
- 1应急响应-战后溯源反制&社会工程学
- 2算法回忆录:母函数解决整数拆分_整数拆分 母函数
- 3mac 安装docker报错Error: Unknown command: cask_liuyaoguangdemacbook-pro:~ liuyaoguang$ brew cask
- 4鸿蒙(API 12 Beta2版)NDK开发【JSVM-API调试&定位】
- 5机器视觉笔迹识别与Arduino控制机器人设计_arduino视觉识别
- 6让「GPT-4V」跑在手机上,这家中国大模型公司做到了
- 7转载和积累系列 - 大数据时代的 9 大Key-Value存储数据库_aerospike scanall顺序
- 8基于SpringBoot的影像注册系统04 sa-token使用(源码解析 + 万字_stputil 能不能存username
- 9FPGA 运行过程中程序丢失_camera驱动找的到fpga驱动掉了
- 10Selenium 自动化测试最佳实践
我做了一个 AI 搜索引擎_thinkany官网
赞
踩
前言
这是一篇两个月前就应该写的文章。
今年 3 月,我做了一个 AI 搜索引擎,名字叫做 ThinkAny,经过三个月的发展,ThinkAny 已经成长为一个月访问量 60 万的全球化产品,用户覆盖日本 / 埃及 / 俄罗斯 / 巴基斯坦等国家和地区,累计用户数突破 17 万。
我有一个习惯,每做一个新项目,都会写一篇文章进行总结。
ThinkAny 的总结文章一直拖着没写,主要原因是我有很严重的强迫症。我总觉得 ThinkAny 现在做的还不够好,想着把交互体验优化的好一些,把搜索准确度再提升一个量级之后,再来写总结文章。
然而 AI 搜索引擎这类产品,复杂性和工作量都超过了我的预期,这会是一个持久战,后面还需要投入很多的时间和精力去把产品做的更完善。
最近看了很多第三方介绍 ThinkAny 的文章和视频,总觉得没有完全表达我想表达的东西。
于是想自己写一篇文章,系统的介绍一下 ThinkAny 这款产品,以及我对 AI 搜索这个市场的一些看法。
第一部分:ThinkAny 的发展历程
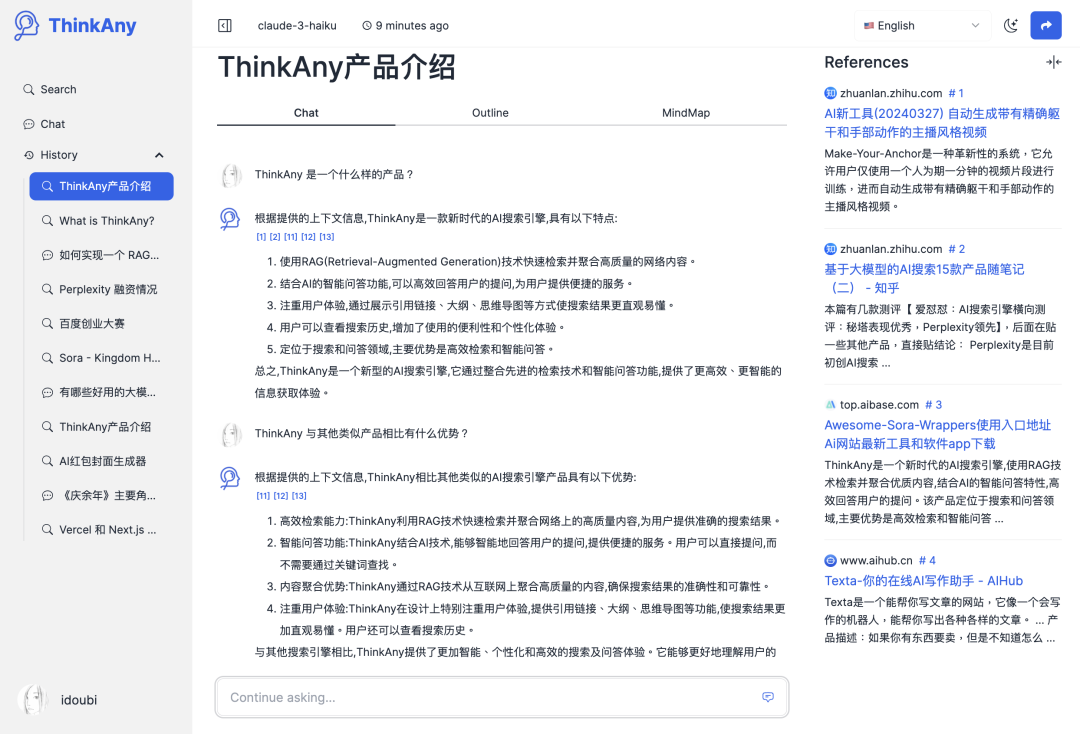
介绍一下 ThinkAny
ThinkAny 是一款新时代的 AI 搜索引擎,利用 RAG(Retrieval-Augmented Generation)技术快速检索和聚合网络上的优质内容,并结合 AI 的智能回答功能,高效地回答用户的问题。
ThinkAny 的目标是:搜得更快,答得更准。
ThinkAny 的定位是做全球化市场,从第一个版本开始就支持了多语言,包括(英语 / 中文 / 韩语 / 日语 / 法语 / 德语 / 俄语 / 阿拉伯语)。
ThinkAny 的官网地址是:https://thinkany.ai
采用双栏式布局,界面非常简洁大气。

20240619140701
我为什么要做 AI 搜索引擎
我选择做什么产品,一般有三个原则:
-
是我很感兴趣的方向
-
产品有价值,能带来成就感
-
在我的能力范围内
早在去年 11 月,就有朋友建议我研究一下 AI 搜索赛道的产品。
当时我的第一想法是,搜索引擎应该是一类有很高技术壁垒的产品,不在我的能力范围,所以一直不敢尝试,也没花时间去研究。
直到今年年初,有媒体报道:“贾扬清 500 行代码写了一个 AI 搜索引擎”,当时觉得很神奇,写一个 AI 搜索引擎这么简单吗?
花了点时间研究了一下贾扬清老师开源的 Lepton Search 源码,Python 写的,后台逻辑 400 多行。
又看了一个叫 float32 的 AI 搜索引擎源码,Go 写的,核心逻辑也就几百行。
看完两个项目代码之后,开始“技术祛魅”,号称能颠覆谷歌 / 百度统治的新一代 AI 搜索引擎,好像也“不过如此”。
底层技术概括起来就一个词,叫做“RAG”,也就是所谓的“检索增强生成”。
-
检索(Retrieve):拿用户 query 调搜索引擎 API,拿到搜素结果;
-
增强(Augmented):设置提示词,把检索结果作为挂载上下文;
-
生成(Generation):大模型回答问题,标注引用来源;
弄清楚 AI 搜索的底层逻辑之后,我决定在这个领域开始新的尝试。
我给要做的 AI 搜索引擎产品取名“ThinkAny”,名字直译于我之前创立的一家公司“任想科技”。
ThinkAny 是如何冷启动的
ThinkAny 第一个版本是我在一个周末的时间写完的。
MVP 版本实现起来很简单,使用 NextJs 做全栈开发,一个界面 + 两个接口。
两个接口分别是:
- /api/rag-search
这个接口调用 serper.dev 的接口,获取谷歌的检索内容。输入用户的查询 query,输出谷歌搜索的前 10 条信息源。
- /api/chat
这个接口选择 OpenAI 的 gpt-3.5-turbo 作为基座模型,把上一步返回的 10 条检索结果的 title + snippet 拼接成上下文,设置提示词,请求大模型做问答输出。
提示词参考的 Lepton Search,第一版内容为:
You are a large language AI assistant built by ThinkAny AI. You are given a user question, and please write clean, concise and accurate answer to the question. You will be given a set of related contexts to the question, each starting with a reference number like [[citation:x]], where x is a number. Please use the context and cite the context at the end of each sentence if applicable. Your answer must be correct, accurate and written by an expert using an unbiased and professional tone. Please limit to 1024 tokens. Do not give any information that is not related to the question, and do not repeat. Say "information is missing on" followed by the related topic, if the given context do not provide sufficient information. Please cite the contexts with the reference numbers, in the format [citation:x]. If a sentence comes from multiple contexts, please list all applicable citations, like [citation:3][citation:5]. Other than code and specific names and citations, your answer must be written in the same language as the question. Here are the set of contexts: {context} Remember, don't blindly repeat the contexts verbatim. And here is the user question:
- 1
前端界面的构建也没有花太多时间,使用 tailwindcss + daisyUI 实现了基本的界面,主要是一个搜索输入框 + 搜索结果页。

20240619150035
写完基本功能后,我把代码提交到了 Github,使用 Vercel 进行发布,通过 Cloudflare 做域名 DNS 解析。第一个版本就这么上线了。
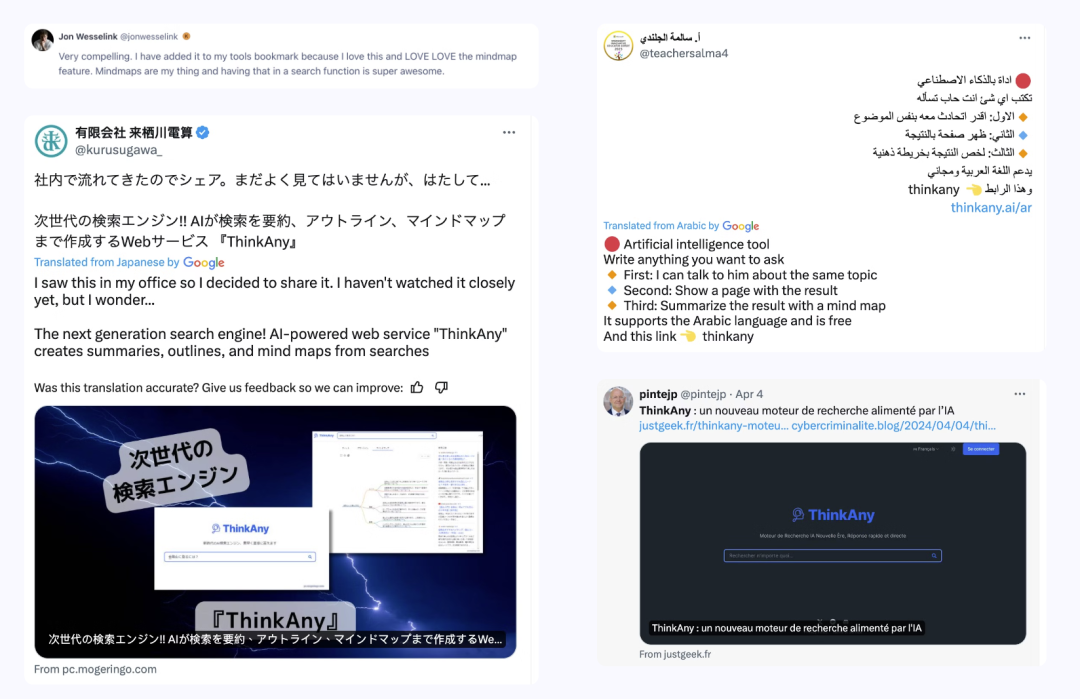
我在 ProductHunt 发布了 ThinkAny,在微信朋友圈 / 即刻 / Twitter 等地方发动态号召投票,当天 ThinkAny 冲到了 ProductHunt 日榜第四。
20240619153349
ProductHunt 上榜给了 ThinkAny 很大的曝光,接下来几天,在 Twitter / Youtube 等平台有用户自发传播,ThinkAny 完成了还算不错的冷启动。
20240619153808
ThinkAny 的产品特性
20240619154427
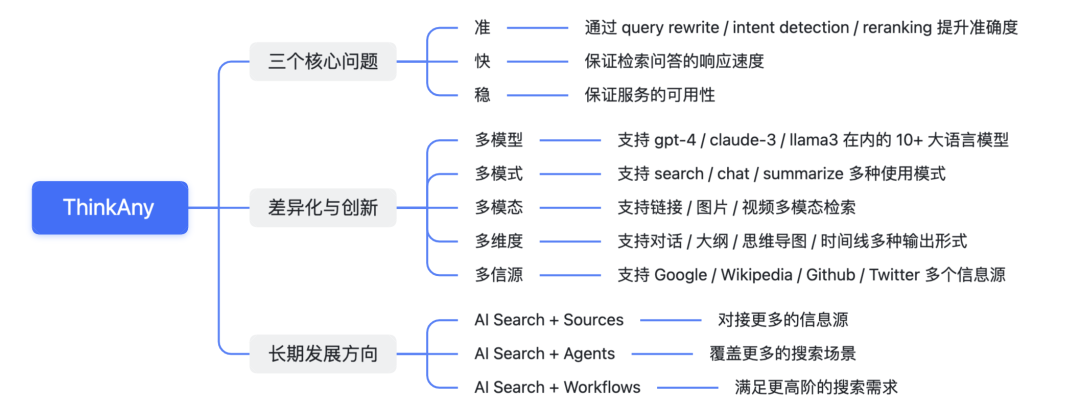
ThinkAny 虽然第一个版本实现的比较简单,但在创立之初,就一直聚焦在三个核心问题。
也就是我认为的,AI 搜索的三个要义:准 / 快 / 稳。
❝
准确度是 AI 搜索的第一要义。
用户之所以会选择使用 AI 搜索引擎,是因为传统搜索引擎不能第一时间给到用户想要的答案,往往需要点进去阅读几个链接的内容之后,才能得到足够多的信息。
而 AI 搜索引擎,解决的第一个问题就是搜索效率问题,用 AI 代替人工,阅读检索内容,总结归纳后给到用户一个直接的答案。
而这个答案,一定要有足够高的准确度。这是建立用户信任的基础,如果准确度不达标,用户使用 AI 搜索的理由就不成立。
影响 AI 搜索的两个关键因素:挂载的上下文信息密度 + 基座模型的智能程度。
ThinkAny 在基座模型的选择上,集成了 gpt-4-turbo / claude-3-opus 等大参数模型,有非常高的智能程度。
在上下文信息密度的问题上,采取了并行读取多个链接内容,暴力传输全部内容的策略。
ThinkAny 也缓存了历史对话,支持对搜索结果进行追问(连续对话)。
❝
AI 搜索的响应速度要足够快
AI 搜索的底层原理是 RAG,涉及到 Retrieve 和 Generation 两个步骤。Retrieve 要求联网检索信息的速度足够快,Generation 要求大模型生成内容的速度足够快。
除了这两个步骤之外,为了提高搜索结果的准确度,需要对检索结果进行重排(Reranking),需要获取检索到的内容详情(Read Content),这两个步骤往往是耗时的。
所谓鱼与熊掌不可兼得,在 AI 搜索准确度与响应速度之间,需要找到一个平衡。为了保证搜索准确度,有时候需要牺牲响应速度,加一些过渡动效来管理用户等待预期。
ThinkAny 目前采取的方案是,通过开关控制是否获取详情内容,线上的版本暂时关闭。表现是响应速度非常快,但准确度不够高。
后续的版本会重点优化准确度,在准与快之间找到一个更好的平衡。
❝
AI 搜索要保证高可用
软件产品的服务稳定性(高可用)是一个很常见的话题,用户规模起来之后,是必须要重视的一项工作。
影响 ThinkAny 可用性的因素,第一个是下游依赖,也就是搜索 API 与基座模型 API 的稳定性。
ThinkAny 最初的版本,大模型问答用的是 OpenAI 官方接口,有时候会遇到响应超时和账号封禁的问题,非常影响可用性,后来切到了 OpenRouter 做多模型聚合,稳定性有了很大的提高。
ThinkAny 当前的线上服务采用的是 Vercel + Supabase 的云平台部署方案。用户量和数据量起来之后也有会比较大的性能瓶颈,目前也在基于 AWS 搭建自己的 K8S 集群,后续迁移过来,在服务稳定性和动态扩容方面会有更好的表现。
除了以上三个核心问题之外,ThinkAny 五月初发布的第二个大版本,在功能差异化方面做了很多创新。
- 多模式使用 Multi-Usage-Mode
支持 Search / Chat / Summarize 三种模式,对应检索问答 / 大模型对话 / 网页摘要三种使用场景。
20240619163507
- 多模型对话 Multi-Chat-Model
集成了包括 Llama 3 70B / Claude 3 Opus / GPT-4 Turbo 在内的 10+ 大语言模型。
- 多模态检索 Multi-Mode-Search
支持检索链接 / 图片 / 视频等模态内容
- 多维度输出 Multi-Form-Output
支持以对话 / 大纲 / 思维导图 / 时间线等形式输出搜索问答内容。

20240625150128
- 多信源检索 Multi-Retrieve-Source
支持检索 Google / Wikipedia / Github 等信息源的内容,作为搜索问答的挂载上下文。
另外,ThinkAny 还开源了一个 API 项目:rag-search,完整实现了联网检索功能,并对检索结果进行重排(Reranking)/ 获取详情内容(Read Content),最终得到一份准确度还不错的检索结果。
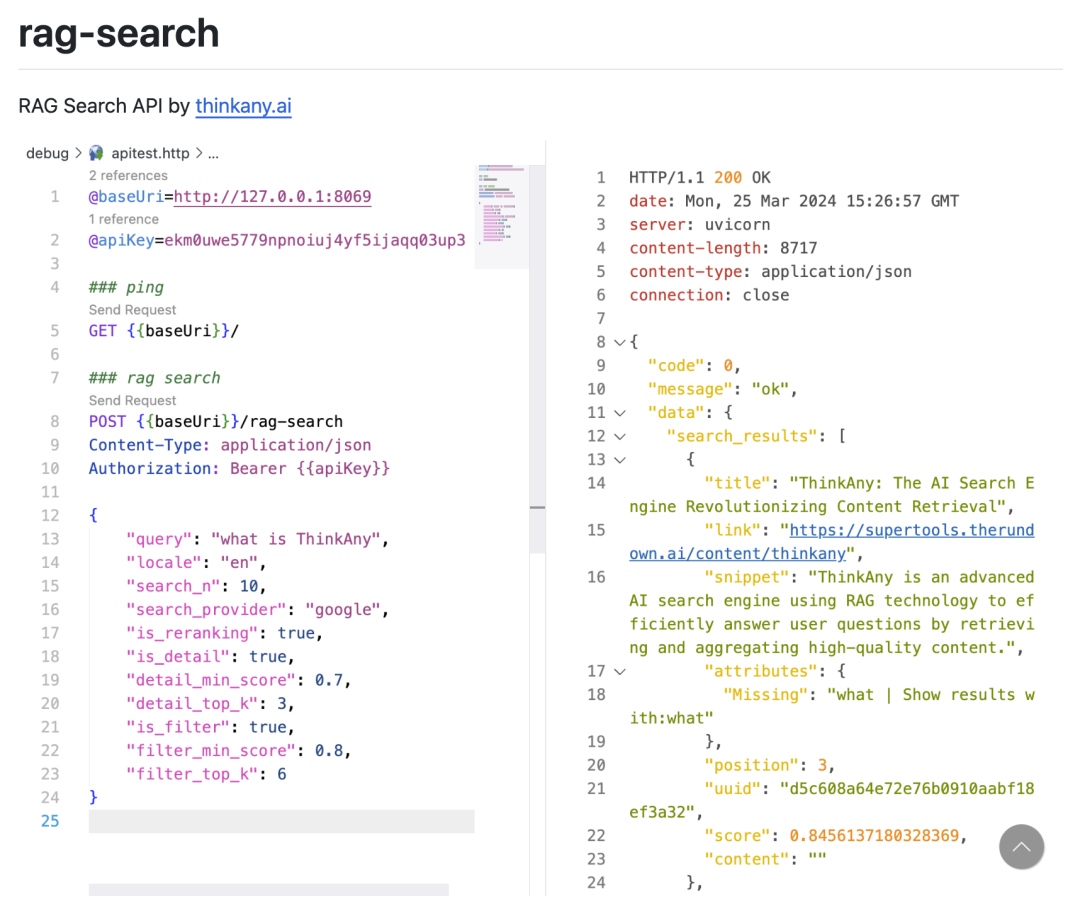
20240619163823
ThinkAny 产品的长期发展方向,会走 AI Search + Anything 的平台化路线。
允许用户挂载自定义信息源(Sources)/ 创建自定义智能体(Agents)/ 实现自定义的流程编排(Workflows)
ThinkAny 要保证基础能力的完备性,结合第三方的创意,实现一个更智能的 AI 搜索平台,覆盖更多的搜索场景。
ThinkAny 的运营情况
ThinkAny 于 2024/03/20 正式发布上线,当天获得 ProductHunt 日榜第四的成绩。
3 个月累计用户 170k,日均 UV 3k,日均 PV 20k,日均搜索 6000 次。
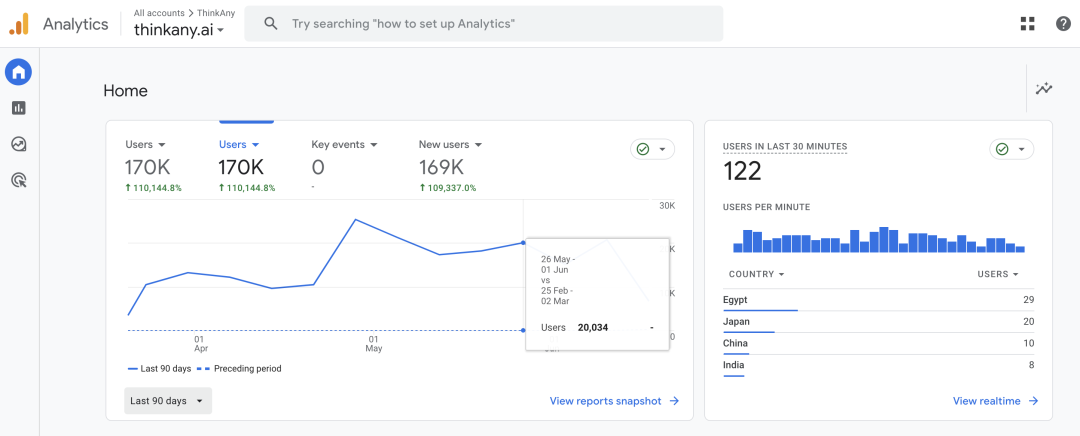
20240619181257
主要用户分布在埃及 / 日本 / 印度 / 美国 / 中国和其他中东地区。
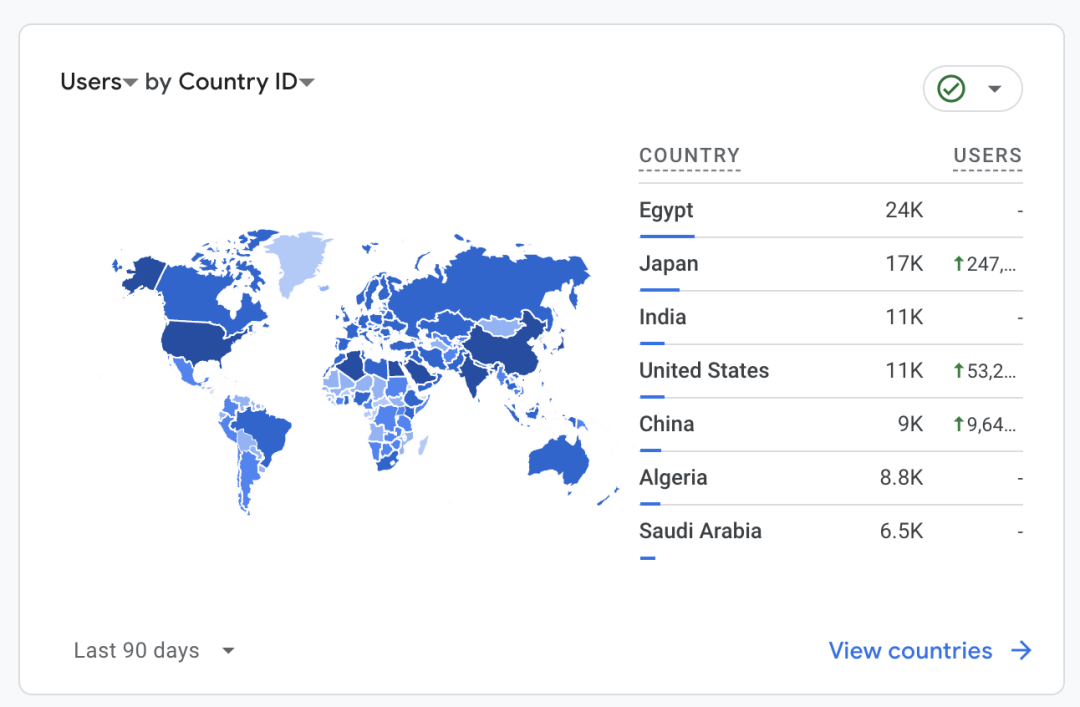
20240619181548
月访问量 580k(基于 similarweb 数据估算),5 月实际访问量较 4 月份增长 90%。
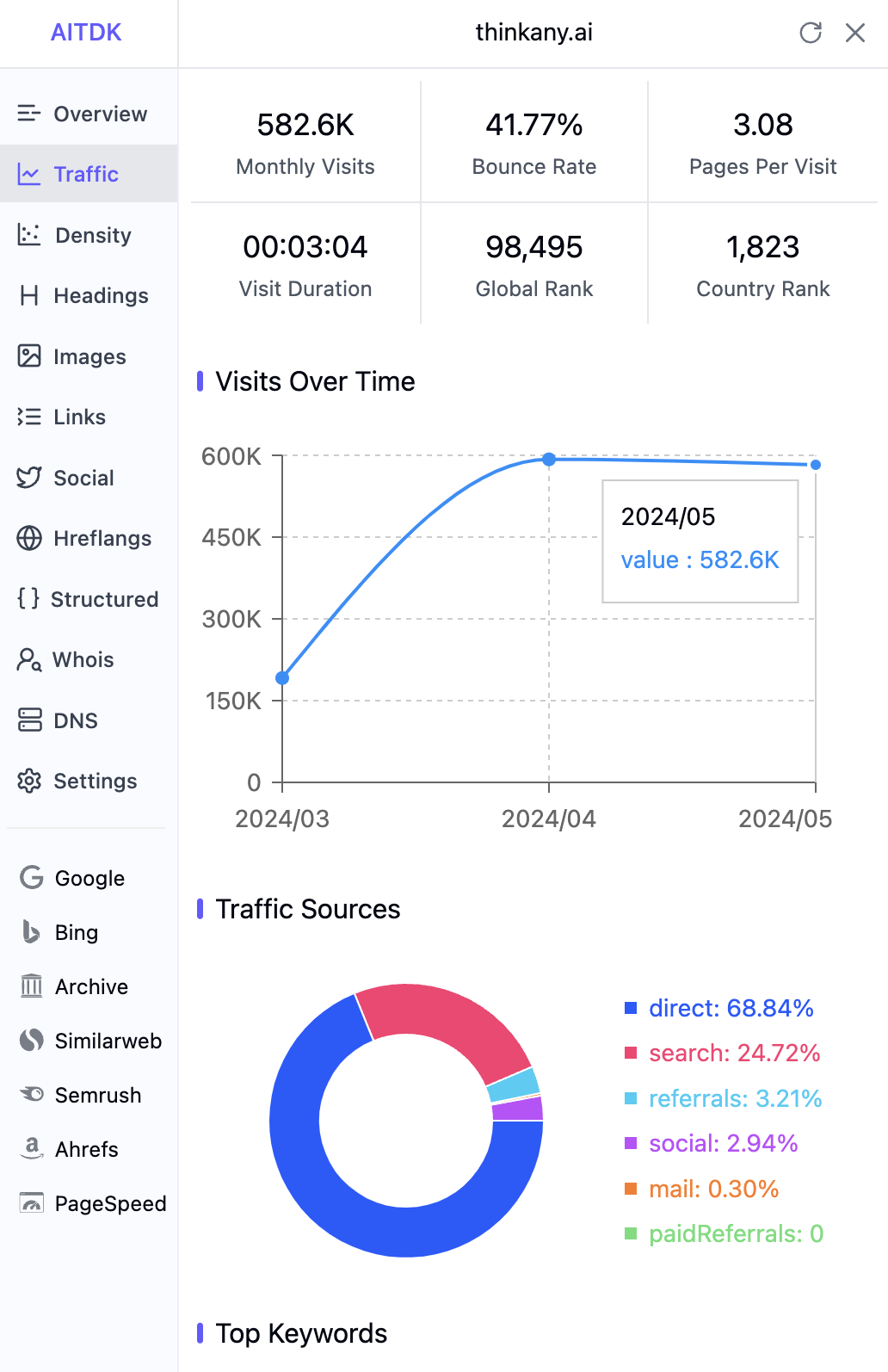
20240619181354
根据 YouTube / Twitter 等平台的用户反馈,用户最喜爱的功能是 ThinkAny 对搜索结果的思维导图摘要功能。
5 月份发布的第二个大版本,上线了用户增值付费功能,然而目前统计到的支付率比较低,仅为 0.03% 左右。
主要支出在于搜索 API 和大模型 API 的成本,当前还未实现营收平衡。
第二部分:关于 AI 搜索的认知分享
AI 搜索的标准流程
AI 搜索,一般有两个流程:一个是初次检索, 另一个是检索后追问。
用一张流程图表示如下
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

