
- 1第7章 文件和数据格式化_csv写高精度数据
- 2GEE踩坑Earth Engine client library loading failed
- 3QT-通用的软件界面框架,好看且实用_qt ui框架
- 4unity 获取 挂载有Content Size Fitter 组件的UI物体的 宽 和 高_unity content size fitter 高度
- 5lazyload.js详解_lazyloud.jscsdn
- 65种延迟加载图像的方法以帮助你提升网站性能与用户体验
- 7微信小程序--长按事件bindlongtap与点击事件bindtap的执行顺序_小程序 长按排序
- 8max函数(C++)_c++ max函数
- 9Unity urp2d ShaderGraph 实现一个黑白转彩色的场景渐变效果 设计思路_unity渐变shader
- 10Unity天空盒的使用_unity 城市夜景 天空盒
python之LSTM预测模型_international-airline-passengers.csv
赞
踩
如果遇到这个错误:ValueError: Error when checking model input: the list of Numpy arrays that you are passing to your model is not the size the model expected. Expected to see 1 array(s), but instead got the following list of 25000 arrays: [array([[ 11],...........]]是因为数据大小或者长度等超出了限制而导致的。所以用limit_imdb_datalength(x_train)来限制数据中的数值大小。
1、数据标准化:
如果使用sigmoid或者tanh作为激活函数的时候,将数据缩放到一个指定范围,避免输入数据的尺度敏感。
MinMaxScaler将数据缩放到一个指定的最大和最小值(通常是1-0)之间。作用:对方差非常小的属性可以增强其稳定性;维持稀疏矩阵中为0的条目。
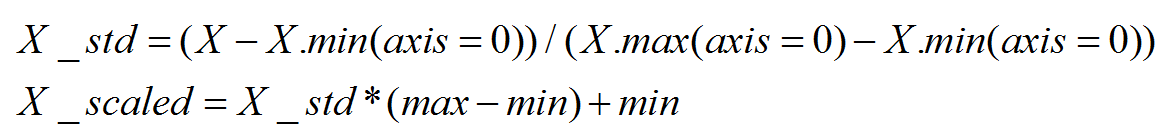
- from sklearn.preprocessing import MinMaxScaler
- data = [[-1, 2], [-0.5, 6], [0, 10], [1, 18]]
- scaler=MinMaxScaler()
- # scaler.fit(data)
- # data=scaler.transform(data)
- data=scaler.fit_transform(data)#等于fit加transform,标准化数据
- data=scaler.inverse_transform(data)#与fit_transform相反,还原标准化后的数据
- # https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.MinMaxScaler.html
正则化,将每个样本缩放到单位范数(每个样本的范数为1), 如果后面要使用如二次型(点积)或者其它核方法计算两个样本之间的相似性这个方法会很有用。normalize,L1范数表示向量中所有元素的绝对值和,L2范数表示欧氏距离,p范数表示向量元素绝对值的p次方和的1/p次幂。

- from sklearn.preprocessing import normalize
- #L1范数表示向量中所有元素的绝对值和,L2范数表示欧氏距离
- x=normalize(data,norm='l1')#norm='l1', 'l2', or 'max', optional ('l2' by default)
- # print(x)
- # https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.normalize.html#sklearn.preprocessing.normalize
2、LSTM模型数据导入
IMDB影评数据导入,可以直接从Keras.datasets中进行导入,imdb.load_data()进行在线下载导入(下载好的也可以导入),也可以自己编写数据导入函数进行数据导入,下面包含两个函数,一个是导入函数,一个是对导入的IMDB数据进行截取。
- def load_imdb_data(path='imdb.npz',choosedata='train',num_words=None):
- """
- imdb.npz数据提取
- :param path: imdb数据地址
- :param choosedata: {'all','train','test','trainandtest'}
- :param num_words:数据值上限
- :return:x,y:数据标签
- """
- with np.load(path) as f:#提取数据
- x_train, y_train = f['x_train'], f['y_train']
- x_test, y_test = f['x_test'], f['y_test']
- #测试数据提取
- indices = np.arange(len(x_train))#数据长度
- np.random.shuffle(indices)#随机打乱顺序
- x_train = x_train[indices]#提取打乱顺序的训练数据
- y_train = y_train[indices]#提取打乱顺序的训练数据的标签
- #训练数据提取
- indices = np.arange(len(x_test))
- np.random.shuffle(indices)
- x_test = x_test[indices]
- y_test = y_test[indices]
- #去除数据中超过上限的值,下限为0
- if num_words is not None:
- x_train = [[w for w in x if 0 <= w < num_words] for x in x_train]
- x_test = [[w for w in x if 0 <= w < num_words] for x in x_test]
- if choosedata=='train':
- return x_train,y_train
- elif choosedata=='test':
- return x_test,y_test
- elif choosedata=='trainandtest':
- return (x_train,y_train),(x_test,y_test)
- elif choosedata=='all':
- #数据拼接
- xs = np.concatenate([x_train, x_test])
- ys = np.concatenate([y_train, y_test])
- return xs,ys
-
- def limit_imdb_datalength(datax,maxlen=500,truncating='post',dtype='int32'):
- """
- 限定数据集的长度,对过长的进行剪切,不足的用0填充
- :param datax:输入数据二维数组
- :param maxlen:限定数据集的长度
- :param truncating:前向限定还是后向限定{'pre','post'}
- :param dtype:数据类型
- :return:x:处理后的数据
- """
- #构建一个相同的矩阵来装改变后的数据
- num_samples=len(datax)
- x = np.full((num_samples, maxlen), 0., dtype=dtype)
- #对数据进行长度判断,并将处理后的数据装在新数组x中
- for idx, s in enumerate(datax):
- if not len(s):
- continue
- if len(s)>maxlen:
- if truncating == 'post':
- trunc = s[:maxlen]
- x[idx, :len(trunc)] = trunc
- elif truncating == 'pre':
- trunc = s[-maxlen:]
- x[idx, -len(trunc):] = trunc
- else:
- trunc=s
- if truncating == 'post':
- x[idx, :len(trunc)] = trunc
- elif truncating == 'pre':
- x[idx, -len(trunc):] = trunc
- return x

国际旅行人数预测的数据导入,需要从网上下载international-airline-passengers.csv数据,当然也可以写函数进行导入,也可以直接通过pandas函数中的read_csv函数进行导入,CSV格式可以直接通过office打开,看着和xls差不多,自己写导入函数的话可以根据Excel表格读取的数据特点来进行程序编写。在此直接调用read_csv进行数据导入,并对导入的数据进行归一化。
- data=read_csv('international-airline-passengers.csv',usecols=[1],engine='python',skipfooter=3)
- data=data.values.astype('float32')
- scaler=MinMaxScaler()
- dataset=scaler.fit_transform(data)#归一化
如果用国际旅行人数来进行预测模型建立的话,导入的数据还需要进行处理,导入的数据只是不同时间的人数,我们需要让不同时间段的人数有关系,将数据关联起来,如果当前时间是t,需要知道前两个时间t-1,t-2,来预测下一个时间t+1;并对导入的数据进行了训练数据和测试数据的分割,用一定数据的数据来进行训练,用一定数据的数据来进行预测。
- def create_data(data,look_back=3,splitsize=0.7):
- """
- 给定当前时间t,预测t+1,使用数据(t-2,t-1,t)
- :param data:数据
- :param look_back:输出数据集的格式,默认3[1,2,3],如果改成4则为[1,2,3,4]
- :return: (x_train,y_train),(x_test,y_test):实际数据,结果,训练数据,结果
- """
- datax,datay=[],[]
- for i in range(len(data)-look_back-1):
- x=data[i:i+look_back,0]#每次去look_back个数据
- datax.append(x)
- y=data[i+look_back,0]#如果x是0,1,2,则y是3
- datay.append(y)
- train_size=int(len(datax)*splitsize)
- # test_size=int(len(datax)-train_size)
- # 前半截数据用于训练,后半截数据用于测试
- x_train,y_train=np.array(datax[0:train_size]),np.array(datay[0:train_size])
- x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 1))#样本、时间步长、特征
- x_test,y_test=np.array(datax[train_size:len(datax)]),np.array(datay[train_size:len(datax)])
- x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 1))
- return (x_train,y_train),(x_test,y_test)
数据的相关导入可以参考:https://blog.csdn.net/zx520113/article/details/84557459。
3、国际旅行人数预测模型建立
拿到了数据,我们需要根据数据来建立相应的模型。为了方便模型下次使用,可以通过save_model保存模型,get_model载入训练好的模型。可参考:https://blog.csdn.net/zx520113/article/details/84789427。
- def perceptron_model():
- #多层感知器模型,hidden_layer_num隐藏层层数
- """这里导入的数据不需要进行reshpe改变,直接用datax.append(x),datay.append(y)的数据就行"""
- model=Sequential()
- model.add(Dense(units=hidden_layer_num,input_dim=look_back,activation='relu'))
- model.add(Dense(units=hidden_layer_num, activation='relu'))
- model.add(Dense(units=1))
- model.compile(loss='mean_squared_error',optimizer='adam')
- return model
-
- def time_model():
- #LSTM搭建的LSTM回归模型
- model=Sequential()
- model.add(LSTM(units=hidden_layer_num,input_shape=(1,look_back)))#四个隐藏层或者更多
- model.add(Dense(units=1))
- model.compile(loss='mean_squared_error',optimizer='adam')
- return model
-
- def time_step_model():
- #使用时间步长的LSTM回归模型
- model=Sequential()
- model.add(LSTM(units=hidden_layer_num,input_shape=(look_back,1)))
- model.add(Dense(units=1))
- model.compile(loss='mean_squared_error',optimizer='adam')
- return model
-
- def memory_batches_model():
- #LSTM的批次时间记忆模型
- model=Sequential()
- # 通过设置stateful为True来保证LSTM层内部的状态,从而获得更好的控制
- model.add(LSTM(units=hidden_layer_num,batch_input_shape=(batch_size,look_back,1),stateful=True))
- model.add(Dense(units=1))
- model.compile(loss='mean_squared_error',optimizer='adam')
- return model
-
- def stack_memory_batches_model():
- # 两个叠加的LSTM的批次时间记忆模型
- model=Sequential()
- #通过设施return_sequences等于True来完成每个LSTM层之前的LSTM层必须返回序列,将LSTM扩展位两层
- model.add(LSTM(units=hidden_layer_num,batch_input_shape=(batch_size,look_back,1),stateful=True,return_sequences=True))
- # 通过设置stateful为True来保证LSTM层内部的状态,从而获得更好的控制
- model.add(LSTM(units=hidden_layer_num,input_shape=(batch_size,look_back,1),stateful=True))
- model.add(Dense(units=1))
- model.compile(loss='mean_squared_error',optimizer='adam')
- return model
4、IMDB预测模型建立
最简单的IMDB模型,有一个词嵌入层,一个LSTM层,一个输出层组成,为提高准确率,可以加入Dropout损失,卷积池化等,搭建复杂的网络。
- def easy_imdb_model():
- model=Sequential()
- model.add(Embedding(top_words,out_dimension,input_length=max_words))
- model.add(LSTM(units=100))
- model.add(Dense(units=1,activation='sigmoid'))
- model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
- model.summary()
- return model
-
- def dropout_imdb_model():
- model=Sequential()
- model.add(Embedding(top_words,out_dimension,input_length=max_words))
- model.add(Dropout(dropout_rate))
- model.add(LSTM(units=100))
- # model.add(LSTM(units=100,dropout=0.2,recurrent_dropout=0.2))
- model.add(Dropout(dropout_rate))
- model.add(Dense(units=1,activation='sigmoid'))
- model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
- model.summary()
- return model
-
- def lstm_cnn_imdb_model():
- model=Sequential()
- model.add(Embedding(top_words,out_dimension,input_length=max_words))
- model.add(Conv1D(filters=32,kernel_size=3,padding='same',activation='relu'))
- model.add(MaxPooling1D(pool_size=2))
- model.add(LSTM(units=100))
- model.add(Dense(units=1,activation='sigmoid'))
- model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
- model.summary()
- return model
5、训练测试模型
通过model.fit()传入相应的数据,参数对模型进行训练。模型训练好后,通过model.predict()传入x数据对模型进行预测,对预测出来的y数据进行scaler.inverse_transform反转,因为我们在最开始对数据进行了处理,所以要得到原来的数据我们需要用相反的方法处理一下预测出来的数据结果。然后对数据进行绘制比对,图像的绘制可以通过matplotlib,plt实现。matplotlib的使用可以参考:https://blog.csdn.net/zx520113/article/details/84103437。
- model=memory_batches_model()
- for i in range(epochs):
- history = model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=0, shuffle=False)
- mean_loss = np.mean(history.history['loss'])
- print('mean loss %.5f for loop %s' % (mean_loss, str(i)))
- model.reset_states()#重置模型中所有层的状态
- (x_train,y_train),(x_test,y_test) = load_imdb_data(choosedata='trainandtest',num_words=max_words)
- x_train = limit_imdb_datalength(x_train,truncating='pre')
- x_test = limit_imdb_datalength(x_test,truncating='pre')
- model=easy_imdb_model()
- model.fit(x_train,y_train,batch_size=batch_size,epochs=epochs,verbose=2)
- scores=model.evaluate(x_test,y_test,verbose=2)
- print("Accuracy:%.2f%%"%(scores[1]*100))
完整的python代码和数据连接:https://download.csdn.net/download/zx520113/10833491

