
热门标签
热门文章
- 1为什么private方法加了@Transactional,事务也没有生效?_@transactional private 无效吗
- 2华为原生 HarmonyOS NEXT 鸿蒙操作系统星河版 发布!不依赖 Linux 内核_华为100%鸿蒙os next
- 3鸿蒙Harmony应用开发—ArkTS声明式开发(基础手势:Image)
- 4“尝试输入密码的次数太多 还原 Apple Watch 并重新配对。” 的正确解法_尝试输入密码次数太多还原apple w
- 5RNN循环卷积神经网络
- 6flutter无法在windows平台上拖拽文件到它的窗口中
- 7Linux下性能分析工具分析火焰图_linux录制分析火焰图
- 8基于ubuntu22.04手动安装openstack——2023.2版本(最新版)的问题汇总_ubuntu openstack ovs
- 9海信电视老出现android是什么意思,海信电视屏幕上显示“智能电视系统启动中,请稍后”是什么意思?怎样处理?- 一起装修网...
- 102022——我在CSDN消失的一年_最近这几年csdn怎么了
当前位置: article > 正文
NLP:文本相似度计算
作者:笔触狂放9 | 2024-03-11 11:36:42
赞
踩
NLP:文本相似度计算
前面我们已经实现了把长段的句子,利用HanLP拆分成足够精炼的分词,后面我们要实现“联想”功能,我这里初步只能想到通过文本相似度计算来实现。下面介绍一下文本相似度计算
(当然HanLP也有文本相似度计算的方法,这里我应该上一节也说过,但是使用之后效果并不理想,因此,我们要换其他的方法)
这里我们采取的是text2vec,事实上网上通用的是word2vec,但是他要求自己训练模型,而且github上的流程我没看得懂,所以我就在github上找了别人现成的模型来使用
- 下载
- pip install torch # conda install pytorch
- pip install -U text2vec
这里下载第二个的时候建议用上镜像,并且请在网络较好的地方下载
- 测试
- import sys
-
-
- sys.path.append('..')
- from text2vec import Similarity
-
- # Two lists of sentences
- sentences1 = ['c++开发十年经验',
- '善于沟通,领导他人',
- '全栈开发',
- '你好']
-
- sentences2 = ['擅长编程',
- '体贴',
- 'web 开发',
- '有领导能力']
-
- sim_model = Similarity()
- for i in range(len(sentences1)):
- for j in range(len(sentences2)):
- score = sim_model.get_score(sentences1[i], sentences2[j])
- print("{} \t\t {} \t\t Score: {:.4f}".format(sentences1[i], sentences2[j], score))

放上运行结果
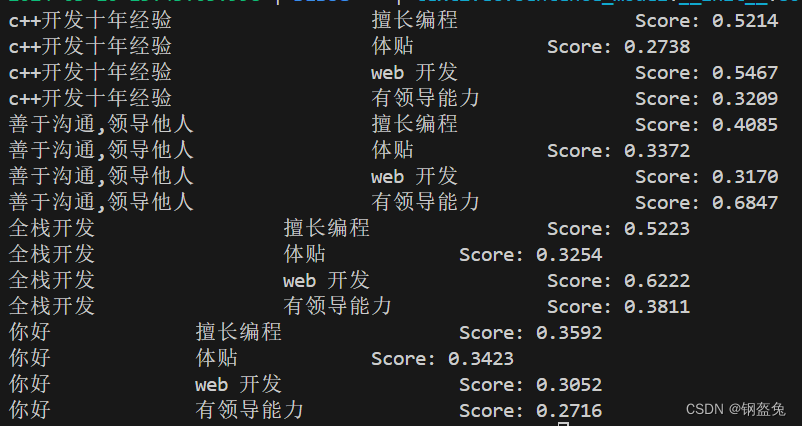
可以发现,联想的效果还是有的,至少在我当前的需求下,它是完全够用的。
- We couldn't connect to 'https://huggingface.co'
这是一个很关键的报错,具体可以参考这位老哥的博客:解决办法
(不过确实,因为围墙的存在,在一定程度上是阻碍了国内科研和学习的发展)
亲测可行的方法则是在代码前面补充上下面两行代码(即利用镜像)
- import os
- os.environ['HF_ENDPOINT']='https://hf-mirror.com'
之后如果有闲工夫的话,我还是想利用word2vec来训练一个自己的模型,毕竟数据摆在这里,不用而去调别人现成的模型,多少是不会满足特定场景的需求。
参考文献:
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/218800
推荐阅读
相关标签

