
- 1【Unity之FairyGUI】你了解FGUI吗,跨平台多功能高效UI插件
- 22024年GitHub-上那些优秀Android开源库,这里是Top10!_github android
- 3Apache Kafka 入门教程
- 4计算机图形学|南邮——画由键盘鼠、标控制的正方体_欧拉角绘制立方体
- 5理解Java并发编程_java 并发编程 真正理解的
- 6QT多媒体编程(一)——音频编程知识详解及MP3音频播放器Demo
- 7AI全栈大模型工程师(四)OpenAI API初探_ai大模型全栈工程师 网盘下载
- 8报表工具对比之润乾报表与锐浪报表对比_锐浪报表 java
- 97月16日13:30 | ACL 2024 5个实验室专场直播开启
- 10Weblogic10.3.6补丁升级
C语言基础笔记(全)_c语言笔记
赞
踩
一、数据类型 数据的输入输出
1.数据类型 常量变量
1.1 数据类型
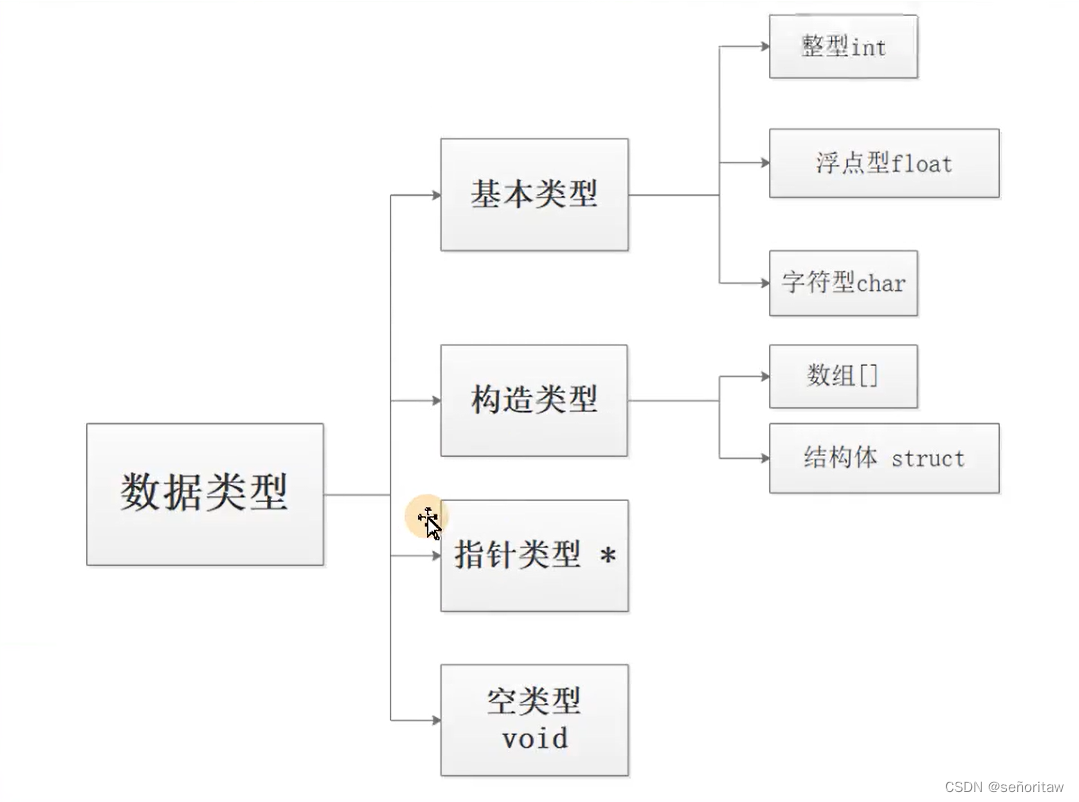
1.2 常量
程序运行中值不发生变化的量,常量又可分为整型、实型(也称浮点型)、字符型和字符串型
1.3 变量
变量代表内存中具有特定属性的存储单元,用来存放数据,即变量的值,这些值在程序的执行过程中是可以改变的
命名规则:只能由字母、数字、下划线组成,并且第一个字符必须为字母或下划线。
大写和小写是不同的字符。
1.4 整型数据
1.4.1符号常量
- #include<stdio.h>
- //符号常量
- #define PI 3+2//符号常量不需要=赋值,也不需要分号
- int main(){
- int i=PI*2;//i就是一个整型变量
- printf("i=%d\n",i);//printf是用来输出的
- }
//最终的输出结果是7 ,符号常量PI是直接替换的效果 。3+2*2=7,不等于8
1.4.2整型变量 int i
整型变量i是4个字节
printf("i size=%d\n",sizeof(i));//sizeof可以用来计算某个变量的空间大小//输出i size =4
1.5 浮点型数据
1.5.1 浮点型常量

1.5.2 浮点型变量
通过float f来定义浮点变量,f占用4个字节的空间
- #include<stdio.h>
- int main(){
- float f=3e-3;
- printf("f=%f\n",f);
- }
- //输出f=0.003000
1.6 字符型数据
1.6.1 字符型常量
用单引号括起来的一个字符是字符型常量,且只能包含一个 字符!例如,'a'、'A'、'l'、' '是正确的字符型常量,而'abc'、"a"、" "是错误的字符型常量
转义字符及其作用
| \n | 换行 |
| \b | 退格 |
| \\ | 反斜杠 |
1.6.2 字符数据在内存中的存储形式及其使用方法
字符用char定义,一个字符变量占一个字节
一个字符常量存放到字符型变量中,实际上是把该字符的ASCII码值存放到内存单元中。
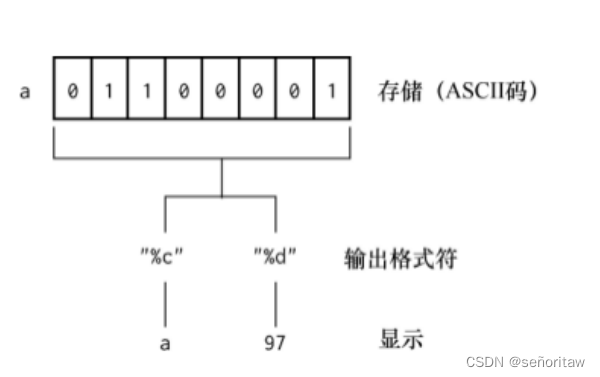
- #include<stdio.h>
- //大写表小写
- int main(){
- char c='A'; //ASCII表中A=65 a=97
- printf("%c\n",c+32);//以字符形式输出 %c打印出来的都是字符
- printf("%d\n",c);//以数值形式输出 %d打印出来的都是ASCII码值
- }
1.7 字符串型常量
由一对双引号括起来的字符序列 例如"How do you do"、"CHINA"、"$123.45"、"a"等都是合法的字符串常量
注意"a" 占用的是两个字节
"CHINA"占用的是6个字节,最后一个字符为'\0' 输出是不输出,因为无法显示
| C | H | I | N | A | \0 |
如上面,为CHINA在内存中的存储结果,所以字符的字节都比里面的字母要多一个
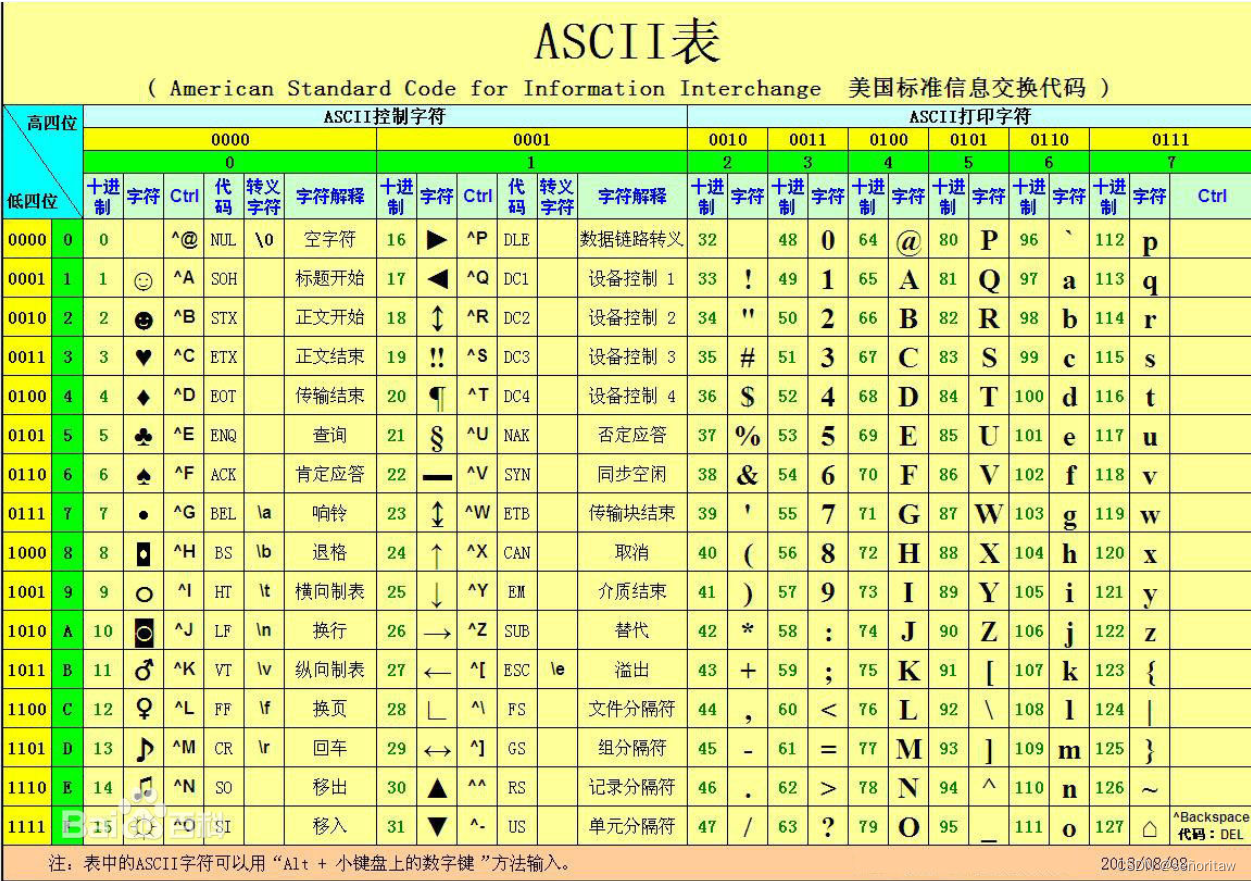
1.8 ASCII码表
2.混合运算
2.1 类型强制转换场景
整型数进行除法运算时,如果运算结果为小数,那么浮点数时一定要进行强制类型转换
- #include<stdio.h>
- //强制类型转换
- int main(){
- int i=5;
- float f=i/2;//这里做的是整型运算,因为左右操作数都是整型
- float k=(float)i/2; //(float)i 强制类型转换式 是浮点型
- printf("%f\n",f);
- printf("%f\n",k);
- return 0;
- }
- f得到的是2
- k得到的才是2.5
2.2 printf函数介绍
printf函数可以输出各种类型的数据,包括整型、浮点型、字符型、字符串型等,实际原理是printf函数将这些类型的数据格式化为字符串后,放入标准缓冲区,然后将结果显示到屏幕上
语法如下:
- #include<studio.h>
- int printf(const char*format,…);
printf函数根据format给出的格式打印输出到stdout(标准输出)和其他参数中
- int age =21;
- printf("Hello %s,you are %d years old \n","Bob",age);
代码的输出如下:
Hello Bob,you are 21 years old其中,%s表示在该位置插入首个参数(一个字符串),%d表示第二个参数(一个整数)应该放在那里,不同的%codes表示不同的变量类型,也可以限制变量的长度,printf函数如下:
| 代码 | 格式 |
| %c | 字符 |
| %d | 带符号整数 |
| %f | 浮点数 |
| %s | 一串字符 |
| %u | 无符号整数 |
| %x | 无符号十六进制数,用小写字母 |
| %X | 无符号十六进制数,用大写字母 |
| %p | 一个指针 |
| %% | 一个'%'符号 |
位于%和格式化命令之间的一个整数被称为最小字段宽度说明符,通常会加上空格来控制格式。
- 用%f精度修饰符指定想要的小数位数,例如,%5.2f会至少显示5位数字并带有2位小数点的浮点数。
- 用%s精度修饰符简单地表示一个最大的长度,以补充句点前的最小字段长度
printf函数的所有输出都是右对齐的,除非在%符号后放置了负号
例如:%-5.2f会显示5位字符、2位小数位的浮点数并且左对齐
- #include<stdio.h>
- //练习printf
- int main(){
- int i=10;
- float f=96.3;
- printf("student number=%-3d,score=%5.2f\n",i,f);//默认是右对齐,加一个负号代表左对齐
- i=100;
- f=98.21;
- printf("studentnumber=%3d,score=%5.2f\n",i,f); //3d表示后面 的数据输出时会占三个空格的位置
- return 0;
- }
3.整型进制转换
3.1整型常量的不同进制表示
计算机中只能存储二进制数,即0和1,而在对应的物理硬件上则是高、低电平.为了更方便地观察内存中的二进制数情况,除我们正常使用的十进制数外,计算机还提供了十六进制数和八进制数.
在计算机中,1字节为8位,1位即二进制的1位,它存储0或1。 int型常量的大小为4字节,即32位。
二进制 0和1
0101 0101 1个字节byte ,有8个位,bit
1KB = 1024 字节
1MB = 1024Kb
1GB = 1024MB
十进制 0-9
八进制 0-7 十进制转八进制 除18
十六进制 0-9 A-F 十进制转十六进制 除16
123为十进制 转二进制 除2 余数倒看
2 |123 1
2 |61 1
2 |30 0
2 |15 1
2 |7 1
2 |3 1
2 |1 1
0 从下往上为二进制 即0000 0000 0000 0000 0000 0111 1011
123转十六进制
16 |123 11 由于十六进制没有11 所以为7b
7
二进制转十六进制
每四位对应十六进制的一个数字
0000 0000 0000 0000 0000 0111 1011 二进制
![]()
7 b
二进制转八进制
每三位对应一个
001 111 011
1 7 3
八进制转十进制
![]()
- #include<stdio.h>
- int main(){
- int i=0x7b; //赋值八进制前面需要加个0 【0173】 十六进制前面需要加个0x 【0x7b】 十进制直接输123
- printf("%d\n",i);//十进制输出 123
- printf("%o\n",i);//%o八进制 173
- printf("%x\n",i);//%s十六进制 7b
- return 0;
- }
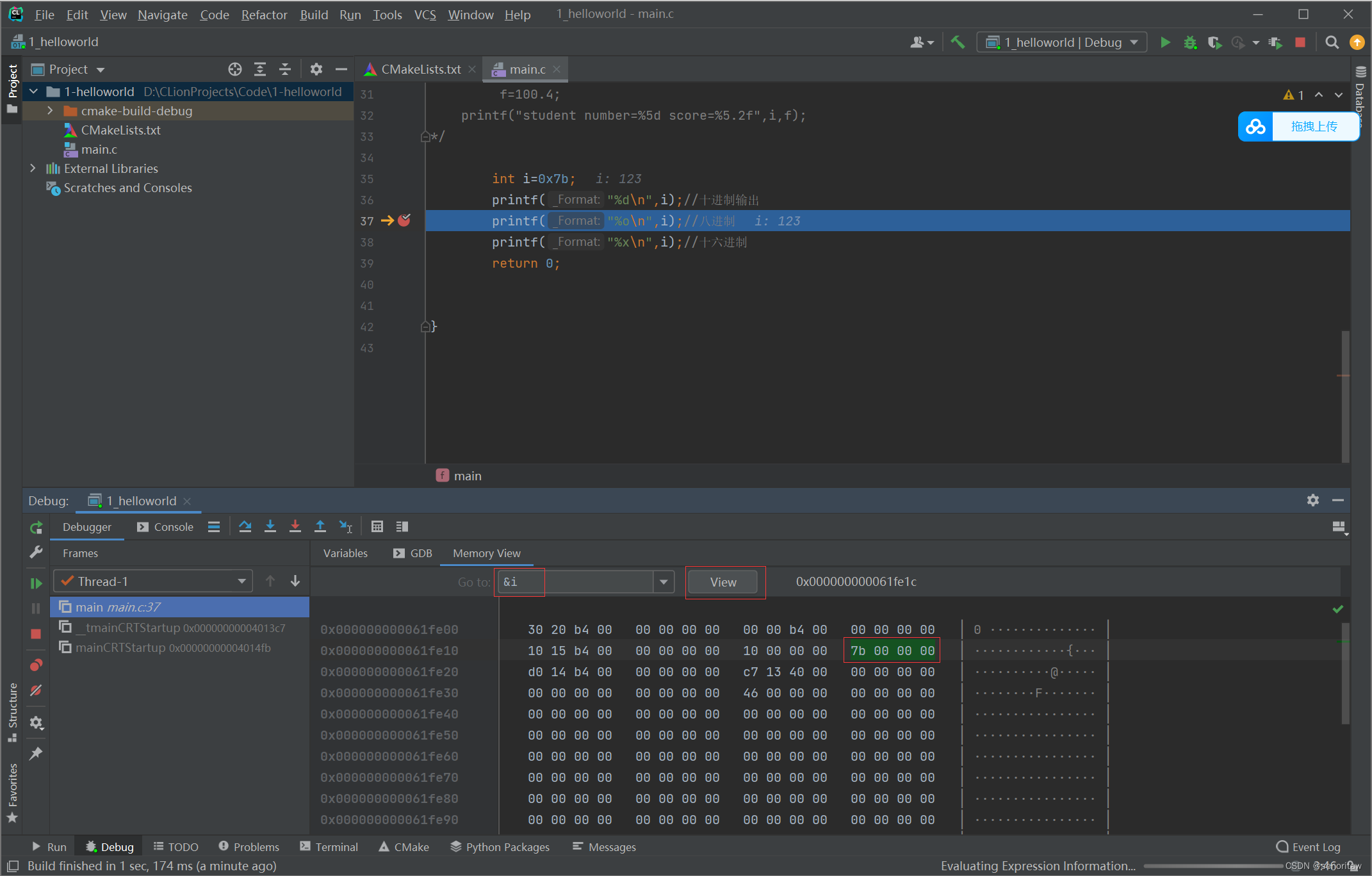
debug查看 打断点 点开内存视图 输入&i 回车查看
4.scanf读取标准输入
4.1 scanf函数的原理
C语言未提供输入/输出关键字,其输入和输出是通过标准函数库来实现的。C语言通过scanf 函数读取键盘输入,键盘输入又被称为标准输入,当scanf函数读取标准输入时,如果还没有输入任何内容,那么scanf函数会被卡住(专业用语为阻塞).如下例
- #include<stdio.h>
- //scanf用来读取标准输入,scanf把标准输入内的内容,需要放到某个变量空间里,因此变量必须取地址
- //scanf会阻塞,是因为标准输入缓冲区是空的
- int main(){
- int i;
- char c;
- float f;
- scanf("%d",&i); //注意一定要取地址&i
- printf("i=%d\n",i);//把标准缓冲区中的整型数读走了
- fflush(stdin);//清空标准输入缓冲区 不清空的话下面的输出会卡住
- scanf("%c",&c);
- printf("c=%c\n",c);//输出字符变量c
- //scanf("%f",&f);
- //printf("f=%f\n",f);
- return 0;
- }

执行时输入20,然后回车,显示结果为
20
20
c=c
进程已结束,退出代码为0
4.2 多种数据类型混合输入
当我们让 scanf函数一次读取多种类型的数据时,要注意当一行数据中存在字符型数据读取时,读取的字符并不会忽略空格和'\n'(回车符),所以编写代码时,我们需要在%d与%c之间加入一个空格。输入格式和输出效果如下图所示, scanf 函数匹配成功了4个成员,所以返回值为4,我们可以通过返回值来判断scanf函数匹配成功了几个成员,中间任何有一个成员匹配出错,后面的成员都会匹配出错.
- #include<stdio.h>
- //scanf一次读多种数据类型
- int main(){
- int i,ret; //定义ret变量 是因为scanf是由返回值的
- float f;
- char c;
- ret=scanf("%d %c%f",&i,&c,&f);//ret是指scanf匹配成功的个数 注意要在%c之前加个空格 不然后面的无法输出 遇到%c前面就加空格
- printf("i=%d,c=%c,f=%5.2f\n",i,c,f);
- return 0;
- }
二、运算符与表达式
1.运算符分类
C语言提供了13种类型的运算符,如下所示。
(1)算术运算符(+-*/ %) .
(2)关系运算符(><= >=<= !=).
(3)逻辑运算符(!&& ll) .
(4)位运算符(<< >> ~|^ &).
(5)赋值运算符(=及其扩展赋值运算符).
(6)条件运算符(?:).
(7)逗号运算符(,).
(8)指针运算符(*和&)---讲指针时讲解
(9)求字节数运算符(sizeof).
(10)强制类型转换运算符((类型)).
(11)分量运算符(.->) 。---讲结构体时讲解
(12)下标运算符([]) 。—---讲数组时讲解
(13)其他(如函数调用运算符()) 。---讲函数时讲解
2.算术运算符及算术表达式
算术运算符包含+、一、*、/和%,当一个表达式中同时出现这5种运算符时,先进行乘(*)、除(/)、取余(%),取余也称取模,后进行加(+)、减(-).
也就是乘、除、取余运算符的优先级高于加、减运算符.
- #include<stdio.h>
- //练习算术运算符
- int main(){
- int result=4+5*2-6/3+11%4;
- printf("result=%d\n",result);
- return 0;
- }
- result=15
3.关系运算符与关系表达式
关系运算符>、<、==、>=、<=、!=依次为大于、小于、是否等于、大于等于、小于等于和不等于。由关系运算符组成的表达式称为关系表达式。
关系表达式的值只有真和假,对应的值为1和0。由于C语言中没有布尔类型,所以在C语言中0值代表假,非0值即为真。
例如,关系表达式3>4为假,因此整体值为0,而关系表达式5>2为真,因此整体值为1。关系运算符的优先级低于算术运算符
如果要判断三个变量a、b、c是否相等,那么不能写为a==b==c,而应写为a==b &&b==C
- #include<stdio.h>
- //关系运算符,优先级小于算术运算符
- int main(){
- int a;
- while(scanf("%d",&a))
- {
- if(3<a&&a<10)//a大于3同时a小于10要这样写 不能写成3<a<10
- {
- printf("a is between 3 and10\n");
- }else{
- printf("a is not between 3 and 10\n");
- }
- }
- return 0;
- }
运算符的优先级表
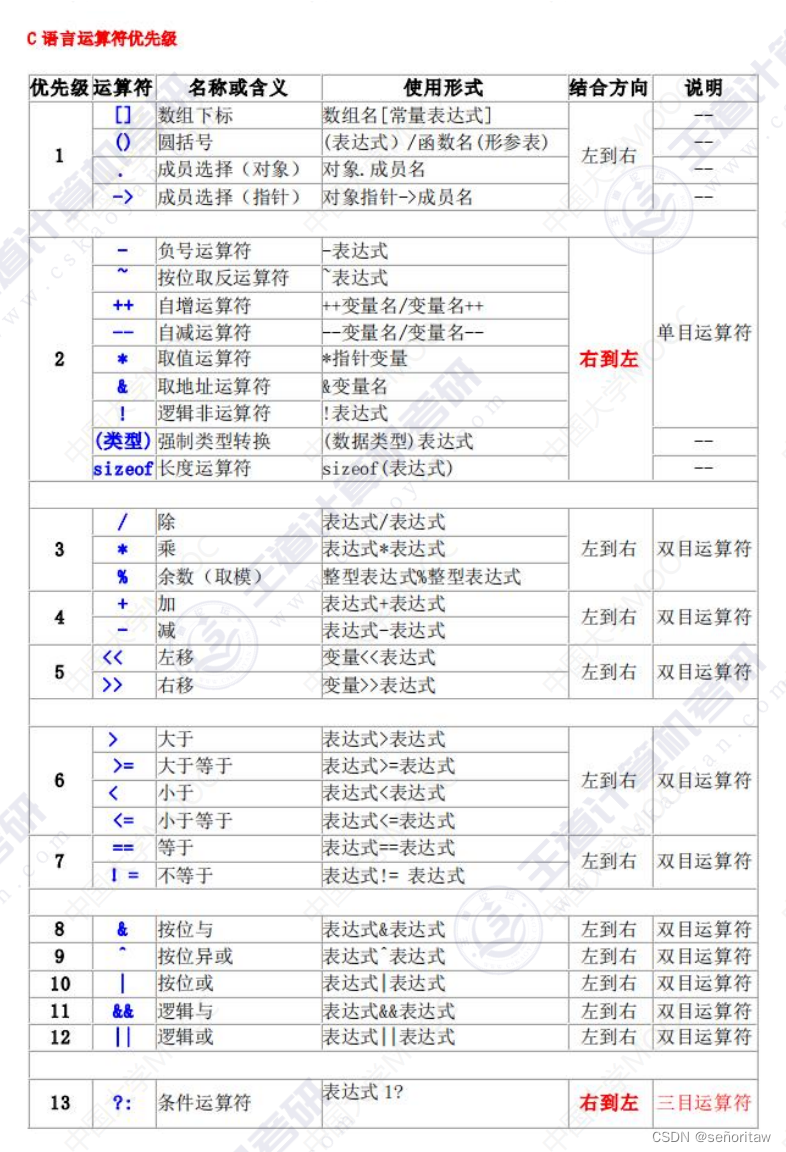
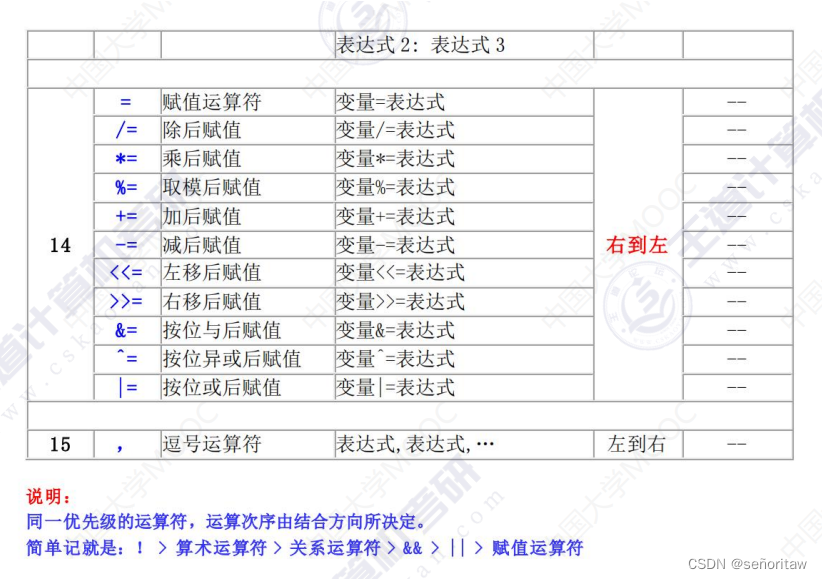
4.逻辑运算符与逻辑表达式
逻辑运算符!、&&、ll依次为逻辑非、逻辑与、逻辑或,这和数学上的与、或、非是一致的.逻辑非的优先级高于算术运算符,逻辑与和逻辑或的优先级低于关系运算符.
逻辑表达式的值只有真和假,对应的值为1和0.
下例中的代码是计算一年是否为闰年的例子,因为需要重复测试,所以我们用了一个 while循环。
- #include<stdio.h>
- //记住优先级目的,不能够加多余的括号
- int main(){
- int year,i,j=6;
- while(scanf("%d",&year))
- {
- if(year%4==0&&year%100!=0||year%400==0)
- {
- printf("%d is leap year\n",year);
- }else{
- printf("%d is not leap year\n",year);
- }
- }
- i=!!j; //逻辑非 非非j 自右至左
- printf("i value=%d\n",i);
- return 0;
- }
- //逻辑与和逻辑或短路运算
- int main(){
- int i=0;
- i&&printf("you can't see me!\n");//当i为假时,不会执行逻辑与后的表达式,称为短路运算 等价于if(为真){}else{} 简洁代码
- i=1;
- i||printf("you can't see me!\n");
- return 0;
- }
5.赋值运算符
a = b+ 25;
a是一个左值,它标识了一个可以存储结果值的地点; b+25是一个右值,因为它指定了一个值。
- #include<stdio.h>
- int main(){
- int a=1,b=2;
- b+25=a; //b+25不能作为左值,因为它并未标识一个特定的位置(并不对应特定的内存空间)
- return 0;
- }
上面的例子执行时会报下面的编译错误
Error:lvalue required as left operand of assignment
5.1复合赋值运算符
复合赋值运算符操作是一种缩写形式,复合赋值运算符能使对变量的赋值操作变得更加简洁。
iNum = iNum + 5;
对变量 iNum的赋值进行操作,值为这个变量本身与一个整型常量5相加的结果.使用复合语句可以实现同样的操作。例如,上面的语句可以修改为
iNum+=5;
赋值运算符与复合赋值运算符的区别如下:
(1)复合赋值运算符简化了程序,可使程序精炼,提升阅读速度。
(2)复合赋值运算符提高了编译效率.
- int main(){
- int a=1,b=2;
- a+=3;
- b*=5;
- printf("a=%d\n",a);
- printf("b=%d\n",b);
- return 0;
- }
6.求字节运算符sizeof
sizeof不是一个函数,而是一个运算符,不像其他运算符是一个符号,sizeof是字母组成的,用于求常量或变量所占用的空间大小
- #include<stdio.h>
- //sizeof运算符
- int main(){
- int i=0;
- printf("i size is%d\n",sizeof(i));
- return 0;
- }
运行结果为i size is 4,可以求得整型变量占用的空间大小是4个字节。
三、选择、循环
关系表达式与逻辑表达式
算术运算符的优先级高于关系运算符、
关系运算符的优先级高于逻辑与和逻辑或运算符
相同优先级的运算符从左至右进行结合
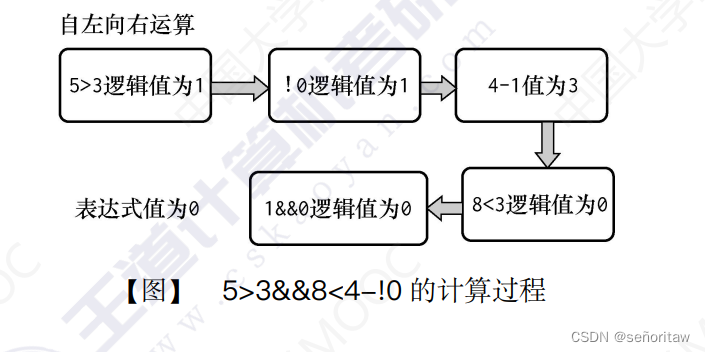
表达式5>3&&8<4-!0的最终值是多少?其计算过程如下图所示。
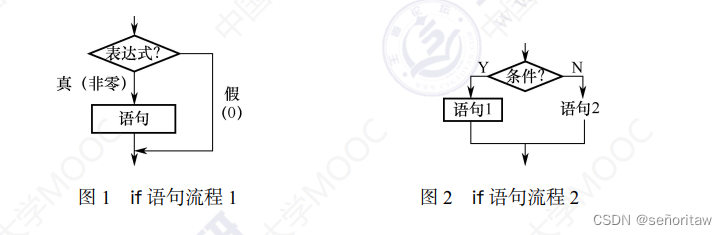
1.if-else语句
- int main(){
- int year;
- scanf("%d",&year);
- if(year%4==0&&year%100!=0||year%400==0)
- {
- printf("yes\n");
- }else{
- printf("no\n");
- }
- return 0;
- }
if语句和else语句也可以多个同时使用(多分支语句)
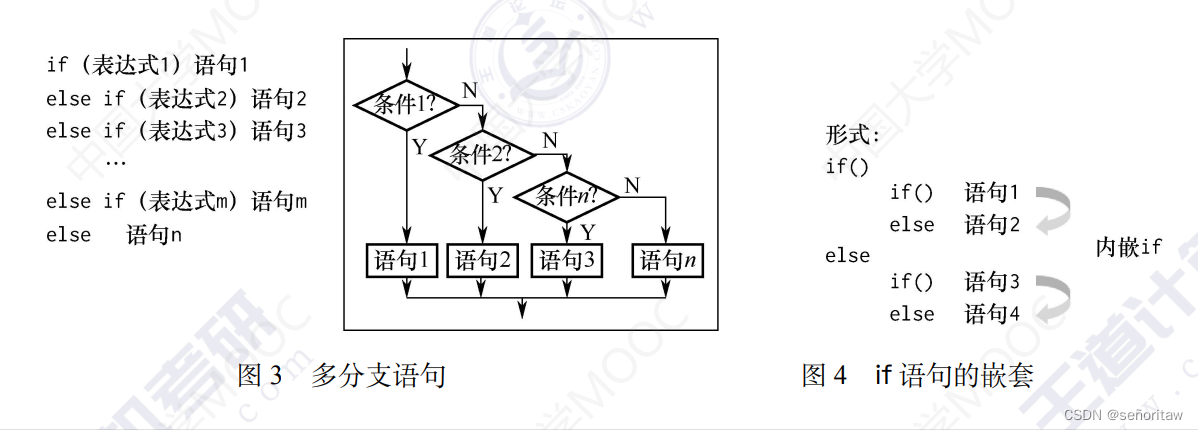
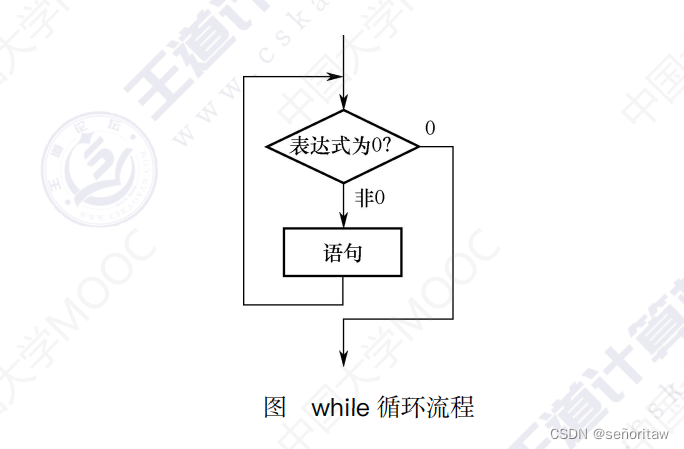
2.while循环
while 语句用来实现“当型”循环结构,其一般形式为“while(表达式)语句;”,当表达式的值非0时,执行while语句中的内嵌语句。
其特点是:先判断表达式,后执行语句。
- //计算从1到100的和
- int main(){
- int i=1,total=0;
- while(i<=100)//在这里加分号会造成死循环
- {
- if(i%2==0)
- {
- i++;
- continue;//continue下面的代码均不会得到执行
- }
- total=total+i;//把i加到total上
- i++;//i++等价于i+=1;在循环体内没有让while判断表达式趋近于假的操作,死循环
- }
- printf("total=%d\n",total);
- return 0;
- }
3.for循环
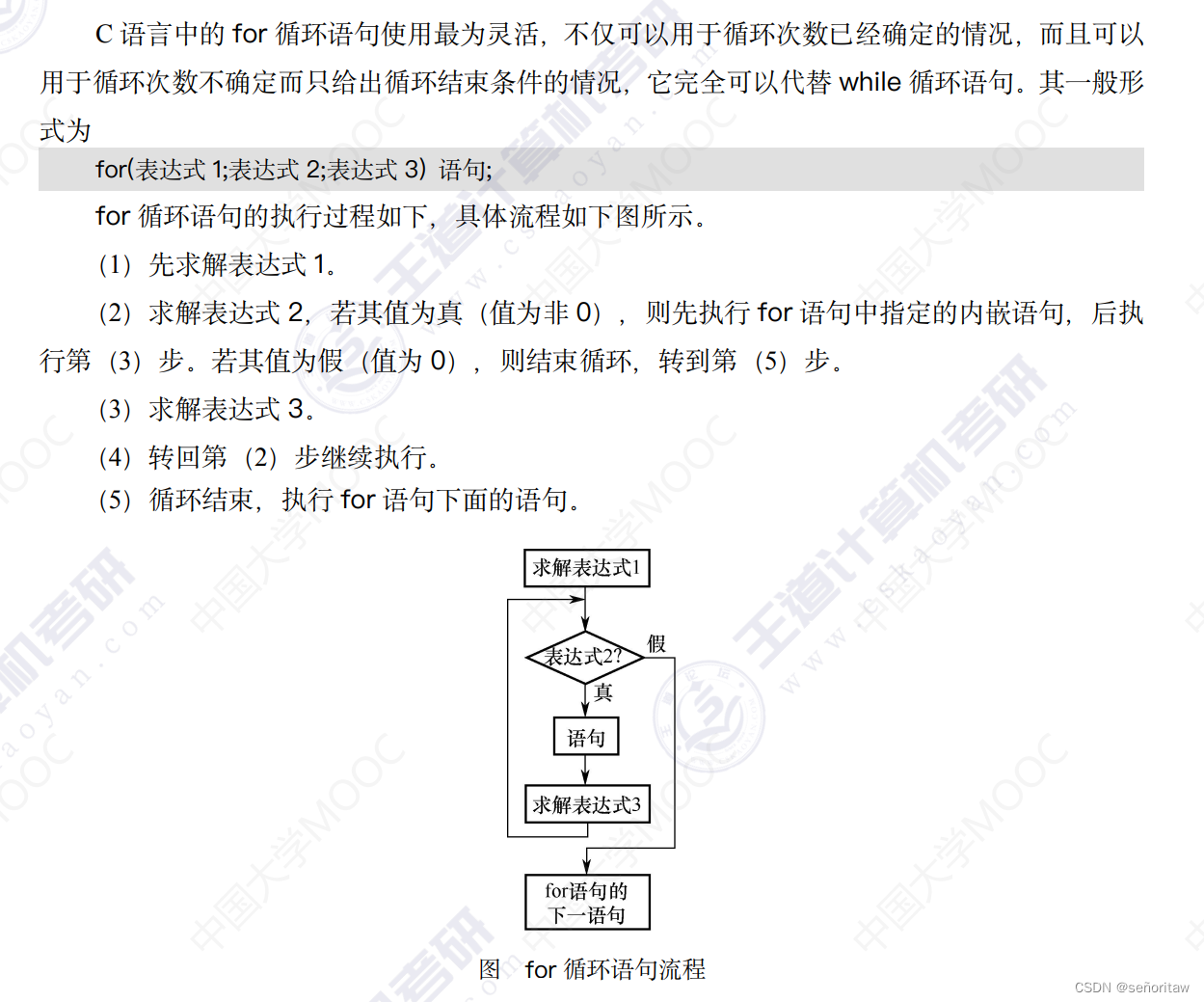
for循环语句中必须且只能有两个分号,用于分割表达式1、表达式2、和表达式3
- //for循环实现从1加到100
- int main(){
- int i,total;
- for(i=1,total=0;i<=100;i++)//for小括号后不要加分号
- {
- total+=i;
- }
- printf("total=%d\n",total);
- return 0;
- }
for循环的可读性比while循环要好,所以能使用for循环时不要强制改为while循环
4.continue语句
continue语句的作用为结束本次循环,即跳过循环体中下面尚未执行的语句,接着进行是否执行下一次循环的判断
continue;
- //for循环实现从1加到100
- //使用continue
- int main(){
- int i,total;
- for(i=1,total=0;i<=100;i++)//for小括号后不要加分号
- {
- if(i%2==0)
- {
- continue;//continue下面的代码均不会得到执行
- }
- total+=i;
- }
- printf("total=%d\n",total);
- return 0;
- }
5.break语句
break语句的作用是结束整个循环过程,不再判断执行循环的条件是否成立
例:从1开始累加,当累加的和大于2000时,结束for循环,同时打印此时total的值和i的值,一旦执行break语句,下一句要执行的就是“printf("total=%d,i=%d\n",total,i);”,break语句也可以用在while循环和do while循环中,起到结束对应循环的作用
- int main(){
- int i,total;
- for(i=1,total=0;i<=100;i++)//for小括号后不要加分号
- {
- if(total>2000)
- {
- break;//当和大于2000时,循环结束
- }
- total+=i;
- }
- printf("total=%d,i=%d\n",total,i);
- return 0;
- }
四、一维数组与字符数组
1.一维数组
1.1数组的定义
数组,是指一组具 有相同数据类型的数据的有序集合。可通过一个符号来 访问多个元素
一维数组的定义格式为
类型说明符 数组名 [常量表达式];
int a[10];
定义一个整型数组,数组名为 a,它有 10 个元素。
声明数组时要遵循以下规则:
(1)数组名的命名规则和变量名的相同,即遵循标识符命名规则。
(2)在定义数组时,需要指定数组中元素的个数,方括号中的常量表达式用来表示元素的 个数,即数组长度。
(3)常量表达式中可以包含常量和符号常量,但不能包含变量。也就是说,C 语言不允许 对数组的大小做动态定义,即数组的大小不依赖于程序运行过程中变量的值
以下是错误的声明示例(最新的 C 标准支持,但是最好不要这么写):
int n;
scanf("%d", &n); /* 在程序中临时输入数组的大小 */
int a[n];
数组声明的其他常见错误如下:
① float a[0]; /* 数组大小为 0 没有意义 */
② int b(2)(3); /* 不能使用圆括号 */
③ int k=3, a[k]; /* 不能用变量说明数组大小*/
1.2 一维数组在内存中的存储
语句 int mark[100];定义的一维数组 mark 在内存中的存放情况如下图所示,每个元素都是 整型元素,占用 4 字节,数组元素的引用方式是“数组名[下标]”,所以访问数组 mark 中的元素 的方式是 mark[0],mark[1],…,mark[99]。注意,没有元素 mark[100],因为数组元素是从 0 开 始编号的
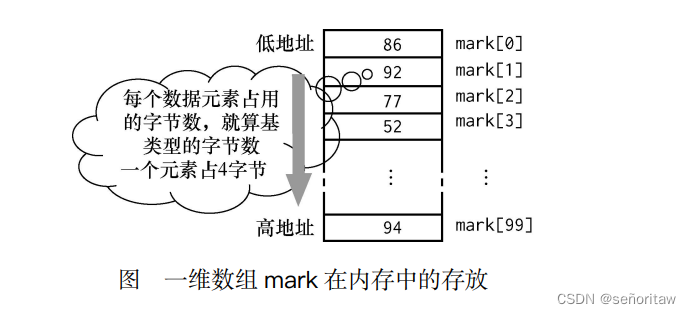
一维数组的初始化方法。
(1)在定义数组时对数组元素赋初值。例如,
int a[10]={0,1,2,3,4,5,6,7,8,9};
不能写成
int a[10];a[10]={0,1,2,3,4,5,6,7,8,9}
(2)可以只给一部分元素赋值。例如,
int a[10]={0,1,2,3,4};
定义 a 数组有 10 个元素,但花括号内只提供 5 个初值,这表示只给前 5 个元素赋初值,后 5 个
元素的值为 0。
(3)如果要使一个数组中全部元素的值为 0,那么可以写为
int a[10]={0,0,0,0,0,0,0,0,0,0};
或
int a[10]={0};
(4)在对全部数组元素赋初值时,由于数据的个数已经确定,因此可以不指定数组的长度。
int a[]={1,2,3,4,5};
2.数组的访问越界
下面借助一个数组的实例来掌握数组元素的赋值、访问越界。
- int main()
- {
- int a[5]={1,2,3,4,5}; //定义数组时,数组长度必须固定
- int j=20;
- int i=10;
- a[5]=6; //越界访问
- a[6]=7; //越界访问会造成数据异常
- printf("i=%d\n",i); //i 发生改变
- return 0;
- }
下图显示了代码运行情况。在内存视图依次输入&j、&a、&i 来查看整型变量 j、整型数组 a、整型变量 i 的地址,即可看到三个变量的地址,这里就像我们给衣柜的每个格子的编号,第一格、第二格……一直到柜子的最后一格。操作系统对内存中的每个位置也给予一个编号,对于 Windows 32 位控制台应用程序来说,这个编号的范围是从 0x00 00 00 00 到 0xFF FF FF FF,总计为 2 的 32 次方,大小为4G。这些编号称为地址(我们是 64 位程序,地址显示的是 64)
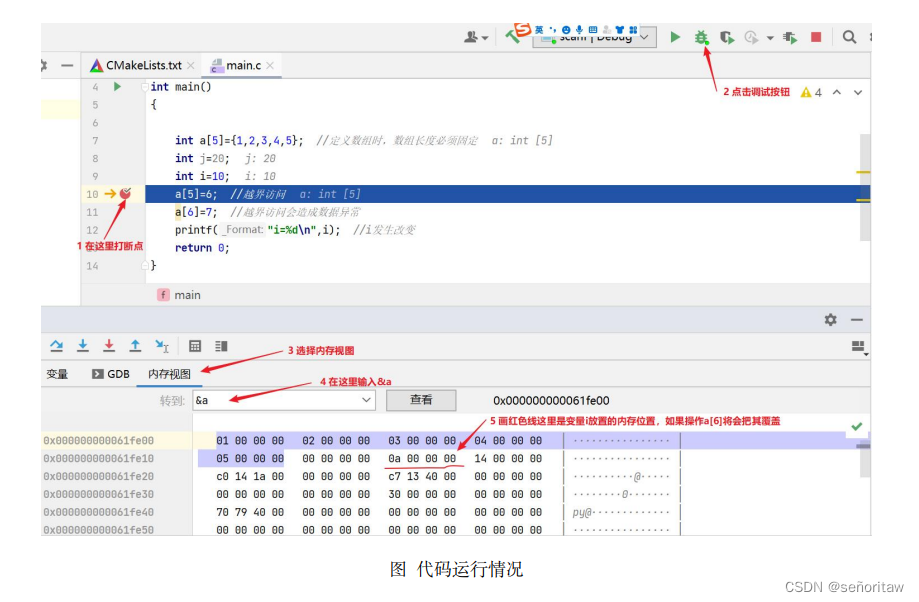
在变量窗口中输入sizeof(a),可以看到数组a的大小为20字节,计算方法其实就是sizeof(int)*5: 数组中有 5 个整型元素,每个元素的大小为 4 字节,所以共有 20 字节。访问元素的顺序是依次从 a[0]到 a[4],a[5]=6、a[6]=7 均为访问越界。下图显示了代码运行情况,从中看出,执行到第 12 行时,变量 i 的值被修改了,这就是访问越界的危险性——未对变量 i 赋值,其值却发生了改变
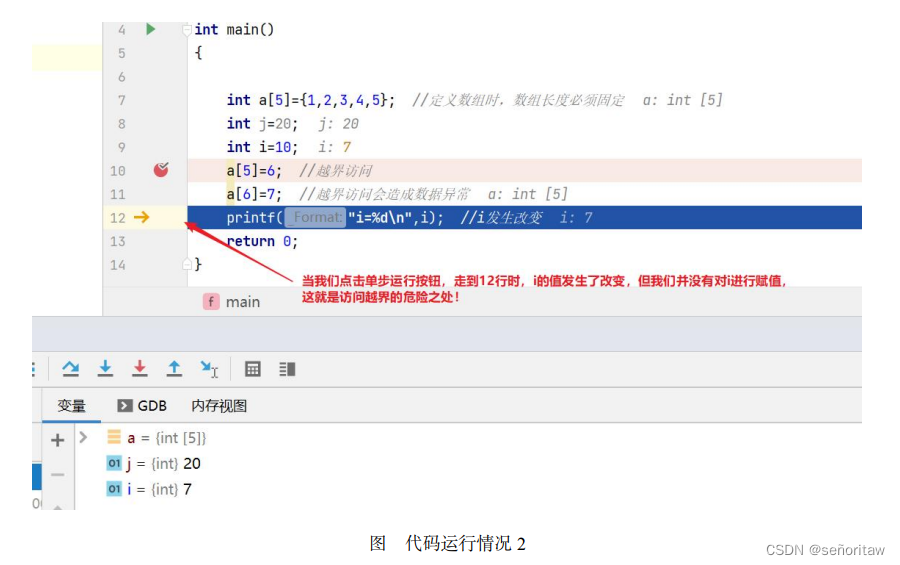
数组另一个值得关注的地方是,编译器并不检查程序对数组下标的引用是否在数组的合法范围内。如果下标值 是通过那些已知正确的值计算得来的,那么就无须检查;如果下标值是由用户输入的数据产生的, 那么在使用它们之前就必须进行检查,以确保它们位于有效范围内。
3.数组的传递
- //一维数组的传递,数组长度无法传递给子函数
- //C 语言的函数调用方式是值传递
- void print(int b[],int len)
- {
- int i;
- for(i=0;i<len;i++)
- {
- printf("%3d",b[i]);
- }
- b[4]=20; //在子函数中修改数组元素
- printf("\n");
- }
-
- //数组越界
- //一维数组的传递
- #define N 5
- int main()
- {
- int a[5]={1,2,3,4,5}; //定义数组时,数组长度必须固定
- print(a,5);
- printf("a[4]=%d\n",a[4]); //a[4]发生改变
- return 0;
- }
如下图 1 所示,进入 print 函数,发现数组 b 的大小变为8 字节,如下图 2 所示,这是因为一维数组在传递时,其长度是传递不过去的,所以我们通过 len来传递数组中的元素个数。
实际数组名中存储的是数组的首地址,在调用函数传递时,是将数组的首地址给了变量 b(其实变量 b 是指针类型,指针8个字节),在 b[]的方括号中填写任何数字都是没有意义的。
这时我们在 print 函数内修改元素 b[4]=20,可以看到数组 b 的起始地址和 main 函数中数组 a 的起始地址相同,即二者在内存中位于同一位置,函数执行结束时,数组 a 中的元素 a[4]就得到了修改

4.字符数组初始化及传递
字符数组的定义方法与前面介绍的一维数组类似。例如,
char c[10];
字符数组的初始化可以采用以下方式。
(1)对每个字符单独赋值进行初始化。例如,
c[0]='I';c[1]=' ';c[2]='a';c[3]='m';c[4]='';c[5]='h';c[6]='a';c[7]='p';c[8]='p';c[9]='y';
(2)对整个数组进行初始化。例如,
char c[10]={'I','a','m','h','a','p','p','y'}
但工作中一般不用以上两种初始化方式,因为字符数组一般用来存取字符串。通常采用的初始化方式是 char c[10]= "hello"。因为 C 语言规定字符串的结束标志为'\0',而系统会对字符串常量自动加一个'\0',为了保证处理方法一致,一般会人为地在字符数组中添加'\0',所以字符数组存储的字符串长度必须比字符数组少 1 字节。例如,char c[10]最长存储 9 个字符,剩余的 1个字符用来存储'\0'。
- 【例】字符数组初始化及传递
- #include <stdio.h>
- //print 函数模拟实现 printf 的%s 打印效果
- void print(char c[])
- {
- int i=0;
- while(c[i])
- {
- printf("%c",c[i]);//当 c[i]为'\0'时,其值是 0,循环结束,也可以写为 c[i]!='\0'。
- i++;
- }
- printf("\n");
- }
-
- //字符数组存储字符串,必须存储结束符'\0'
- int main()
- {
- char c[5]={'h','e','l','l','o'};
- char d[5]="how";
- printf("%s\n",c); //会发现打印了乱码 ,printf 通过%s 打印字符串时,原理是依次输出每个字符,当读到结束符'\0'时,结束打印;
- printf("%s\n",d);
- print(d);
- return 0;
- }
5.scanf 读取字符串
- #include <stdio.h>
- //scanf 读取字符串时使用%s
- int main()
- {
- char c[10];
- char d[10];
- scanf("%s",c);
- printf("%s\n",c);
- scanf("%s%s",c,d);
- printf("c=%s,d=%s\n",c,d);
- return 0;
- }
scanf 通过%s 读取字符串,对 c 和 d 分别输入"are"和"you"(中间加一个空格),scanf在使用%s 读取字符串时,会忽略空格和回车(这一点与%d 和%f 类似)。
输入顺序及执行结果如下图
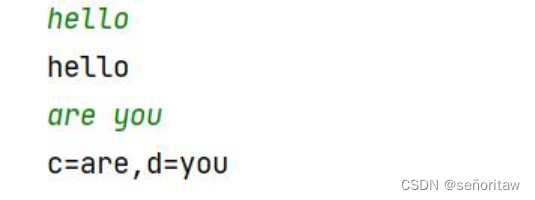
6.gets 函数与 puts 函数
gets 函数类似于 scanf 函数,用于读取标准输入。 scanf 函数在读取字符串时遇到空格就认为读取结束,所以当输入的字符串存在空格时,需要使用 gets 函数进行读取。gets 函数的格式如下:
char *gets(char *str);
puts 函数类似于 printf 函数,用于输出标准输出。puts 函数的格式如下:
int puts(char *str);
函数 puts 把 str(字符串)写入 STDOU(标准输出)。puts 会将数组 c 中存储的"how areyou"字符串打印到屏幕上,同时打印换行,相对于 printf 函数,puts 只能用于输出字符串,同时多打印一个换行符,等价于 printf(“%s\n”,c)
- //gets 一次读取一行
- int main()
- {
- char c[20];
- gets(c);
- puts(c);
- return 0;
- }

7.str 系列字符串操作函数(机试重要)
str 系列字符串操作函数主要包括 strlen、strcpy、strcmp、strcat 等。
strlen 函数用于统计字符串长度,
strcpy 函数用于将某个字符串复制到字符数组中,
strcmp 函数用于比较两个字符串的大小,
strcat 函数用于将两个字符串连接到一起。
各个函数的具体格式如下所示:
- #include <string.h> //引入头文件
-
- size_t strlen(char *str);
- char *strcpy(char *to, const char *from);
- int strcmp(const char *str1, const char *str2);
- char *strcat(char *str1, const char *str2);
对于传参类型 char*,直接放入字符数组的数组名即可。
- #include <stdio.h>
- #include <string.h>
- //str 系列字符串操作函数的使用。
- int mystrlen(char c[]) {
- int i = 0;
- while (c[i++]);
- return i - 1;
- }
- //strlen 统计字符串长度
-
- int main() {
- int len; //用于存储字符串长度
- char c[20];
- char d[100] = "world";
- gets(c);
- puts(c);
- len = strlen(c);
- printf("len=%d\n", len);
- len = mystrlen(c);
- printf("mystrlen len=%d\n", len);
- strcat(c, d);
- strcpy(d, c); //c 中的字符串复制给 d
- puts(d);
- printf("c?d %d\n", strcmp(c, d));
- puts(c);
- return 0;
- }
下图所示为我们输入"hello"后的执行结果

五、指针
5.1 指针的定义
内存区域中的每字节都对应一个编号,这个编号就是“地址”.
在程序中定义一个变量,在对程序进行编译时,系统就会给这个变量分配内存单元.
按变量地址存取变量值的方式称为“直接访问”,如printf(""%d",i);、 scanf("%d",&i);等,
另一种存取变量值的方式称为“间接访问”,即将变量i的地址存放到另一个变量中.
在C语言中,指针变量是一种特殊的变量,它用来存放变量地址。
指针变量的定义格式如下:
基类型 *指针变量名;
例如
int *i_pointer;
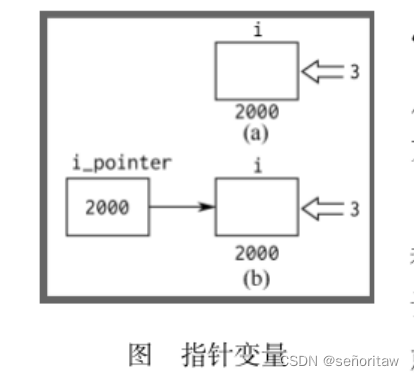
指针与指针变量是两个概念,一个变量的“地址”成为该变量的“指针”
用来存放一个变量的地址(即指针)的变量,称为“指针变量”
如下图的i_pointer,在64位应用程序中,sizeof(i_pointer)=8,即占8个字节
如果考研强调程序是32位的,则寻址范围为4字节
5.2 取地址操作符与取值操作符,指针本质
取地址操作符为&,也称引用,通过&可以获取一个变量的地址值;
取值操作符为*,也称解引用,通过*可以得到一个地址对应的数据。
如下例,通过&i获取整型变量i的地址值,然后对整型指针变量p进行初始化, p中存储的是整型变量i的地址值,所以通过*p(printf 函数中的*p)就可以获取整型变量i的值. p中存储的是一个绝对地址值,
- #include <stdio.h>
-
- int main() {
- int i=5;
- //定义了一个指针变量,i_pointer就是指针变量名
- //指针变量的初始化一定是某个变量取地址来赋值,不能随机写个数
- int *i_pointer;
- i_pointer=&i;
- printf("i=%d\n",i); //直接访问
- printf("*i_pointor=%d",*i_pointer);
- return 0;
- }
注意:
(1)指针变量前面的“*”表示该变量为指针型变量。
例如,float *pointer_1;
指针变量名是pointer_1 ,而不是*pointer_1.
(2)在定义指针变量时必须指定其类型。只有整型变量的地址才能放到指向整型变量的指针变量中。例如,下面的赋值是错误的:
float a;
int * pointer_1;
pointer_1=&a;//毫无意义而且会出错
(3)如果已执行了语句
pointer_1=&a; 那&*pointer_1与&a相同,都表示变量a的地址,即pointer_1
即虽然”&“和”*“两个运算符的优先级相同,但是要按自右向左的方向结合*&a表示,先进行&a的运算,得到a的地址,在进行*运算,*&a和*pointer_1的作用一样,都等价于变量a,即*&a与a等价
int *a,b,c;表示声明了一个指针变量,两个int变量
要声明三个指针变量需要写成int *a,*b,*c;
指针的使用场景只有两个,即传递和偏移
5.3 指针的传递
下例的主函数通过子函数改变量i的值,但是执行程序后发现i的值并未发生改变
因为i的地址和j的地址实际并不相同,执行change函数改变的并不是之前定义的i的地址
- #include <stdio.h>
- void change(int j){ //j是形参
- j=5;
- }
- int main() {
- int i=10;
- printf("before value i=%d\n",i);
- //在子函数内去改变主函数的某个变量值
- change(i); //C语言的函数调用是值传递,实参赋值给形参,j=i
- printf("after value i=%d\n",i);
- return 0;
- }
-
- //输出结果都是10
原理如下图所示,程序的执行过程其实就是内存的变化过程,当main函数执行时,系统会为其开辟函数栈空间,当程序走到int i时,main函数的栈空间就会为变量i分配4字节大小的空间,调用change函数时,系统会为change函数重新分配新的函数栈空间,并为形参变量j分配4字节大小的空间,调用change(i)实际是将i的值赋值给j,这就是值传递,当change()中修改变量j的值后,函数执行结束,其栈空间就会释放,j就不再存在,i的值不会改变。

要在子函数中修改main函数的值,如下所示,通过指针进行操作
- #include <stdio.h>
- void change(int *j){ //j是形参
- *j=5; //间接访问得到变量i *j等价于变量i
- }
-
- //指针的传递
- int main() {
- int i=10;
- printf("before value i=%d\n",i);
- change(&i); //传递变量i的地址 j=&i
- printf("after value i=%d\n",i);
- return 0;
- }
-
- //执行change()后,打印的i的值为5
变量i的地址传递给change函数时,实际效果是j=&i,依然是值传递,只是这时候的j是一个指针变量,内部存储的是变量i的地址,所以通过*j就间接访问到了与变量i相同的区域,通过*j=5就实现了对变量i的值的改变。
5.4 指针的偏移使用场景
5.4.1 指针的偏移
拿到指针变量后可以对他进行加减,如找到一栋楼是2栋,那往前就是1栋,往后就是3栋
- #include <stdio.h>
- //指针的偏移使用场景,也就是对指针进行加减
- #define N 5 //符号常量N
- int main() {
- int a[N]={1,2,3,4,5}; //数组名内存中存储了数组的起始地址,a中存储的就是一个地址值
- int *p;//定义指针变量p
- p=a;//不是取地址a 因为数组名中本来就有地址
- int i;
- for(i=0;i<N;i++){
- printf("%3d",*(p+i)); //这里*(p+i)和a[i]的结果是等价的
- }
- printf("\n-------------------------------\n");
- p=&a[4]; //让p指向最后一个元素
- for(i=0;i<N;i++){ //逆序输出
- printf("%3d",*(p-i));
- }
- printf("\n");
- return 0;
- }
1 2 3 4 5
-------------------------------
5 4 3 2 1
如下图所示,数组名中存储着数组的起始地址Ox61fdf0,其类型为整型指针,所以可以将其赋值给整型指针变量p,可以从监视窗口中看到p+1的值为Ox61fdf4.指针变量加1后,偏移的长度是其基类型的长度,也就是偏移sizeof(int),这样通过*p+1就可以得到元素a[1]。编译器在编译时,数组取下标的操作正是转换为指针偏移来完成
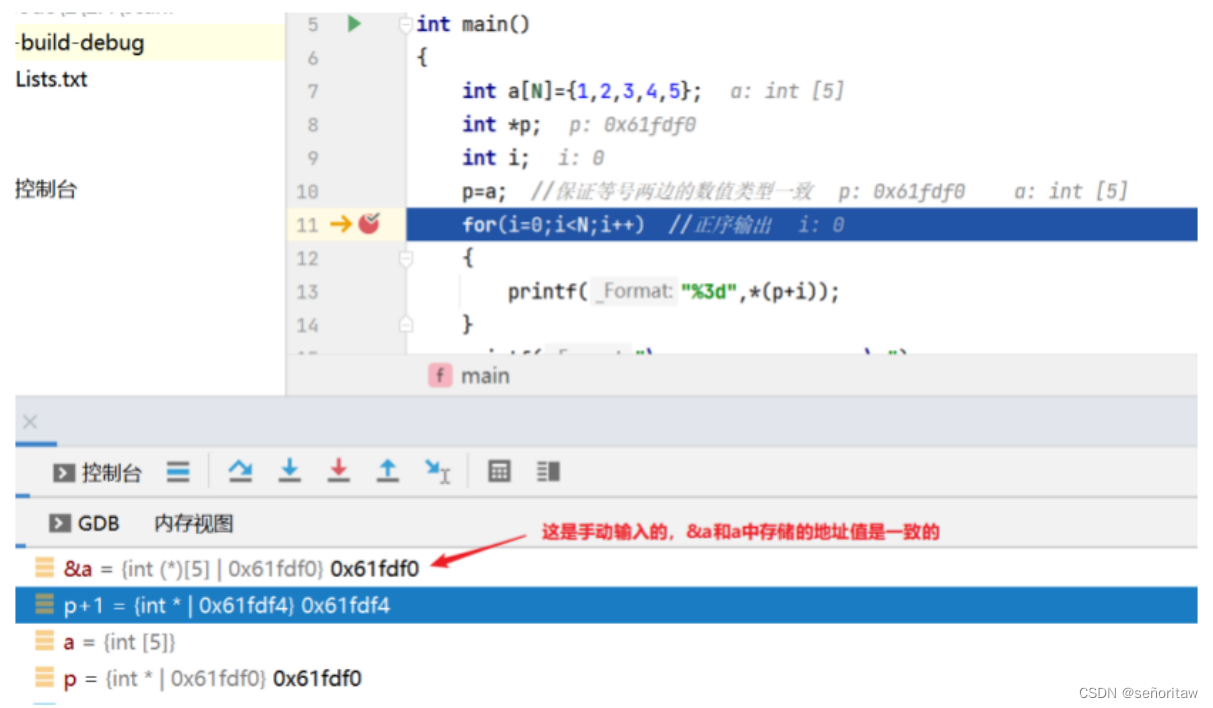
float *p; p的加减也是偏移4个字节
5.4.2 指针与一维数组
一维数组中存储的是数组的首地址,如下例中数组名c中存储的是一个起始地址,所以子函数change中其实传入了一个地址,定义一个指针变量时,指针变量的类型要和数组的数据类型保持一致,通过取值操作,可以将“h”改为“H”,这种方法称为指针法,获取数组元素时,也可以通过取下标的方式来获取数组元素并进行修改,这种方法称为下标法。
- #include <stdio.h>
- //指针与一维数组的的传递
- //数组名作为实参传递给子函数时,是弱化为指针的 (指针默认就是8个字节)
- //练习传递与偏移
-
- void change(char *d){
- *d='H';
- d[1]='E'; //*(d+1)='E'与其等价
- *(d+2)='L';
- *(d+3)='L';
- *(d+4)='O';
- }
- int main(){
- char c[10]="hello";
- change(c);
- puts(c);
- return 0;
- }
5.6指针与malloc动态内存申请,栈与堆的差异
5.6.1 指针与动态内存申请
C语言的数组长度固定,因为其定义的整型、浮点型、字符型变量、数组变量都在栈空间中,而栈空间的大小在编译时是确定的,如果使用的空间大小不确定,就要使用堆空间。
- #include <stdio.h>
- #include <stdlib.h> //malloc使用的头文件
- #include <string.h> //strcpy使用的头文件
- int main() {
- int size;//代表要申请多大字节的空间
- char *p;//void*类型的指针是不能偏移的,不能进行加减 ,因此不会定义无类型指针
- scanf("%d",&size); //输入要申请的空间大小
- //malloc返回的void*代表无类型指针
- p= (char*)malloc(size); //malloc返回的是对应空间起始地址 要强转malloc的类型与p一致
- strcpy(p,"malloc success");//strcpy传进去的也是指针类型的 所以可以直接copy
- puts(p);
- free(p);//释放申请的空间时,必须是最初malloc返回给我们的地址 即free的时候p不能变 不能填p+1这种 会异常
- printf("free success\n");
- return 0;
- }
注意:指针本身的大小和其指向空间的大小是两码事,指针本身大小只跟操作系统的位数有关,指向空间的大小是字节定义的,需要定义变量单独存储
5.6.2 栈空间与堆空间的差异
栈是计算机系统提供的数据结构,计算机会在底层对栈提供支持,分配专门的寄存器存放栈的地址,操作都有专门的指令执行,所以栈的效率比较高。
堆则是C/C++函数库提供的数据结构,它的机制很复杂,例如为了分配一块内存,库函数会按照一定的算法在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间就可能调用系统功能去增加程序数据段的内存空间,堆的效率要比栈低得多。
栈不能动态,所以要动态还是要使用堆,注意堆使用完要用free释放
- #include <stdio.h>
- #include <stdlib.h> //malloc使用的头文件
- #include <string.h> //strcpy使用的头文件
- //堆和栈的差异
- char* print_stack(){
- char c[100]="I am print_stack func"; //c中存了数组的起始地址
- char *p;
- p=c;
- puts(p);
- return p;
- }
- char* print_malloc(){
- char *p=(char*) malloc(100); //堆空间在整个进程中一直有效,不因为函数结束消亡
- strcpy(p,"I am print_stack func");
- puts(p);
- return p;
- }
- int main(){
- char *p;
- p=print_stack(); //调用函数执行完之后,操作系统就会直接释放掉这个栈空间
- puts(p);//p接到了print_stack()的指针 打印乱码或null
- p=print_malloc();
- puts(p);
- free(p);//只有free的时候,堆空间才会释放
- return 0;
- }
-
-
- /*
- int main() {
- int size;//代表要申请多大字节的空间
- char *p;//void*类型的指针是不能偏移的,不能进行加减 ,因此不会定义无类型指针
- scanf("%d",&size); //输入要申请的空间大小
- //malloc返回的void*代表无类型指针
- p= (char*)malloc(size); //malloc返回的是对应空间起始地址 要强转malloc的类型与p一致
- strcpy(p,"malloc success");//strcpy传进去的也是指针类型的 所以可以直接copy
- puts(p);
- free(p);//释放申请的空间时,必须是最初malloc返回给我们的地址 即free的时候p不能变 不能填p+1这种 会异常
- printf("free success\n");
- return 0;
- }
- */
六、函数
6.1 函数的声明与定义—嵌套调用
6.1.1 函数的声明与定义
函数间的调用关系是,由主函数调用其他函数,其他函数也可以互相调用,同一个函数可以背一个或多个函数调用任意次。
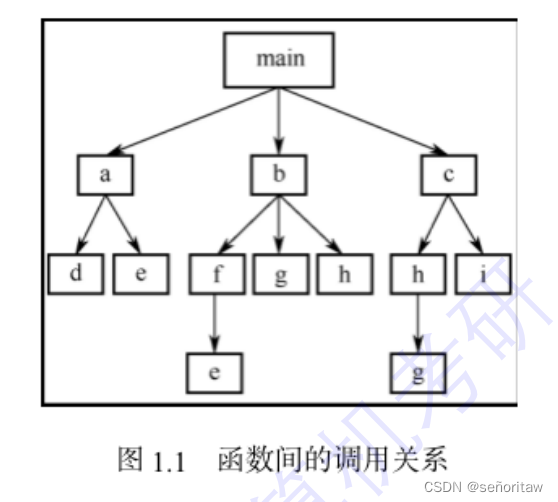
下例中有两个c文件, func.c是子函数printstar和print_message 的实现,也称定义; main.c是main函数, func.h中存放的是标准头文件的声明和 main函数中调用的两个子函数的声明,如果不在头文件中对使用的函数进行声明,那么在编译时会出现警告。
【例1】函数的嵌套调用
- func.c
- #include "func.h"
-
- int main() {
- int a=10;
- a=print_star(a);
- print_message();//调用print_message
- print_star(5);
- return 0;
- }
- func.h
-
- #ifndef FUNCTION_DEFINE_FUNC_H
- #define FUNCTION_DEFINE_FUNC_H
- #include <stdio.h> //都需要用到这个头文件 就都统一写在这里就行 <>表示从标准库中找头文件
- void print_message(); //print_message函数的声明
- int print_star(int i); //print_star函数声明。有形参,有返回值
- #endif //FUNCTION_DEFINE_FUNC_H
- main.c
- #include "func.h" //“”表示在当前路径下找头文件
-
- //print_star的定义
- int print_star(int i){
- printf("************************\n");
- printf("print_star %d\n",i);
- return i+3;
- }
-
- void print_message(){
- printf("how do you do\n");
- print_star(6); //调用print_star
- }
C语言的编译和执行有以下特点:
(1)一个C程序由一个或多个程序模块组成,每个程序模块作为一个源程序文件。对于较大的程序,通常将程序内容分别放在若干源文件中,再由若干源程序文件组成一个C程序。这样处理便于分别编写、分别编译,进而提高调试效率(复试有用).一个源程序文件可以为多个C程序共用。
(2)一个源程序文件由一个或多个函数及其他有关内容(如命令行、数据定义等)组成.一个源程序文件是一个编译单位,在程序编译时是以源程序文件为单位而不是以函数为单位进行编译的.main.c和 func.c分别单独编译,在链接成为可执行文件时, main中调用的函数printstar和 print_message才会通过链接去找到函数定义的位置.
(3)C程序的执行是从 main函数开始的,如果在main函数中调用其他函数,那么在调用后会返回到main函数中,在 main函数中结束整个程序的运行.
(4)所有函数都是平行的,即在定义函数时是分别进行的,并且是互相独立的。一个函数并不从属于另一函数,即函数不能嵌套定义,函数间可以互相调用,但不能调用main函数.main函数是由系统调用的,例1.1的 main 函数中调用print_message 函数,而 print_message函数中又调用printstar 函数.我们把这种调用称为嵌套调用.
6.1.2 函数的分类与调用
函数分为如下两种
(1)标准函数:即库函数,由系统提供的可以直接使用的,如 printf函数、scanf 函数.不同的C系统提供的库函数的数量和功能会有一些不同,但许多基本的函数是相同的。
(2)用户自己定义的函数:用以解决用户的专门需要.从函数的形式看,函数分为如下两类.
a.无参函数:一般用来执行指定的一组操作.调用无参函数时,主调函数不向被调用函数传递数据。
无参函数的定义形式如下:
- 类型标识符 函数名()
- {
- 声明部分
- 语句部分
- }
例1中, print_message就是无参函数。
b.有参函数:主调函数在调用被调用函数时,通过参数向被调用函数传递数据。
有参函数的定义形式如下:
- 类型标识符函数名(形式参数表列)
- {
- 声明部分
- 语句部分
- }
例1中,printstar就是有参函数,int i对应的i为形参,主调函数和被调用函数之间存在数据传递关系。
6.2 函数的递归调用
6.2.1 递归调用
函数自身调用自身的操作,称为递归函数,递归函数一定要有结束条件,否则会产生死循环!
【例1】n的阶乘的递归调用实现。
分析:f(n)=n*f(n-1); 如5!=5*4!
- #include <stdio.h>
-
- int f(int n){
- //一定要有结束条件
- if(1==n){
- return 1;
- }
- return n*f(n-1); //写公式
- }
-
- int main() {
- int n;
- scanf("%d",&n);
- printf("f(%d)=%d\n",n, f(n));
- return 0;
- }
【例2】假如有n个台阶,一次只能上1个台阶或2个台阶,请问走到第n个台阶有几种走法?
- #include <stdio.h>
- //上台阶 ,到第n个台阶 一次只能上一个或两个,有多少种走法
- //分析 step(3)=step(2)+step(1)
- // 3 = 2 + 1
- int step(int n){
- if(1==n||2==n){//当台阶是1个或2个时,递归结束,一个台阶只有一种走法,2个台阶只有两种走法
- return n;
- }
- return step(n-1)+ step(n-2);
- }
-
- int main(){
- int n;
- scanf("%d",&n);
- printf("step(%d)=%d",n, step(n));
- return 0;
- }
递归的核心:找公式,写递归结束条件。
6.3 局部变量与全局变量
6.3.1 全局变量解析-形参-实参解析
在不同的函数之间传递数据时,可以使用的方法如下:
(1)参数:通过形式参数和实际参数。
(2)返回值:用return 语句返回计算结果。
(3)全局变量:外部变量。
- #include <stdio.h>
-
- int i=10;//i是一个全局变量,不建议使用 局部变量全局变量重名不会报错 容易搞错
- void print(int a)//形参看成一个局部变量
- {
- printf("I am print i=%d\n",i);
- }
-
- int main() {
- {
- int j=5;
- }//局部变量只在离自己最近的大括号内有效
- int i=5;
- printf("main i=%d\n",i);
- for(int k=0;k<-1;)
- {
-
- }
- // printf("k=%d\n",k);for循环括号内定义的变量,循环体外不可用
- print(3);
- return 0;
- }
全局变量存储,如下图所示,全局变量i存储在数据段,所以main函数和 print函数都是可见的。全局变量不会因为某个函数执行结束而消失,在整个进程的执行过程中始终有效,因此工作中应尽量避免使用全局变量!
在函数内定义的变量都称为局部变量,局部变量存储在自己的函数对应的栈空间内,函数执行结束后,函数内的局部变量所分配的空间将会得到释放。如果局部变量与全局变量重名,那么将采取就近原则,即实际获取和修改的值是局部变量的值.

形参与实参的说明如下:
(1)定义函数中指定的形参,如果没有函数调用,那并不占用内存中的存储单元。只有发生函数调用时,函数print 中的形参才被分配内存单元。在调用结束后,形参所占的内存单元也会被释放。
(2)实参可以是常量、变量或表达式,但要求它们有确定的值,例如, print(i+3)在调用时将实参的值i+3赋给形参。print函数可以有两个形参,如 print( inta,int b)
(3)在被定义的函数中,必须指定形参的类型.如果实参列表中包含多个实参,那么各参数间用逗号隔开。实参与形参的个数应相等,类型应匹配,且实参与形参应按顺序对应,一一传递数据。
(4)实参与形参的类型应相同或赋值应兼容。
(5)实参向形参的数据传递是单向“值传递”,只能由实参传给形参,而不能由形参传回给实参.在调用函数时,给形参分配存储单元,并将实参对应的值传递给形参,调用结束后,形参单元被释放,实参单元仍保留并维持原值.
(6)形参相当于局部变量,因此不能再定义局部变量与形参同名,否则会造成编译不通。
6.3.2 外部变量
函数之外定义的变量称为外部变量.外部变量可以为本文件中的其他函数共用,它的有效范围是从定义变量的位置开始到本源文件结束,所以也称全程变量。
关于全局变量需要注意如下几点:
(1)全局变量在程序的全部执行过程中都占用存储单元,而不是仅在需要时才开辟单元。
(2)使用全局变量过多会降低程序的清晰性。在各个函数执行时都可能改变外部变量的值,程序容易出错,因此要有限制地使用全局变量(初试时尽量不用)。
(3)因为函数在执行时依赖于其所在的外部变量,如果将一个函数移到另一个文件中,那么还要将有关的外部变量及其值一起移过去。然而,如果该外部变量与其他文件的变量同名,那么
就会出现问题,即会降低程序的可靠性和通用性.C语言一般要求把程序中的函数做成一个封闭体,除可以通过“实参→形参”的渠道与外界发生联系外,没有其他渠道.
七、结构体与C++引用
7.1 结构体的定义、初始化、结构体数组
C 语言提供结构体来管理不同类型的数据组合。通过将不同类型的数据组合成一个整体,方便引用
例如,一名学生有学号、姓 名、性别、年龄、地址等属性,如果针对学生的学号、姓名、年龄等都单独定义一个变量,那么在有多名学生时,变量就难以分清。就可通过结构体来管理
声明一个结构体类型的一般形式为
struct 结构体名 {成员表列};- struct student
- {
- int num;char name[20];char sex;
- int age;float score;char addr[30];
- };
先声明结构体类型,再定义变量名。
struct student student1,student2;【例1】结构体的scanf读取和输出
- #include <stdio.h>
-
- struct student{
- int num;
- char name[20];
- char sex;
- int age;
- float score;
- char addr[30];
- };//结构体类型声明,注意最后一定要加分号
-
- int main() {
- struct student s={1001,"lele",'M',20,85.4,"Shenzhen"};
- struct student sarr[3];//定义一个结构体数组变量
- int i;
- //结构体输出必须单独去访问内部的每个成员
- s.num=1003; //单独赋值 输出的值会改变
- printf("%d %s %c %d %f %s\n",s.num,s.name,s.sex,s.age,s.score,s.addr);
- printf("--------------------------------------\n");
- // scanf("%d%s %c%d%f%s",&s.num,s.name,&s.sex,&s.age,&s.score,s.addr);
- for(i=0;i<3;i++)
- {
- scanf("%d%s %c%d%f%s",&sarr[i].num,sarr[i].name,&sarr[i].sex,&sarr[i].age,&sarr[i].score,sarr[i].addr);
- }
- for(i=0;i<3;i++)//结构体数组的输出
- {
- printf("%d %s %c %d %f %s\n",sarr[i].num,sarr[i].name,sarr[i].sex,sarr[i].age,sarr[i].score,sarr[i].addr);
- }
-
- return 0;
- }
结构体类型声明要放在 main 函数之前,这样 main 函数中才可以使用这个结构体,工作中往往把结构体声明放在头文件中。
注意,结构体类型声明最后一定要加分号,否则会编译不通。 定义结构体变量时,使用 struct student 来定义,不能只有 struct 或 student,否则也会编译不通。
结构体的初始化只能在一开始定义,如果 struct student s={1001,"lele",'M',20,85.4,"Shenzhen"}已经执行,即 struct student s 已经定义,就不能再执 行 s={1001,"lele",'M',20,85.4,"Shenzhen"}
整型数据(%d)、浮点型数据(%f)、字符串型数据(%s)都会忽略空格,但字符型数据(%c)不会忽略空格,所以读取字符型数据就要在待读取的字符数据与其他数据之间加入空格。
7.2 结构体对齐
结构体本身的对齐规则,考研初试只需要记住,结构体的大小必须是其最大成员的整数倍
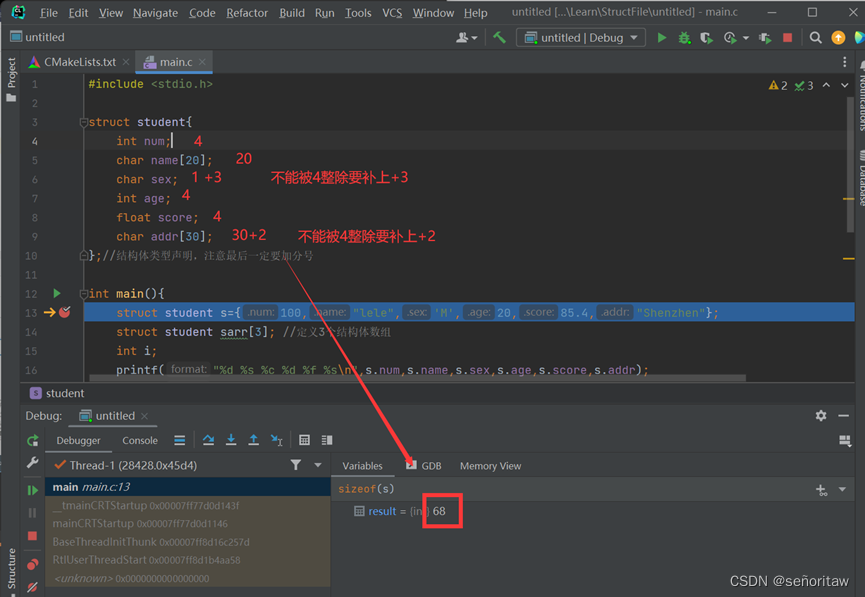
结构体对齐,是为了cpu高效的去取内存中上的数据
- #include <stdio.h>
-
- struct student_type1{
- double score;//double是一种浮点类型,8个字节,浮点分为float和double,float占4个字节,记住有这两种即可
- short age;//short 是整型,占2个字节
- };
-
- struct student_type2{
- double score;
- int height;//如果两个小存储之和是小于最大长度8,那么它们就结合在一起
- short age;
- };
-
- struct student_type3{
- int height; //4个字节
- char sex;
- short age;
- };
- //结构体对齐
- int main() {
- struct student_type1 s1;
- struct student_type2 s2={1,2,3};
- struct student_type3 s3;
- printf("s1 size=%d\n",sizeof(s1));
- printf("s2 size=%d\n",sizeof(s2));
- printf("s3 size=%d\n",sizeof(s3));
- return 0;
- }
注意:两个小存储挨在一起且和小于最大长度,那两个小存储就结合在一起看
s1 size=16 //double8 + short 8
s2 size=16 //double>int+short 所以长度为 double8 + (int+short)8
s3 size=8 //int>char+short 所以长度为 int 4 + (char+short)4
7.3 结构体指针与typedef的使用
7.3.1 结构体指针
一个结构体变量的指针就是该变量所占据的内存段的起始地址。可以设置一个指针变量,用它指向一个结构体变量,此时该指针变量的值是结构体变量的起始地址。指针变量也可以用来指向结构体数组中的元素,从而能够通过结构体指针快速访问结构体内的每个成员。
- #include <stdio.h>
-
- struct student{
- int num;
- char name[20];
- char sex;
- };
- //结构体指针的练习
- int main() {
- struct student s={1001,"wangle",'M'};
- struct student sarr[3]={1001,"lilei",'M',1005,"zhangsan",'M',1007,"lili",'F'};
- struct student *p;//定义了一个结构体指针变量
- p=&s;
- //*p要加括号去访问元素是因为.的优先级比*高,如果不加括号就会报错
- printf("%d %s %c\n",(*p).num,(*p).name,(*p).sex);//方式1访问通过指针对象去访问成员
- printf("%d %s %c\n",p->num,p->name,p->sex);//方式2访问通过结构体指针去访问成员,用这种
- p=sarr;
- printf("%d %s %c\n",(*p).num,(*p).name,(*p).sex);//方式1访问通过指针对象去访问成员
- printf("%d %s %c\n",p->num,p->name,p->sex);//方式2访问通过结构体指针去访问成员,用这种
- printf("------------------------------\n");
- p=p+1;
- printf("%d %s %c\n",(*p).num,(*p).name,(*p).sex);//方式1访问通过指针对象去访问成员
- printf("%d %s %c\n",p->num,p->name,p->sex);//方式2访问通过结构体指针去访问成员,用这种
- return 0;
- }
1001 wangle M
1001 wangle M
1002 lilei M
1002 lilei M
-------------------------
1003 zhangsan M
1003 zhangsan M
由上面例子可以看到,p 就是一个结构体指针,可以对结构体 s 取地址并赋给 p,这样借助成员选择操作符,就可以通过 p 访问结构体的每个成员,然后进行打印。
由于数组名中存储的是数据的首地址,所以可以将 sarr 赋给 p,这样也可以访问对应的成员。
使用(*p).num 访问成员要加括号是因为“.”成员选择的优先级高于“*”(即 取值)运算符,所以必须加括号,通过*p 得到 sarr[0],然后获取对应的成员。
7.3.2 结构体的使用
定义结构体变量时使用的语句是 struct student s,这样定义结构体变量有些麻烦,每次都需要写 struct student。可以选择使用 typedef 声明新的类型名来代替已有的类型名
- #include <stdio.h>
-
- typedef struct student{
- int num;
- char name[20];
- char sex;
- }stu,*pstu; //pstu等价于 struct student*
- //typedef的使用,typedef 起别名
-
- typedef int INGETER; //在特定的地方使用 给int起别名
- int main() {
- //stu s ={0};//结构体变量初始化为0 stu 等价于struct student
- stu s={1001,"wangle",'M'};
- stu *p=&s;//定义了一个结构体指针
- pstu p1=&s;//定义了一个结构体指针
- INGETER num=10;
- printf("num=%d,p->num=%d\n",num,p->num);
- return 0;
- }
7.4 C++的引用
7.4.1 C++的引用讲解
对于 C++,建源文件时,名字需要叫 main.cpp,以 cpp 后缀结尾
使用了引用后,在子函数内的 操作和函数外操作手法一致,这样编程效率较高
【例1.1】在子函数内修改主函数的普通变量的值(C++)
- #include <stdio.h>
- //C++引用的讲解
-
- //在子函数中要修改主函数中变量的值,就用引用,不需要修改,就不用
- void modify_num(int &b){//形参中写&,要称为引用
- b=b+1;
- }
-
- //在子函数内修改主函数的普通变量的值
- int main() {
- int a=10;
- modify_num(a);
- printf("after modify_num a=%d\n",a);
- return 0;
- }
上面的代码如果改为纯 C,代码如下:
【例 1.2】在子函数内修改主函数的普通变量(纯 C 代码)
- #include <stdio.h>
- void modify_num(int *b)
- {
- *b=*b+1;
- }
-
- int main()
- {
- int a=10;
- modify_num(&a);
- printf("after modify_num a=%d\n",a);
- return 0;
- }
【例 1.3】子函数内修改主函数的一级指针变量(这是是重要的!)
- #include <stdio.h>
- void modify_pointer(int *&p,int *q){//引用必须和变量名紧邻
- p=q;
- }
- //子函数内修改主函数的一级指针变量
- int main() {
- int *p=NULL;
- int i=10;
- int *q=&i;
- modify_pointer(p,q);
- printf("after modify_pointer *p=%d\n",*p);
- return 0;//进程已结束,退出代码为 -1073741819,不为0,那么代码进程异常结束
- }
上面的代码如果改为纯 C,就需要使用到二级指针
- #include <stdio.h>
- void modify_pointer(int **p,int *q)//相对于 C++这里是 int **p;
- {
- *p=q;//这里的写法和例 1.2 中的是非常类似的
- }
- int main()
- {
- int *p=NULL;
- int i=10;
- int *q=&i;
- modify_pointer(&p,q);//相对于 C++这里是&p
- printf("after modify_pointer *p=%d\n",*p);
- return 0;
- }
7.4.2 C++的布尔类型
布尔类型在 C 语言没有,C++有 true 和 false,值是1和0
【例 2.1】 布尔类型也是有值的
- #include <stdio.h>
- //设置布尔值的好处是提升了代码的可阅读性
- int main()
- {
- bool a=true;
- bool b= false;
- printf("a=%d,b=%d\n", a,b);
- return 0;
- }
a=1,b=0

