. 热点数据永不过期 2. 互斥加锁,多线程访问redis某key无数据时,只有一个线程能去存储层查询并存入redis,然后其它线程再从redis取数据 | 1. 避免数据同时过期,设置过期时间为随机值 2. 降级和熔断,对于非核心请求直接返回预定义信息 3. 构建高可用服务 |
Redis键的过期
1. 设置过期时间的命令
| 命令 | 示例和描述 |
|---|---|
| PERSIST | PERSIST key-name —— 移除键的过期时间 |
| TTL | TTL key-name —— 查看给定键距离过期还有多少秒 |
| EXPIRE | EXPIRE key-name seconds —— 让给定键在指定的秒数之后过期 |
| EXPIREAT | EXPIREAT key-name timestamp —— 将给定键的过期时间设置为给定的 UNIX 时间戳 |
| PTTL | PTTL key-name —— 查看给定键距离过期时间还有多少毫秒 |
| PEXPIRE | PEXPIRE key-name milliseconds —— 让给定键在指定的毫秒数之后过期 |
| PEXPIREAT | PEXPIREAT key-name timestamp-milliseconds —— 将一个毫秒级别精度的 UNIX 时间戳设置为过期时间 |
2. 过期时间设置原则
- 热点数据不设置过期时间,可以避免缓存击穿问题
- 设置的过期时间时随机值,避免大量key同时过期,导致缓存雪崩
3. Redis处理过期键策略
- 惰性删除: 客户端访问key时,检查是否过期,过期则删除
- 定期删除: 服务端将设置了过期时间的key放到独立字典中,定期进行扫描。扫描逻辑:
- 随机选择部分key(20)
- 删除过期key
- 若过期比例超过25%则重复操作
4. Redis缓存淘汰策略
LRU和LFU的算法代码见这里
当写入数据将导致超出maxmemory限制时,Redis会采用maxmemory-policy所指定的策略进行数据淘汰。该策略包含如下八种。
| 策略 | 描述 | 版本 |
|---|---|---|
| noeviction | 直接返回错误; | |
| volatile-ttl | 从设置了过期时间的键中,选择过期时间最小的键,进行淘汰; | |
| volatile-random | 从设置了过期时间的键中,随机选择键,进行淘汰; | |
| volatile-lru | 从设置了过期时间的键中,使用LRU算法选择键,进行淘汰; | |
| volatile-lfu | 从设置了过期时间的键中,使用LFU算法选择键,进行淘汰; | 4.0 |
| allleys-random | 从所有的键中,随机选择键,进行淘汰; | |
| allkeys-lru | 从所有的键中,使用LRU算法选择键,进行淘汰; | |
| allkeys-lfu | 从所有的键中,使用LFU算法选择键,进行淘汰; | 4.0 |
前缀含义:
- volatile:从设置了过期时间的键中淘汰数据
- allkeys:从所有的键中淘汰数据
LRU与LFU:
- LRU最近最少访问删除策略,非热点数据在偶尔访问后,一段时间内不会被淘汰。
- LFU最近最不经常使用删除策略,访问次数最少会被删除,如果多个数据访问数据相同,则这些数据根据LRU策略删除
Redis的线程
从 Redis 的 v1.0 到 v6.0 版本之前,Redis 的核心网络模型一直是一个典型的单 Reactor 模型。Redis v6.0 才改造成多线程模式。
Redis的主要瓶颈是内存和网络带宽,而非CPU。6.0引入多线程解决网络IO问题。
1. 版本变更中的多线程
| 涉及的多线程 | |
|---|---|
| Redis 3.0前 | 1. 持久化:BGSAVE和BGREWRITEAOF会fork子进程进行 2. 异步任务:关闭文件、将缓冲区冲洗到磁盘文件中 |
| Redis 4.0 | 异步删除键值对的命令:UNLINK(DEL的异步版本)、FLUSHALL ASYNC、FLUSHDB ASYNC(删除选项,整个数据集还是单个数据库) |
| Redis 6.0 | socket读写、请求解析是多线程,但命令执行是单线程(键值对操作,防止线程不安全) |
2. Redis为什么快
- 单线程处理命令避免上下文切换和线程竞争带来的开销
- 数据存储在内存
- c语言本身性能高
- IO多路复用技术,实现高吞吐的网络IO UNIX IO五种模型
3. Redis核心为什么使用单线程
- 避免上下文切换
- 避免同步机制带来开销
- 简单可维护
如何设计分布式锁
- set key value nx ex seconds 原子性地赋值和设置过期时间
- Redisson框架
双写一致问题
- 先删缓存后更数据库
- 先更新缓存后更新数据库
- 先更数据库后删缓存
- 先更新数据库后更新缓存
- 延时双删
1. 删除和更新缓存的比较
- 删除:
- 优点:操作简单
- 缺点:下次读取时需要重新从数据库取
- 更新:
- 优点:数据变化更新及时
- 缺点:写多读少的场景性能差。
2. 先删缓存后更数据库
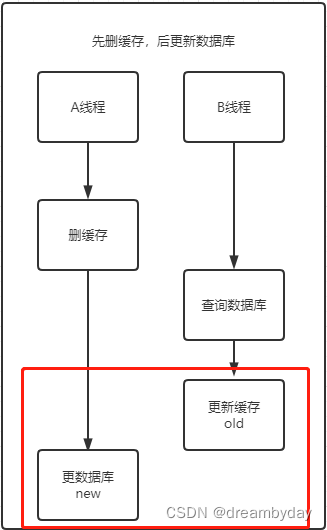
在A线程删缓存和更新数据库期间,其他线程查询并更新缓存后,会造成数据库和缓存不一致的情况。
3. 先更新缓存后更新数据库
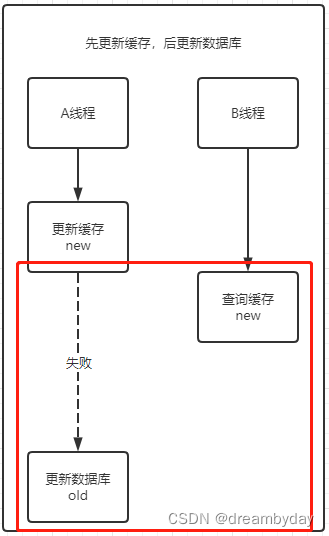
A线程更新缓存后若数据库更新失败,会造成数据库和缓存不一致的情况。一般需要重试,一般通过异步方式进行
4. 先更数据库,后删除/更新缓存
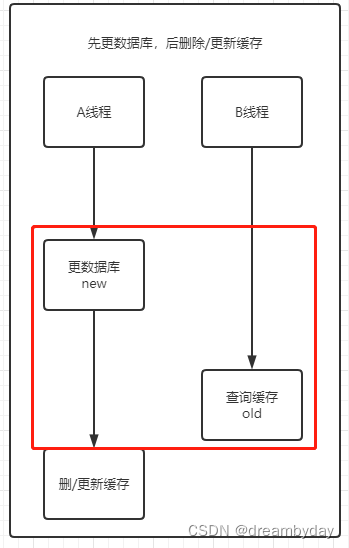
- 在 A线程更新数据库到删除/更新缓存期间,其它线程查询到的数据是历史缓存数据,与数据库不一致。
- 若A线程删/更新缓存失败,则从A更新数据库后,缓存和数据库就一直不一致。
5. 延时双删
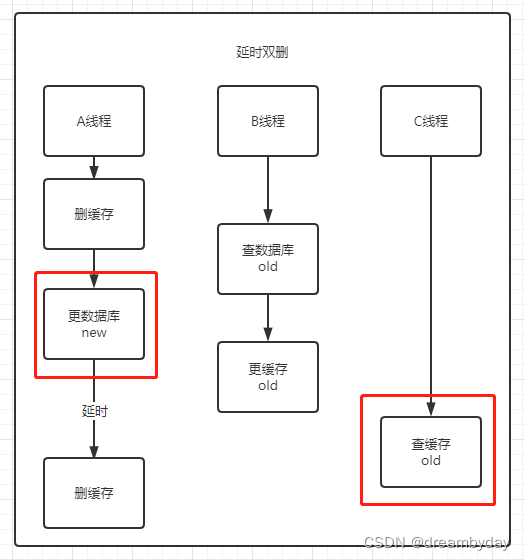
- 若B线程在A第一次删缓存和更数据库期间查询数据库,并在A更新数据和延时删除缓存之间更新了缓存,那么在B更新缓存和A延时删缓存的中间时刻发生数据不一致。
- 若是B线程更新缓存在A延时删除缓存之后发生,则同样发生了数据不一致。这说明延时时间设置不合理。
延时时间的设置:
- 设置时间过大可能导致情况1发生
- 设置时间过小可能导致情况2发生
- 需要根据业务场景合理估计设置时间
6. 如何强一致
- 对单key使用分布式锁,将缓存操作和数据库操作放到一个锁中,会影响性能,需要注意失败处理和锁的释放
- 放弃缓存
- 单key串行化读写,相同key的操作加入等待队列(类似于加锁)
如何使用布隆过滤器
布隆过滤器使用bit位存储数据。占用空间小。
可以用于拦截不存在的数据,有概率拦截到存在的数据。
其它
1. Redis各种数据结构原理
2. 持久化
3. 高可用
3. 大key问题
什么是大key?:
value值占用内存较大
有什么影响:
- 网络传输内容大,占用带宽,服务端和客户端的读取耗时增加
- 可能是热key,频繁读取影响性能
- 大key用del删除时,会阻塞线程
- 可能带来分布式系统中的数据倾斜,资源利用率不平衡
- 在集群中,数据迁移困难(migrate 命令是通过 dump 和 restore 和 del 三个命令组合成原子命令完成,如果是存在 bigkey 的话,可能会因为大 value 的原因导致迁移失败,而且较慢的 migrate 会阻塞 Redis,影响 Redis 服务)
如何产生:
一般是因为业务涉及不合理,没有预计value动态增长
- 一直往value里塞数据,没有删除或者限制机制
- 数据没有进行分片,将大key变为小key
如何排查:
- 利用redis-cli bigkeys命令,在线扫描(不会阻塞)
- 利用redis-rdb-toos,离线分析RDB持久化文件,实时性差,但是完全离线对性能无影响
如何解决:
- 删除: 先用scan渐进式查找key,(用keys * 会阻塞)
- 低于4.0版本,除了string类型,其他类型都可以每次用del删除一部分
- 高于4.0版本,可以使用unlink直接异步删除
- 压缩与拆分:
- string类型:难以拆分,可以序列化、压缩。但是会增加额外耗时
- hash类型 :字段拆分,将一个对象分为多个部分,读取时可以使用multiget事务读取
- list、set类型:可以通过计算分片到不同的集群节点上
todo
- RedLock
- 选举算法
- Redisson原理
- 事务、广播、消息队列
- 监控、问题处理
参考
推荐阅读
相关标签

