
热门标签
热门文章
- 1如何实现锁屏状态下远程控制安卓手机,向日葵远程控制全指南
- 22021-07-14 linux学习-网络方面(五) 配置防火墙之firewalld图形化管理工具_没安装图像化界面怎么打开firewall-config
- 3麒麟KYLINOS域名解析失败的修复方法_麒麟v10 apt-get 解析域名
- 4MySQL表分区技术介绍
- 5微擎的安装与使用
- 6vscode连接远程服务器失败问题合集_vscode远程ssh连接服务器连不上
- 7Python ORM之SQLAlchemy全面指南_query.filter_by() 不等于
- 8关于微信小程序使用UDP实现局域网通讯及UDP模块的封装_微信小程序 udp
- 9【区间贪心】合理安排电视节目_c语言看尽量多的节目
- 10package architecture (i386) does not match system
当前位置: article > 正文
掌财社:python怎么爬取链家二手房的数据?爬虫实战!_python爬取并导出链家各个市区的数据
作者:笔触狂放9 | 2024-03-06 06:27:03
赞
踩
python爬取并导出链家各个市区的数据
我们知道爬虫的比较常见的应用都是应用在数据分析上,爬虫作为数据分析的前驱,它负责数据的收集。今天我们以python爬取链家二手房数据为例来进行一个python爬虫实战。(内附python爬虫源代码)
一、查找数据所在位置:
打开链家官网,进入二手房页面,选取某个城市,可以看到该城市房源总数以及房源列表数据。
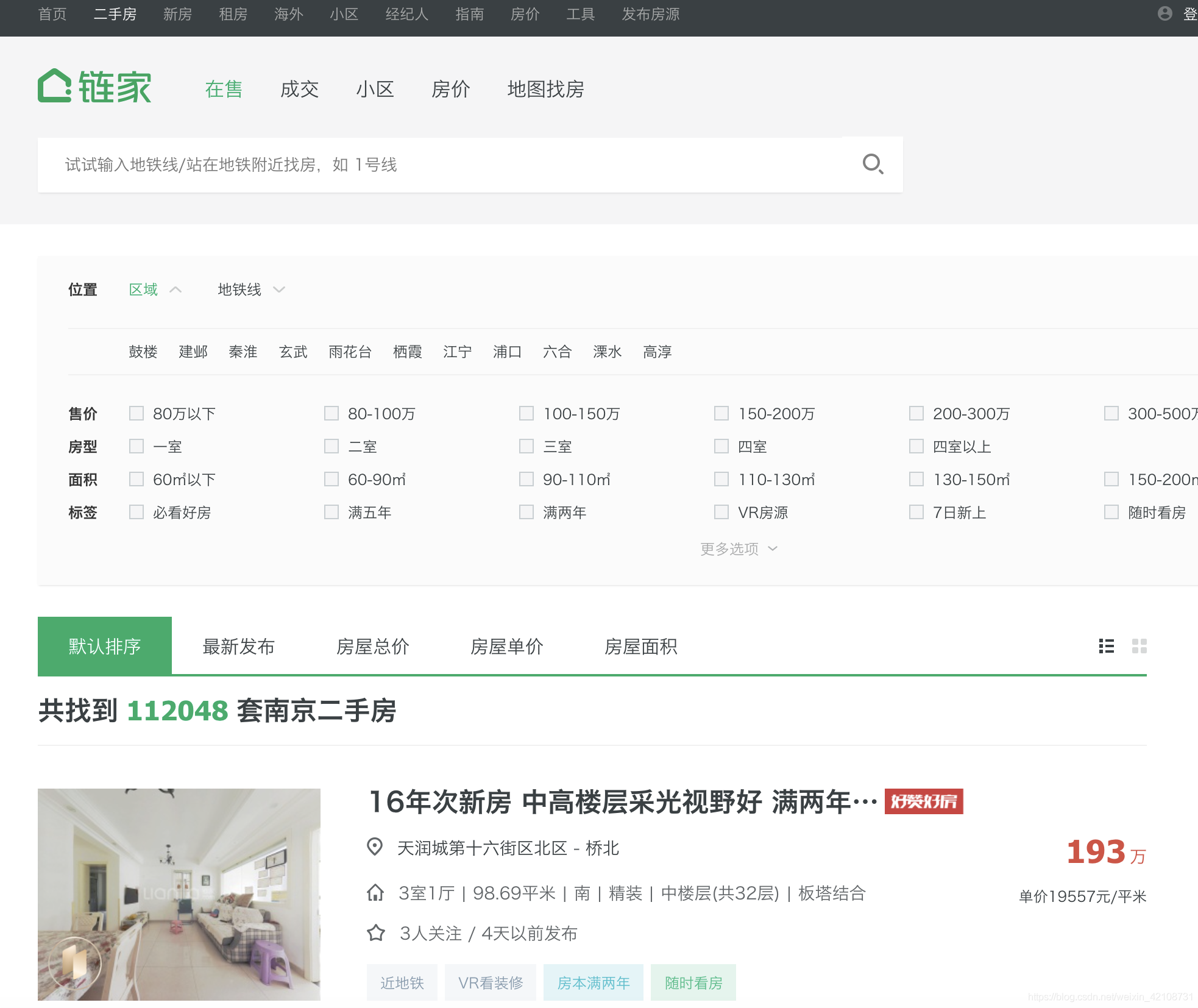
二、确定数据存放位置:
某些网站的数据是存放在html中,而有些却api接口,甚至有些加密在js中,还好链家的房源数据是存放到html中:

三、获取html数据:
通过requests请求页面,获取每页的html数据
- # 爬取的url,默认爬取的南京的链家房产信息
- url = 'https://nj.lianjia.com/ershoufang/pg{}/'.format(page)
- # 请求url
- resp = requests.get(url, headers=headers, timeout=10)
四、解析html,提取有用数据&#x
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/196482
推荐阅读
相关标签

