
热门标签
热门文章
- 1ThingsBoard-OAuth2登录-UI配置授权登录_thingsboard 用户权限设置
- 22010-2021年最常见的1000道Java架构师面试题(附答案)_java架构师背题
- 3uni打包android或iOS_uniapp ios安卓同一套打包
- 4Tuxera NTFS for Mac2023苹果电脑Mac硬盘读写工具
- 5pritunl+openvpn安装及使用
- 6Matlab编程技巧:A*算法仿真_a*算法matlab
- 7Android埋点方案的简单实现-AOP之AspectJ_安卓aop埋点
- 8python矢量裁剪栅格代码_矢量裁剪矢量,矢量裁剪栅格ArcGIS中这样玩
- 9制造业数字化经营新思路:管理平台架构及三大落地方法论_数字化经营平台
- 10spring security oauth2 资源服务器WebAsyncTask/DeferredResult接口调用报错InsufficientAuthenticationException
当前位置: article > 正文
自然语言处理——概述_自然语言处理四大任务
作者:笔触狂放9 | 2024-03-11 15:58:45
赞
踩
自然语言处理四大任务
自然语言处理的四大基本任务
文本分类、文本匹配、序列标注、文本生成
1、文本分类
- 新闻分类:娱乐、财经、军事、科技……
- 垃圾邮件识别:spam
- 情感分析:好评,中评、差评
- 意图识别:定座位、拒绝
2、文本匹配
- query-doc搜索
- 商品检索
- QA系统
- 个性化推荐
- 智能客服
- 声纹识别
3、序列标注
- 分词
- 词性标注
- 命名实体识别
- 关系抽取
- 时间抽取
- 句法分析
- 辞职边界检测
- 语音识别
4、文本生成
- 文本到文本的生成:机器翻译,文本摘要,古诗生成,智能对话
- 数据到文本的生成:自动撰写
- 图像到文本的生成:基于图像问答,看图说话
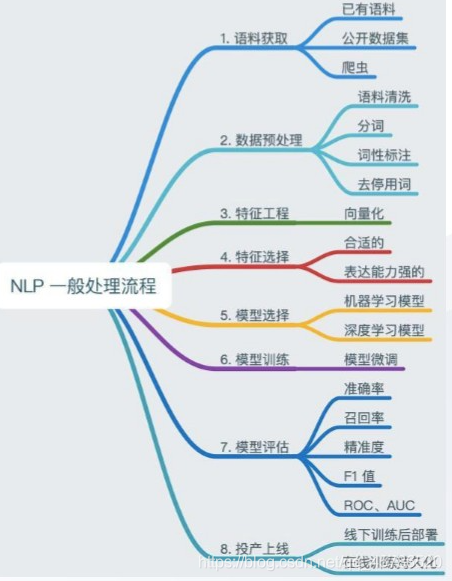
NLP处理流程
1、 获取语料
一般通过已有数据、公开数据集、爬虫等方式获取
2、 数据预处理
- 语料清洗:保留有用的数据,删除噪音数据,常见对的清洗方式有:人工去重、对齐、删除、标准等。
- 分词:将文本分词词语,比如通过基于规则的或基于统计的分词方法进行分词。
- 词性标注:给词语标上词类标签,比如名词、动词、形容词等,常用的词性标注方法欧基于规则的和基于统计的算法。
- 去停用词:去掉对文本特征没有任何贡献作用的字词。
3、 特征工程
将分词结果转换为向量,常用的模型有
- 词袋模型(Bag of Word),如 TF-IDF算法
- 静态词向量,如 word2vec、fasttext、 glove
- 动态词向量, 如elmo 、 gpt、bert、 xlnet等
4、特征选择
这一步的特征选择是基于特征工程得到的特征,选择合适的,表达能力强的特征,常见的特征选择方法有:DF、MI、IG、WFO等。
5、模型选择
- 基于统计的学习模型:TFIDF、HMN、MEMM、CRF
- 基于机器学习的模型:KNN、SVM、Naive Bayes、决策树、k-means等
- 基于深度学习的模型:LSTM、Seq2seq,FastText、TextRNN、TextCNN、TextRCNN等
6、模型训练
训练模型并调整模型。
7、模型评估
错误率、精确度、准确率、召回率、F1值、ROC曲线、BLEU
8、投产上线
一种是线下训练模型,然后将模型进行线上部署提供服务;;另一种是在线训练模型,训练模型完成后将模型pickle持久化,提供对外服务。
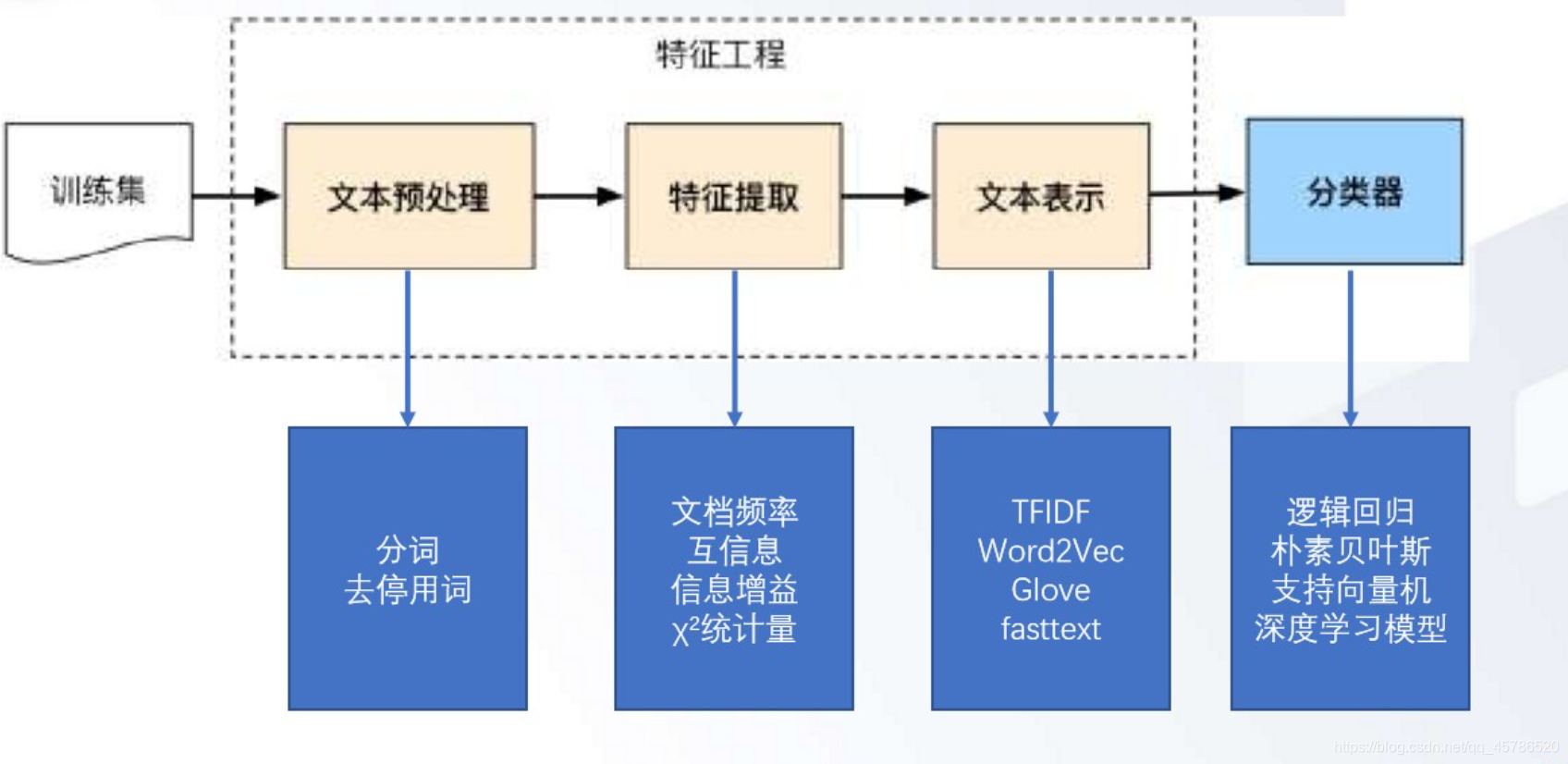
文本分类方法将整个文本分类问题就拆分成了特征工程和分类器两部分。特征工程分为文本预处理、特征提取、文本表示三个部分,最终目的是把文本转换成计算机可理解的格式,并封装足够用于分类的信息,即很强的特征表达能力:
未登录词
即未出现在算法使用的词典中的词,比如不常见的专业金融术语等。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/笔触狂放9/article/detail/219754
推荐阅读
相关标签

