
热门标签
热门文章
- 1Dubbo3.0|阿里巴巴服务框架三位一体的选择与实践_弹内业务
- 2mysql 服务器#1045 无法登录_登录phpmyadmin提示: #1045 无法登录 MySQL 服务器
- 3为Raspbian OS安装OpenVINO工具包(笔记)_openvino toolkit for raspbian安装包
- 4Windows 环境下的 Socket 编程 3 - 基于 TCP 的服务器/客户端_windows socket tcp
- 5如何使用视频号下载提取器提取视频,推荐2种方法使用!
- 6Centos 7源码安装Python3_centos python3.12
- 7计算机操作系统的虚拟存储器_操作系统中的虚拟存储器
- 8京东业务增长10倍背后的敏捷开发秘籍【案例+分析】
- 9zabbix 监控案例之监控Linux TCP连接状态_zabbix 监控tcp端口
- 10【Android】RecyclerView的使用方法(可以横向滚动)_android recycleview横向滚动
当前位置: article > 正文
【多元统计分析及R语言建模】附代码及word版表格,针对教材P212页的表格7-5,用系统聚类和快速聚类做聚类分析。_多元统计分析及r语言建模论文
作者:笔触狂放9 | 2024-02-22 01:26:24
赞
踩
多元统计分析及r语言建模论文
目的:1996年全国31个省、市、自治区城镇居民消费数据采用系统聚类及快速聚类做聚类分析
1.数据概况
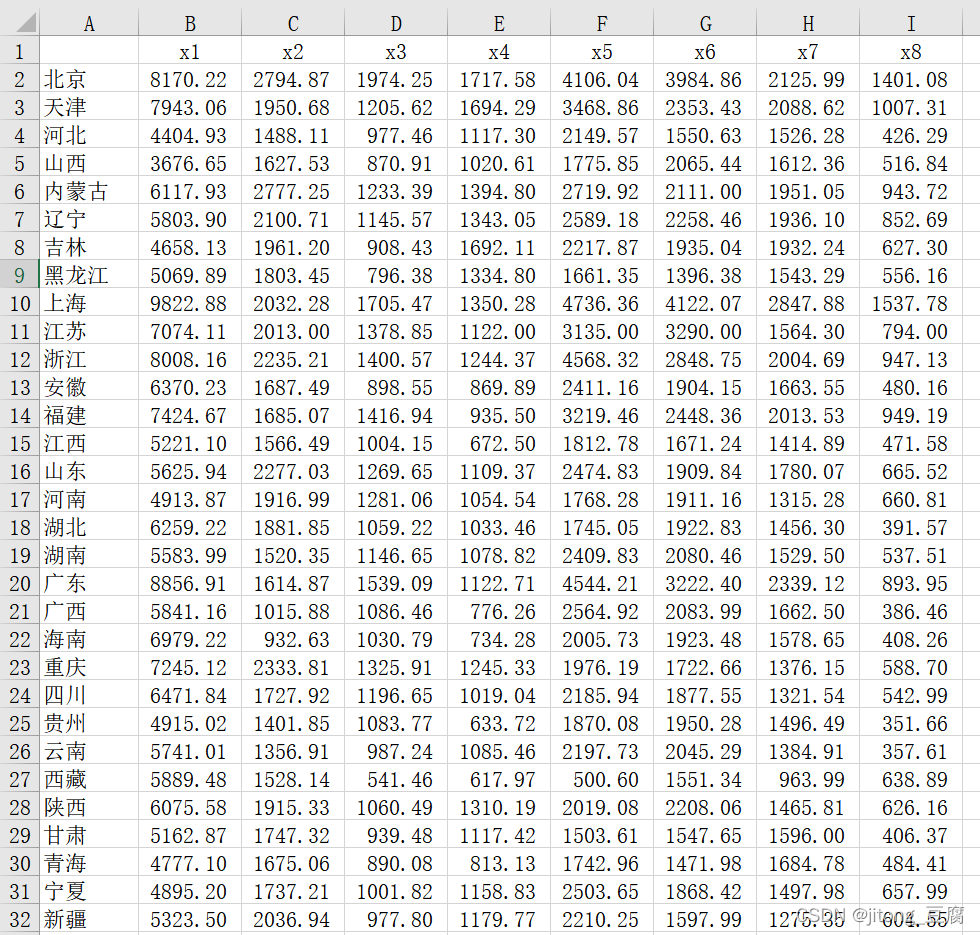
2.代码及运行结果
2.1 系统聚类法
#导包
library(xlsx)
#读取数据
data = read.xlsx("C:\\Users\\6\\Desktop\\R语言\\多元统计分析及R语言建模作业\\1996年全国31个省、市、自治区城镇居民消费数据.xlsx",'Sheet1',row.names=T)
#了解数据结构
plot(data,gap=0)
- 1
- 2
- 3
- 4
- 5
- 6
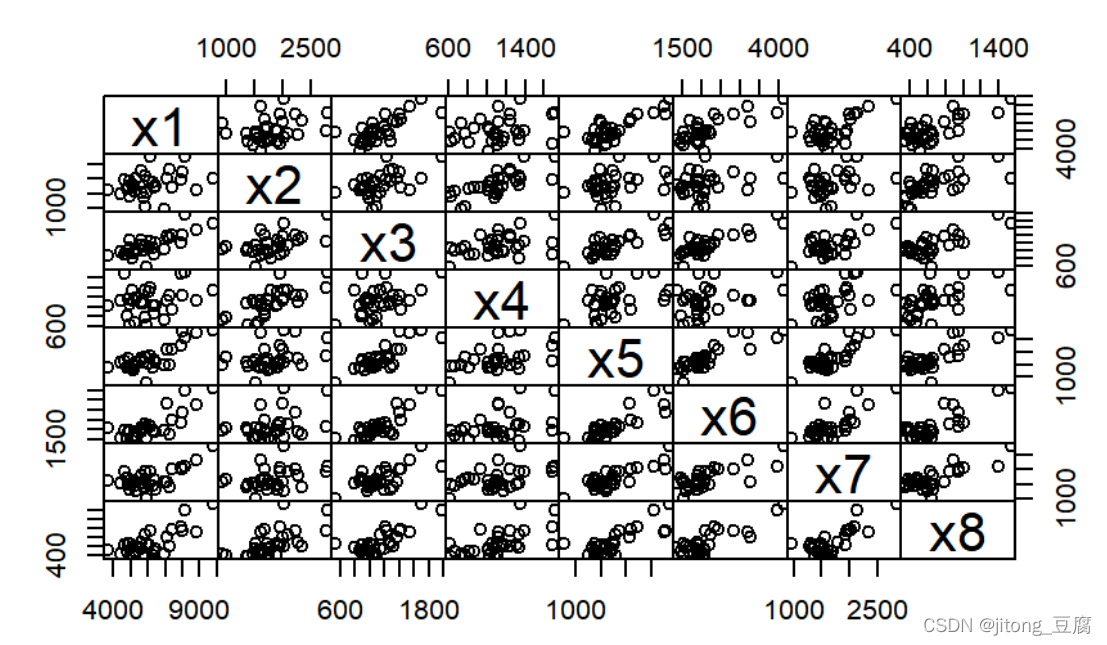
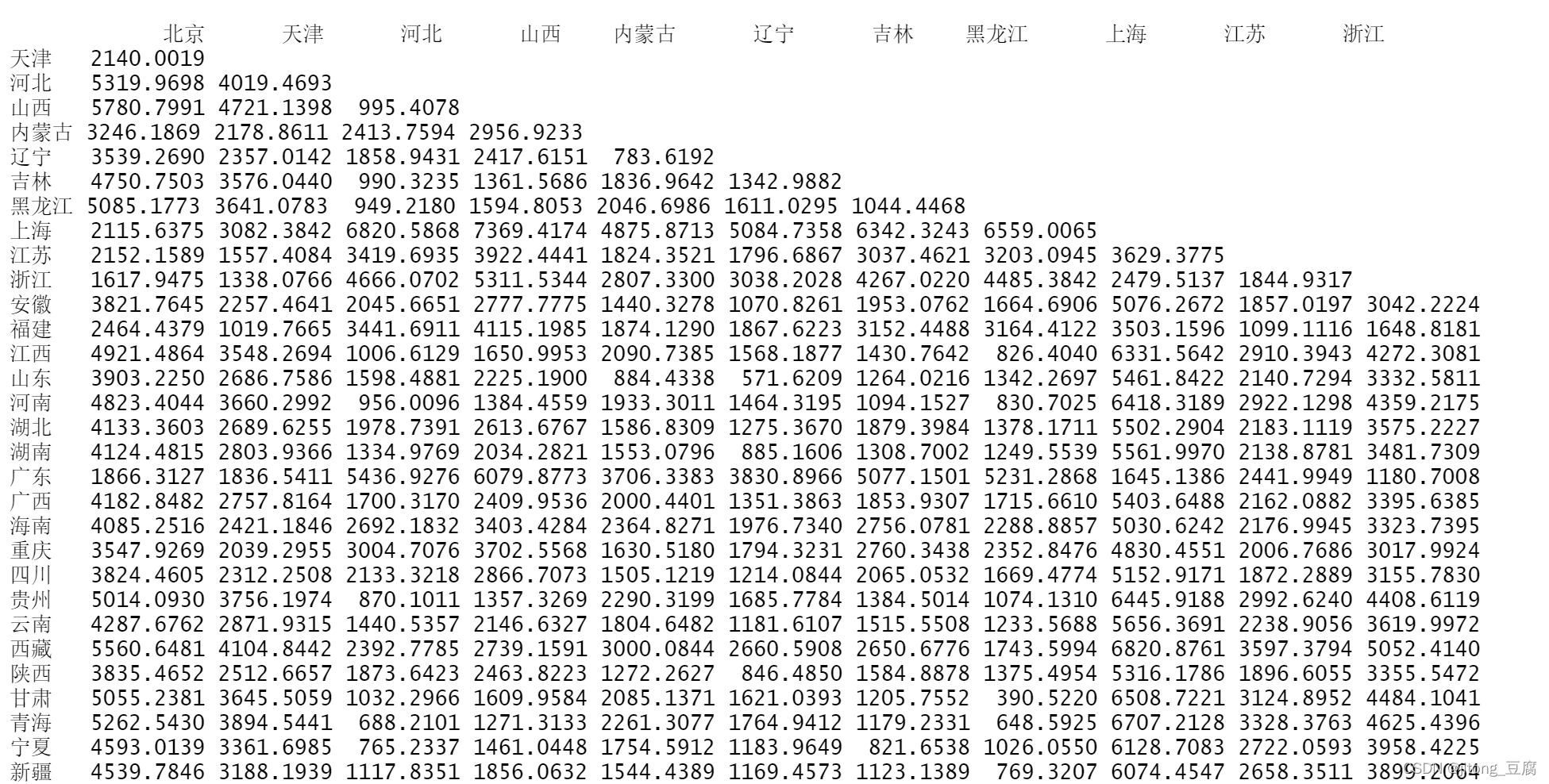
#计算矩阵行向量之前的距离
D=dist(data);D #默认为euclidean距离
- 1
- 2
#对每个聚类模型进行测试
#图片统一放在代码最下方,可根据图片里的表示判断是哪个距离法
plot(hclust(D,"single")); #最短距离法
plot(hclust(D,'complete')) #最长距离法
plot(hclust(D,'median')) #中间距离法
plot(hclust(D,'average')) #类平均法
plot(hclust(D,'centroid')) #重心法
plot(hclust(D,'ward.D')) #Ward.D法
plot(hclust(D,'ward.D2')) #Ward.D2法
H = hclust(D,'ward.D2');H #选择Ward.D2法进行进一步分类
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
最短距离法:
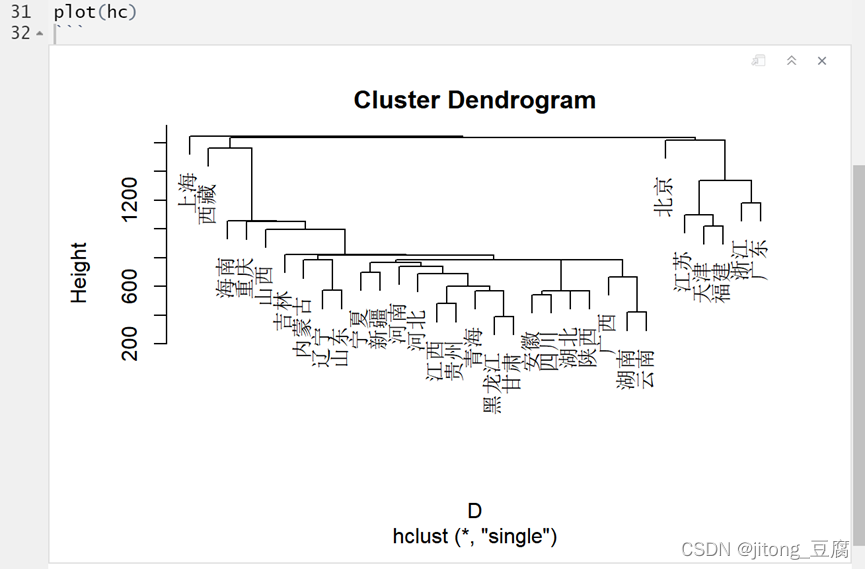
最长距离法
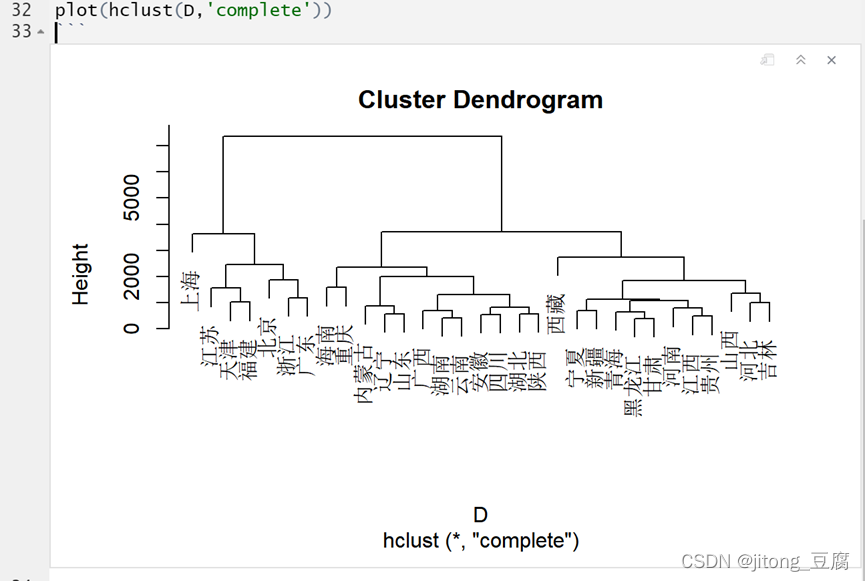
中间距离法:
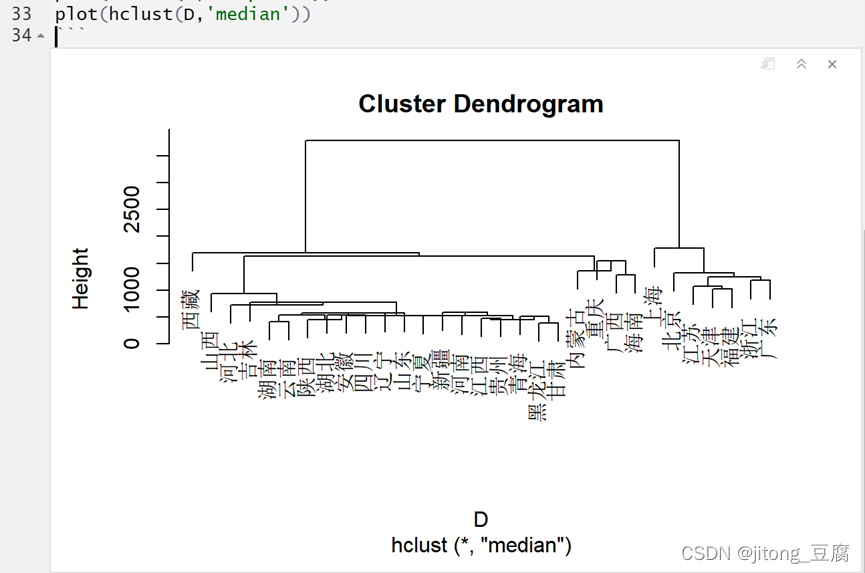
类平均法:
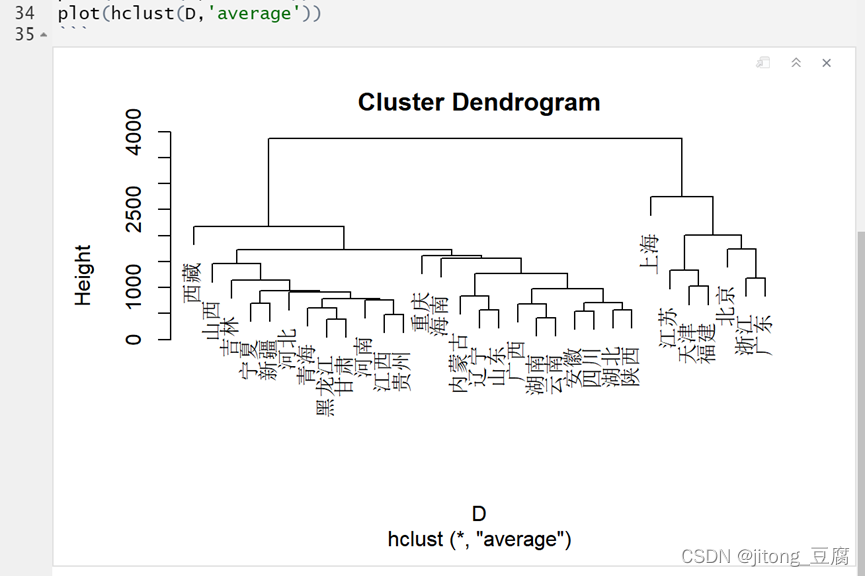
重心法:
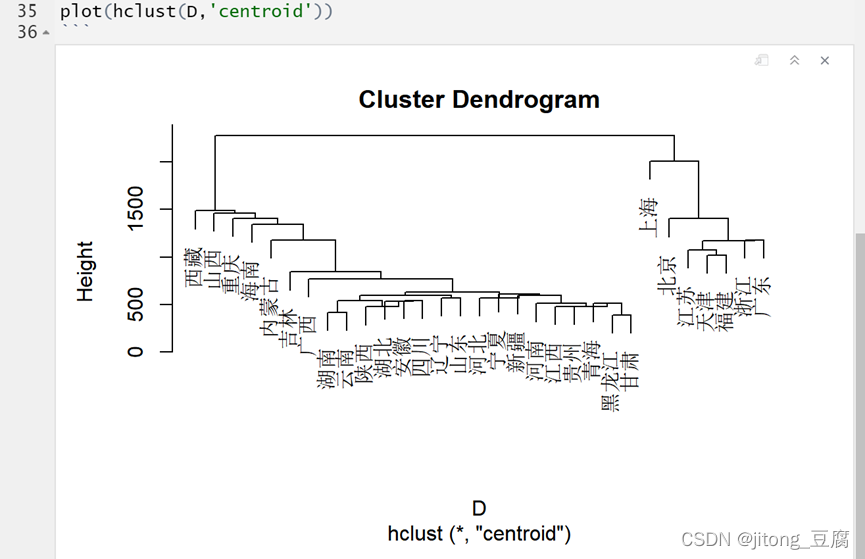
Ward.D法
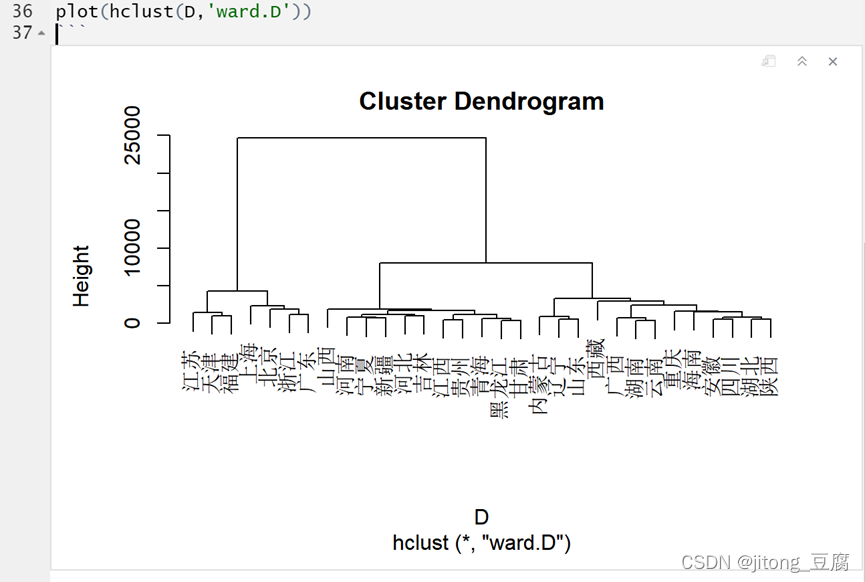
Ward.D2法
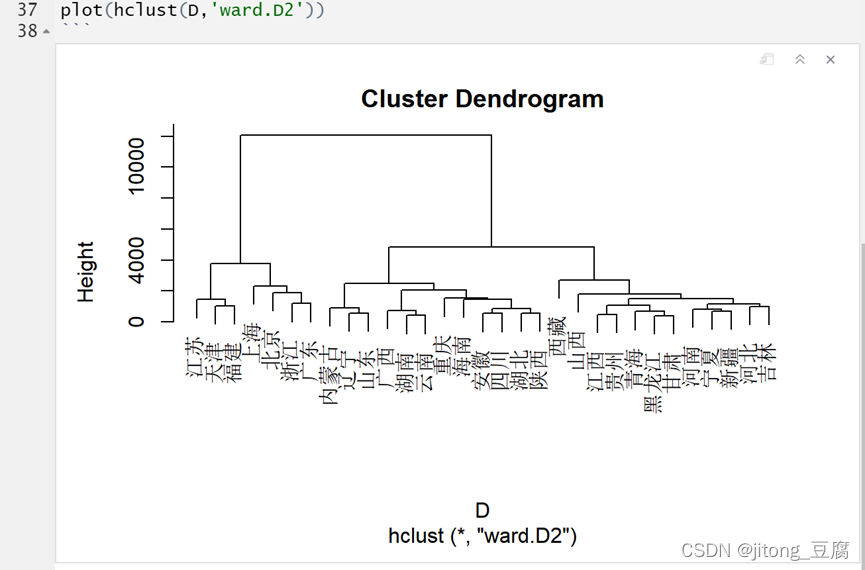
综合考虑以上的分析结果,从全国各省、市、自治区的消费数据来看,使用Ward.D2方法聚类的效果较好,且分为四类较为合适。
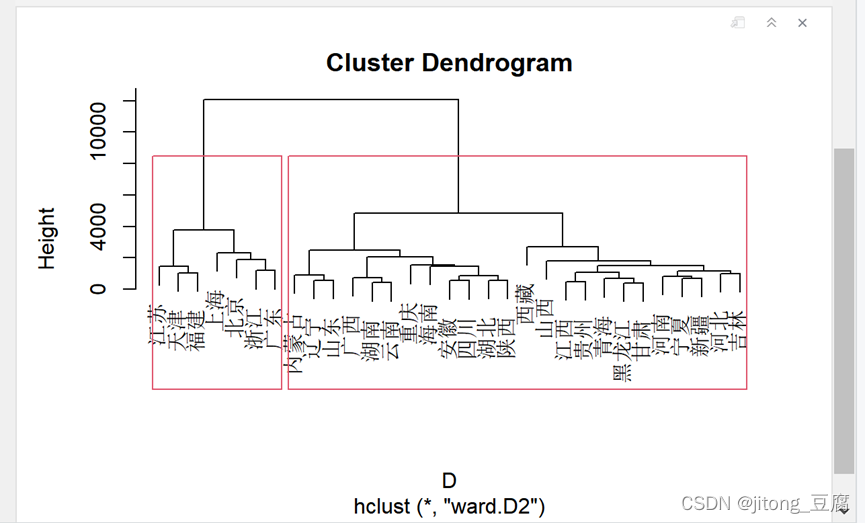
plot(H);rect.hclust(H,2)
cutree(H,2) # 分两类
plot(H);rect.hclust(H,3)
cutree(H,3) #分三类
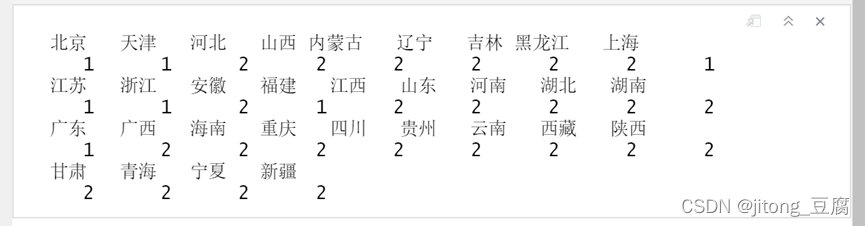
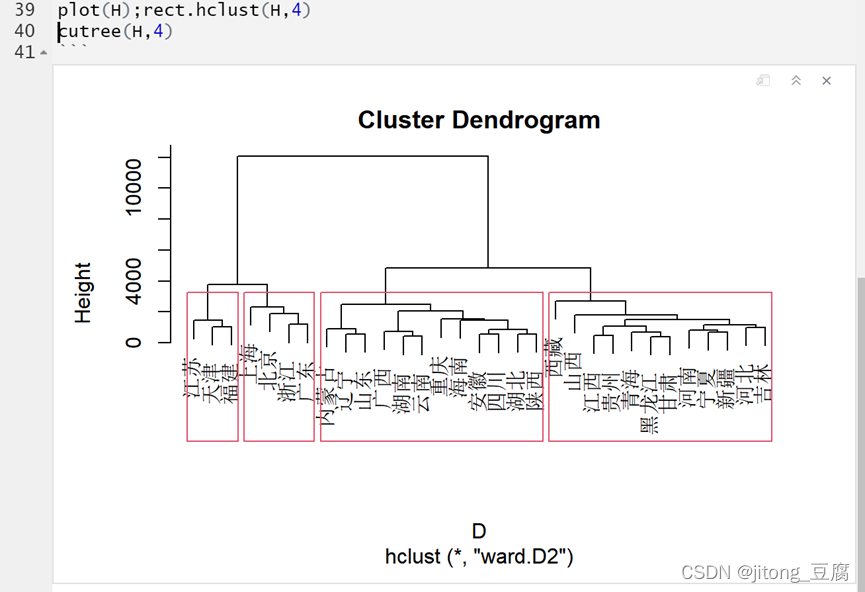
plot(H);rect.hclust(H,4)
cutree(H,4) #分四类
- 1
- 2
- 3
- 4
- 5
- 6
结果如下:
两类:
三类:
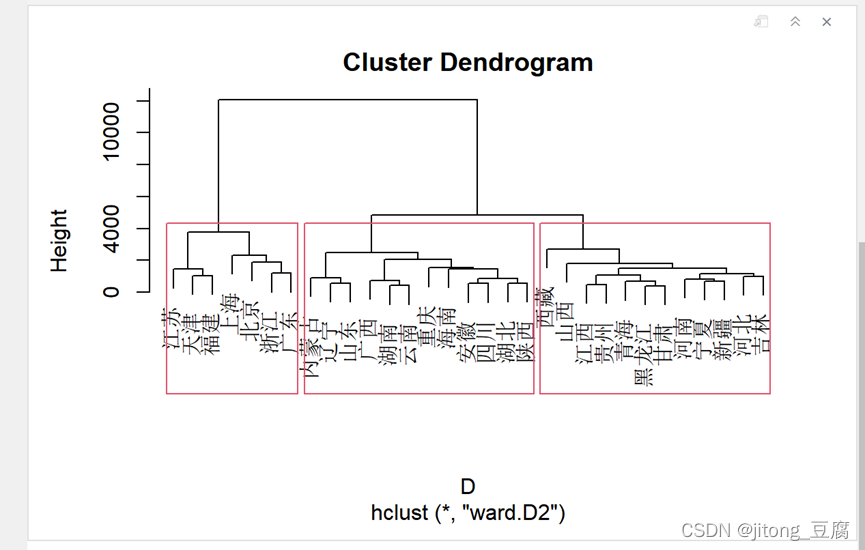
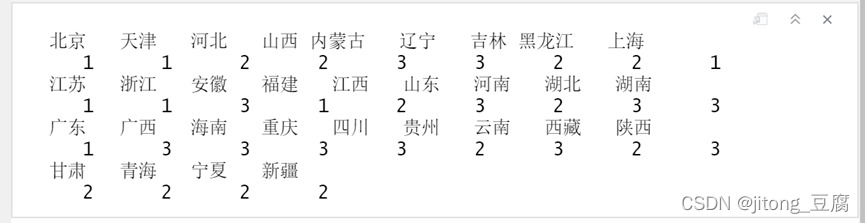
四类:

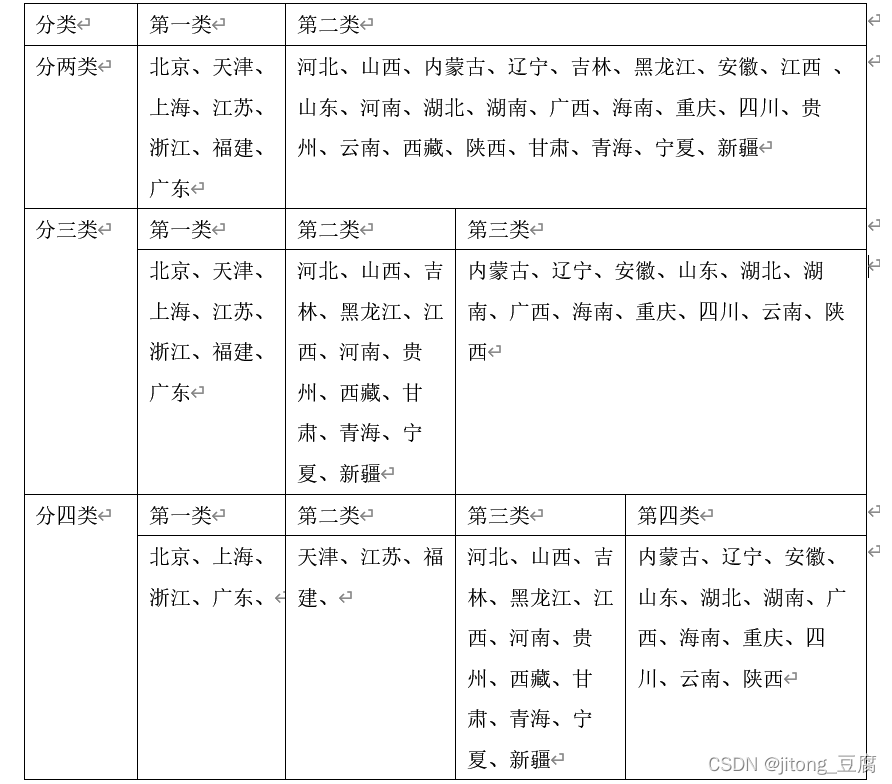
按类整理聚类图结果:
这个图画的画比较难画,word版已上传至网盘,可复制。若有问题可在评论区提出。
2.2 快速聚类法
X = rbind(data)
km = kmeans(X,4) #使用快速聚类发分四类 (同样可以分为2,3,4类,参数自调)
kc = km$cluster
km #km中存有快速聚类结果
- 1
- 2
- 3
- 4
最终结果如下:
两类:
提示:在R gui中,城市及分类的情况(1,2,3,4)是错位的,要看清哦!
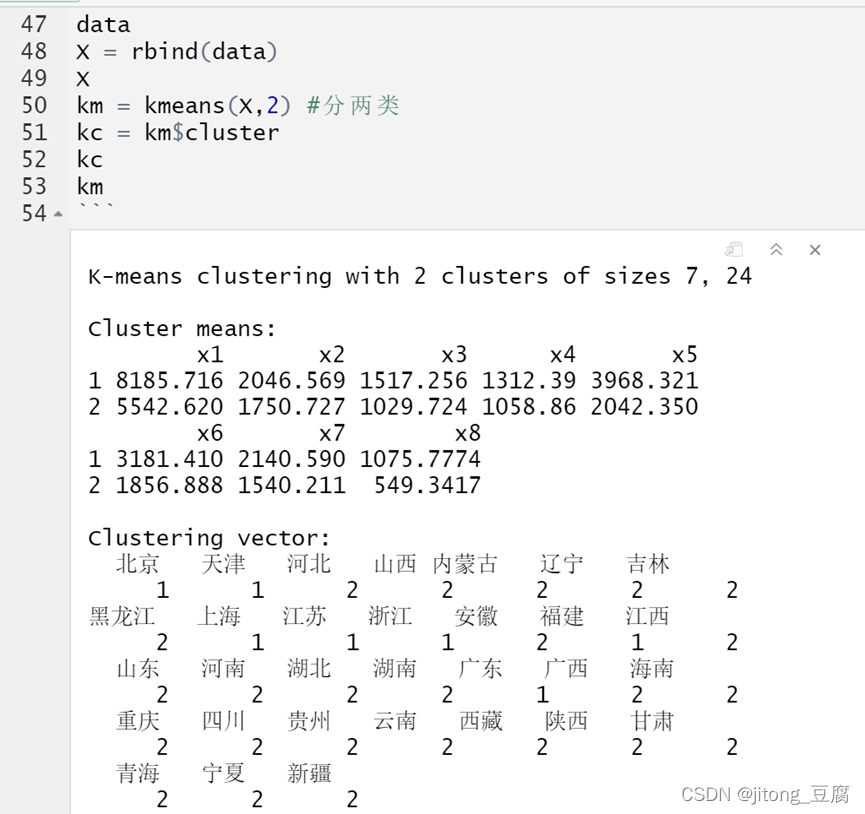
三类:
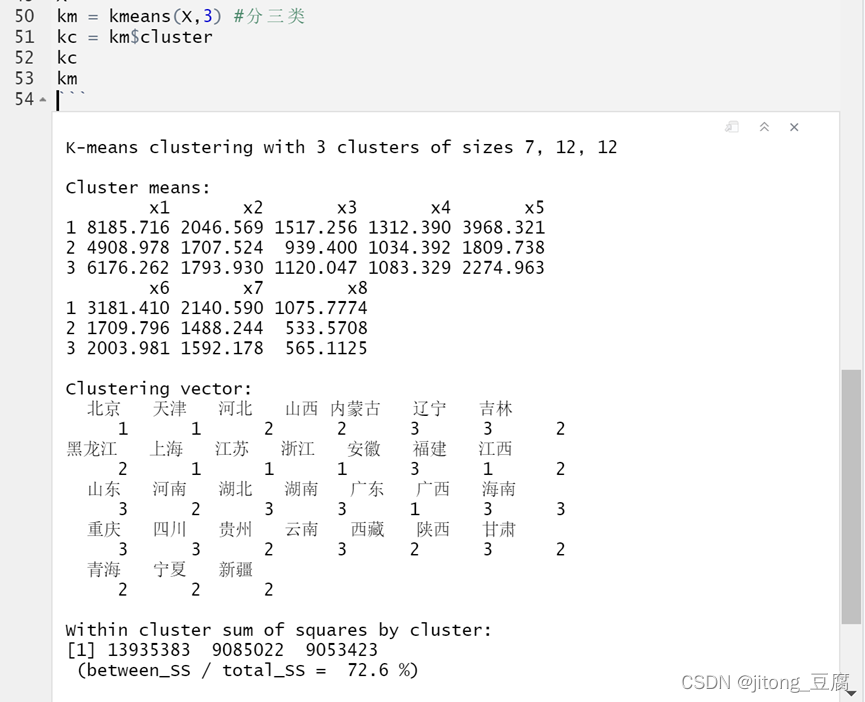
四类:
整理的效果图:
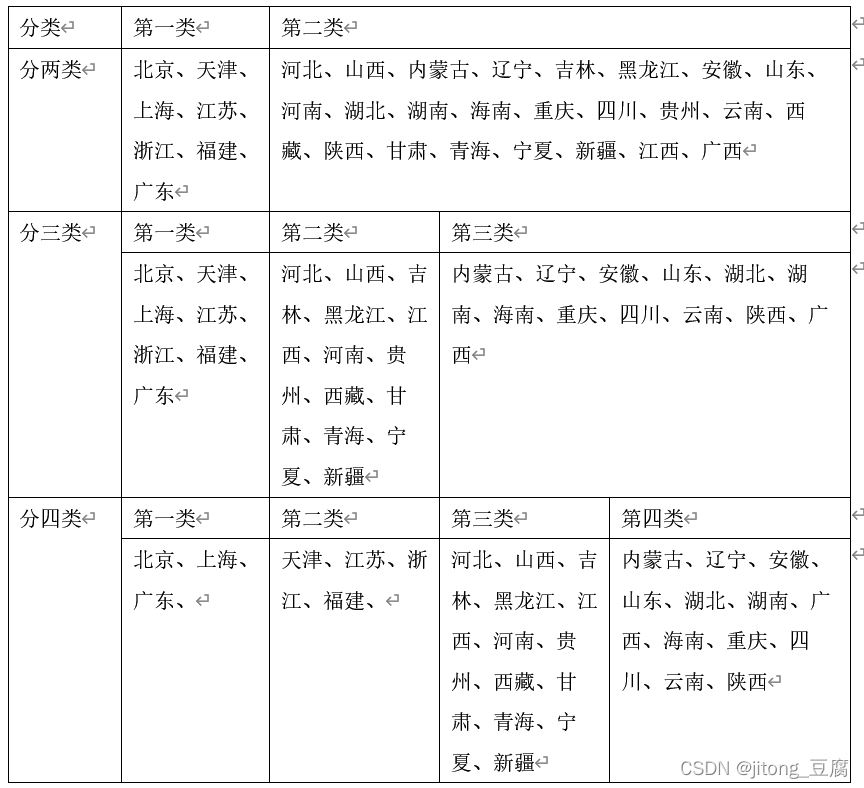
结论:对比系统聚类法及快速聚类法,两种聚类法在聚类方面基本上差不多,只有在分四类时,浙江出现了微小的差距,在分两类分三类时,情况是一致的,因此在选择聚类的方法时可以根据实际情况选择较好的模型。
3.链接
数据及代码连接:链接:https://pan.baidu.com/s/1n0nrF3txGosB00gGlfMw5w
提取码:8888
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/127909

